函数
—— 封装的一个公式:sin、cos、tan
—— 函数为脚本的别名
—— 函数就是一个功能模块,在函数中写执行的命令即可;使用函数可以避免代码重复,增加可读性,简化脚本,使用函数可以将大的工程分割为若干小的功能模块,代码的可读性更强
—— 函数由函数名和函数体组成
—— 函数一定要先定义,才能使用
—— 帮助:help function
函数的用法
注:一定要先给函数定义,才能执行函数
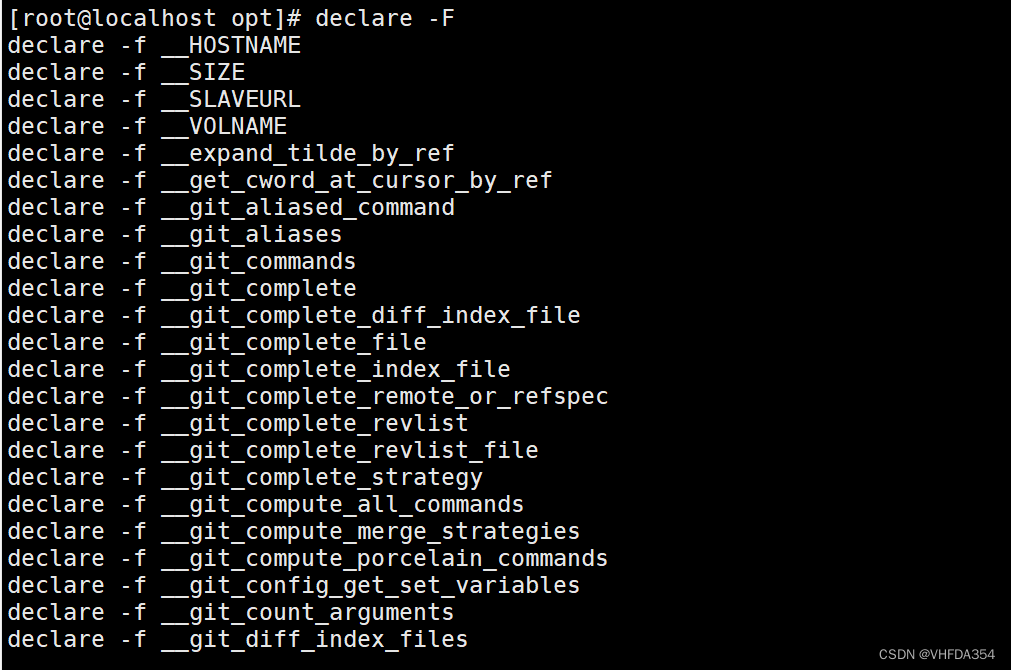
查看函数
declare 命令
—— declare -F :查看函数列表
—— declare -f __函数名 :查找指定函数名;两个下划线
函数的定义
—— 格式1:自定义函数名 () {
脚本;命令序列
}
—— 格式2:function 自定义函数名 {
脚本;命令序列
}
—— 格式3:function 自定义函数名 (){
脚本;命令序列
}
例
格式1 #一般用此格式
[root@localhost opt]# han () { echo "hello"; }
#定义一个函数 han 为标准输出 hello
[root@localhost opt]# han
hello #执行此函数,显示结果格式2
[root@localhost opt]# function han { echo "hello"; }
[root@localhost opt]# han
hello格式3
[root@localhost opt]# function han () { echo "hello"; }
[root@localhost opt]# han
hello删除函数
unset 命令
—— unset 函数名
例
#先定义一个函数,并验证是否能使用
[root@localhost opt]# han () { echo "hello"; }
[root@localhost opt]# han
hello[root@localhost opt]# unset han #删除函数
[root@localhost opt]# han
bash: han: 未找到命令...
#再次使用函数,验证是否删除;删除成功
定义函数变量的作用范围
local
—— 加此关键词,可以固定函数的变量范围,使其只能在函数内运行
export
—— 让子shell 继承变量
例
[root@localhost opt]# name=吴彦祖 #定义一个变量name为吴彦祖
[root@localhost opt]# echo $name #验证
吴彦祖
[root@localhost opt]# id () { name=彭于晏;echo $name; }
#定义一个函数id,让其中变量name输出结果为彭于晏
[root@localhost opt]# id #验证
彭于晏
[root@localhost opt]# echo $name
彭于晏#此时输出变量name已经被函数id所影响
[root@localhost opt]# unset id
[root@localhost opt]# echo $name
彭于晏
#就算删除函数id,变量name已经被更改
[root@localhost opt]# name=吴彦祖 #重新定义name
[root@localhost opt]# echo $name #验证
吴彦祖
[root@localhost opt]# id () { local name=彭于晏;echo $name; }
#使用命令 local,限制变量参数,使其只能在函数中执行
[root@localhost opt]# id #验证
彭于晏
[root@localhost opt]# echo $name #验证,此时变量name不会被函数id影响
吴彦祖函数的返回值
return
—— 自定义 返回值 0 -- 255
—— 如果使用函数,那么 $? 那么使用就会受限,可以使用 return 自定义 $? 的返回值,来判断函数中的命令是否成功
—— 函数一结束就取返回值,因为 $? 变量只返回执行的最后一条命令的退出返回码
—— 退出码必须是0-255,超出的值将为除以256取余
例
[root@localhost opt]# text () { echo "hello"; }
#定义一个函数
[root@localhost opt]# text
hello
[root@localhost opt]# echo $?
0
#此时返回值为0
[root@localhost opt]# text () { echo "hello";return 250; }
#更改返回值为250
[root@localhost opt]# text
hello
[root@localhost opt]# echo $?
250
#此时返回值已经被更改为250函数的传递参
脚本
#!/bin/bash
sum () {
echo " $1 " #识别第一个字符串
echo " $2 " #识别第二个字符串
#识别两个字符串
}
sum $2 $1
#这后面的$2和$1,代表的是跟在脚本后面的字符串的顺序;此处就是设定将第二个字符串放在第一位,将第一个字符串放在第二位显示结果
[root@localhost opt]# bash j.sh 1 99 1 需要注意
—— 脚本的 $1 $2 和函数的 $1 $2 ,是没有关系的
—— 函数的 $1 $2 是指跟在函数后面的值
递归函数
—— 函数的本质就是一个程序,每开一个进程都会消耗资源,无限的开自己死循环就会造成资源的无限占用形成病毒
—— 函数调用自己本身的函数
—— 必须要有结束函数的语句,防止死循环
阶乘函数
—— 一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且0和1的阶乘为1,自然数n的
—— 阶乘写作 n! =1×2×3×...×n
—— 阶乘亦可以递归方式定义:0!=1,n!=(n-1)!×n n!=n(n-1)(n-2)...1 n(n-1)! = n(n-1)(n-2)!
脚本举例:此脚本作用是计算任意数值的阶乘
#!/bin/bash
fact () {
if [ $1 -eq 0 -o $1 -eq 1 ]
thenecho 1
elseecho $[$1* $(fact $[$1-1])]
#这里将 $[$1-1] 的值再次使用函数 fact 进行执行
#此处 * 为乘
fi
}
fact $1结果展示
[root@localhost opt]# bash digui.sh 5
120
#5的阶乘为120函数的文件
—— 专门存放函数的文件
—— . 绝对路径的文件名 函数名:从存放函数的文件中,提取使用指定函数(. 可以用 source 代替)
数组
—— 数据的集合称为数组
-
普通数组,普通数组可以不事先声明,直接使用;下标只能是数值
-
关联数组,关联数组必须先声明,再使用;下标可以自定义任意字符串
-
变量:存储单个元素的内存空间
-
数组:存储多个元素的连续的内存空间,相当于多个变量的集合
—— 数组名和索引
-
索引的编号从0开始,属于数值索引
-
索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash 4.0版本之后开始支持
-
bash的数组支持稀疏格式(索引不连续)
数组的使用
—— 一定要先声明数组
daclare -a 普通数组(不需要手动声明,系统帮你声明了)
—— 关联数组一定要手动声明
declare -A 数组名
定义数组
—— 自定义数组名=(数组值中间用空格隔开)
例
![]()
单个调用
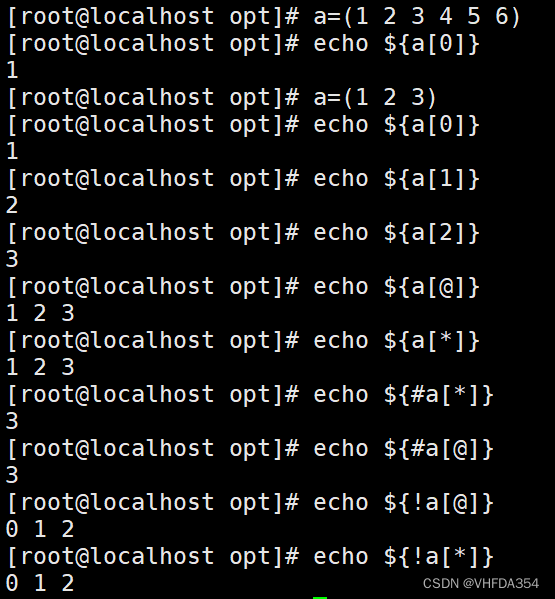
| echo | 作用 |
|---|---|
| ${a[0]} | 调用第一个值 |
| ${a[1]} | 调用第二个值 |
| ${a[2]} | 调用第三个值 |
| …… | …… |
| ${a[n]} | 调用第n个值 |
全部调用
| echo | 作用 |
|---|---|
| ${a[@]} 或者 ${a[*]} | 显示所有结果 |
| ${#a[@]} 或者 ${#a[*]} | 统计个数 |
| ${!a[@]} 或者 ${!a[*]} | 显示所有下标 |
例
数组切片
—— 格式:echo ${自定义数组名[@或*]:自定义数字:自定义数字}
—— 注意:以 “:” 为分隔符
例
[root@localhost opt]# a=(1 2 3 4 5)
[root@localhost opt]# echo ${a[@]:1:3}
2 3 4
#从第一个开始并跳过第一个,到后三个结束数组替换
—— 格式:echo ${自定义数组名[@或*]/查找的目标字符/替换的字符}
—— 注意:以 “/” 为分隔符
例
[root@localhost opt]# a=(1 2 3 4 5)
[root@localhost opt]# echo ${a[@]/2/hi}
1 hi 3 4 5
#查找a数组中第二个字符串,并替换成hi数组删除
—— 格式:unset 数组名 //删除该数组
—— 格式:unset 数组名[n] //选择数组中的第 n 个删除;从0开始,0代表第一个字符
例
[root@localhost opt]# a=(1 2 3 4 5)
[root@localhost opt]# echo ${a[*]}
1 2 3 4 5
[root@localhost opt]# unset a[2] #删除该数组中第三个字符
[root@localhost opt]# echo ${a[*]} #验证
1 2 4 5
[root@localhost opt]# unset a #删除该数组
[root@localhost opt]# echo ${a[*]}
#不会显示任何东西冒泡排序
—— 一种数组排序算法
—— 类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动
—— 基本思想:冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部
—— 算法思路:冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了,而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少
脚本举例:此脚本是随机生成十个不同的数字并进行从小到大排序
#!/bin/bash
for i in {0..9}
do
a[$i]=$RANDOM
done
#生成一个拥有十个随机数的数组
echo "原始数组: ${a[@]}"l=${#a[@]}
#定义变量l 等同于数组的总个数;此处 l=10
for((i=1;i<$l;i++))
#需要进行比较的次数
dofor ((j=0;j<$l-$i;j++))#相邻的数字,需要比较的次数dofirst=${a[$j]}#数组的第 n个数k=$[$j+1]#数组的 n+1大小的下标second=${a[$k]}#数组的第 n+1个数if [ $first -gt $second ]thentemp=$firsta[$j]=$seconda[$k]=$temp#该三行是将两个数字进行更换位置fidone
doneecho "从小到大: ${a[@]}"
脚本举例
比较随机数字的数组大小
#!/bin/bash
for a in {0..9}
dob[$a]=$RANDOM[ $a -eq 0 ] && min=${b[0]} && max=${b[0]}[ ${b[$a]} -gt $max ] && max=${b[$a]}[ ${b[$a]} -lt $min ] && min=${b[$a]}
doneecho "数组: ${b[*]}"
echo "最大值: $max"
echo "最小值: $min"补充命令
scp 脚本名 目标ip
—— 将脚本发送给指定虚拟机
declare 命令补充
—— declare +/- 选项 变量名
| 选项 | 作用 |
|---|---|
| - | 赋予变量类型属性 |
| + | 取消变量的类型属性 |
| -a | 将变量声明为数组型 |
| -i | 将变量声明为整数型 |
| -x | 将变量声明为环境变量 |
| -r | 将变量声明为只读变量 |
| -p | 查看变量的被声明的类型 |
eval 命令
—— 格式:eval()
—— 注释:将任意字符串当成有效的表达式来求值并返回计算结果;如果参数不是字符串类型,则直接返回参数;需要注意的是,使用 eval() 函数时需要谨慎,因为它可以执行任意代码,存在一定的安全风险
显示颜色的命令