Python
- 一、入门语法
- 1.1 字符串的多种定义方式
- 1.2 Python中的运算符
- 1.3 input语句
- 1.4 字符串格式化的方式
- 二、Python判断语句
- 2.1 布尔类型和比较运算符
- 2.2 if判断语句的基础格式
- 2.3 if else语句的使用
- 2.4 if_elif_else语句的使用
- 2.5 判断语句的嵌套
- 三、Python循环语句
- 3.1 while循环的基础语法
- 3.2 while循环的嵌套应用
- 3.3 for循环的基础语法
- 3.4 range语句
- 3.5 for循环的嵌套使用
- 四、函数
- 4.1 函数参数
- 4.2 函数的返回值定义语法
- 4.3 函数说明文档
- 4.4 函数嵌套调用
- 4.5 变量的作用域
- 4.6 综合案例
- 五、函数进阶
- 5.1 函数的多返回值
- 5.2 函数参数的多种使用形式
- 5.3 函数作为参数传递
- 5.4 lambda匿名函数
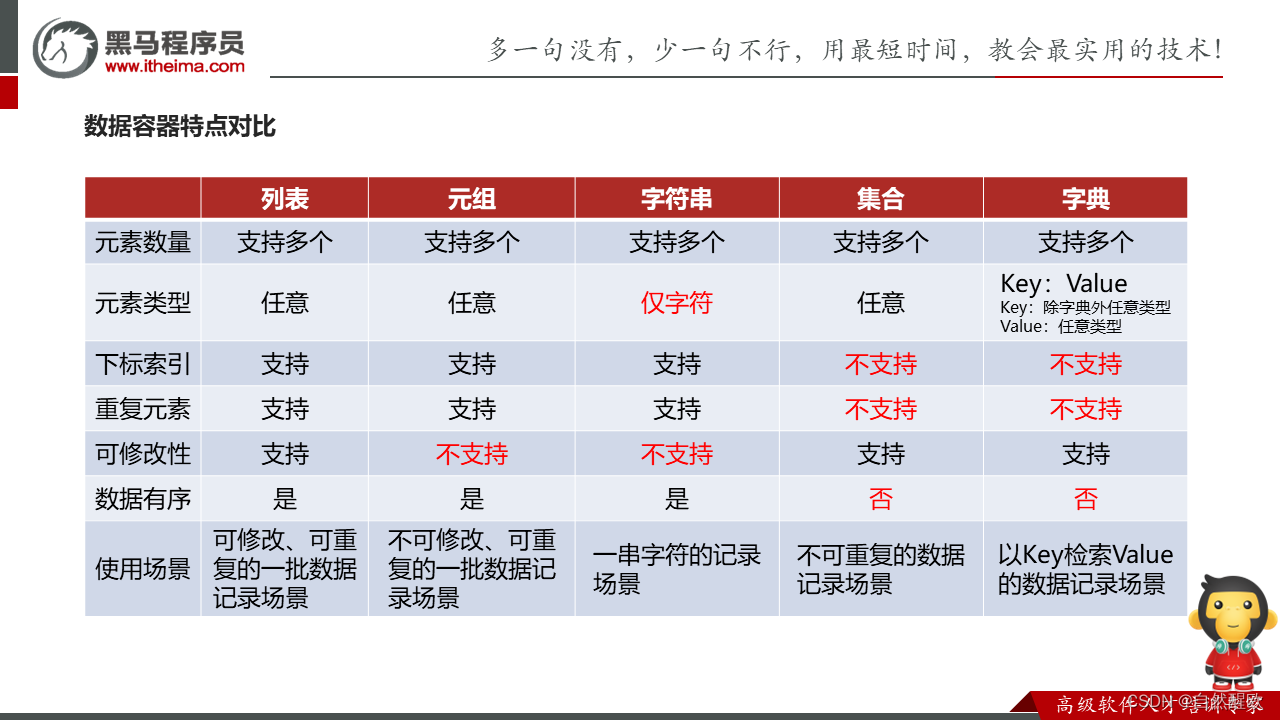
- 六、数据容器
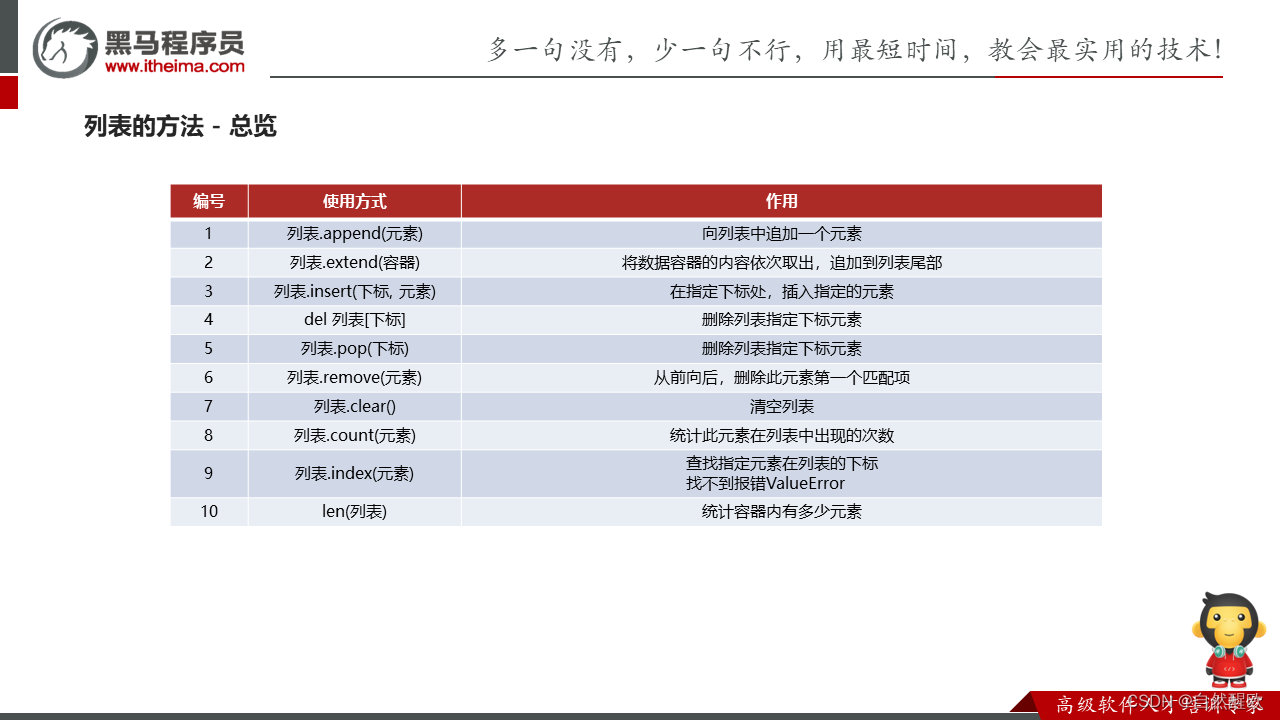
- 6.1 list列表
- 6.2 list列表的常用操作
- 6.3 tuple元组的定义和操作
- 6.4 字符串
- 6.5 序列和切片
- 6.6 集合
- 6.7 字典
- 6.8 字典的常用操作
- 6.9 数据容器通用功能
- 6.10 字符串大小比较
- 七、文件操作
- 7.1 文件的读取
- 7.2 文件的写入
- 7.3 文件的追加
- 7.4 文件操作的综合案例
- 八、异常_模块_包
- 8.1 异常的捕获
- 8.2 异常的传递
- 8.3 模块的导入
- 8.4 自定义模块
- 8.5 包
- 8.5.1 __init__py
- 8.5.2 my_module1.py
- 8.5.3 my_module2.py
- 8.6 综合案例练习
- 8.6.1 file_util.py
- 8.6.2 str_util.py
- 九、可视化图表
- 9.1 JSON数据格式
- 9.2 pyecharts基础入门
- 9.3 折线图开发
- 9.4 地图可视化的基本使用
- 9.5 全国疫情可视化地图开发
- 9.6 河南省疫情地图开发
- 9.7 基础柱状图开发
- 9.8 基础时间线柱状图开发
- 9.9 列表的sort方法
- 9.10 GDP动态柱状图开发
- 十、 面向对象
- 10.1 成员方法
- 10.2 类和对象
- 10.3 构造方法
- 10.4 其它内置方法
- 10.5 封装
- 10.6 继承的基础语法
- 10.7 继承_复写和使用父类成员
- 10.8 类型注解_变量
- 10.9 类型注解_Union联合类型
- 10.10 多态
- 10.11 综合案例
- 10.11.1 data_define.py
- 10.11.2 file_define.py
- 10.11.3 main.py
- 十一、 SQL
- 11.1 DML
- 11.1.1 插入
- 11.1.2 删除
- 11.1.3 更新
- 11.2 DQL
- 11.2.1 基础查询
- 11.2.2 过滤查询
- 2.3 分组聚合
- 11.2.4 排序分页
- 11.3. Python & MySQL
- 11.3.1 pymysql入门
- 11.3.2 pymysql_数据插入
- 11.4 综合案例
- 11.4.1 main.py
- 11.4.2 main2.py
- 十二、 pyspark
- 12.1 基本准备
- 12.2 数据输入
- 12.3 数据计算_map方法
- 12.4 数据计算_flatMap方法
- 12.5 数据计算_reduceByKey方法
- 12.6 练习案例1
- 12.7 数据计算_filter方法
- 12.8 数据计算_distinct方法
- 12.9 数据计算_sortBy方法
- 12.10 练习案例2
- 12.11 数据输出_输出为Python对象
- 12.12 数据输出_输出到文件
- 12.13 综合案例
- 十三、 高级技巧
- 13.1 闭包
- 13.2 装饰器
- 13.3 单例模式
- 13.3.1 str_tools_py.py
- 13.3.2 test.py
- 13.3.3 非单例模式
- 13.4 工厂模式
- 13.5 多线程模式
- 13.6 socket编程
- 13.6.1 服务端开发
- 13.6.2 客户端开发
- 13.7 正则表达式
- 13.7.1 基础匹配
- 13.7.2 元字符匹配
- 13.8 递归
一、入门语法
1.1 字符串的多种定义方式
"""
演示字符串的三种定义方式:
- 单引号定义法
- 双引号定义法
- 三引号定义法
"""# 单引号定义法,使用单引号进行包围
name = '黑马程序员'
print(type(name))
# 双引号定义法
name = "黑马程序员"
print(type(name))
# 三引号定义法,写法和多行注释是一样的
name = """
我是
黑马
程序员
"""
print(type(name))# 在字符串内 包含双引号
name = '"黑马程序员"'
print(name)
# 在字符串内 包含单引号
name = "'黑马程序员'"
print(name)
# 使用转义字符 \ 解除引号的效用
name = "\"黑马程序员\""
print(name)
name = '\'黑马程序员\''
print(name)
1.2 Python中的运算符
"""
演示Python中的各类运算符
"""
# 算术(数学)运算符
print("1 + 1 = ", 1 + 1)
print("2 - 1 = ", 2 - 1)
print("3 * 3 = ", 3 * 3)
print("4 / 2 = ", 4 / 2)
print("11 // 2 = ", 11 // 2)
print("9 % 2 = ", 9 % 2)
print("2 ** 2 = ", 2 ** 2)
# 赋值运算符
num = 1 + 2 * 3
# 复合赋值运算符
# +=
num = 1
num += 1 # num = num + 1
print("num += 1: ", num)
num -= 1
print("num -= 1: ", num)
num *= 4
print("num *= 4: ", num)
num /= 2
print("num /= 2: ", num)
num = 3
num %= 2
print("num %= 2: ", num)num **= 2
print("num **=2: ", num)num = 9
num //= 2
print("num //= 2:", num)
1.3 input语句
"""
演示Python的input语句
获取键盘的输入信息
"""
name = input("请告诉我你是谁?")
print("我知道了,你是:%s" % name)# 输入数字类型
num = input("请告诉我你的银行卡密码:")
# 数据类型转换
num = int(num)
print("你的银行卡密码的类型是:", type(num))name = """黑马程序员"""
1.4 字符串格式化的方式
"""
演示第一种对表达式进行字符串格式化
"""
print("1 * 1 的结果是:%d" % (1 * 1))
print(f"1 * 2的结果是:{1 * 2}")
print("字符串在Python中的类型名是:%s" % type("字符串"))"""
演示第二种字符串格式化的方式:f"{占位}"
"""
name = "传智播客"
set_up_year = 2006
stock_price = 19.99
# f: format
print(f"我是{name},我成立于:{set_up_year}年,我今天的股价是:{stock_price}")"""
讲解字符串格式化的课后练习题
"""
# 定义需要的变量
name = "传智播客"
stock_price = 19.99
stock_code = "003032"
# 股票 价格 每日 增长 因子
stock_price_daily_growth_factor = 1.2
growth_days = 7finally_stock_price = stock_price * stock_price_daily_growth_factor ** growth_daysprint(f"公司:{name},股票代码:{stock_code},当前股价:{stock_price}")
print("每日增长系数: %.1f,经过%d天的增长后,股价达到了:%.2f" % (stock_price_daily_growth_factor, growth_days, finally_stock_price))
二、Python判断语句
2.1 布尔类型和比较运算符
"""
演示布尔类型的定义
以及比较运算符的应用
"""
# 定义变量存储布尔类型的数据
bool_1 = True
bool_2 = False
print(f"bool_1变量的内容是:{bool_1}, 类型是:{type(bool_1)}")
print(f"bool_2变量的内容是:{bool_2}, 类型是:{type(bool_2)}")
# 比较运算符的使用
# == , !=, >, <, >=, <=
# 演示进行内容的相等比较
num1 = 10
num2 = 10
print(f"10 == 10的结果是:{num1 == num2}")num1 = 10
num2 = 15
print(f"10 != 15的结果是:{num1 != num2}")name1 = "itcast"
name2 = "itheima"
print(f"itcast == itheima 结果是:{name1 == name2}")# 演示大于小于,大于等于小于等于的比较运算
num1 = 10
num2 = 5
print(f"10 > 5结果是:{num1 > num2}")
print(f"10 < 5的结果是:{num1 < num2}")num1 = 10
num2 = 11
print(f"10 >= 11的结果是:{num1 >= num2}")
print(f"10 <= 11的结果是:{num1 <= num2}")
2.2 if判断语句的基础格式
"""
演示Python判断语句:if语句的基本格式应用
"""
age = 10if age >= 18:print("我已经成年了")print("即将步入大学生活")print("时间过的真快呀")"""
演示练习
题:成年人判断
"""# 获取键盘输入
age = int(input("请输入你的年龄:"))# 通过if判断是否是成年人
if age >= 18:print("您已成年,游玩需要买票,10元.")print("祝您游玩愉快")
2.3 if else语句的使用
"""
演示Python中
if else的组合判断语句
"""
age = int(input("请输入你的年龄:"))if age >= 18:print("您已成年,需要买票10元。")
else:print("您未成年,可以免费游玩。")"""
演示if else练习题:我要买票吗
"""# 定义键盘输入获取身高数据
height = int(input("请输入你的身高(cm):"))# 通过if进行判断
if height > 120:print("您的身高超出120CM,需要买票,10元。")
else:print("您的身高低于120CM,可以免费游玩。")print("祝您游玩愉快")
2.4 if_elif_else语句的使用
"""
演示if elif else 多条件判断语句的使用
"""# 通过if判断,可以使用多条件判断的语法
# 第一个条件就是if
if int(input("请输入你的身高(cm):")) < 120:print("身高小于120cm,可以免费。")
elif int(input("请输入你的VIP等级(1-5):")) > 3:print("vip级别大于3,可以免费。")
elif int(input("请告诉我今天几号:")) == 1:print("今天是1号免费日,可以免费")
else:print("不好意思,条件都不满足,需要买票10元。")"""
演示if elif else练习题:猜猜心里数字
"""# 定义一个变量数字
num = 5# 通过键盘输入获取猜想的数字,通过多次if 和 elif的组合进行猜想比较
if int(input("请猜一个数字:")) == num:print("恭喜第一次就猜对了呢")
elif int(input("猜错了,再猜一次:")) == num:print("猜对了")
elif int(input("猜错了,再猜一次:")) == num:print("恭喜,最后一次机会,你猜对了")
else:print("Sorry 猜错了")
2.5 判断语句的嵌套
"""
演示判断语句的嵌套使用
"""
age = 11
year = 1
level = 1
if age >= 18:print("你是成年人")if age < 30:print("你的年龄达标了")if year > 2:print("恭喜你,年龄和入职时间都达标,可以领取礼物")elif level > 3:print("恭喜你,年龄和级别达标,可以领取礼物")else:print("不好意思,尽管年龄达标,但是入职时间和级别都不达标。")else:print("不好意思,年龄太大了")else:print("不好意思,小朋友不可以领取。")"""
演示判断语句的实战案例:终极猜数字
"""# 1. 构建一个随机的数字变量
import random
num = random.randint(1, 10)guess_num = int(input("输入你要猜测的数字:"))# 2. 通过if判断语句进行数字的猜测
if guess_num == num:print("恭喜,第一次就猜中了")
else:if guess_num > num:print("你猜测的数字大了")else:print("你猜测的数字小了")guess_num = int(input("再次输入你要猜测的数字:"))if guess_num == num:print("恭喜,第二次猜中了")else:if guess_num > num:print("你猜测的数字大了")else:print("你猜测的数字小了")guess_num = int(input("第三次输入你要猜测的数字:"))if guess_num == num:print("第三次猜中了")else:print("三次机会用完了,没有猜中。")
三、Python循环语句
3.1 while循环的基础语法
"""
演示while循环的基础应用
"""
i = 0
while i < 100:print("小美,我喜欢你")i += 1"""
演示while循环基础练习题:求1-100的和
"""
sum = 0
i = 1
while i<=100:sum += ii += 1print(f"1-100累加的和是:{sum}")"""
演示while循环的基础案例 - 猜数字
"""# 获取范围在1-100的随机数字
import random
num = random.randint(1, 100)
# 定义一个变量,记录总共猜测了多少次
count = 0# 通过一个布尔类型的变量,做循环是否继续的标记
flag = True
while flag:guess_num = int(input("请输入你猜测的数字:"))count += 1if guess_num == num:print("猜中了")# 设置为False就是终止循环的条件flag = Falseelse:if guess_num > num:print("你猜的大了")else:print("你猜的小了")print(f"你总共猜测了{count}次")
3.2 while循环的嵌套应用
"""
演示while循环的嵌套使用
"""# 外层:表白100天的控制
# 内层:每天的表白都送10只玫瑰花的控制i = 1
while i <= 100:print(f"今天是第{i}天,准备表白.....")# 内层循环的控制变量j = 1while j <= 10:print(f"送给小美第{j}只玫瑰花")j += 1print("小美,我喜欢你")i += 1print(f"坚持到第{i - 1}天,表白成功")"""
演示使用while的嵌套循环
打印输出九九乘法表
"""# 定义外层循环的控制变量
i = 1
while i <= 9:# 定义内层循环的控制变量j = 1while j <= i:# 内层循环的print语句,不要换行,通过\t制表符进行对齐print(f"{j} * {i} = {j * i}\t", end='')j += 1i += 1print() # print空内容,就是输出一个换行
3.3 for循环的基础语法
"""
演示for循环的基础语法
"""name = "itheima"for x in name:# 将name的内容,挨个取出赋予x临时变量# 就可以在循环体内对x进行处理print(x)"""
演示for循环的练习题:数一数有几个a
"""
# 统计如下字符串中,有多少个字母a
name = "itheima is a brand of itcast"# 定义一个变量,用来统计有多少个a
count = 0# for 循环统计
# for 临时变量 in 被统计的数据:
for x in name:if x == "a":count += 1print(f"被统计的字符串中有{count}个a")
3.4 range语句
"""
演示Python中的range()语句的基本使用
"""# range语法1 range(num)
# for x in range(10):
# print(x)# range 语法2 range(num1, num2)
# for x in range(5, 10):
# # 从5开始,到10结束(不包含10本身)的一个数字序列,数字之间间隔是1
# print(x)# range 语法3 range(num1, num2, step)
# for x in range(5, 10, 2):
# # 从5开始,到10结束(不包含10本身)的一个数字序列,数字之间的间隔是2
# print(x)for x in range(10):print("送玫瑰花")"""
演示Python for循环临时变量的作用域
"""
i = 0
for i in range(5):print(i)print(i)
3.5 for循环的嵌套使用
"""
演示嵌套应用for循环
"""# 坚持表白100天,每天都送10朵花
# range
i = 0
for i in range(1, 101):print(f"今天是向小美表白的第{i}天,加油坚持。")# 写内层的循环了for j in range(1, 11):print(f"给小美送的第{j}朵玫瑰花")print("小美我喜欢你")print(f"第{i}天,表白成功")"""
演示for循环打印九九乘法表
"""# 通过外层循环控制行数
for i in range(1, 10):# 通过内层循环控制每一行的数据for j in range(1, i + 1):# 在内层循环中输出每一行的内容print(f"{j} * {i} = {j * i}\t", end='')# 外层循环可以通过print输出一个回车符print()
四、函数
4.1 函数参数
"""
演示函数的定义语法
"""# 定义一个函数,输出相关信息
def say_hi():print("Hi 我是黑马程序员,学Python来黑马")# 调用函数,让定义的函数开始工作
say_hi()"""
演示函数使用参数
"""# 定义2数相加的函数,通过参数接收被计算的2个数字
def add(x, y, z):result = x + y + zprint(f"{x} + {y} + {z}的计算结果是:{result}")# 调用函数,传入被计算的2个数字
add(5, 6, 7)"""
演示函数的参数练习案例:升级自动查核酸
"""# 定义函数,接收1个形式参数,数字类型,表示体温
def check(num):# 在函数体内进行判断体温print("欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!")if num <= 37.5:print(f"体温测量中,您的体温是:{num}度,体温正常请进!")else:print(f"体温测量中,您的体温是:{num}度,需要隔离!")# 调用函数,传入实际参数
check(37.6)
4.2 函数的返回值定义语法
"""
演示:定义函数返回值的语法格式
"""# 定义一个函数,完成2数相加功能
def add(a, b):result = a + b# 通过返回值,将相加的结果返回给调用者return result# 返回结果后,还想输出一句话print("我完事了")# 函数的返回值,可以通过变量去接收
r = add(5, 6)
print(r)"""
演示特殊字面量:None
"""
# 无return语句的函数返回值
def say_hi():print("你好呀")result = say_hi()
print(f"无返回值函数,返回的内容是:{result}")
print(f"无返回值函数,返回的内容类型是:{type(result)}")# 主动返回None的函数
def say_hi2():print("你好呀")return Noneresult = say_hi2()
print(f"无返回值函数,返回的内容是:{result}")
print(f"无返回值函数,返回的内容类型是:{type(result)}")
# None用于if判断
def check_age(age):if age > 18:return "SUCCESS"else:return Noneresult = check_age(16)
if not result:# 进入if表示result是None值 也就是Falseprint("未成年,不可以进入")# None用于声明无初始内容的变量
name = None
4.3 函数说明文档
"""
演示对函数进行文档说明
"""# 定义函数,进行文档说明
def add(x, y):"""add函数可以接收2个参数,进行2数相加的功能:param x: 形参x表示相加的其中一个数字:param y: 形参y表示相加的另一个数字:return: 返回值是2数相加的结果"""result = x + yprint(f"2数相加的结果是:{result}")return resultadd(5, 6)
4.4 函数嵌套调用
"""
演示嵌套调用函数
"""# 定义函数func_b
def func_b():print("---2---")
# 定义函数func_a,并在内部调用func_b
def func_a():print("---1---")# 嵌套调用func_bfunc_b()print("---3---")
# 调用函数func_a
func_a()
4.5 变量的作用域
"""
演示在函数使用的时候,定义的变量作用域
"""# 演示局部变量
# def test_a():
# num = 100
# print(num)
#
#
# test_a()
# 出了函数体,局部变量就无法使用了
# print(num)# 演示全局变量
# num = 200
#
# def test_a():
# print(f"test_a: {num}")
#
# def test_b():
# print(f"test_b: {num}")
#
# test_a()
# test_b()
# print(num)# 在函数内修改全局变量
# num = 200
#
# def test_a():
# print(f"test_a: {num}")
#
# def test_b():
# num = 500 # 局部变量
# print(f"test_b: {num}")
#
# test_a()
# test_b()
# print(num)# global关键字,在函数内声明变量为全局变量
num = 200def test_a():print(f"test_a: {num}")def test_b():global num # 设置内部定义的变量为全局变量num = 500print(f"test_b: {num}")test_a()
test_b()
print(num)
4.6 综合案例
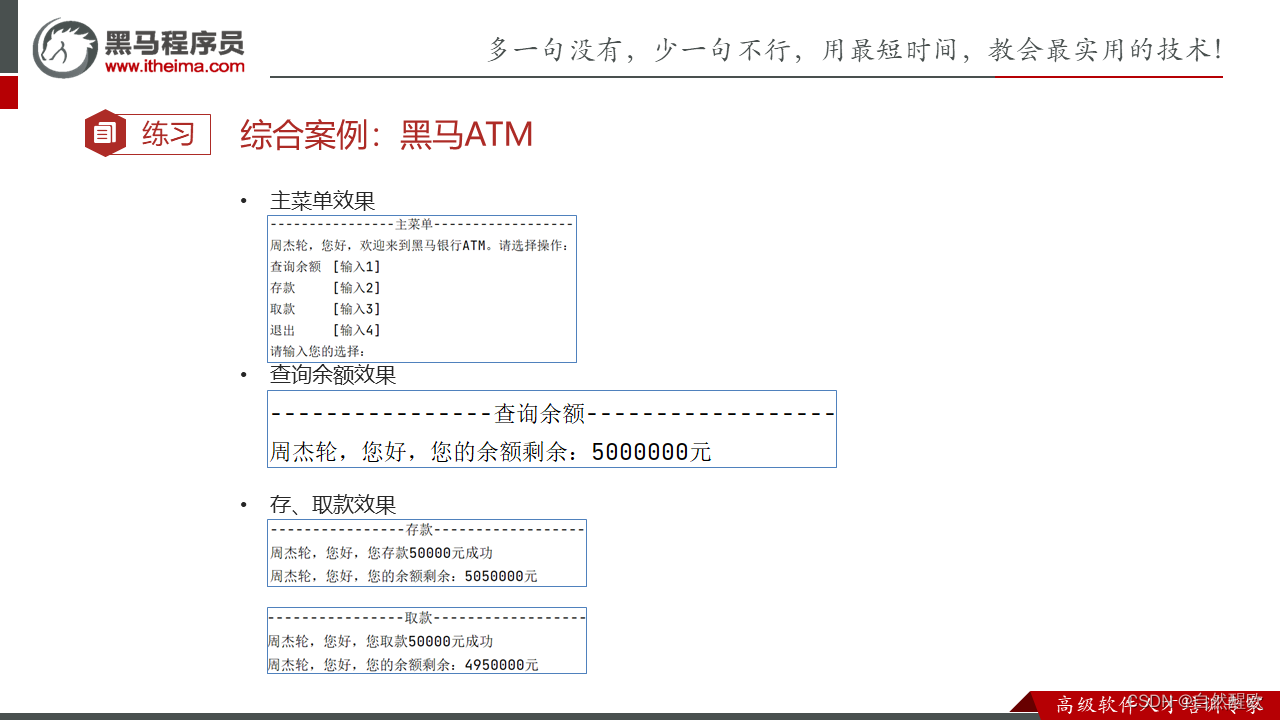

"""
演示函数综合案例开发
"""# 定义全局变量money name
money = 5000000
name = None
# 要求客户输入姓名
name = input("请输入您的姓名:")
# 定义查询函数
def query(show_header):if show_header:print("-------------查询余额------------")print(f"{name},您好,您的余额剩余:{money}元")# 定义存款函数
def saving(num):global money # money在函数内部定义为全局变量money += numprint("-------------存款------------")print(f"{name},您好,您存款{num}元成功。")# 调用query函数查询余额query(False)# 定义取款函数
def get_money(num):global moneymoney -= numprint("-------------取款------------")print(f"{name},您好,您取款{num}元成功。")# 调用query函数查询余额query(False)
# 定义主菜单函数
def main():print("-------------主菜单------------")print(f"{name},您好,欢迎来到黑马银行ATM。请选择操作:")print("查询余额\t[输入1]")print("存款\t\t[输入2]")print("取款\t\t[输入3]") # 通过\t制表符对齐输出print("退出\t\t[输入4]")return input("请输入您的选择:")# 设置无限循环,确保程序不退出
while True:keyboard_input = main()if keyboard_input == "1":query(True)continue # 通过continue继续下一次循环,一进来就是回到了主菜单elif keyboard_input == "2":num = int(input("您想要存多少钱?请输入:"))saving(num)continueelif keyboard_input == "3":num = int(input("您想要取多少钱?请输入:"))get_money(num)continueelse:print("程序退出啦")break # 通过break退出循环
五、函数进阶
5.1 函数的多返回值
"""
演示函数的多返回值示例
"""# 演示使用多个变量,接收多个返回值
def test_return():return 1, "hello", Truex, y, z = test_return()
print(x)
print(y)
print(z)
5.2 函数参数的多种使用形式
"""
演示多种传参的形式
"""
def user_info(name, age, gender):print(f"姓名是:{name}, 年龄是:{age}, 性别是:{gender}")
# 位置参数 - 默认使用形式
user_info('小明', 20, '男')# 关键字参数
user_info(name='小王', age=11, gender='女')
user_info(age=10, gender='女', name='潇潇') # 可以不按照参数的定义顺序传参
user_info('甜甜', gender='女', age=9)# 缺省参数(默认值)
def user_info(name, age, gender):print(f"姓名是:{name}, 年龄是:{age}, 性别是:{gender}")user_info('小天', 13, '男')# 不定长 - 位置不定长, *号
# 不定长定义的形式参数会作为元组存在,接收不定长数量的参数传入
def user_info(*args):print(f"args参数的类型是:{type(args)},内容是:{args}")user_info(1, 2, 3, '小明', '男孩')# 不定长 - 关键字不定长, **号
def user_info(**kwargs):print(f"args参数的类型是:{type(kwargs)},内容是:{kwargs}")
user_info(name='小王', age=11, gender='男孩')
5.3 函数作为参数传递
"""
演示函数作为参数传递
"""# 定义一个函数,接收另一个函数作为传入参数
def test_func(compute):result = compute(1, 2) # 确定compute是函数print(f"compute参数的类型是:{type(compute)}")print(f"计算结果:{result}")# 定义一个函数,准备作为参数传入另一个函数
def compute(x, y):return x + y
# 调用,并传入函数
test_func(compute)
5.4 lambda匿名函数
"""
演示lambda匿名函数
"""# 定义一个函数,接受其它函数输入
def test_func(compute):result = compute(1, 2)print(f"结果是:{result}")
# 通过lambda匿名函数的形式,将匿名函数作为参数传入
def add(x, y):return x + y
test_func(add)
test_func(lambda x, y: x + y)
六、数据容器
6.1 list列表
"""
演示数据容器之:list列表
语法:[元素,元素,....]
"""
# 定义一个列表 list
my_list = ["itheima", "itcast", "python"]
print(my_list)
print(type(my_list))my_list = ["itheima", 666, True]
print(my_list)
print(type(my_list))# 定义一个嵌套的列表
my_list = [ [1, 2, 3], [4, 5, 6]]
print(my_list)
print(type(my_list))# 通过下标索引取出对应位置的数据
my_list = ["Tom", "Lily", "Rose"]
# 列表[下标索引], 从前向后从0开始,每次+1, 从后向前从-1开始,每次-1
print(my_list[0])
print(my_list[1])
print(my_list[2])
# 错误示范;通过下标索引取数据,一定不要超出范围
# print(my_list[3])# 通过下标索引取出数据(倒序取出)
print(my_list[-1])
print(my_list[-2])
print(my_list[-3])# 取出嵌套列表的元素
my_list = [ [1, 2, 3], [4, 5, 6]]
print(my_list[1][1])
6.2 list列表的常用操作
"""
演示数据容器之:list列表的常用操作
"""
mylist = ["itcast", "itheima", "python"]
# 1.1 查找某元素在列表内的下标索引
index = mylist.index("itheima")
print(f"itheima在列表中的下标索引值是:{index}")
# 1.2如果被查找的元素不存在,会报错
# index = mylist.index("hello")
# print(f"hello在列表中的下标索引值是:{index}")# 2. 修改特定下标索引的值
mylist[0] = "传智教育"
print(f"列表被修改元素值后,结果是:{mylist}")
# 3. 在指定下标位置插入新元素
mylist.insert(1, "best")
print(f"列表插入元素后,结果是:{mylist}")
# 4. 在列表的尾部追加```单个```新元素
mylist.append("黑马程序员")
print(f"列表在追加了元素后,结果是:{mylist}")
# 5. 在列表的尾部追加```一批```新元素
mylist2 = [1, 2, 3]
mylist.extend(mylist2)
print(f"列表在追加了一个新的列表后,结果是:{mylist}")
# 6. 删除指定下标索引的元素(2种方式)
mylist = ["itcast", "itheima", "python"]# 6.1 方式1:del 列表[下标]
del mylist[2]
print(f"列表删除元素后结果是:{mylist}")
# 6.2 方式2:列表.pop(下标)
mylist = ["itcast", "itheima", "python"]
element = mylist.pop(2)
print(f"通过pop方法取出元素后列表内容:{mylist}, 取出的元素是:{element}")
# 7. 删除某元素在列表中的第一个匹配项
mylist = ["itcast", "itheima", "itcast", "itheima", "python"]
mylist.remove("itheima")
print(f"通过remove方法移除元素后,列表的结果是:{mylist}")# 8. 清空列表
mylist.clear()
print(f"列表被清空了,结果是:{mylist}")
# 9. 统计列表内某元素的数量
mylist = ["itcast", "itheima", "itcast", "itheima", "python"]
count = mylist.count("itheima")
print(f"列表中itheima的数量是:{count}")# 10. 统计列表中全部的元素数量
mylist = ["itcast", "itheima", "itcast", "itheima", "python"]
count = len(mylist)
print(f"列表的元素数量总共有:{count}个")"""
演示使用while和for循环遍历列表
"""
def list_while_func():"""使用while循环遍历列表的演示函数:return: None"""mylist = ["传智教育", "黑马程序员", "Python"]# 循环控制变量:通过下标索引来控制,默认是0# 每一次循环,将下标索引变量+1# 循环条件:下标索引变量 < 列表的元素数量# 定义一个变量,用来标记列表的下标index = 0 # 初始下标为0while index < len(mylist):# 通过index变量取出对应下标的元素element = mylist[index]print(f"列表的元素:{element}")# 至关重要:将循环变量(index)每一次循环都+1index += 1def list_for_func():"""使用for循环遍历列表的演示函数:return:"""mylist = [1, 2, 3, 4, 5]# for 临时变量 in 数据容器:for element in mylist:print(f"列表的元素有:{element}")if __name__ == '__main__':# list_while_func()list_for_func()6.3 tuple元组的定义和操作
"""
演示tuple元组的定义和操作
"""# 定义元组
t1 = (1, "Hello", True)
t2 = ()
t3 = tuple()
print(f"t1的类型是:{type(t1)}, 内容是:{t1}")
print(f"t2的类型是:{type(t2)}, 内容是:{t2}")
print(f"t3的类型是:{type(t3)}, 内容是:{t3}")# 定义单个元素的元素
t4 = ("hello", )
print(f"t4的类型是:{type(t4)}, t4的内容是:{t4}")
# 元组的嵌套
t5 = ( (1, 2, 3), (4, 5, 6) )
print(f"t5的类型是:{type(t5)}, 内容是:{t5}")# 下标索引去取出内容
num = t5[1][2]
print(f"从嵌套元组中取出的数据是:{num}")# 元组的操作:index查找方法
t6 = ("传智教育", "黑马程序员", "Python")
index = t6.index("黑马程序员")
print(f"在元组t6中查找黑马程序员,的下标是:{index}")
# 元组的操作:count统计方法
t7 = ("传智教育", "黑马程序员", "黑马程序员", "黑马程序员", "Python")
num = t7.count("黑马程序员")
print(f"在元组t7中统计黑马程序员的数量有:{num}个")
# 元组的操作:len函数统计元组元素数量
t8 = ("传智教育", "黑马程序员", "黑马程序员", "黑马程序员", "Python")
num = len(t8)
print(f"t8元组中的元素有:{num}个")
# 元组的遍历:while
index = 0
while index < len(t8):print(f"元组的元素有:{t8[index]}")# 至关重要index += 1# 元组的遍历:for
for element in t8:print(f"2元组的元素有:{element}")# 修改元组内容
# t8[0] = "itcast"# 定义一个元组
t9 = (1, 2, ["itheima", "itcast"])
print(f"t9的内容是:{t9}")
t9[2][0] = "黑马程序员"
t9[2][1] = "传智教育"
print(f"t9的内容是:{t9}")
6.4 字符串
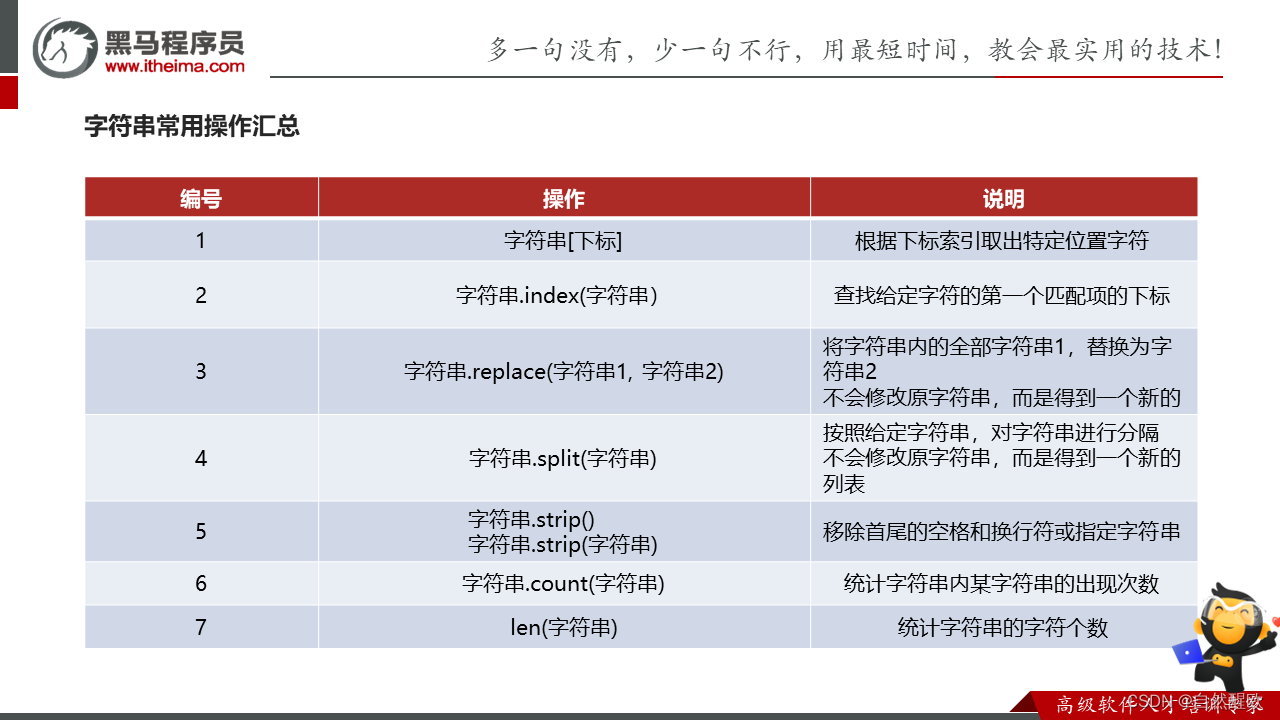
"""
演示以数据容器的角色,学习字符串的相关操作
"""
my_str = "itheima and itcast"
# 通过下标索引取值
value = my_str[2]
value2 = my_str[-16]
print(f"从字符串{my_str}取下标为2的元素,。值是:{value},取下标为-16的元素。值是:{value2}")# my_str[2] = "H"# index方法
value = my_str.index("and")
print(f"在字符串{my_str}中查找and,其起始下标是:{value}")# replace方法
new_my_str = my_str.replace("it", "程序")
print(f"将字符串{my_str},进行替换后得到:{new_my_str}")# split方法
my_str = "hello python itheima itcast"
my_str_list = my_str.split(" ")
print(f"将字符串{my_str}进行split切分后得到:{my_str_list}, 类型是:{type(my_str_list)}")# strip方法
my_str = " itheima and itcast "
new_my_str = my_str.strip() # 不传入参数,去除首尾空格
print(f"字符串{my_str}被strip后,结果:{new_my_str}")my_str = "12itheima and itcast21"
new_my_str = my_str.strip("12")
print(f"字符串{my_str}被strip('12')后,结果:{new_my_str}")# 统计字符串中某字符串的出现次数, count
my_str = "itheima and itcast"
count = my_str.count("it")
print(f"字符串{my_str}中it出现的次数是:{count}")
# 统计字符串的长度, len()
num = len(my_str)
print(f"字符串{my_str}的长度是:{num}")
6.5 序列和切片

"""
演示对序列进行切片操作
"""# 对list进行切片,从1开始,4结束,步长1
my_list = [0, 1, 2, 3, 4, 5, 6]
result1 = my_list[1:4] # 步长默认是1,所以可以省略不写
print(f"结果1:{result1}")# 对tuple进行切片,从头开始,到最后结束,步长1
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result2 = my_tuple[:] # 起始和结束不写表示从头到尾,步长为1可以省略
print(f"结果2:{result2}")# 对str进行切片,从头开始,到最后结束,步长2
my_str = "01234567"
result3 = my_str[::2]
print(f"结果3:{result3}")# 对str进行切片,从头开始,到最后结束,步长-1
my_str = "01234567"
result4 = my_str[::-1] # 等同于将序列反转了
print(f"结果4:{result4}")# 对列表进行切片,从3开始,到1结束,步长-1
my_list = [0, 1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1]
print(f"结果5:{result5}")# 对元组进行切片,从头开始,到尾结束,步长-2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result6 = my_tuple[::-2]
print(f"结果6:{result6}")
6.6 集合
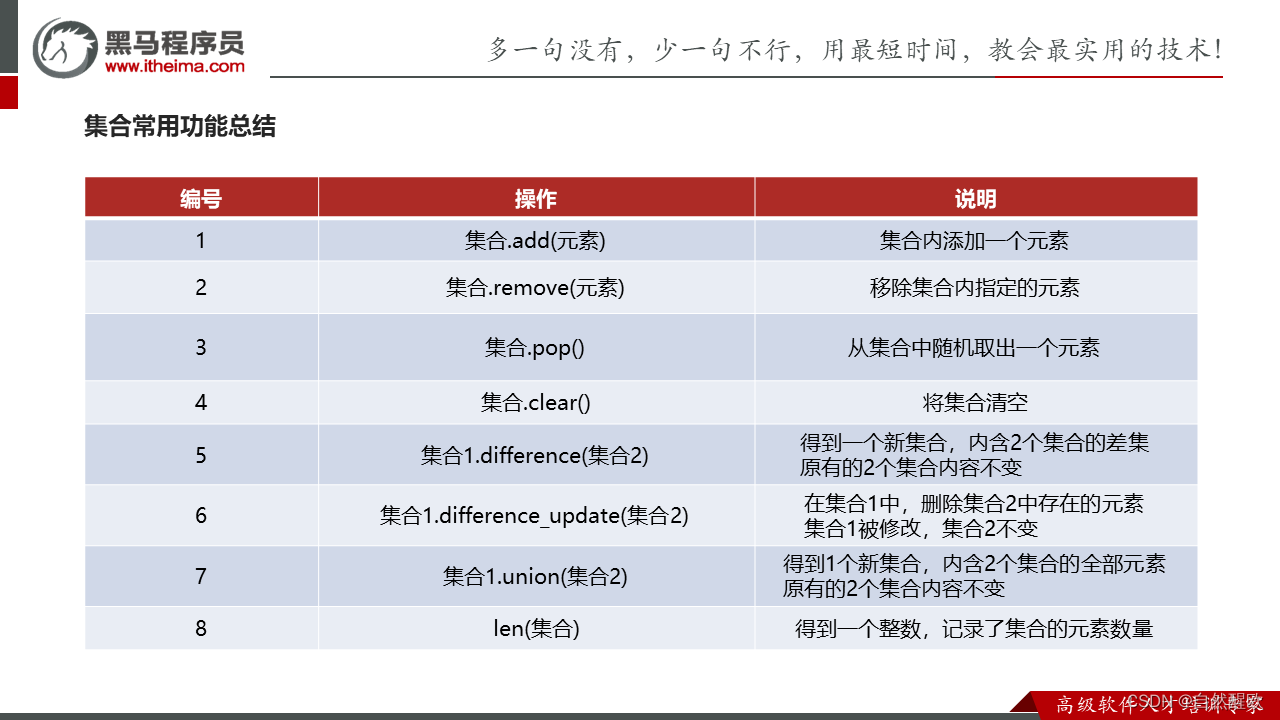
"""
演示数据容器集合的使用
"""# 定义集合
my_set = {"传智教育", "黑马程序员", "itheima", "传智教育", "黑马程序员", "itheima", "传智教育", "黑马程序员", "itheima"}
my_set_empty = set() # 定义空集合
print(f"my_set的内容是:{my_set}, 类型是:{type(my_set)}")
print(f"my_set_empty的内容是:{my_set_empty}, 类型是:{type(my_set_empty)}")# 添加新元素
my_set.add("Python")
my_set.add("传智教育") #
print(f"my_set添加元素后结果是:{my_set}")
# 移除元素
my_set.remove("黑马程序员")
print(f"my_set移除黑马程序员后,结果是:{my_set}")
# 随机取出一个元素
my_set = {"传智教育", "黑马程序员", "itheima"}
element = my_set.pop()
print(f"集合被取出元素是:{element}, 取出元素后:{my_set}")# 清空集合, clear
my_set.clear()
print(f"集合被清空啦,结果是:{my_set}")# 取2个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2)
print(f"取出差集后的结果是:{set3}")
print(f"取差集后,原有set1的内容:{set1}")
print(f"取差集后,原有set2的内容:{set2}")# 消除2个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2)
print(f"消除差集后,集合1结果:{set1}")
print(f"消除差集后,集合2结果:{set2}")# 2个集合合并为1个
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2)
print(f"2集合合并结果:{set3}")
print(f"合并后集合1:{set1}")
print(f"合并后集合2:{set2}")# 统计集合元素数量len()
set1 = {1, 2, 3, 4, 5, 1, 2, 3, 4, 5}
num = len(set1)
print(f"集合内的元素数量有:{num}个")# 集合的遍历
# 集合不支持下标索引,不能用while循环
# 可以用for循环
set1 = {1, 2, 3, 4, 5}
for element in set1:print(f"集合的元素有:{element}")
6.7 字典
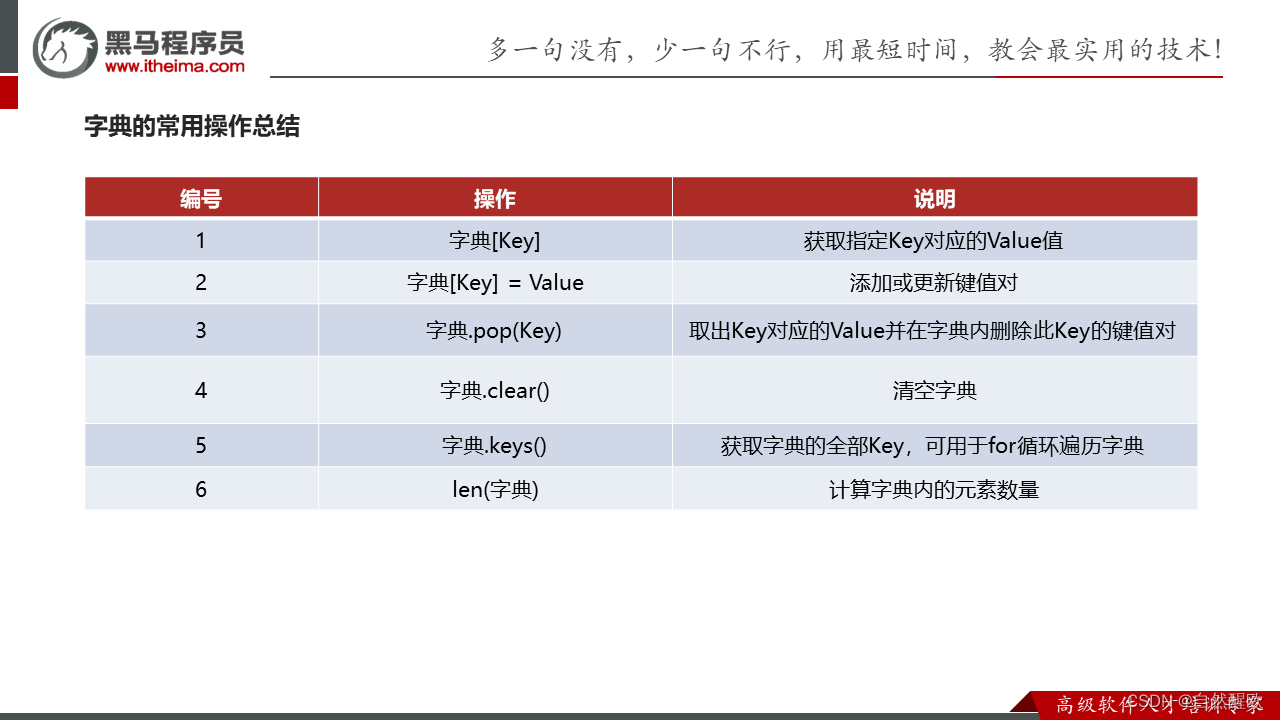
"""
演示数据容器字典的定义
"""# 定义字典
my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77}
# 定义空字典
my_dict2 = {}
my_dict3 = dict()
print(f"字典1的内容是:{my_dict1}, 类型:{type(my_dict1)}")
print(f"字典2的内容是:{my_dict2}, 类型:{type(my_dict2)}")
print(f"字典3的内容是:{my_dict3}, 类型:{type(my_dict3)}")# 定义重复Key的字典
my_dict1 = {"王力鸿": 99, "王力鸿": 88, "林俊节": 77}
print(f"重复key的字典的内容是:{my_dict1}")# 从字典中基于Key获取Value
my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77}
score = my_dict1["王力鸿"]
print(f"王力鸿的考试分数是:{score}")
score = my_dict1["周杰轮"]
print(f"周杰轮的考试分数是:{score}")
# 定义嵌套字典
stu_score_dict = {"王力鸿": {"语文": 77,"数学": 66,"英语": 33}, "周杰轮": {"语文": 88,"数学": 86,"英语": 55}, "林俊节": {"语文": 99,"数学": 96,"英语": 66}
}
print(f"学生的考试信息是:{stu_score_dict}")# 从嵌套字典中获取数据
# 看一下周杰轮的语文信息
score = stu_score_dict["周杰轮"]["语文"]
print(f"周杰轮的语文分数是:{score}")
score = stu_score_dict["林俊节"]["英语"]
print(f"林俊节的英语分数是:{score}")
6.8 字典的常用操作
"""
演示字典的常用操作
"""
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77}
# 新增元素
my_dict["张信哲"] = 66
print(f"字典经过新增元素后,结果:{my_dict}")
# 更新元素
my_dict["周杰轮"] = 33
print(f"字典经过更新后,结果:{my_dict}")
# 删除元素
score = my_dict.pop("周杰轮")
print(f"字典中被移除了一个元素,结果:{my_dict}, 周杰轮的考试分数是:{score}")# 清空元素, clear
my_dict.clear()
print(f"字典被清空了,内容是:{my_dict}")# 获取全部的key
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77}
keys = my_dict.keys()
print(f"字典的全部keys是:{keys}")
# 遍历字典
# 方式1:通过获取到全部的key来完成遍历
for key in keys:print(f"字典的key是:{key}")print(f"字典的value是:{my_dict[key]}")# 方式2:直接对字典进行for循环,每一次循环都是直接得到key
for key in my_dict:print(f"2字典的key是:{key}")print(f"2字典的value是:{my_dict[key]}")# 统计字典内的元素数量, len()函数
num = len(my_dict)
print(f"字典中的元素数量有:{num}个")
6.9 数据容器通用功能


"""
演示数据容器的通用功能
"""
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}# len元素个数
print(f"列表 元素个数有:{len(my_list)}")
print(f"元组 元素个数有:{len(my_tuple)}")
print(f"字符串元素个数有:{len(my_str)}")
print(f"集合 元素个数有:{len(my_set)}")
print(f"字典 元素个数有:{len(my_dict)}")# max最大元素
print(f"列表 最大的元素是:{max(my_list)}")
print(f"元组 最大的元素是:{max(my_tuple)}")
print(f"字符串最大的元素是:{max(my_str)}")
print(f"集合 最大的元素是:{max(my_set)}")
print(f"字典 最大的元素是:{max(my_dict)}")
# min最小元素
print(f"列表 最小的元素是:{min(my_list)}")
print(f"元组 最小的元素是:{min(my_tuple)}")
print(f"字符串最小的元素是:{min(my_str)}")
print(f"集合 最小的元素是:{min(my_set)}")
print(f"字典 最小的元素是:{min(my_dict)}")
# 类型转换: 容器转列表
print(f"列表转列表的结果是:{list(my_list)}")
print(f"元组转列表的结果是:{list(my_tuple)}")
print(f"字符串转列表结果是:{list(my_str)}")
print(f"集合转列表的结果是:{list(my_set)}")
print(f"字典转列表的结果是:{list(my_dict)}")
# 类型转换: 容器转元组
print(f"列表转元组的结果是:{tuple(my_list)}")
print(f"元组转元组的结果是:{tuple(my_tuple)}")
print(f"字符串转元组结果是:{tuple(my_str)}")
print(f"集合转元组的结果是:{tuple(my_set)}")
print(f"字典转元组的结果是:{tuple(my_dict)}")
# 类型转换: 容器转字符串
print(f"列表转字符串的结果是:{str(my_list)}")
print(f"元组转字符串的结果是:{str(my_tuple)}")
print(f"字符串转字符串结果是:{str(my_str)}")
print(f"集合转字符串的结果是:{str(my_set)}")
print(f"字典转字符串的结果是:{str(my_dict)}")
# 类型转换: 容器转集合
print(f"列表转集合的结果是:{set(my_list)}")
print(f"元组转集合的结果是:{set(my_tuple)}")
print(f"字符串转集合结果是:{set(my_str)}")
print(f"集合转集合的结果是:{set(my_set)}")
print(f"字典转集合的结果是:{set(my_dict)}")
# 进行容器的排序
my_list = [3, 1, 2, 5, 4]
my_tuple = (3, 1, 2, 5, 4)
my_str = "bdcefga"
my_set = {3, 1, 2, 5, 4}
my_dict = {"key3": 1, "key1": 2, "key2": 3, "key5": 4, "key4": 5}print(f"列表对象的排序结果:{sorted(my_list)}")
print(f"元组对象的排序结果:{sorted(my_tuple)}")
print(f"字符串对象的排序结果:{sorted(my_str)}")
print(f"集合对象的排序结果:{sorted(my_set)}")
print(f"字典对象的排序结果:{sorted(my_dict)}")print(f"列表对象的反向排序结果:{sorted(my_list, reverse=True)}")
print(f"元组对象的反向排序结果:{sorted(my_tuple, reverse=True)}")
print(f"字符串对象反向的排序结果:{sorted(my_str, reverse=True)}")
print(f"集合对象的反向排序结果:{sorted(my_set, reverse=True)}")
print(f"字典对象的反向排序结果:{sorted(my_dict, reverse=True)}")
6.10 字符串大小比较
"""
演示字符串大小比较
"""# abc 比较 abd
print(f"abd大于abc,结果:{'abd' > 'abc'}")
# a 比较 ab
print(f"ab大于a,结果:{'ab' > 'a'}")
# a 比较 A
print(f"a 大于 A,结果:{'a' > 'A'}")
# key1 比较 key2
print(f"key2 > key1,结果:{'key2' > 'key1'}")
七、文件操作
7.1 文件的读取

"""
演示对文件的读取
"""# 打开文件
import timef = open("D:/测试.txt", "r", encoding="UTF-8")
print(type(f))
# 读取文件 - read()
# print(f"读取10个字节的结果:{f.read(10)}")
# print(f"read方法读取全部内容的结果是:{f.read()}")
print("-----------------------------------------------")
# 读取文件 - readLines()
# lines = f.readlines() # 读取文件的全部行,封装到列表中
# print(f"lines对象的类型:{type(lines)}")
# print(f"lines对象的内容是:{lines}")# 读取文件 - readline()
# line1 = f.readline()
# line2 = f.readline()
# line3 = f.readline()
# print(f"第一行数据是:{line1}")
# print(f"第二行数据是:{line2}")
# print(f"第三行数据是:{line3}")# for循环读取文件行
# for line in f:
# print(f"每一行数据是:{line}")
# # 文件的关闭
# f.close()
# time.sleep(500000)
# with open 语法操作文件
with open("D:/测试.txt", "r", encoding="UTF-8") as f:for line in f:print(f"每一行数据是:{line}")time.sleep(500000)
"""
演示读取文件,课后练习题
"""# 打开文件,以读取模式打开
f = open("D:/word.txt", "r", encoding="UTF-8")
# 方式1:读取全部内容,通过字符串count方法统计itheima单词数量
# content = f.read()
# count = content.count("itheima")
# print(f"itheima在文件中出现了:{count}次")
# 方式2:读取内容,一行一行读取
count = 0 # 使用count变量来累计itheima出现的次数
for line in f:line = line.strip() # 去除开头和结尾的空格以及换行符words = line.split(" ")for word in words:if word == "itheima":count += 1 # 如果单词是itheima,进行数量的累加加1
# 判断单词出现次数并累计
print(f"itheima出现的次数是:{count}")
# 关闭文件
f.close()
7.2 文件的写入
"""
演示文件的写入
"""# 打开文件,不存在的文件, r, w, a
import time
# “w”模式,会将原有的内容清空# f = open("D:/test.txt", "w", encoding="UTF-8")
# # write写入
# f.write("Hello World!!!") # 内容写入到内存中
# # flush刷新
# # f.flush() # 将内存中积攒的内容,写入到硬盘的文件中
# # close关闭
# f.close() # close方法,内置了flush的功能的
# 打开一个存在的文件
f = open("D:/test.txt", "w", encoding="UTF-8")
# write写入、flush刷新
f.write("黑马程序员")
# close关闭
f.close()
7.3 文件的追加
"""
演示文件的追加写入
"""# 打开文件,不存在的文件
# f = open("D:/test.txt", "a", encoding="UTF-8")
# # write写入
# f.write("黑马程序员")
# # flush刷新
# f.flush()
# # close关闭
# f.close()
# 打开一个存在的文件
f = open("D:/test.txt", "a", encoding="UTF-8")
# write写入、flush刷新
f.write("\n月薪过万")
# close关闭
f.close()
7.4 文件操作的综合案例


"""
演示文件操作综合案例:文件备份
"""# 打开文件得到文件对象,准备读取
fr = open("D:/bill.txt", "r", encoding="UTF-8")
# 打开文件得到文件对象,准备写入
fw = open("D:/bill.txt.bak", "w", encoding="UTF-8")
# for循环读取文件
for line in fr:line = line.strip()# 判断内容,将满足的内容写出if line.split(",")[4] == "测试":continue # continue进入下一次循环,这一次后面的内容就跳过了# 将内容写出去fw.write(line)# 由于前面对内容进行了strip()的操作,所以要手动的写出换行符fw.write("\n")# close2个文件对象
fr.close()
fw.close() # 写出文件调用close()会自动flush()
八、异常_模块_包
8.1 异常的捕获
"""
演示捕获异常
"""# 基本捕获语法
# try:
# f = open("D:/abc.txt", "r", encoding="UTF-8")
# except:
# print("出现异常了,因为文件不存在,我将open的模式,改为w模式去打开")
# f = open("D:/abc.txt", "w", encoding="UTF-8")# 捕获指定的异常
# try:
# print(name)
# # 1 / 0
# except NameError as e:
# print("出现了变量未定义的异常")
# print(e)
# 捕获多个异常
# try:
# # 1 / 0
# print(name)
# except (NameError, ZeroDivisionError) as e:
# print("出现了变量未定义 或者 除以0的异常错误")
# 未正确设置捕获异常类型,将无法捕获异常# 捕获所有异常
try:f = open("D:/123.txt", "r", encoding="UTF-8")
except Exception as e:print("出现异常了")f = open("D:/123.txt", "w", encoding="UTF-8")
else:print("好高兴,没有异常。")
finally:print("我是finally,有没有异常我都要执行")f.close()8.2 异常的传递
"""
演示异常的传递性
"""# 定义一个出现异常的方法
def func1():print("func1 开始执行")num = 1 / 0 # 肯定有异常,除以0的异常print("func1 结束执行")
# 定义一个无异常的方法,调用上面的方法def func2():print("func2 开始执行")func1()print("func2 结束执行")
# 定义一个方法,调用上面的方法def main():try:func2()except Exception as e:print(f"出现异常了,异常的信息是:{e}")main()
8.3 模块的导入

"""
演示Python的模块导入
"""from time import sleep# 使用import导入time模块使用sleep功能(函数)
# import time # 导入Python内置的time模块(time.py这个代码文件)
# print("你好")
# time.sleep(5) # 通过. 就可以使用模块内部的全部功能(类、函数、变量)
# print("我好")# 使用from导入time的sleep功能(函数)
# from time import sleep
# print("你好")
# sleep(5)
# print("我好")# 使用 * 导入time模块的全部功能
# from time import * # *表示全部的意思
# print("你好")
# sleep(5)
# print("我好")# 使用as给特定功能加上别名
# import time as t
# print("你好")
# t.sleep(5)
# print("我好")from time import sleep as sl
print("你好")
sl(5)
print("我好")
8.4 自定义模块
"""
演示自定义模块
"""
# 导入自定义模块使用
# import my_module1
# from my_module1 import test
# test(1, 2)# 导入不同模块的同名功能
# from my_module1 import test
# from my_module2 import test
# test(1, 2)
# __main__变量
# from my_module1 import test# __all__变量
from my_module1 import *
test_a(1, 2)
# test_b(2, 1)
8.5 包
"""
演示Python的包
"""# 创建一个包
# 导入自定义的包中的模块,并使用
# import my_package.my_module1
# import my_package.my_module2
#
# my_package.my_module1.info_print1()
# my_package.my_module2.info_print2()# from my_package import my_module1
# from my_package import my_module2
# my_module1.info_print1()
# my_module2.info_print2()# from my_package.my_module1 import info_print1
# from my_package.my_module2 import info_print2
# info_print1()
# info_print2()# 通过__all__变量,控制import *
from my_package import *
my_module1.info_print1()
my_module2.info_print2()
8.5.1 __init__py
__all__ = ['my_module1']
8.5.2 my_module1.py
"""
演示自定义模块1
"""def info_print1():print("我是模块1的功能函数代码")8.5.3 my_module2.py
"""
自定义模块2
"""def info_print2():print("我是模块2的功能函数代码")8.6 综合案例练习

"""
演示异常、模块、包的综合案例练习
"""
# 创建my_utils 包, 在包内创建:str_util.py 和 file_util.py 2个模块,并提供相应的函数import my_utils.str_util
from my_utils import file_utilprint(my_utils.str_util.str_reverse("黑马程序员"))
print(my_utils.str_util.substr("itheima", 0, 4))file_util.append_to_file("D:/test_append.txt", "itheima")
file_util.print_file_info("D:/test_append.txt")8.6.1 file_util.py
"""
文件处理相关的工具模块
"""def print_file_info(file_name):"""功能是:将给定路径的文件内容输出到控制台中:param file_name: 即将读取的文件路径:return: None"""f = Nonetry:f = open(file_name, "r", encoding="UTF-8")content = f.read()print("文件的全部内容如下:")print(content)except Exception as e:print(f"程序出现异常了,原因是:{e}")finally:if f: # 如果变量是None,表示False,如果有任何内容,就是Truef.close()def append_to_file(file_name, data):"""功能:将指定的数据追加到指定的文件中:param file_name: 指定的文件的路径:param data: 指定的数据:return: None"""f = open(file_name, "a", encoding="UTF-8")f.write(data)f.write("\n")f.close()if __name__ == '__main__':# print_file_info("D:/bill.txtxxx")append_to_file("D:/test_append.txt", "传智教育")
8.6.2 str_util.py
"""
字符串相关的工具模块
"""def str_reverse(s):"""功能是将字符串完成反转:param s: 将被反转的字符串:return: 反转后的字符串"""return s[::-1]def substr(s, x, y):"""功能是按照给定的下标完成给定字符串的切片:param s: 即将被切片的字符串:param x: 切片的开始下标:param y: 切片的结束下标:return: 切片完成后的字符串"""return s[x:y]if __name__ == '__main__':print(str_reverse("黑马程序员"))print(substr("黑马程序员", 1, 3))
九、可视化图表
9.1 JSON数据格式
"""
演示JSON数据和Python字典的相互转换
"""
import json
# 准备列表,列表内每一个元素都是字典,将其转换为JSON
data = [{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 准备字典,将字典转换为JSON
d = {"name":"周杰轮", "addr":"台北"}
json_str = json.dumps(d, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 将JSON字符串转换为Python数据类型[{k: v, k: v}, {k: v, k: v}]
s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]'
l = json.loads(s)
print(type(l))
print(l)
# 将JSON字符串转换为Python数据类型{k: v, k: v}
s = '{"name": "周杰轮", "addr": "台北"}'
d = json.loads(s)
print(type(d))
print(d)
9.2 pyecharts基础入门
"""
演示pyecharts的基础入门
"""
# 导包
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("GDP", [30, 20, 10])# 设置全局配置项set_global_opts来设置,
line.set_global_opts(title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),legend_opts=LegendOpts(is_show=True),toolbox_opts=ToolboxOpts(is_show=True),visualmap_opts=VisualMapOpts(is_show=True),
)# 通过render方法,将代码生成为图像
line.render()
9.3 折线图开发
"""
演示可视化需求1:折线图开发
"""
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts# 处理数据
f_us = open("D:/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容f_jp = open("D:/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 日本的全部内容f_in = open("D:/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 印度的全部内容# 去掉不合JSON规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")# 去掉不合JSON规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]# 获取确认数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]# 生成图表
line = Line() # 构建折线图对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据# 设置全局选项
line.set_global_opts(# 标题设置title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()
9.4 地图可视化的基本使用
"""
演示地图可视化的基本使用
"""
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts# 准备地图对象
map = Map()
# 准备数据
data = [("北京", 99),("上海", 199),("湖南", 299),("台湾", 399),("广东", 499)
]
# 添加数据
map.add("测试地图", data, "china")# 设置全局选项
map.set_global_opts(visualmap_opts=VisualMapOpts(is_show=True,is_piecewise=True,pieces=[{"min": 1, "max": 9, "label": "1-9", "color": "#CCFFFF"},{"min": 10, "max": 99, "label": "10-99", "color": "#FF6666"},{"min": 100, "max": 500, "label": "100-500", "color": "#990033"}])
)# 绘图
map.render()
9.5 全国疫情可视化地图开发
"""
演示全国疫情可视化地图开发
"""
import json
from pyecharts.charts import Map
from pyecharts.options import *# 读取数据文件
f = open("D:/疫情.txt", "r", encoding="UTF-8")
data = f.read() # 全部数据
# 关闭文件
f.close()
# 取到各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data) # 基础数据字典
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图需要用的数据列表
for province_data in province_data_list:province_name = province_data["name"] # 省份名称province_confirm = province_data["total"]["confirm"] # 确诊人数data_list.append((province_name, province_confirm))# 创建地图对象
map = Map()
# 添加数据
map.add("各省份确诊人数", data_list, "china")
# 设置全局配置,定制分段的视觉映射
map.set_global_opts(title_opts=TitleOpts(title="全国疫情地图"),visualmap_opts=VisualMapOpts(is_show=True, # 是否显示is_piecewise=True, # 是否分段pieces=[{"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},{"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},{"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},{"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},{"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},{"min": 100000, "lable": "100000+", "color": "#990033"},])
)
# 绘图
map.render("全国疫情地图.html")
9.6 河南省疫情地图开发
"""
演示河南省疫情地图开发
"""
import json
from pyecharts.charts import Map
from pyecharts.options import *# 读取文件
f = open("D:/疫情.txt", "r", encoding="UTF-8")
data = f.read()
# 关闭文件
f.close()
# 获取河南省数据
# json数据转换为python字典
data_dict = json.loads(data)
# 取到河南省数据
cities_data = data_dict["areaTree"][0]["children"][3]["children"]# 准备数据为元组并放入list
data_list = []
for city_data in cities_data:city_name = city_data["name"] + "市"city_confirm = city_data["total"]["confirm"]data_list.append((city_name, city_confirm))# 手动添加济源市的数据
data_list.append(("济源市", 5))# 构建地图
map = Map()
map.add("河南省疫情分布", data_list, "河南")
# 设置全局选项
map.set_global_opts(title_opts=TitleOpts(title="河南省疫情地图"),visualmap_opts=VisualMapOpts(is_show=True, # 是否显示is_piecewise=True, # 是否分段pieces=[{"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},{"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},{"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},{"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},{"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},{"min": 100000, "lable": "100000+", "color": "#990033"},])
)# 绘图
map.render("河南省疫情地图.html")
9.7 基础柱状图开发
"""
演示基础柱状图的开发
"""
from pyecharts.charts import Bar
from pyecharts.options import LabelOpts
# 使用Bar构建基础柱状图
bar = Bar()
# 添加x轴的数据
bar.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
# 反转x和y轴
bar.reversal_axis()
# 绘图
bar.render("基础柱状图.html")# 反转x轴和y轴# 设置数值标签在右侧
9.8 基础时间线柱状图开发
"""
演示带有时间线的柱状图开发
"""
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts
from pyecharts.globals import ThemeTypebar1 = Bar()
bar1.add_xaxis(["中国", "美国", "英国"])
bar1.add_yaxis("GDP", [30, 30, 20], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()bar2 = Bar()
bar2.add_xaxis(["中国", "美国", "英国"])
bar2.add_yaxis("GDP", [50, 50, 50], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()bar3 = Bar()
bar3.add_xaxis(["中国", "美国", "英国"])
bar3.add_yaxis("GDP", [70, 60, 60], label_opts=LabelOpts(position="right"))
bar3.reversal_axis()# 构建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 在时间线内添加柱状图对象
timeline.add(bar1, "点1")
timeline.add(bar2, "点2")
timeline.add(bar3, "点3")# 自动播放设置
timeline.add_schema(play_interval=1000,is_timeline_show=True,is_auto_play=True,is_loop_play=True
)# 绘图是用时间线对象绘图,而不是bar对象了
timeline.render("基础时间线柱状图.html")
9.9 列表的sort方法
"""
在学习了将函数作为参数传递后,我们可以学习列表的sort方法来对列表进行自定义排序
"""# 准备列表
my_list = [["a", 33], ["b", 55], ["c", 11]]# 排序,基于带名函数
# def choose_sort_key(element):
# return element[1]
#
# my_list.sort(key=choose_sort_key, reverse=True)
# 排序,基于lambda匿名函数
my_list.sort(key=lambda element: element[1], reverse=True)print(my_list)9.10 GDP动态柱状图开发
"""
演示第三个图表:GDP动态柱状图开发
"""
from pyecharts.charts import Bar, Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType# 读取数据
f = open("D:/1960-2019全球GDP数据.csv", "r", encoding="GB2312")
data_lines = f.readlines()
# 关闭文件
f.close()
# 删除第一条数据
data_lines.pop(0)
# 将数据转换为字典存储,格式为:
# { 年份: [ [国家, gdp], [国家,gdp], ...... ], 年份: [ [国家, gdp], [国家,gdp], ...... ], ...... }
# { 1960: [ [美国, 123], [中国,321], ...... ], 1961: [ [美国, 123], [中国,321], ...... ], ...... }
# 先定义一个字典对象
data_dict = {}
for line in data_lines:year = int(line.split(",")[0]) # 年份country = line.split(",")[1] # 国家gdp = float(line.split(",")[2]) # gdp数据# 如何判断字典里面有没有指定的key呢?try:data_dict[year].append([country, gdp])except KeyError:data_dict[year] = []data_dict[year].append([country, gdp])# print(data_dict[1960])
# 创建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 排序年份
sorted_year_list = sorted(data_dict.keys())
for year in sorted_year_list:data_dict[year].sort(key=lambda element: element[1], reverse=True)# 取出本年份前8名的国家year_data = data_dict[year][0:8]x_data = []y_data = []for country_gdp in year_data:x_data.append(country_gdp[0]) # x轴添加国家y_data.append(country_gdp[1] / 100000000) # y轴添加gdp数据# 构建柱状图bar = Bar()x_data.reverse()y_data.reverse()bar.add_xaxis(x_data)bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))# 反转x轴和y轴bar.reversal_axis()# 设置每一年的图表的标题bar.set_global_opts(title_opts=TitleOpts(title=f"{year}年全球前8GDP数据"))timeline.add(bar, str(year))# for循环每一年的数据,基于每一年的数据,创建每一年的bar对象
# 在for中,将每一年的bar对象添加到时间线中# 设置时间线自动播放
timeline.add_schema(play_interval=1000,is_timeline_show=True,is_auto_play=True,is_loop_play=False
)
# 绘图
timeline.render("1960-2019全球GDP前8国家.html")
十、 面向对象
10.1 成员方法
"""
演示面向对象类中的成员方法定义和使用
"""# 定义一个带有成员方法的类
class Student:name = None # 学生的姓名def say_hi(self):print(f"大家好呀,我是{self.name},欢迎大家多多关照")def say_hi2(self, msg):print(f"大家好,我是:{self.name},{msg}")stu = Student()
stu.name = "周杰轮"
stu.say_hi2("哎哟不错哟")stu2 = Student()
stu2.name = "林俊节"
stu2.say_hi2("小伙子我看好你")
10.2 类和对象
"""
演示类和对象的关系,即面向对象的编程套路(思想)
"""# 设计一个闹钟类
class Clock:id = None # 序列化price = None # 价格def ring(self):import winsoundwinsound.Beep(2000, 3000)# 构建2个闹钟对象并让其工作
clock1 = Clock()
clock1.id = "003032"
clock1.price = 19.99
print(f"闹钟ID:{clock1.id},价格:{clock1.price}")
# clock1.ring()clock2 = Clock()
clock2.id = "003033"
clock2.price = 21.99
print(f"闹钟ID:{clock2.id},价格:{clock2.price}")
clock2.ring()
10.3 构造方法
"""
演示类的构造方法
"""
# 演示使用构造方法对成员变量进行赋值
# 构造方法的名称:__init__class Student:def __init__(self, name, age ,tel):self.name = nameself.age = ageself.tel = telprint("Student类创建了一个类对象")stu = Student("周杰轮", 31, "18500006666")
print(stu.name)
print(stu.age)
print(stu.tel)
10.4 其它内置方法

"""
演示Python内置的各类魔术方法
"""class Student:def __init__(self, name, age):self.name = name # 学生姓名self.age = age # 学生年龄# __str__魔术方法def __str__(self):return f"Student类对象,name:{self.name}, age:{self.age}"# __lt__魔术方法def __lt__(self, other):return self.age < other.age# __le__魔术方法def __le__(self, other):return self.age <= other.age# __eq__魔术方法def __eq__(self, other):return self.age == other.agestu1 = Student("周杰轮", 31)
stu2 = Student("林俊节", 36)
print(stu1 == stu2)
10.5 封装
"""
演示面向对象封装思想中私有成员的使用
"""# 定义一个类,内含私有成员变量和私有成员方法
class Phone:__current_voltage = 0.5 # 当前手机运行电压def __keep_single_core(self):print("让CPU以单核模式运行")def call_by_5g(self):if self.__current_voltage >= 1:print("5g通话已开启")else:self.__keep_single_core()print("电量不足,无法使用5g通话,并已设置为单核运行进行省电。")phone = Phone()
phone.call_by_5g()"""
讲解面向对象-封装特性课后练习题
设计带有私有成员的手机
"""
# 设计一个类,用来描述手机
class Phone:# 提供私有成员变量:__is_5g_enable__is_5g_enable = True # 5g状态# 提供私有成员方法:__check_5g()def __check_5g(self):if self.__is_5g_enable:print("5g开启")else:print("5g关闭,使用4g网络")# 提供公开成员方法:call_by_5g()def call_by_5g(self):self.__check_5g()print("正在通话中")phone = Phone()
phone.call_by_5g()
10.6 继承的基础语法
"""
演示面向对象:继承的基础语法
"""# 演示单继承
class Phone:IMEI = None # 序列号producer = "ITCAST" # 厂商def call_by_4g(self):print("4g通话")class Phone2022(Phone):face_id = "10001" # 面部识别IDdef call_by_5g(self):print("2022年新功能:5g通话")phone = Phone2022()
print(phone.producer)
phone.call_by_4g()
phone.call_by_5g()
# 演示多继承
class NFCReader:nfc_type = "第五代"producer = "HM"def read_card(self):print("NFC读卡")def write_card(self):print("NFC写卡")class RemoteControl:rc_type = "红外遥控"def control(self):print("红外遥控开启了")class MyPhone(Phone, NFCReader, RemoteControl):passphone = MyPhone()
phone.call_by_4g()
phone.read_card()
phone.write_card()
phone.control()print(phone.producer)# 演示多继承下,父类成员名一致的场景
10.7 继承_复写和使用父类成员
"""
演示面向对象:继承中
对父类成员的复写和调用
"""class Phone:IMEI = None # 序列号producer = "ITCAST" # 厂商def call_by_5g(self):print("使用5g网络进行通话")# 定义子类,复写父类成员
class MyPhone(Phone):producer = "ITHEIMA" # 复写父类的成员属性def call_by_5g(self):print("开启CPU单核模式,确保通话的时候省电")# 方式1# print(f"父类的厂商是:{Phone.producer}")# Phone.call_by_5g(self)# 方式2print(f"父类的厂商是:{super().producer}")super().call_by_5g()print("关闭CPU单核模式,确保性能")phone = MyPhone()
phone.call_by_5g()
print(phone.producer)# 在子类中,调用父类成员
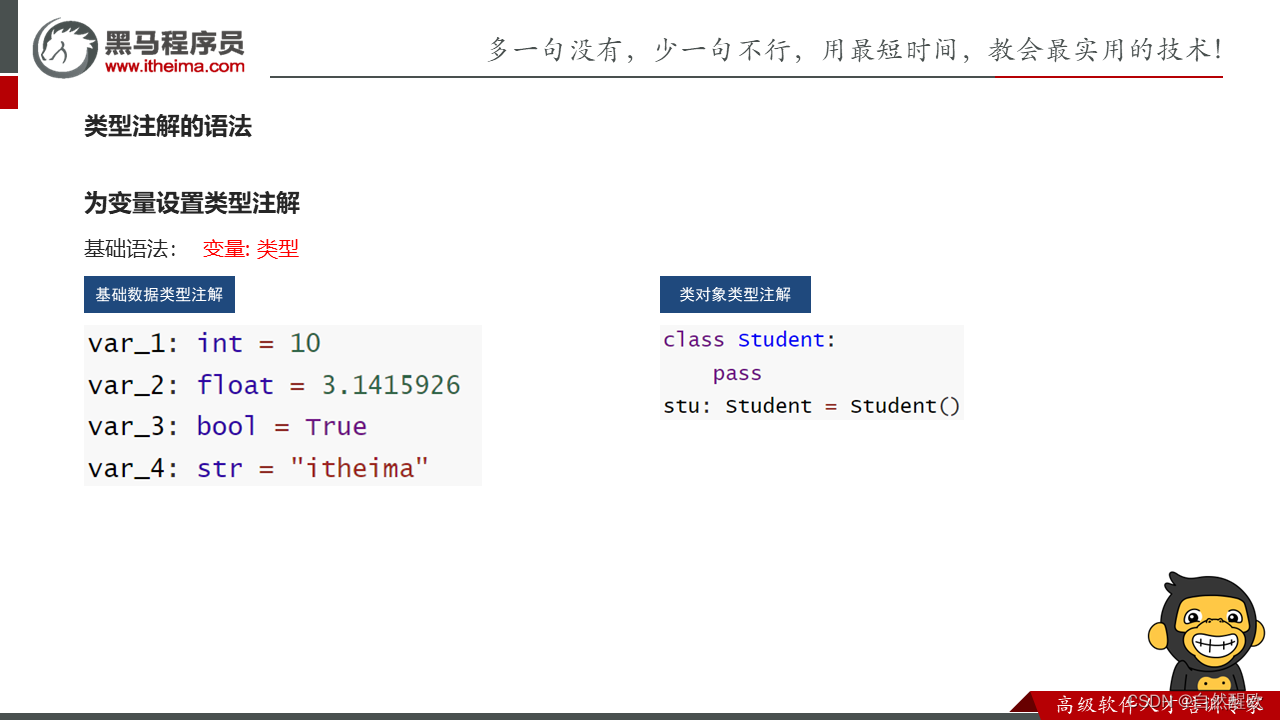
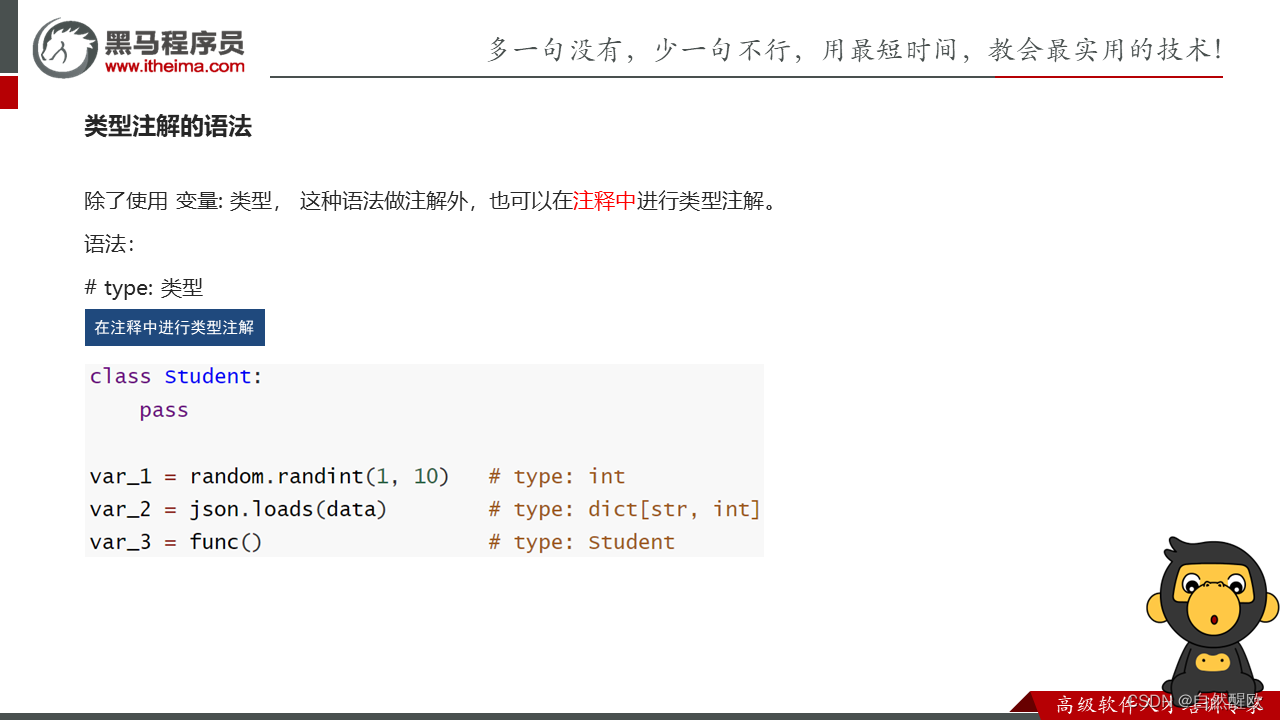
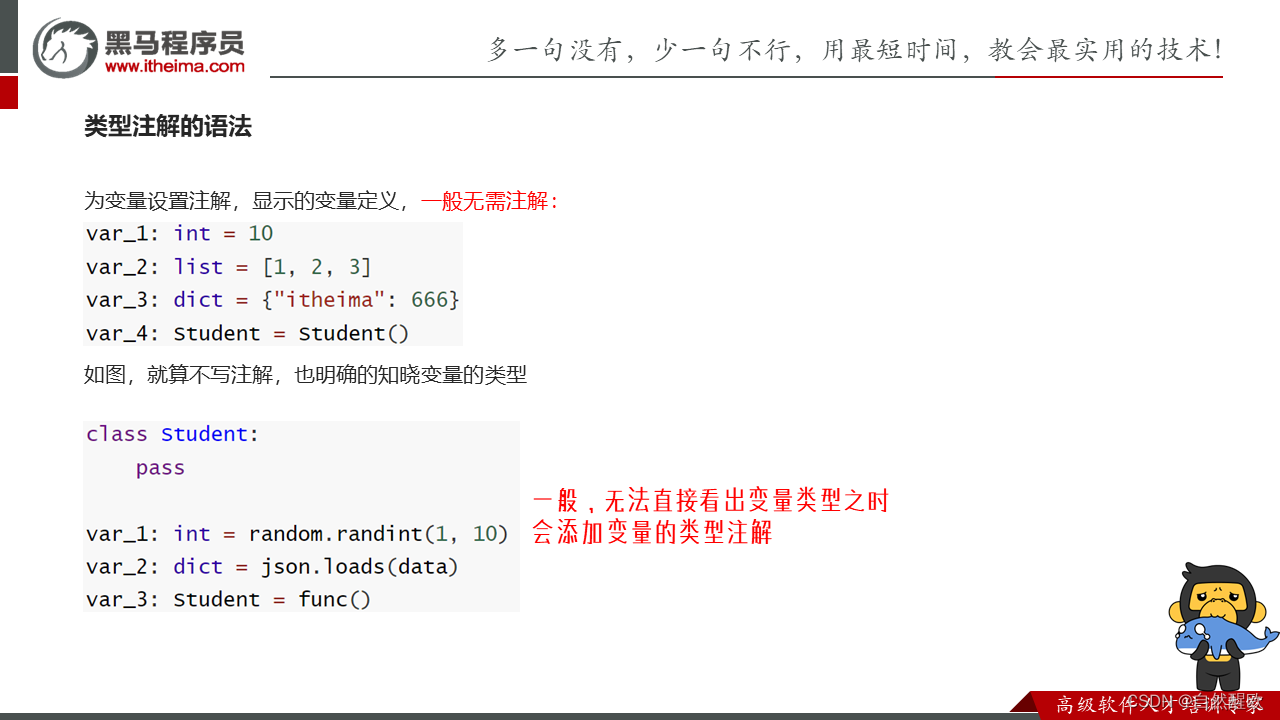
10.8 类型注解_变量

"""
演示变量的类型注解
"""# 基础数据类型注解
import json
import random# var_1: int = 10
# var_2: str = "itheima"
# var_3: bool = True
# 类对象类型注解
class Student:pass
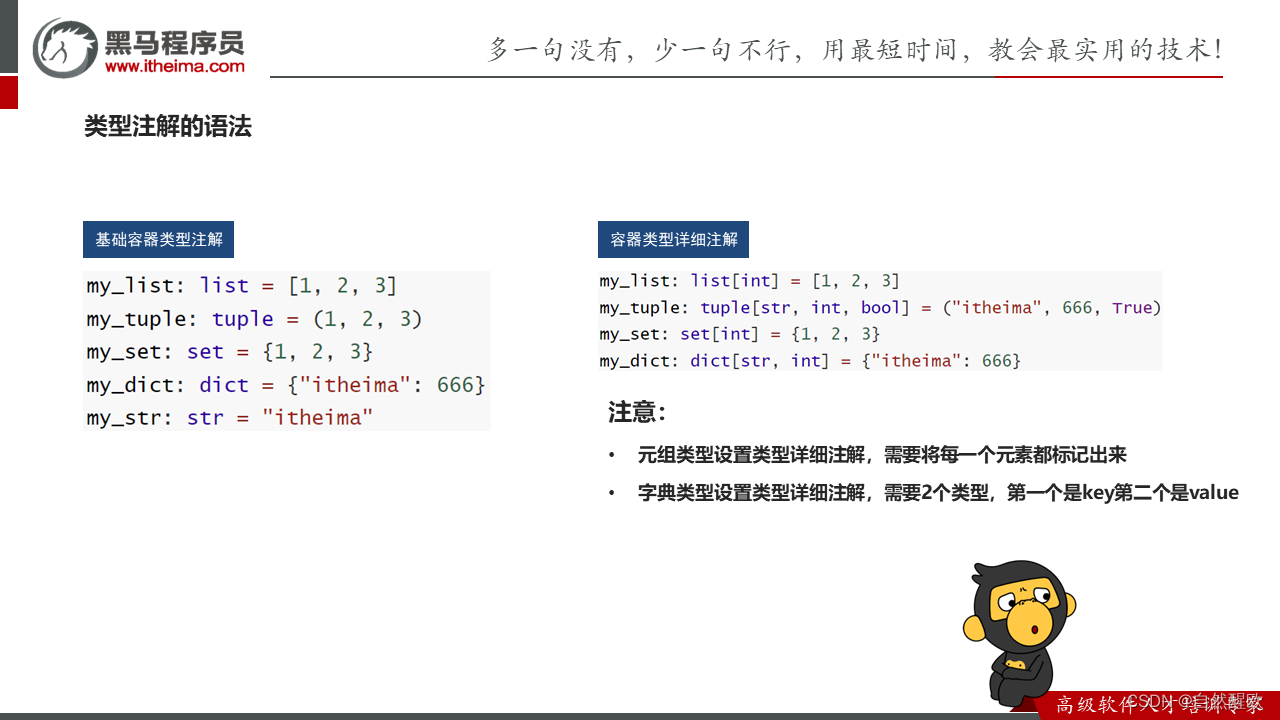
stu: Student = Student()# 基础容器类型注解
# my_list: list = [1, 2, 3]
# my_tuple: tuple = (1, 2, 3)
# my_dict: dict = {"itheima": 666}
# 容器类型详细注解
my_list: list[int] = [1, 2, 3]
my_tuple: tuple[int, str, bool] = (1, "itheima", True)
my_dict: dict[str, int] = {"itheima": 666}
# 在注释中进行类型注解
var_1 = random.randint(1, 10) # type: int
var_2 = json.loads('{"name": "zhangsan"}') # type: dict[str, str]
def func():return 10
var_3 = func() # type: int
# 类型注解的限制
var_4: int = "itheima"
var_5: str = 123"""
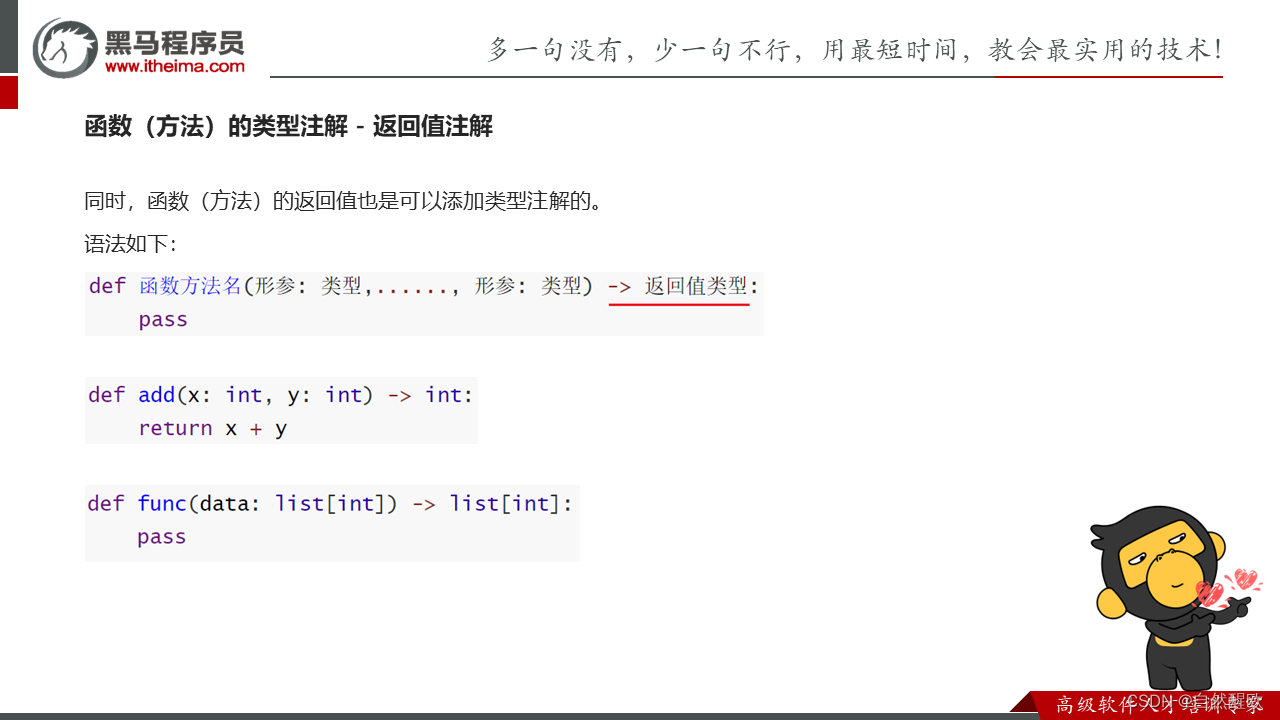
演示对函数(方法)进行类型注解
"""
# 对形参进行类型注解
def add(x: int, y: int):return x + y# 对返回值进行类型注解
def func(data: list) -> list:return dataprint(func(1))
10.9 类型注解_Union联合类型
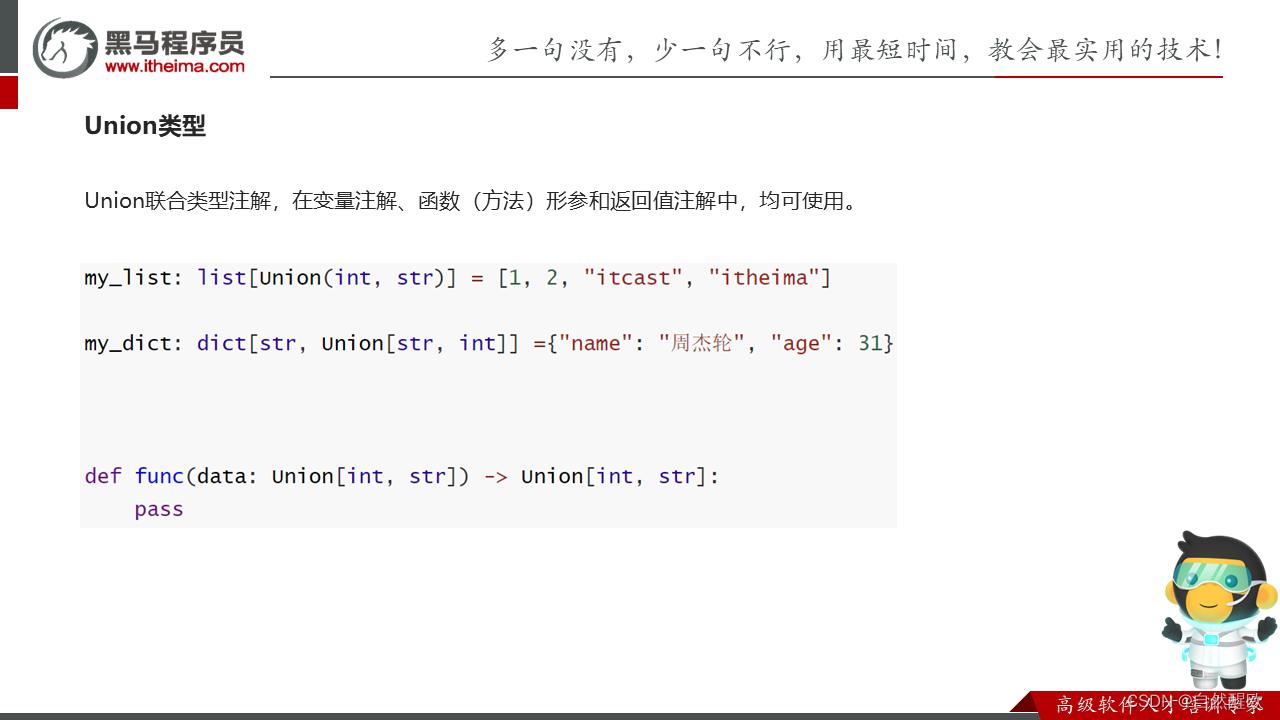
"""
演示Union联合类型注解
"""
# 使用Union类型,必须先导包
from typing import Unionmy_list: list[Union[int, str]] = [1, 2, "itheima", "itcast"]def func(data: Union[int, str]) -> Union[int, str]:pass
10.10 多态
"""
演示面向对象的多态特性以及抽象类(接口)的使用
"""class Animal:def speak(self):passclass Dog(Animal):def speak(self):print("汪汪汪")class Cat(Animal):def speak(self):print("喵喵喵")def make_noise(animal: Animal):"""制造点噪音,需要传入Animal对象"""animal.speak()# 演示多态,使用2个子类对象来调用函数
dog = Dog()
cat = Cat()make_noise(dog)
make_noise(cat)# 演示抽象类
class AC:def cool_wind(self):"""制冷"""passdef hot_wind(self):"""制热"""passdef swing_l_r(self):"""左右摆风"""passclass Midea_AC(AC):def cool_wind(self):print("美的空调制冷")def hot_wind(self):print("美的空调制热")def swing_l_r(self):print("美的空调左右摆风")class GREE_AC(AC):def cool_wind(self):print("格力空调制冷")def hot_wind(self):print("格力空调制热")def swing_l_r(self):print("格力空调左右摆风")def make_cool(ac: AC):ac.cool_wind()midea_ac = Midea_AC()
gree_ac = GREE_AC()make_cool(midea_ac)
make_cool(gree_ac)
10.11 综合案例
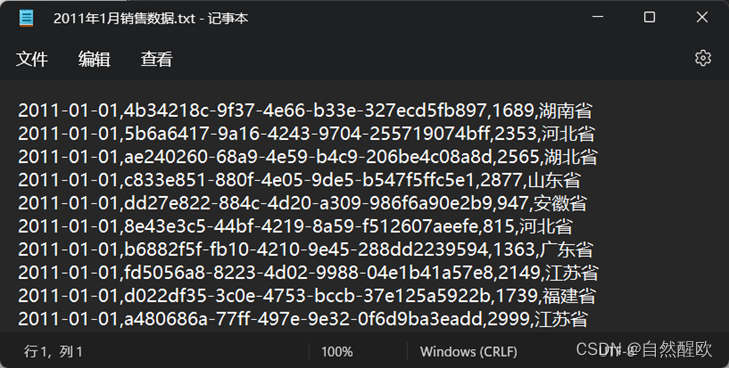
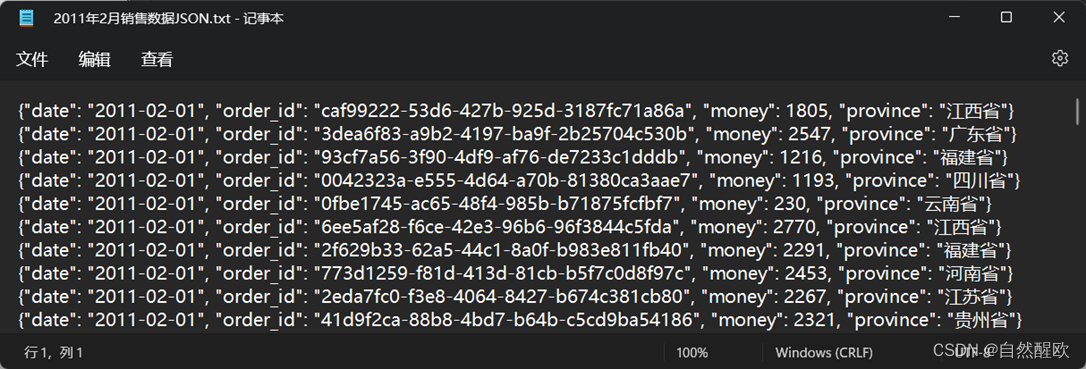
-
1月份数据是普通文本,使用逗号分割数据记录,从前到后分别是(日期,订单id,销售额,销售省份)
-
2月份数据是JSON数据,同样包含(日期,订单id,销售额,销售省份)
-
数据文件下载地址
10.11.1 data_define.py
"""
数据定义的类
"""
class Record:def __init__(self, date, order_id, money, province):self.date = date # 订单日期self.order_id = order_id # 订单IDself.money = money # 订单金额self.province = province # 销售省份def __str__(self):return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
10.11.2 file_define.py
"""
和文件相关的类定义
"""
import jsonfrom data_define import Record# 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:def read_data(self) -> list[Record]:"""读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""passclass TextFileReader(FileReader):def __init__(self, path):self.path = path # 定义成员变量记录文件的路径# 复写(实现抽象方法)父类的方法def read_data(self) -> list[Record]:f = open(self.path, "r", encoding="UTF-8")record_list: list[Record] = []for line in f.readlines():line = line.strip() # 消除读取到的每一行数据中的\ndata_list = line.split(",")record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])record_list.append(record)f.close()return record_listclass JsonFileReader(FileReader):def __init__(self, path):self.path = path # 定义成员变量记录文件的路径def read_data(self) -> list[Record]:f = open(self.path, "r", encoding="UTF-8")record_list: list[Record] = []for line in f.readlines():data_dict = json.loads(line)record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])record_list.append(record)f.close()return record_listif __name__ == '__main__':text_file_reader = TextFileReader("D:/2011年1月销售数据.txt")json_file_reader = JsonFileReader("D:/2011年2月销售数据JSON.txt")list1 = text_file_reader.read_data()list2 = json_file_reader.read_data()for l in list1:print(l)for l in list2:print(l)
10.11.3 main.py
"""
面向对象,数据分析案例,主业务逻辑代码
实现步骤:
1. 设计一个类,可以完成数据的封装
2. 设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
3. 读取文件,生产数据对象
4. 进行数据需求的逻辑计算(计算每一天的销售额)
5. 通过PyEcharts进行图形绘制
"""
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
from pyecharts.charts import Bar
from pyecharts.options import *
from pyecharts.globals import ThemeTypetext_file_reader = TextFileReader("D:/2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:/2011年2月销售数据JSON.txt")jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data# 开始进行数据计算
# {"2011-01-01": 1534, "2011-01-02": 300, "2011-01-03": 650}
data_dict = {}
for record in all_data:if record.date in data_dict.keys():# 当前日期已经有记录了,所以和老记录做累加即可data_dict[record.date] += record.moneyelse:data_dict[record.date] = record.money# 可视化图表开发
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))bar.add_xaxis(list(data_dict.keys())) # 添加x轴的数据
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False)) # 添加了y轴数据
bar.set_global_opts(title_opts=TitleOpts(title="每日销售额")
)bar.render("每日销售额柱状图.html")
十一、 SQL

11.1 DML
11.1.1 插入
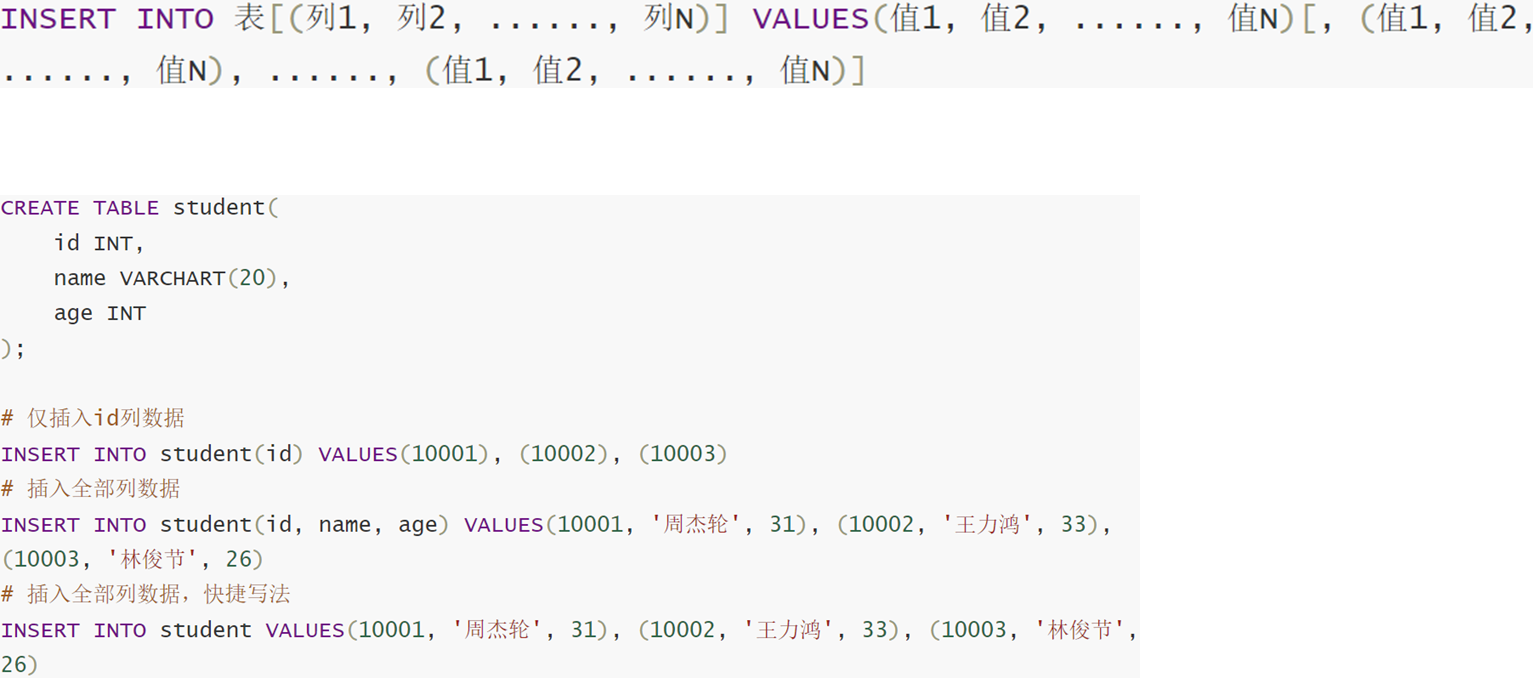
11.1.2 删除
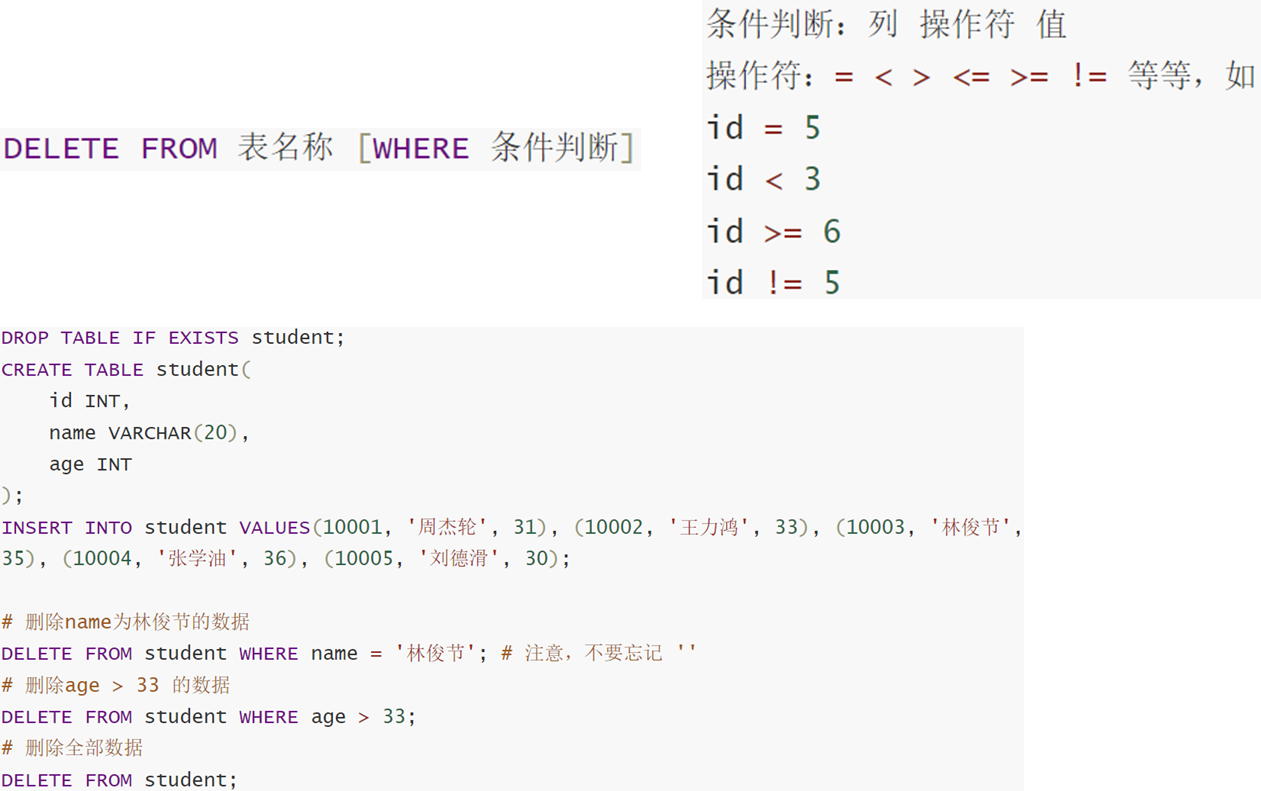
11.1.3 更新

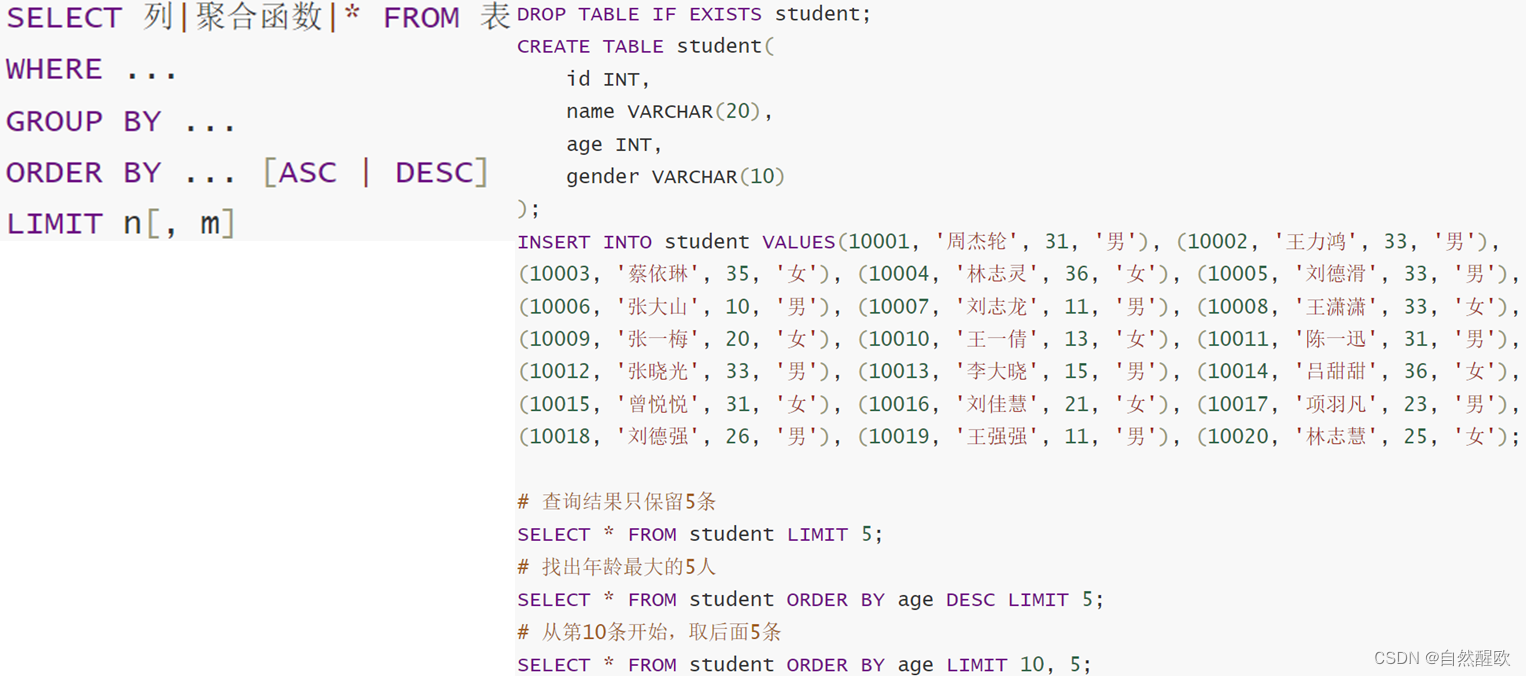
11.2 DQL
11.2.1 基础查询
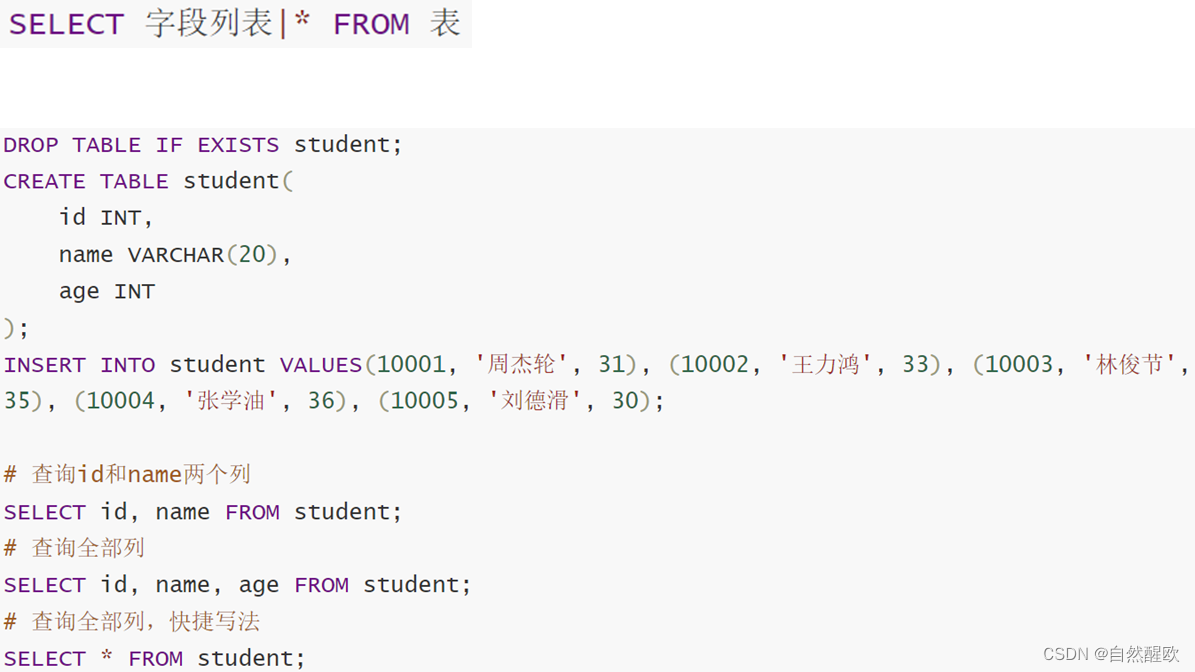
11.2.2 过滤查询
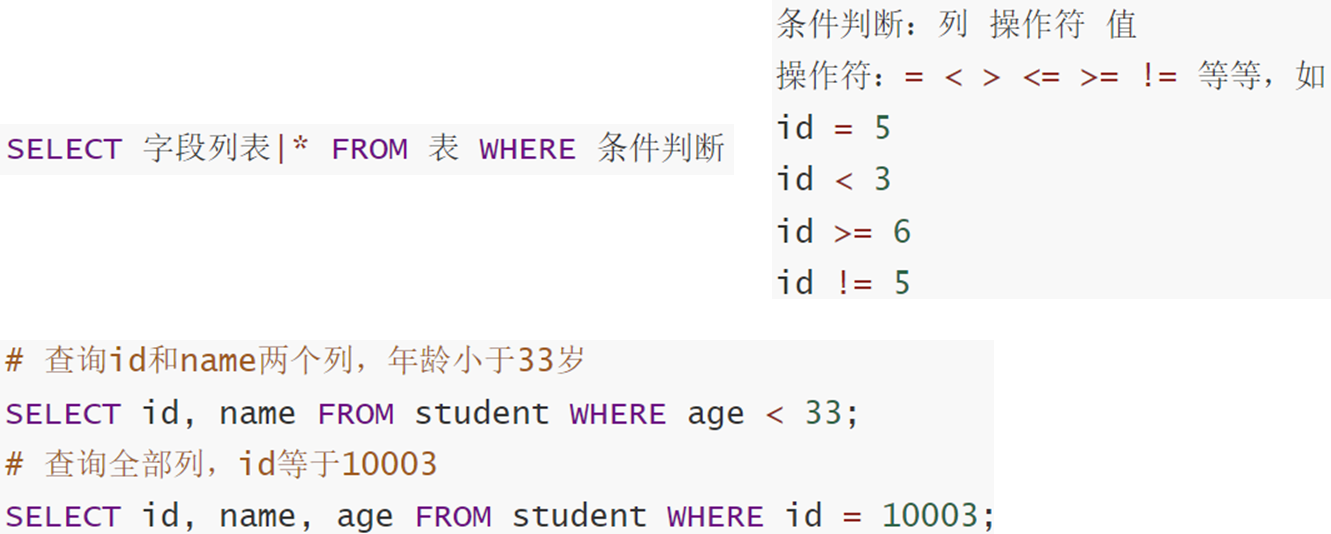
2.3 分组聚合

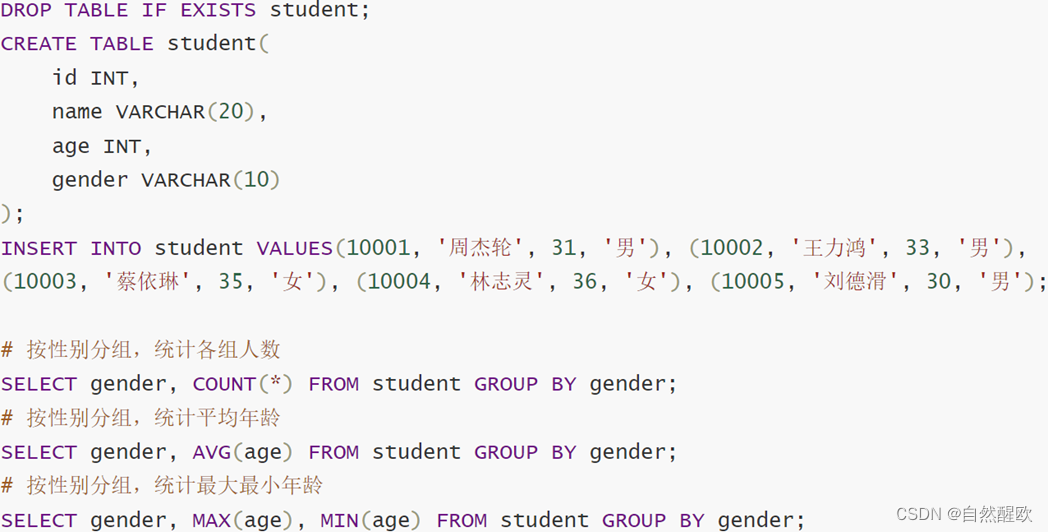

11.2.4 排序分页
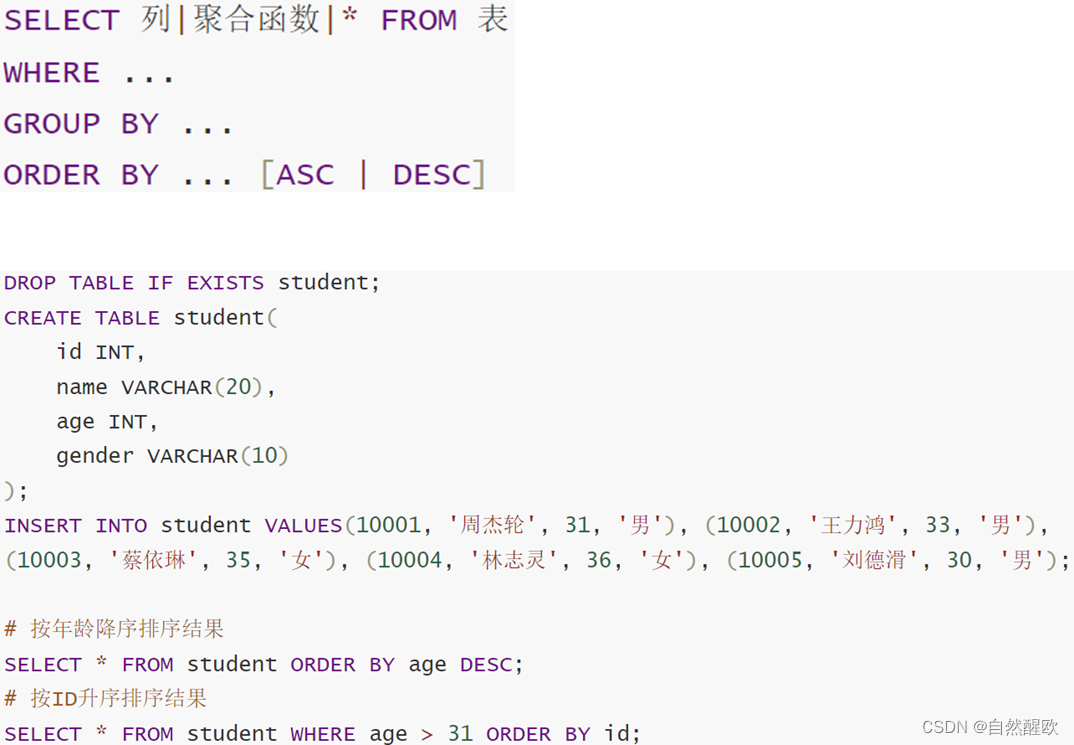

11.3. Python & MySQL
11.3.1 pymysql入门
"""
演示Python pymysql库的基础操作
"""
from pymysql import Connection# 构建到MySQL数据库的链接
conn = Connection(host="localhost", # 主机名(IP)port=3306, # 端口user="root", # 账户password="123456", # 密码autocommit=True # 设置自动提交
)# print(conn.get_server_info())
# 执行非查询性质SQL
cursor = conn.cursor() # 获取到游标对象
# 选择数据库
conn.select_db("world")
# 执行sql
cursor.execute("insert into student values(10001, '周杰轮', 31, '男')")
# 关闭链接
conn.close()
11.3.2 pymysql_数据插入
"""
演示使用pymysql库进行数据插入的操作
"""
from pymysql import Connection# 构建到MySQL数据库的链接
conn = Connection(host="localhost", # 主机名(IP)port=3306, # 端口user="root", # 账户password="123456", # 密码autocommit=True # 自动提交(确认)
)# print(conn.get_server_info())
# 执行非查询性质SQL
cursor = conn.cursor() # 获取到游标对象
# 选择数据库
conn.select_db("world")
# 执行sql
cursor.execute("insert into student values(10002, '林俊节', 31, '男')")
# # 通过commit确认
# conn.commit()
# 关闭链接
conn.close()
11.4 综合案例
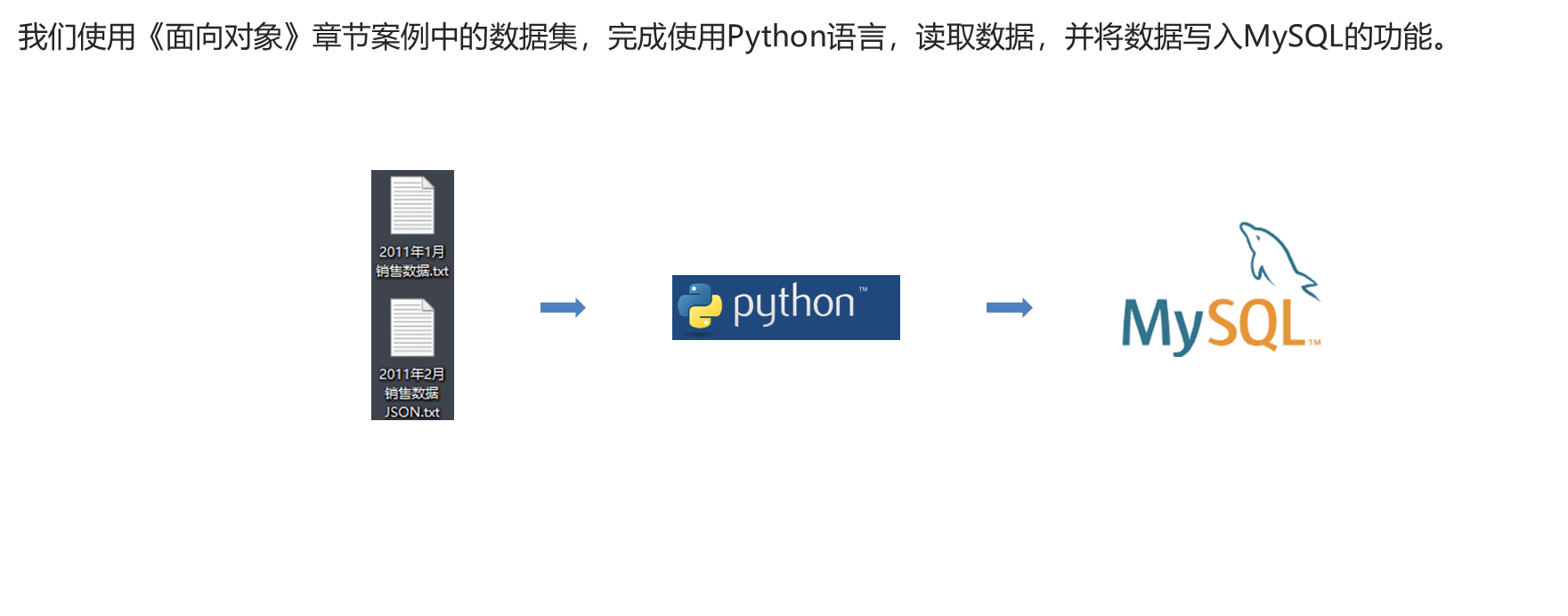
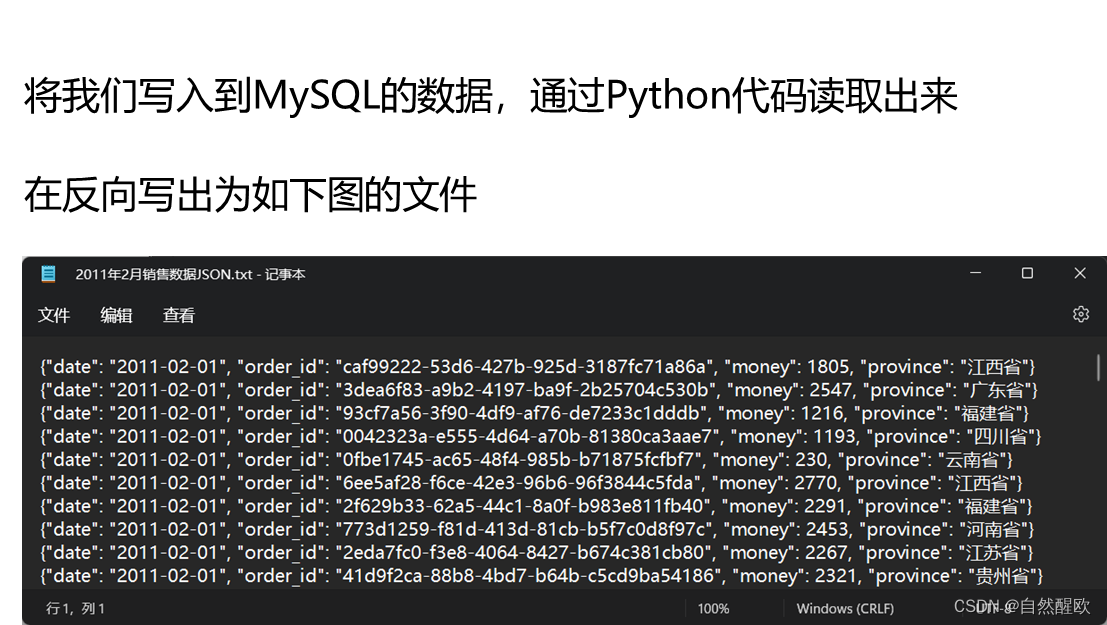
- 数据文件下载地址
- data_define.py 和 file_define.py 请查看 10.11.1 和 10.11.2
11.4.1 main.py
"""
SQL 综合案例,读取文件,写入MySQL数据库中
"""
from file_define import TextFileReader, JsonFileReader
from data_define import Record
from pymysql import Connectiontext_file_reader = TextFileReader("D:/2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:/2011年2月销售数据JSON.txt")jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data# 构建MySQL链接对象
conn = Connection(host="localhost",port=3306,user="root",password="123456",autocommit=True
)
# 获得游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("py_sql")
# 组织SQL语句
for record in all_data:sql = f"insert into orders(order_date, order_id, money, province) " \f"values('{record.date}', '{record.order_id}', {record.money}, '{record.province}')"# 执行SQL语句cursor.execute(sql)# 关闭MySQL链接对象
conn.close()
11.4.2 main2.py
from data_define import Record
from pymysql import Connectionf = open("d:/output.json", "w", encoding="UTF-8")
# 构建MySQL链接对象
conn = Connection(host="localhost",port=3306,user="root",password="123456",autocommit=True
)
# 获得游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("py_sql")
# 查询
cursor.execute("SELECT * FROM orders")
result = cursor.fetchall()
for r in result:record = Record(r[0], r[1], r[2], r[3])f.write(record.to_json())f.write("\n")# 关闭MySQL链接对象
conn.close()
f.close()
十二、 pyspark
12.1 基本准备
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark

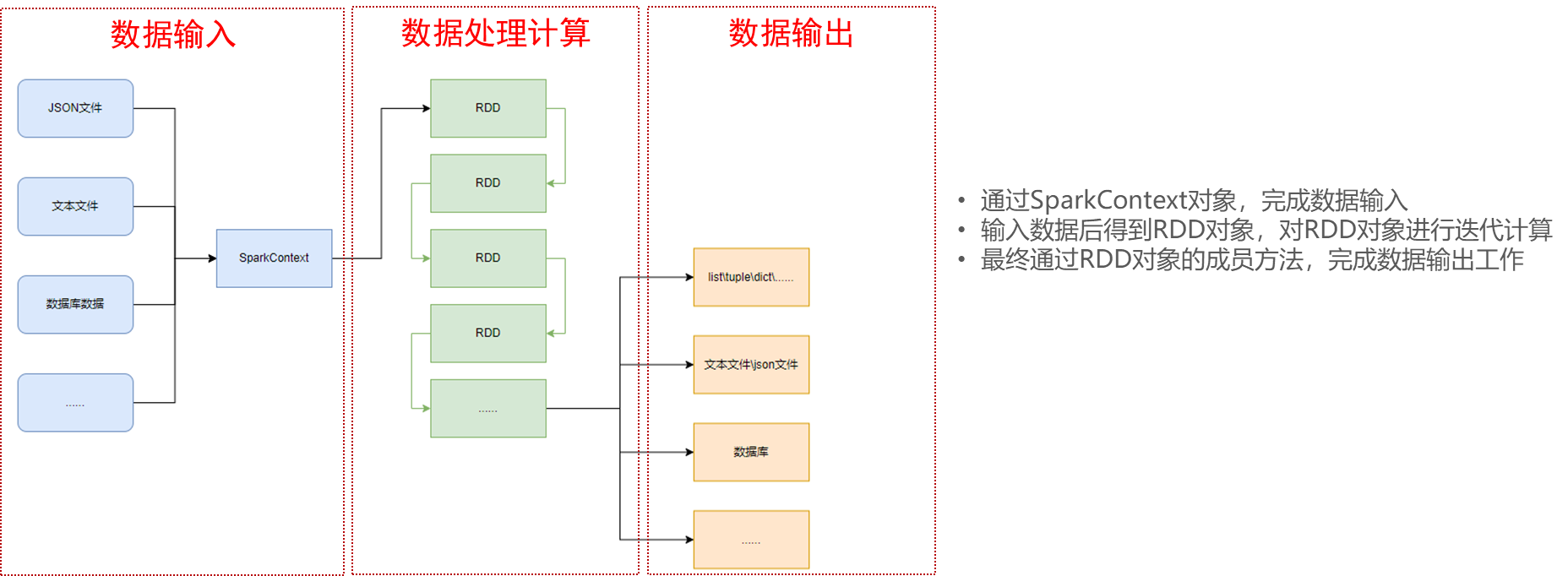
"""
演示获取PySpark的执行环境入库对象:SparkContext
并通过SparkContext对象获取当前PySpark的版本
"""# 导包
from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 打印PySpark的运行版本
print(sc.version)
# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
12.2 数据输入
"""
演示通过PySpark代码加载数据,即数据输入
"""
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# # 通过parallelize方法将Python对象加载到Spark内,成为RDD对象
# rdd1 = sc.parallelize([1, 2, 3, 4, 5])
# rdd2 = sc.parallelize((1, 2, 3, 4, 5))
# rdd3 = sc.parallelize("abcdefg")
# rdd4 = sc.parallelize({1, 2, 3, 4, 5})
# rdd5 = sc.parallelize({"key1": "value1", "key2": "value2"})
#
# # 如果要查看RDD里面有什么内容,需要用collect()方法
# print(rdd1.collect())
# print(rdd2.collect())
# print(rdd3.collect())
# print(rdd4.collect())
# print(rdd5.collect())# 用过textFile方法,读取文件数据加载到Spark内,成为RDD对象
rdd = sc.textFile("D:/hello.txt")
print(rdd.collect())
rdd.map()
sc.stop()
12.3 数据计算_map方法
- 功能:map算子,是将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数),返回新的RDD

"""
演示RDD的map成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 通过map方法将全部数据都乘以10
# def func(data):
# return data * 10rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5)print(rdd2.collect())
# (T) -> U
# (T) -> T
# 链式调用12.4 数据计算_flatMap方法
- 功能:对rdd执行map操作,然后进行
解除嵌套操作.

"""
演示RDD的flatMap成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize(["itheima itcast 666", "itheima itheima itcast", "python itheima"])# 需求,将RDD数据里面的一个个单词提取出来
rdd2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd2.collect())
12.5 数据计算_reduceByKey方法
- 功能:
针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作.

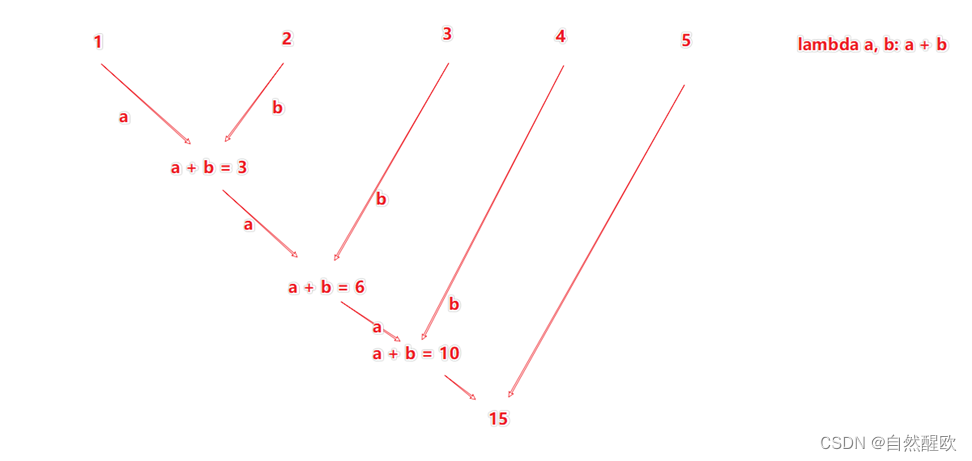
"""
演示RDD的reduceByKey成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([('男', 99), ('男', 88), ('女', 99), ('女', 66)])
# 求男生和女生两个组的成绩之和
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd2.collect())
12.6 练习案例1
- 读取文件;统计文件内,单词的出现数量。
- 数据文件下载地址
"""
完成练习案例:单词计数统计
"""# 1. 构建执行环境入口对象
from pyspark import SparkContext, SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 2. 读取数据文件
rdd = sc.textFile("D:/hello.txt")
# 3. 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 4. 将所有单词都转换成二元元组,单词为Key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word: (word, 1))
# 5. 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 6. 打印输出结果
print(result_rdd.collect())
12.7 数据计算_filter方法
- 功能:
过滤想要的数据进行保留

"""
演示RDD的filter成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 对RDD的数据进行过滤
rdd2 = rdd.filter(lambda num: num % 2 == 0)print(rdd2.collect())12.8 数据计算_distinct方法
- 功能:对RDD数据进行去重,返回新RDD
- 语法:
rdd.distinct()无需传参
"""
演示RDD的distinct成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 1, 3, 3, 5, 5, 7, 8, 8, 9, 10])
# 对RDD的数据进行去重
rdd2 = rdd.distinct()
print(rdd2.collect())
12.9 数据计算_sortBy方法
- 功能:对RDD数据进行
排序,基于你指定的排序依据.

"""
演示RDD的sortBy成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 1. 读取数据文件
rdd = sc.textFile("D:/hello.txt")
# 2. 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 3. 将所有单词都转换成二元元组,单词为Key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word: (word, 1))
# 4. 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 5. 对结果进行排序
final_rdd = result_rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=1)
print(final_rdd.collect())
12.10 练习案例2

- 数据文件下载地址
"""
完成练习案例:JSON商品统计
需求:
1. 各个城市销售额排名,从大到小
2. 全部城市,有哪些商品类别在售卖
3. 北京市有哪些商品类别在售卖
"""
from pyspark import SparkConf, SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python310/python.exe'
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# TODO 需求1: 城市销售额排名
# 1.1 读取文件得到RDD
file_rdd = sc.textFile("D:/orders.txt")
# 1.2 取出一个个JSON字符串
json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))
# 1.3 将一个个JSON字符串转换为字典
dict_rdd = json_str_rdd.map(lambda x: json.loads(x))
# 1.4 取出城市和销售额数据
# (城市,销售额)
city_with_money_rdd = dict_rdd.map(lambda x: (x['areaName'], int(x['money'])))
# 1.5 按城市分组按销售额聚合
city_result_rdd = city_with_money_rdd.reduceByKey(lambda a, b: a + b)
# 1.6 按销售额聚合结果进行排序
result1_rdd = city_result_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)
print("需求1的结果:", result1_rdd.collect())
# TODO 需求2: 全部城市有哪些商品类别在售卖
# 2.1 取出全部的商品类别
category_rdd = dict_rdd.map(lambda x: x['category']).distinct()
print("需求2的结果:", category_rdd.collect())
# 2.2 对全部商品类别进行去重
# TODO 需求3: 北京市有哪些商品类别在售卖
# 3.1 过滤北京市的数据
beijing_data_rdd = dict_rdd.filter(lambda x: x['areaName'] == '北京')
# 3.2 取出全部商品类别
result3_rdd = beijing_data_rdd.map(lambda x: x['category']).distinct()
print("需求3的结果:", result3_rdd.collect())
# 3.3 进行商品类别去重
12.11 数据输出_输出为Python对象
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
"""
演示将RDD输出为Python对象
"""from pyspark import SparkConf, SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python310/python.exe'
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])# collect算子,输出RDD为list对象
rdd_list: list = rdd.collect()
print(rdd_list)
print(type(rdd_list))
# reduce算子,对RDD进行两两聚合
num = rdd.reduce(lambda a, b: a + b)
print(num)
# take算子,取出RDD前N个元素,组成list返回
take_list = rdd.take(3)
print(take_list)
# count,统计rdd内有多少条数据,返回值为数字
num_count = rdd.count()
print(f"rdd内有{num_count}个元素")sc.stop()
12.12 数据输出_输出到文件
-
功能:将RDD的数据写入文本文件中支持 本地写出,hdfs等文件系统.
-
注意事项

-
修改rdd分区为1个
方式1,SparkConf对象设置属性隆局并行度为1:

方式2,创建RDD的时候设置(parallelize方法传入numSlices参数为1)
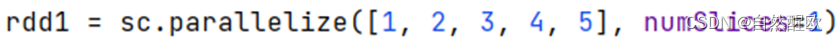
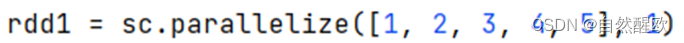
"""
演示将RDD输出到文件中
"""from pyspark import SparkConf, SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python310/python.exe'
os.environ['HADOOP_HOME'] = "D:/dev/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")sc = SparkContext(conf=conf)# 准备RDD1
rdd1 = sc.parallelize([1, 2, 3, 4, 5], numSlices=1)# 准备RDD2
rdd2 = sc.parallelize([("Hello", 3), ("Spark", 5), ("Hi", 7)], 1)# 准备RDD3
rdd3 = sc.parallelize([[1, 3, 5], [6, 7, 9], [11, 13, 11]], 1)# 输出到文件中
rdd1.saveAsTextFile("D:/output1")
rdd2.saveAsTextFile("D:/output2")
rdd3.saveAsTextFile("D:/output3")
12.13 综合案例

- 数据文件下载地址
"""
演示PySpark综合案例
"""from pyspark import SparkConf, SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python310/python.exe'
os.environ['HADOOP_HOME'] = "D:/dev/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
conf.set("spark.default.parallelism", "1")
sc = SparkContext(conf=conf)# 读取文件转换成RDD
file_rdd = sc.textFile("D:/search_log.txt")
# TODO 需求1: 热门搜索时间段Top3(小时精度)
# 1.1 取出全部的时间并转换为小时
# 1.2 转换为(小时, 1) 的二元元组
# 1.3 Key分组聚合Value
# 1.4 排序(降序)
# 1.5 取前3
result1 = file_rdd.map(lambda x: (x.split("\t")[0][:2], 1)).\reduceByKey(lambda a, b: a + b).\sortBy(lambda x: x[1], ascending=False, numPartitions=1).\take(3)
print("需求1的结果:", result1)# TODO 需求2: 热门搜索词Top3
# 2.1 取出全部的搜索词
# 2.2 (词, 1) 二元元组
# 2.3 分组聚合
# 2.4 排序
# 2.5 Top3
result2 = file_rdd.map(lambda x: (x.split("\t")[2], 1)).\reduceByKey(lambda a, b: a + b).\sortBy(lambda x: x[1], ascending=False, numPartitions=1).\take(3)
print("需求2的结果:", result2)# TODO 需求3: 统计黑马程序员关键字在什么时段被搜索的最多
# 3.1 过滤内容,只保留黑马程序员关键词
# 3.2 转换为(小时, 1) 的二元元组
# 3.3 Key分组聚合Value
# 3.4 排序(降序)
# 3.5 取前1
result3 = file_rdd.map(lambda x: x.split("\t")).\filter(lambda x: x[2] == '黑马程序员').\map(lambda x: (x[0][:2], 1)).\reduceByKey(lambda a, b: a + b).\sortBy(lambda x: x[1], ascending=False, numPartitions=1).\take(1)
print("需求3的结果:", result3)# TODO 需求4: 将数据转换为JSON格式,写出到文件中
# 4.1 转换为JSON格式的RDD
# 4.2 写出为文件
file_rdd.map(lambda x: x.split("\t")).\map(lambda x: {"time": x[0], "user_id": x[1], "key_word": x[2], "rank1": x[3], "rank2": x[4], "url": x[5]}).\saveAsTextFile("D:/output_json")
十三、 高级技巧
13.1 闭包

"""
演示Python的闭包特性
"""# 简单闭包
# def outer(logo):
#
# def inner(msg):
# print(f"<{logo}>{msg}<{logo}>")
#
# return inner
#
#
# fn1 = outer("黑马程序员")
# fn1("大家好")
# fn1("大家好")
#
# fn2 = outer("传智教育")
# fn2("大家好")
# 使用nonlocal关键字修改外部函数的值
# def outer(num1):
#
# def inner(num2):
# nonlocal num1
# num1 += num2
# print(num1)
#
# return inner
#
# fn = outer(10)
# fn(10)
# fn(10)
# fn(10)
# fn(10)# 使用闭包实现ATM小案例
def account_create(initial_amount=0):def atm(num, deposit=True):nonlocal initial_amountif deposit:initial_amount += numprint(f"存款:+{num}, 账户余额:{initial_amount}")else:initial_amount -= numprint(f"取款:-{num}, 账户余额:{initial_amount}")return atmatm = account_create()atm(100)
atm(200)
atm(100, deposit=False)
13.2 装饰器
"""
演示装饰器的写法
"""# 装饰器的一般写法(闭包)
# def outer(func):
# def inner():
# print("我睡觉了")
# func()
# print("我起床了")
#
# return inner
#
#
# def sleep():
# import random
# import time
# print("睡眠中......")
# time.sleep(random.randint(1, 5))
#
#
# fn = outer(sleep)
# fn()# 装饰器的快捷写法(语法糖)
def outer(func):def inner():print("我睡觉了")func()print("我起床了")return inner@outer
def sleep():import randomimport timeprint("睡眠中......")time.sleep(random.randint(1, 5))sleep()
13.3 单例模式
13.3.1 str_tools_py.py
class StrTools:passstr_tool = StrTools()
13.3.2 test.py
from str_tools_py import str_tools1 = str_tool
s2 = str_toolprint(id(s1))
print(id(s2))
13.3.3 非单例模式
"""
演示非单例模式的效果
"""
class StrTools:passs1 = StrTools()
s2 = StrTools()
print(id(s1))
print(id(s2))
13.4 工厂模式
"""
演示设计模式之工厂模式
"""class Person:passclass Worker(Person):passclass Student(Person):passclass Teacher(Person):passclass PersonFactory:def get_person(self, p_type):if p_type == 'w':return Worker()elif p_type == 's':return Student()else:return Teacher()pf = PersonFactory()
worker = pf.get_person('w')
stu = pf.get_person('s')
teacher = pf.get_person('t')
13.5 多线程模式
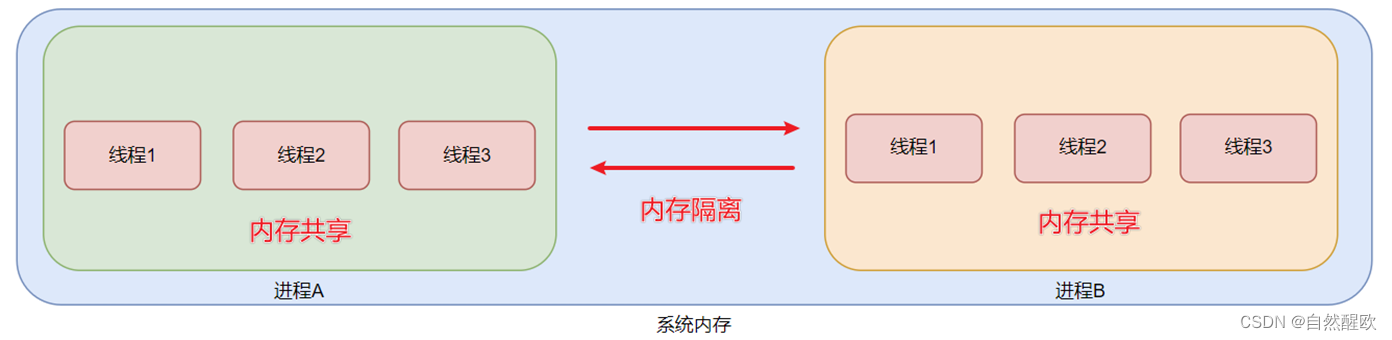
"""
演示多线程编程的使用
"""
import time
import threadingdef sing(msg):print(msg)time.sleep(1)def dance(msg):print(msg)time.sleep(1)if __name__ == '__main__':# 创建一个唱歌的线程sing_thread = threading.Thread(target=sing, args=("我要唱歌 哈哈哈", ))# 创建一个跳舞的线程dance_thread = threading.Thread(target=dance, kwargs={"msg": "我在跳舞哦 啦啦啦"})# 让线程去干活吧sing_thread.start()dance_thread.start()
13.6 socket编程
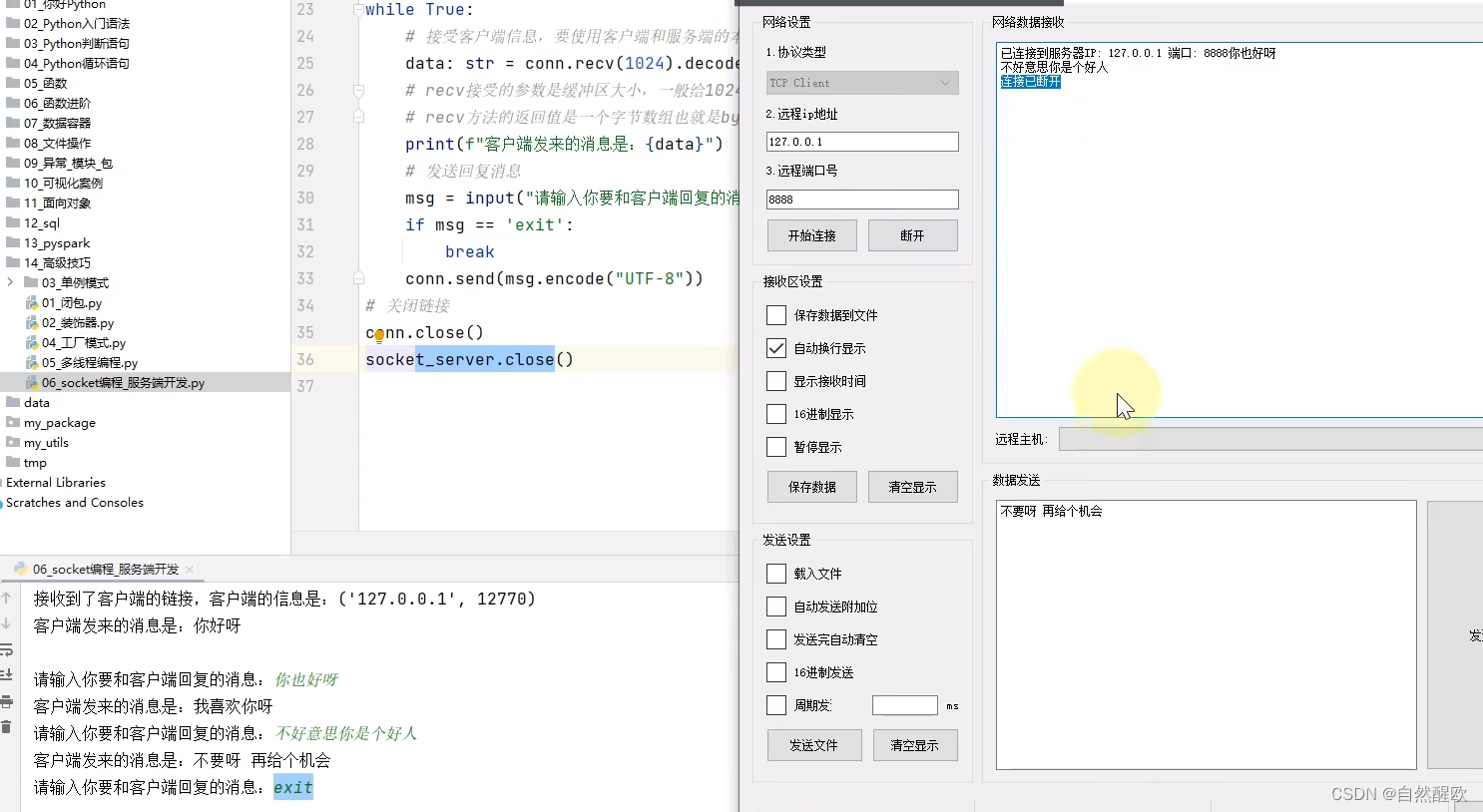
13.6.1 服务端开发
"""
演示Socket服务端开发
"""
import socket
# 创建Socket对象
socket_server = socket.socket()
# 绑定ip地址和端口
socket_server.bind(("localhost", 8888))
# 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受的链接数量
# 等待客户端链接
# result: tuple = socket_server.accept()
# conn = result[0] # 客户端和服务端的链接对象
# address = result[1] # 客户端的地址信息
conn, address = socket_server.accept()
# accept方法返回的是二元元组(链接对象, 客户端地址信息)
# 可以通过 变量1, 变量2 = socket_server.accept()的形式,直接接受二元元组内的两个元素
# accept()方法,是阻塞的方法,等待客户端的链接,如果没有链接,就卡在这一行不向下执行了print(f"接收到了客户端的链接,客户端的信息是:{address}")while True:# 接受客户端信息,要使用客户端和服务端的本次链接对象,而非socket_server对象data: str = conn.recv(1024).decode("UTF-8")# recv接受的参数是缓冲区大小,一般给1024即可# recv方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象print(f"客户端发来的消息是:{data}")# 发送回复消息msg = input("请输入你要和客户端回复的消息:")if msg == 'exit':breakconn.send(msg.encode("UTF-8"))
# 关闭链接
conn.close()
socket_server.close()
13.6.2 客户端开发
"""
演示Socket客户端开发
"""
import socket
# 创建socket对象
socket_client = socket.socket()
# 连接到服务端
socket_client.connect(("localhost", 8888))while True:# 发送消息msg = input("请输入要给服务端发送的消息:")if msg == 'exit':breaksocket_client.send(msg.encode("UTF-8"))# 接收返回消息recv_data = socket_client.recv(1024) # 1024是缓冲区的大小,一般1024即可。 同样recv方法是阻塞的print(f"服务端回复的消息是:{recv_data.decode('UTF-8')}")
# 关闭链接
socket_client.close()
13.7 正则表达式
13.7.1 基础匹配
- re.match:从头开始匹配,匹配第一个命中项
- re.search:全局匹配,匹配第一个命中项
- re.findall:全局匹配,匹配全部命中项
"""
演示Python正则表达式re模块的3个基础匹配方法
"""
import res = "1python itheima python python"
# match 从头匹配
result = re.match("python", s)
print(result)
# print(result.span())
# print(result.group())
# search 搜索匹配result = re.search("python2", s)
print(result)
# findall 搜索全部匹配
result = re.findall("python", s)
print(result)
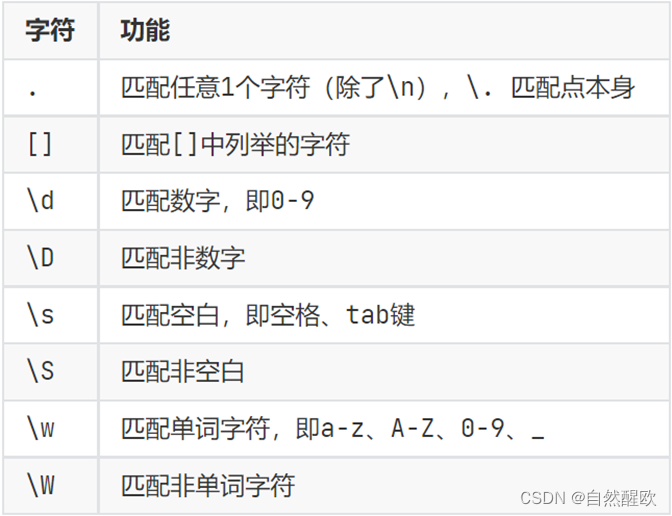
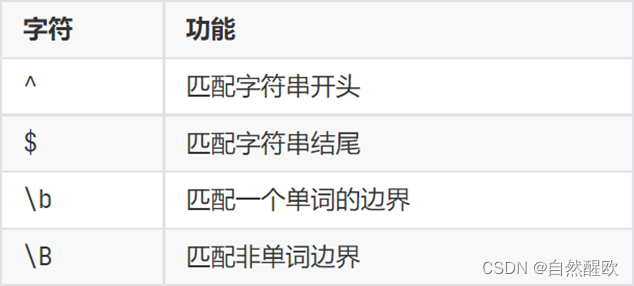
13.7.2 元字符匹配
- 单字符匹配
- 数量匹配

- 边界匹配
- 分组匹配

"""
演示Python正则表达式使用元字符进行匹配
"""
import re# s = "itheima1 @@python2 !!666 ##itccast3"
#
# result = re.findall(r'[b-eF-Z3-9]', s) # 字符串前面带上r的标记,表示字符串中转义字符无效,就是普通字符的意思
# print(result)# 匹配账号,只能由字母和数字组成,长度限制6到10位
# r = '^[0-9a-zA-Z]{6,10}$'
# s = '123456_'
# print(re.findall(r, s))
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
# r = '^[1-9][0-9]{4,10}$'
# s = '123453678'
# print(re.findall(r, s))
# 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
# abc.efg.daw@qq.com.cn.eu.qq.aa.cc
# abc@qq.com
# {内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}@{内容}.{内容}.{内容}
r = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
# s = 'a.b.c.d.e.f.g@qq.com.a.z.c.d.e'
s = 'a.b.c.d.e.f.g@126.com.a.z.c.d.e'
print(re.match(r, s))
13.8 递归
"""
演示Python递归操作
需求:通过递归,找出一个指定文件夹内的全部文件思路:写一个函数,列出文件夹内的全部内容,如果是文件就收集到list
如果是文件夹,就递归调用自己,再次判断。"""
import osdef test_os():"""演示os模块的3个基础方法"""print(os.listdir("D:/test")) # 列出路径下的内容# print(os.path.isdir("D:/test/a")) # 判断指定路径是不是文件夹# print(os.path.exists("D:/test")) # 判断指定路径是否存在def get_files_recursion_from_dir(path):"""从指定的文件夹中使用递归的方式,获取全部的文件列表:param path: 被判断的文件夹:return: list,包含全部的文件,如果目录不存在或者无文件就返回一个空list"""print(f"当前判断的文件夹是:{path}")file_list = []if os.path.exists(path):for f in os.listdir(path):new_path = path + "/" + fif os.path.isdir(new_path):# 进入到这里,表明这个目录是文件夹不是文件file_list += get_files_recursion_from_dir(new_path)else:file_list.append(new_path)else:print(f"指定的目录{path},不存在")return []return file_listif __name__ == '__main__':print(get_files_recursion_from_dir("D:/test"))def a():a()