Words&Contents
Home | Interactive Visual Data Analysis
Book Outline
这本书对视觉、互动和分析方法进行了系统而全面的概述,作为数据可视化方面比较好的读物;
目录
Words&Contents
Book Outline
(一)Introduction
1.Basic Considerations
1.1 Visualization ,Interaction , and Computation
1.2 Five Ws of Interactive Visual Data Analysis
2.introductory Examples
2.1 Start Simple
2.2 Enhancing the Data Analysis
2.3 Consider Advanced Techniques
3.Book Outlines
(一)Introduction
信息时代,数据已经变成了一个非常有价值的商品,我们如何 make sense of data ? 如何利用分析数据从而得出一些有价值的信息?
1.Basic Considerations
对可视化的一些基本的术语给予一些认识:
1.1 Visualization ,Interaction , and Computation

这个定义我认为对整个可视化的概括的更加全面,不仅仅是一次性的绘制图,而是随着insigt的揭露进行交互来不断探究;
1.2 Five Ws of Interactive Visual Data Analysis
为了开发出有效的数据分析工具,必须考虑到该工具的使用环境。因而我们遵循five W的变体来进行探究:Ws: What, why, who, where, and when.
(1)What data are to be analyzed?
有许多中类型的数据,针对不同类型的数据有个体特征,例如数据规模、维度和异质性;
(2)Why are the data analyzed?
帮助人们实现目标,而对于目标即包含多种分析任务,例如识别数据值或者根据数据设定相关的模式;
(3)Who will analyze the data?
这个暂时个人理解是决策者才是需要分析数据的;
(4)Where will the data be analyzed?
普通的工作场所当然是具有显示器、鼠标和键盘的经典桌面设置。然而,也有大型的显示墙和交互式表面,为交互式可视化数据分析提供了新的机会。
(5)When will the data be analyzed?
绝大数是根据自身的需求所决定;
这5个Ws表明了数据分析的工具往往会受到多个因素的影响,对于What和Why这两个因素的影响往往是至关重要的,这往往决定了我们的工作必须是针对某一个任务,即是定制的,不通用的。同时Who,即主观的因素,感知能力、认知、背景知识和专业等也会影响视觉驱动和交互控制的工具。Where和When这两个因素,影响不太大,但是当我们考虑到数据分析要在多个异构显示上运行、支持协作会话或遵循针对特定领域的工作流时,这两个因素可以起到很重要的作用,并且能够使得工作具有更大的亮点,使得更加的专业。
2.introductory Examples
从一些基础的可视化表示到一些高级的分析场景,不仅给出了交互式可视化的强大能力,并且也分析了设计的决策和挑战。
2.1 Start Simple

一个简单的例子,主要是针对于雨果《悲惨世界》中的人物关系图,这种一般graph可以采用Node-Link diagram,只有图表的结构很难把其中的关系显示出来。图中,每一个人物被可视化为一个节点,人物之间的关系表示为边,这样能够比较明显的表示该数据集中的关系。
针对每一个人物,根据数据集中表示的属性,其中每个节点根据id来进行识别,对于边来说,有权重、边的起点和终点。因此,在图中,边的连接往往决定了节点人物的重要性,因而用颜色来进行编码节点的度,当节点的度数越高,此时也用节点的大小来突出重要的人物;针对边的权重这个性质,我们使用边的宽度来表示,当边的权重越高,说明这个关系较为重要,则边越宽;

notes: 这里的布局主要采用的是强制定向布局算法(Force-directed Layout Algorithm),也称为是力导向布局算法,是一种常用于图形和网络可视化的布局算法怕,它模拟了物理系统中的力和运动原理,通过相互作用的力来确定节点的位置。
2.2 Enhancing the Data Analysis
上述的算法对于较为简单的数据集是非常好的,但是数据集相对复杂的时候就难以展示了,例如 climate networks,节点数量以及边的连线会导致视觉混杂的问题;
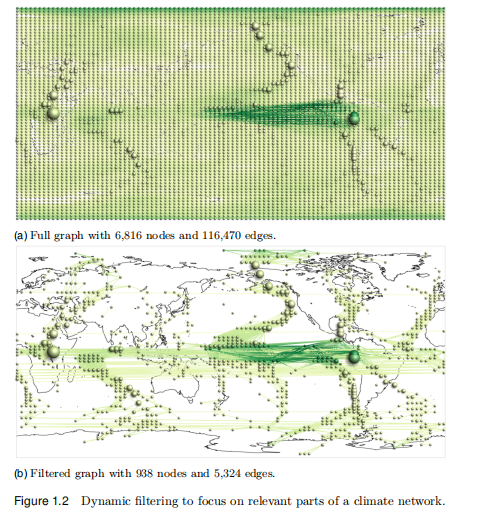

2.3 Consider Advanced Techniques
综上两个小节,使用了动态过滤和多个视图来对整个数据集有一个较为全面的overview,但是,使用交互式可视化分析数据也会有一些局限。可视化必须适应可用的显示空间。交互不应该让用户做太多的事情。分析计算必须及时地产生结果。
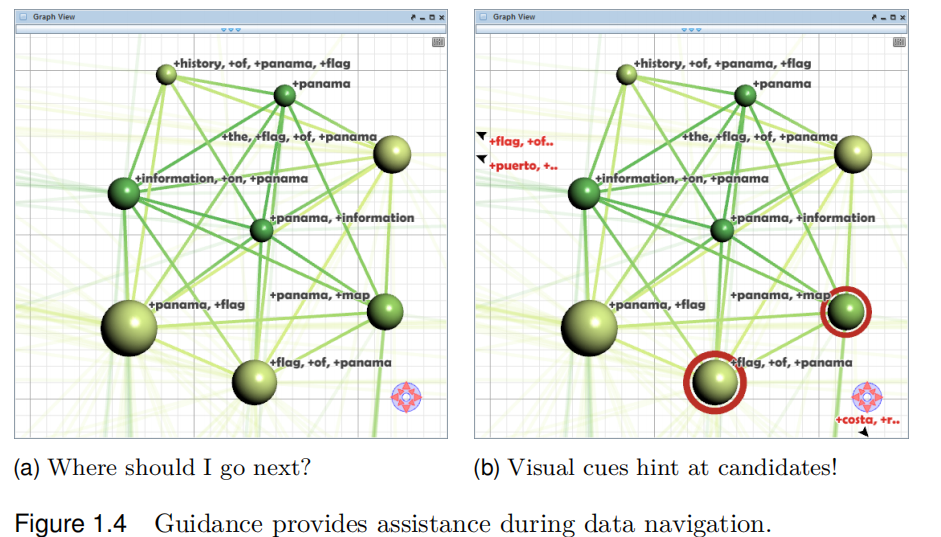
当我们考虑到这两个限制的时候,想出了两个方法:
(1)指导用户进行数据分析;
Some Questions are valued to be answered.
(2)扩大屏幕空间可视化。
可以考虑使用多个显示屏或者多个用户共同协作的方式来解决;
3.Book Outlines(见第一部分)
参考: