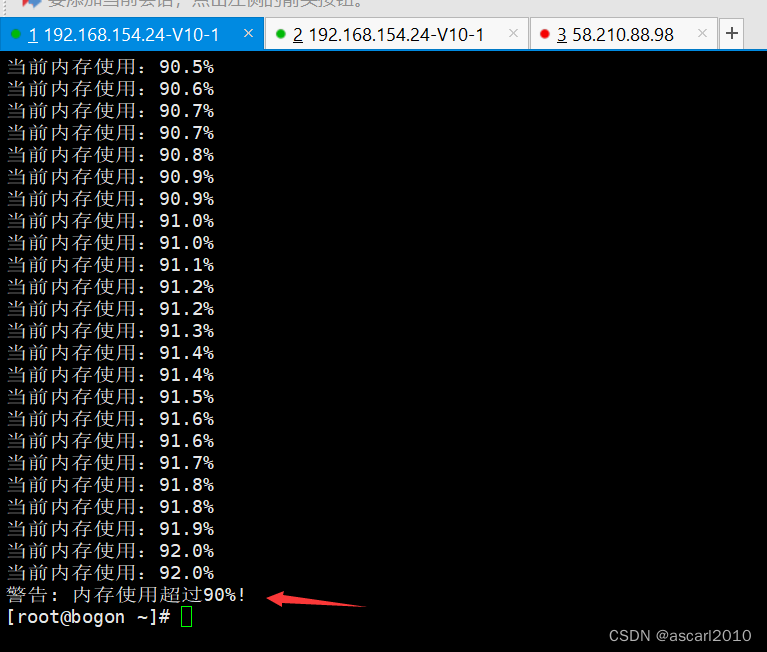
paper:RTMDet: An Empirical Study of Designing Real-Time Object Detectors
official implementation:https://github.com/open-mmlab/mmdetection/tree/main/configs/rtmdet
本文的创新点
Backbone and Neck
- 在backbone的basic building block中采用large-kernel depth-wise convolution,提高了模型捕获全局上下文的能力。
- 直接添加depth-wise卷积会增加模型深度,减慢推理速度。因此通过减小building block的个数来减小模型深度,同时通过增加模型宽度来补偿模型容量。
- 作者还观察到,在neck部分设置更多参数,使其容量与backbone兼容,可以实现更好的速度-精度的平衡。
论文中提到的增加模型宽度,以及通过增加neck部分的expand ratio来增加neck部分的参数在代码中都没有看到。
block的结构设计中采用大核深度可分离卷积,而没有采用重参数化方法的原因:其它YOLO系列中结构重参数化技术被广泛使用,但有一些副作用,比如训练速度变慢,增加训练占用显存,以及在量化到较低的比特后增加了误差间隙,这需要通过重参数化优化器或量化感知训练来补偿。
Head
- 不同尺度的head之间共享卷积参数,但BN层独立。
Label Assignment and Loss
提出在计算matching cost时使用soft label来扩大高质量匹配和低质量配置之间的差异,从而稳定训练加速收敛。基于SimOTA进行的改动。
- 分类损失引入soft label,就是GFL
- 回归损失添加log,增大了低质量匹配的cost,增大了高质量匹配和低质量匹配之间的差异。
- center损失采用soft center region cost。
Data Augmentation
cross-sample数据增强比如MixUp和CutMix有两个缺点:(1)每个iteration需要load多张图片,增加了data loading cost减慢了训练速度。(2)生成的样本带有噪声有可能不属于真实数据的实际分布,影响模型的训练。
- 引入caching mechanism改进MixUp和CutMix。
- 对于第二点,YOLOX通过使用两阶段的训练策略,第一阶段使用强数据增强,第二阶段使用弱数据增强,由于第一阶段的强数据增强包括随机旋转和剪切,导致输入和转换后的box之间有错位,YOLOX在第二阶段增加L1损失来微调回归分支。
为了解耦数据增强和损失函数的使用,本文去除了这些数据增强,在280个epoch的第一个阶段将混合图片的数量增加到8个来补偿数据增强的强度。在最后20个epoch中,切换到Large Scale Jittering,从而在一个与真实数据分布更更一致的doman中对模型进行微调。
Training Strategy
- 为了稳定训练优化器采用AdamW,这个在卷积目标检测模型中很少使用,但在vision transformer中是default。
方法介绍 & 代码解析
骨干网络部分用depth-wise卷积增加了网络深度,因此作者减少了第2个和第3个stage中block的数量,如下表所示,block数量由9减到6延迟降低了20%,但AP也降低了0.5,为了弥补精度的所示,作者在每个stage的最后添加了一个channel attention,实现了更好的精度-速度的权衡。

以RTMDet-s为例,deepen_factor=0.33, widen_factor=0.5,因此每个stage的block数量变成了1-2-2-1。stage2的结构如下

Head部分共享卷积参数,但BN独立。官方实现中在定义head时是分开的,最后将每个head的卷积就赋值为相同。
if self.share_conv:for n in range(len(self.prior_generator.strides)):for i in range(self.stacked_convs):self.cls_convs[n][i].conv = self.cls_convs[0][i].convself.reg_convs[n][i].conv = self.reg_convs[0][i].conv# print(self.cls_convs[n][0]) # 共享conv,但BN独立
ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): SyncBatchNorm(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)
)标签分配的实现在dynamic_soft_label_assigner.py中,基于SimOTA,只不过对cost的计算进行了改进,具体如下,其值为分类cost、回归cost、区域cost的加权和
![]()
cost_matrix = soft_cls_cost + iou_cost + soft_center_prior其中分类cost采用了Generalized focal loss中的quality focal loss
![]()
pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
soft_label = gt_onehot_label * pairwise_ious[..., None]
scale_factor = soft_label - valid_pred_scores.sigmoid()
soft_cls_cost = F.binary_cross_entropy_with_logits(valid_pred_scores, soft_label,reduction='none') * scale_factor.abs().pow(2.0)
soft_cls_cost = soft_cls_cost.sum(dim=-1)其中 \(Y_{soft}\) 是预测框与gt框之间的IoU,作为soft label取来原始的标签1。
当用IoU以及相关变体作为回归损失时,最佳匹配和最差匹配之间的差值小于1,这使得区分高质量匹配和低质量匹配变得困难,因此作者使用IoU的对数作为回归的代价,这增大了低质量匹配即IoU较小匹配的cost
![]()
iou_cost = -torch.log(pairwise_ious + EPS) * self.iou_weight至于区域代价 \(C_{region}\),和FCOS、YOLOX等采用的fixed center prior方法不同,本文采用了一种soft center region cost来稳定dynamic cost的匹配
![]()
distance = (valid_prior[:, None, :2] - gt_center[None, :, :]).pow(2).sum(-1).sqrt() / strides[:, None]
soft_center_prior = torch.pow(10, distance - self.soft_center_radius)数据增强部分,Mosaic和MixUp中引入缓存机制。这一部分实现在mmdet/datasets/transforms/transforms.py中。
在mmdet中要使用Mosaic,需要同时使用MultiImageMixDataset。原本results字典中保存的是一张图的相关信息包括img、gt_bboxes、gt_labels等,在MultiImageMixDataset类中调用Mosaic类中的get_indexes方法,随机再挑出其它三张图的索引。然后将这3张图的信息放到列表中作为key 'mix_results'的value加到原始的results中,这样results就包含了4张图的信息。
而在CachedMosaic中,是维护了一个缓存列表self.results_cache,max_cached_images指定最大缓存数量,默认为40,作者指出10张缓存就可以满足随机的要求了。
def __init__(self,*args,max_cached_images: int = 40,random_pop: bool = True,**kwargs) -> None:super().__init__(*args, **kwargs)self.results_cache = []self.random_pop = random_popassert max_cached_images >= 4, 'The length of cache must >= 4, ' \f'but got {max_cached_images}.'self.max_cached_images = max_cached_images在原始mosaic中,每个iteration需要从整个训练集中随机挑选3张与当前张进行combine,而在cachedmosaic中是从cache中挑选3张,因此挑选索引的原始大小不同,如下
# mosaic
def get_indexes(self, dataset: BaseDataset) -> int:"""Call function to collect indexes.Args:dataset (:obj:`MultiImageMixDataset`): The dataset.Returns:list: indexes."""indexes = [random.randint(0, len(dataset)) for _ in range(3)]return indexes# cachedmosaic
def get_indexes(self, cache: list) -> list:"""Call function to collect indexes.Args:cache (list): The results cache.Returns:list: indexes."""indexes = [random.randint(0, len(cache) - 1) for _ in range(3)]return indexes首先进行append和pop更新缓存列表
# cache and pop images
self.results_cache.append(copy.deepcopy(results))
if len(self.results_cache) > self.max_cached_images:if self.random_pop:index = random.randint(0, len(self.results_cache) - 1)else:index = 0self.results_cache.pop(index)然后根据get_indexes方法得到的索引从缓存列表中得到mix_results,其中包含3张图片的信息用于与当前图片进行组合,当前图片保存在results中。
indices = self.get_indexes(self.results_cache)
mix_results = [copy.deepcopy(self.results_cache[i]) for i in indices]
而在原始的mosaic中,results中除了当前图片还包含从整个训练集中挑选的3张图片,即mix_results包含在results中传进函数的。
assert 'mix_results' in results
results_patch = copy.deepcopy(results['mix_results'][i - 1])