背景
大语言模型是自然语言处理领域的一项重要技术,能够通过学习大量的文本数据,生成具有语法和意义的自然语言文本。目前大语言模型已经成为了自然语言处理领域的一个热门话题,引起了广泛的关注和研究。
知识库需求在各行各业中普遍存在,例如制造业中历史故障知识库、游戏社区平台的内容知识库、电商的商品推荐知识库和医疗健康领域的挂号推荐知识库系统等。
本文旨在介绍一些企业知识库的典型实用场景,以及如何使用智能搜索,结合大语言模型,针对企业知识库提供基于搜索的精准问答。
基于智能搜索的大语言模型增强方案介绍
架构图
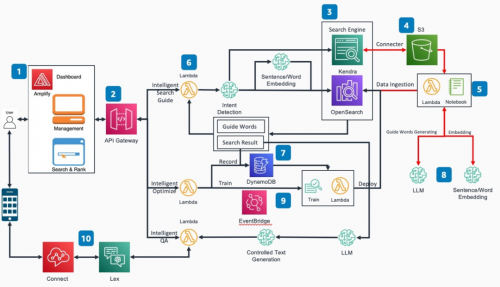
该平台将包括五大核心内容
1. 智能搜索
传统仅依靠关键词匹配的分词搜索的方式在很多场景下可以提供快速有效的查询,但是也存在一些固有的局限性。例如匹配一些包括停用词在内的无关词汇,无法识别同义词和缺乏抽象能力。为了解决这些问题,本方案中一方面使用意图识别大语言模型,对关键信息进行提取,从而可以有效的避免停用词等无法词汇对搜索造成的干扰。另一方面,引入AI/ML的方法来辅助实现语意搜索。具体来讲,使用同一个向量编码的大语言模型对搜索语句和文档数据库进行语意编码,在检索的过程中,使用knn方法进行向量匹配。以下是一个传统分词搜索与语意向量搜索的对比展示。可以看到,使用向量搜索功能后,可以召回更多自然语意上相近而关键词无关的内容,增加召回范围和提升搜索准确性。
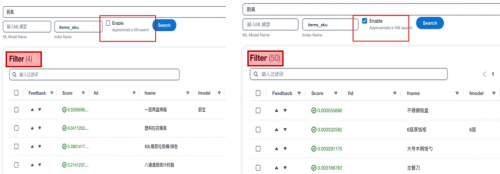
在本方案中,以Amazon OpenSearch和Amazon Kendra为基础构建搜索引擎。提供分词搜索,模糊查询和AI/ML辅助搜索功能。不在局限于某一种搜索方式,而是将所有搜索方法取长补短,进行有机的整合。
智能引导
造成搜索不准确的原因,一方面是由于搜索引擎本身的能力不足,另外一方面的原因是因为搜索的语句不够准确和具体。因此,本方案中提出了一种引导式的搜索机制来帮助检索人员逐步丰富输入的搜索语句,最终达到提升搜索准确性的目的。
以下面制造业大型设备维保知识库的搜索流程为例。该知识库存储历史维修记录,包括故障现象,故障原因,维修方案等字段。
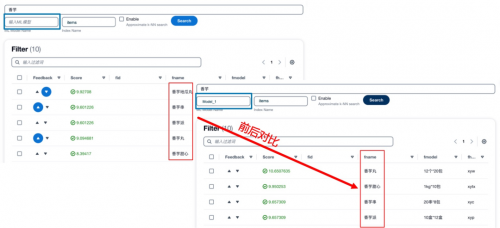
当用户输入检索词“电路”后,除了从知识库中返回与电路相关的条目之外,还会给予一些提示词,例如“门系统”、“控制系统”等,这些词代表与“电路”相关的故障往往伴随可能出现问题的系统,提示用户进一步丰富当前的搜索描述。
当用户进一步输入“主板”后,会将“电路”和“主板”进行联合查询,返回相关的条目,并进一步给出新的提示词。
用户可以重复以上过程,直到搜索出来更为精准的结果。

提示词的获取:根据实际情况,可以采用人工打标、无监督聚类、有监督分类、大语言模型(LLM)等方法进行提取,并提前注入到数据库中。
智能优化
通常情况下,由于知识库的迭代更新,检索的准确率可能会随时时间的推荐逐步降低,一方面是因为我们往往不能保证,数据库和搜索引擎一次性构建完成后就达到很好的效果。另外一方面是因为对于过时的知识没有进行有效的处理。因此,本方案提出以用户行为对搜索引擎进行持续优化。
具体来讲包括两个步骤:
用户行为收集:将历史用户的行为进行收集,例如用户对某个搜索词条的打分。
大语言模型的训练和部署:通过用户行为,整理得到搜索词条和知识库之间的相关度。使用该相关度训练和部署一个重排大语言模型,该重排大语言模型可以根据历史的用户行为,给予用户更加偏好的内容更高的权重得分。
值得注意的是,该大语言模型是基于传统机器学习模型xgboost的,所以所需要的训练数据量和推理所需要的资源都是很小的(例如只需要几十条数据和t3.small机型),因此可以基于不同的用户/用户群训练不同的重排大语言模型,达到千人千面,个性化搜索的目的。
4.智能问答
基于私有知识库进行问答是另外一个广泛应用的场景,例如智能客户聊天机器人系统,IT/HR系统智能问答系统等。
如果仅使用搜索引擎,只能基于问题从数据库中提取与该问题相关的内容,而不能直接给出答案。
如果仅使用大语言模型(Large Language Model,LLM),不能基于私有知识库进行问答。一种可行的方式是将私有知识库和问题直接以prompt的形式直接一次性给到LLM,然后让LLM给出回答。但是受限于LLM Token的限制,无法一次性输入过多的知识库。
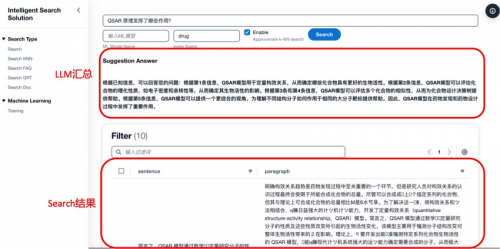
因此,在本方案中,将两者结合。如下图所示,当用户提出一个问题后,首先使用搜索提取与问题相关的知识,然后再将问题和提取的知识给到LLM进行总结,最后直接给出问题答案。
5. 非结构化数据注入
可供搜索引擎进行检索的企业知识库是一种结构化的数据,但往往企业的原始知识都是以非结构化的数据进行存储的,来自多个渠道,也包含了多种格式,例如Words,PDF,Excel等。
为了能够帮助企业快速将这些结构化数据利用起来,本方案提供了非结构化数据注入功能,该功能将企业的知识文档进行自动段落拆分和向量编码,建立结构化企业知识库。
大语言模型技术细节
LLM
最近半年,大语言模型(LLM)在自然语言处理领域取得了飞速的发展。大语言模型通常基于Transformer架构,在大规模的网络文本数据上进行训练,其核心是使用一个自我监督的目标来预测部分句子中的下一个单词。亚马逊云科技已推出大语言模型Titan和大语言模型平台Amazon Bedrock,另外还有许多研究机构推出开源大语言模型,如斯坦福大学的Alpaca和清华大学的ChatGLM等。这些大语言模型都具备强大的文本处理能力,广泛应用在智能问答、文本总结、文本生成等场景。
Embedding
各类非结构化数据广泛存在于我们的生活和工作场景,如文本、图片、视频等,为了处理这些非结构化数据,亚马逊云科技通常使用Embedding模型提取这些数据的特征,并把数据特征转化成向量,通过特征向量对这些非结构化数据进行分析和检索。通用的预训练大语言模型都有把文本进行向量化的功能,可以根据不同的场景和语种,选用合适的预训练大语言模型作为Embedding模型。
Intent Detection
搜索意图识别主要功能是分析用户的核心搜索需求,例如在电商场景,用户找的电子产品,是电脑类的,还是手机类的,是家庭场景用的,还是户外场景用的等等,如果意图识别不准,会有很多不相关的商品展现给用户,导致产生非常差的用户体验,因此精准的意图识别非常重要。意图识别主要包括类目预测和实体识别大语言模型,类目预测大语言模型主要采用文本多分类模型,根据平台的用户行为数据,将查询文本预测属于各个类目的概率。实体识别大语言模型将查询文本中的实体词识别出来,实体词是描述商品的维度信息,如品牌、颜色、材质等,通过实体识别大语言模型识别出查询文本的实体词后,再到搜索引擎进行精准查询。
Controlled Text Generation
可控文本生成是在传统文本生成的基础上,增加对生成文本的控制,如指定生成文本的关键词、格式、风格等,从而使生成的文本符合我们的预期,比如生成与某人相同风格的文本,生成有固定内容格式的报告,根据简单的故事线生成完整的小说等等。可控文本生成有对预训练模型finetune、重新训练文本生成模型和重构预训练模型输出结果等方式。在大语言模型推出后,目前可以方便的通过Prompt提示词,指导大语言模型进行可控文本生成,针对不同的场景和文本生成目标,设计不同格式和内容的提示词,生成满足需求的文本。