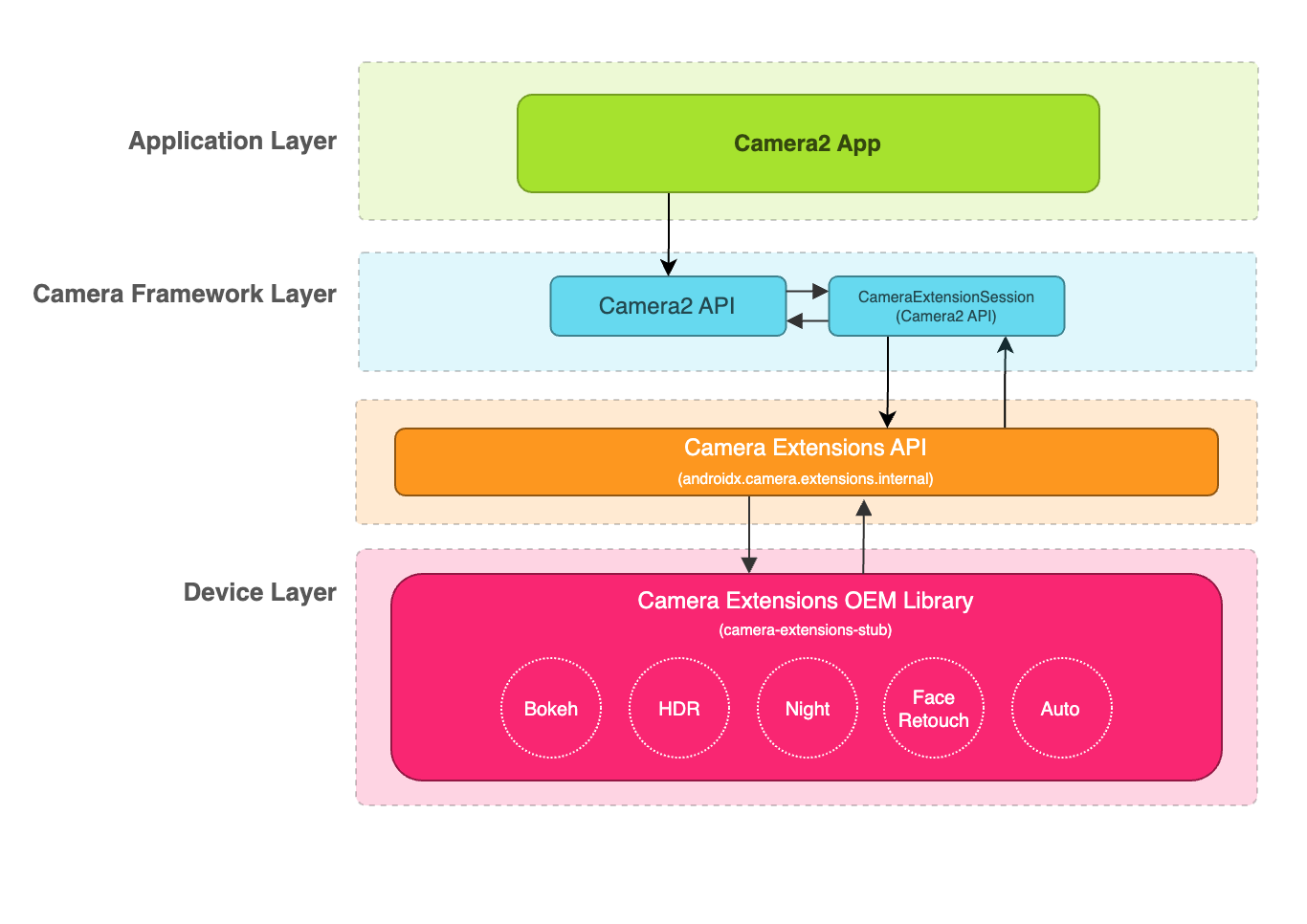
提示:RAM++模型:环境安装、数据准备与说明、模型推理、模型finetune、模型pretrain等
文章目录
- 前言
- 一、环境安装
- 二、数据准备与解读
- 1.数据下载
- 2.数据标签内容解读
- 3.标签map内容解读
- 三、finetune训练
- 1.微调训练命令
- 2.load载入参数问题
- 3.权重载入
- 4.数据加载问题
- 5.设备不匹配报错
- 6.运行结果
- 四、pretrain预训练
- 1.预训练命令
- 2.swin_large_patch4_window12_384_22k.pth权重
- a.下载
- b.权重加载修改
- 3.ram_plus_tag_embedding_class_4585_des_51.pth权重
- a.下载
- b.权重加载修改
- 4.变量设备匹配问题
- 5. 预训练成功显示
- 五、数据加载源码简单解读
- 六、推理
前言
随着SAM模型分割一切大火之后,又有RAM模型识别一切,RAM模型由来可有三篇模型构成,TAG2TEXT为首篇将tag引入VL模型中,由tagging、generation、alignment分支构成,随后才是RAM模型,主要借助CLIP模型辅助与annotation处理trick,由tagging、generation分支构成,最后才是RAM++模型,该模型引入semantic concepts到图像tagging训练框架,RAM++模型能够利用图像-标签-文本三者之间的关系,整合image-text alignment 和 image-tagging 到一个统一的交互框架里。作者也将三个模型整合成一套代码,本文将介绍RAM++模型,主要内容包含环境安装、数据准备与说明、模型推理、模型finetune、模型pretrain等内容,并逐过程解读,也帮读者踩完所有坑,只要按照我我步骤将会实现RAM流畅运行。
TAG2TEXT论文链接:点击这里
RAM论文链接:点击这里
RAM++论文链接:点击这里
github官网链接:点击这里
一、环境安装
说实话,环境安装按照官网来,没有报什么错,可直接推理运行,但是训练可能会缺一些东西,后续将介绍,环境安装如下:
Install recognize-anything as a package:
pip install git+https://github.com/xinyu1205/recognize-anything.git
Or, for development, you may build from source
git clone https://github.com/xinyu1205/recognize-anything.git
cd recognize-anything
pip install -e .
二、数据准备与解读
1.数据下载
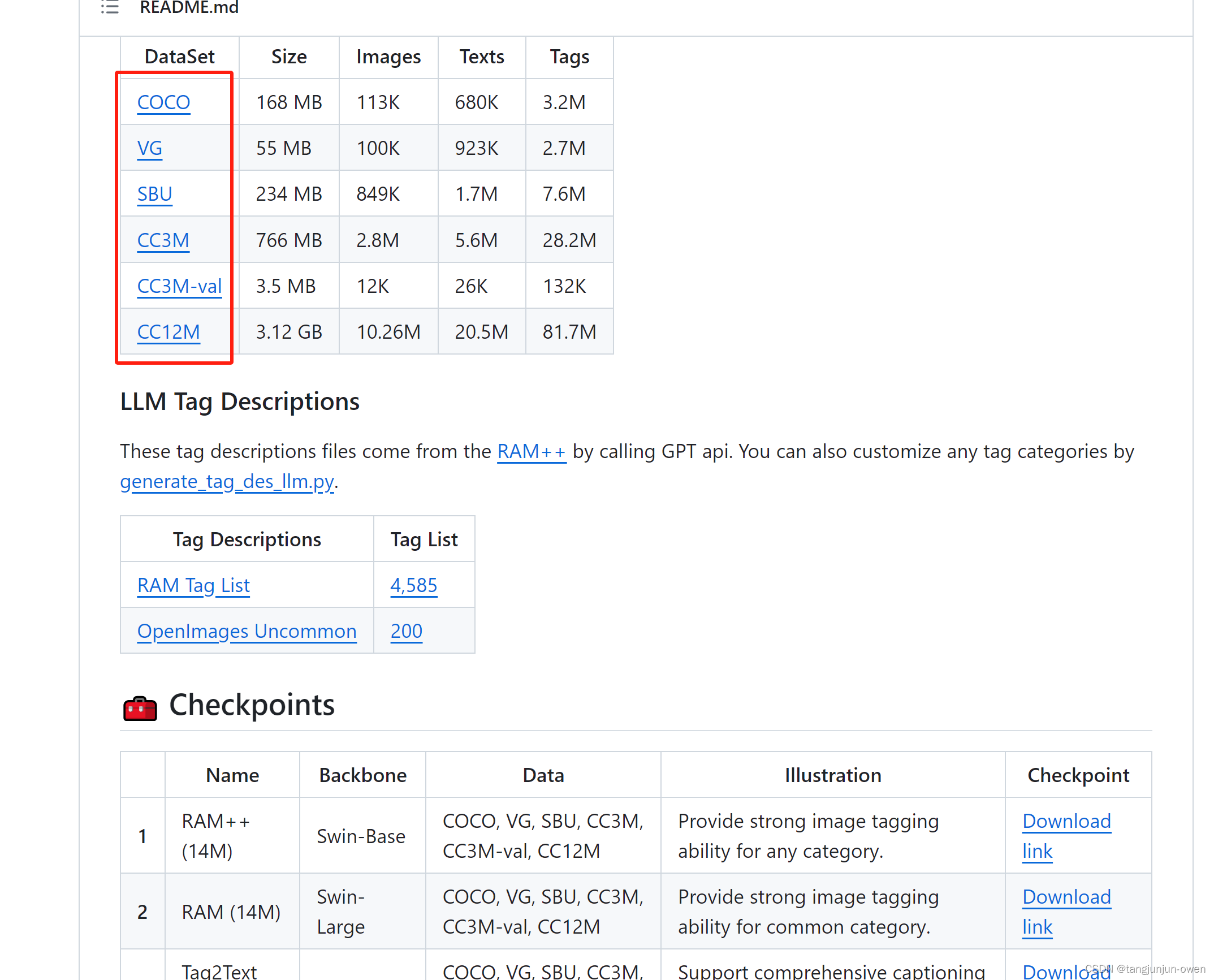
图像数据需要根据相应内容去下载,而数据标签下载可以去github代码官网链接,点击下面红框即可。当然你也可转到下面网页链接。
数据标签下载:https://huggingface.co/datasets/xinyu1205/recognize-anything-dataset-14m/tree/main
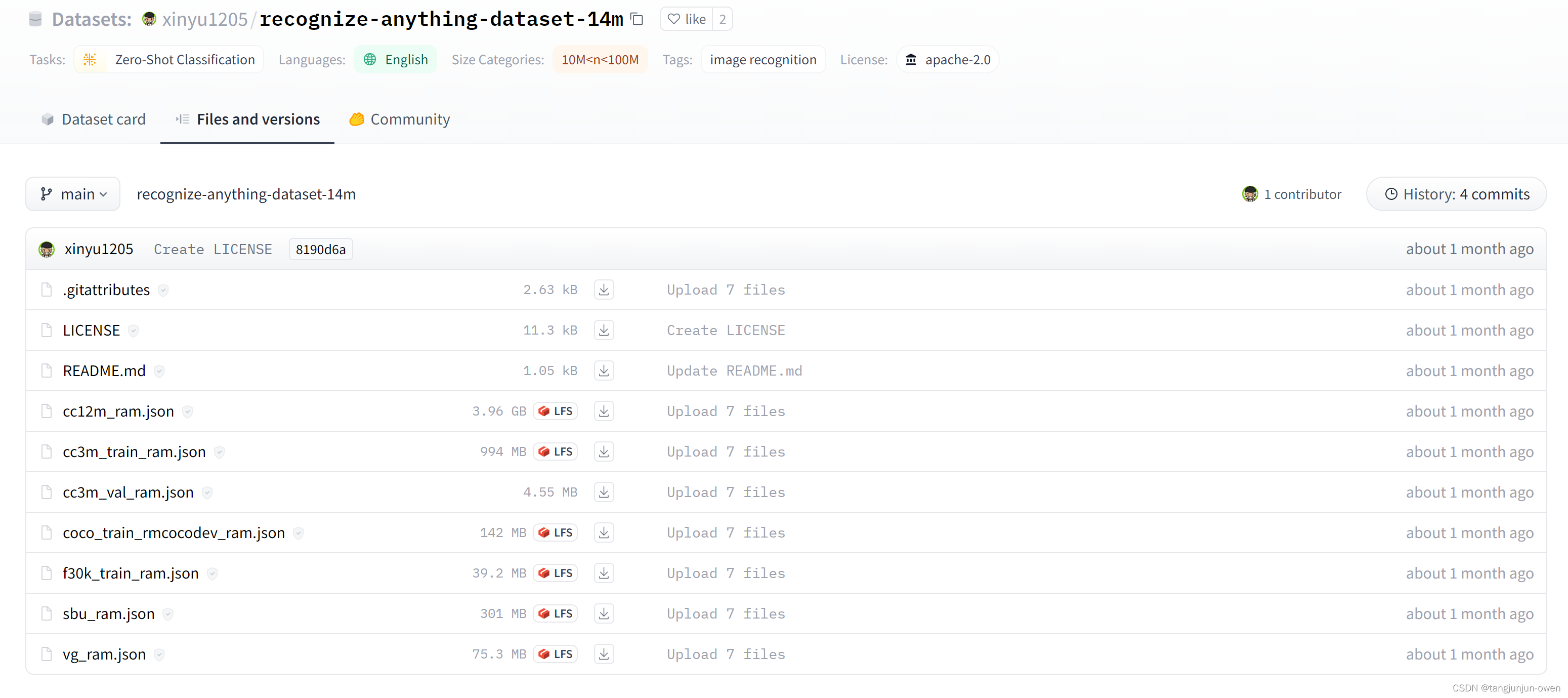
当进入标签页面如下:
2.数据标签内容解读
当你下载了标签后,你能发现标签实际是列表,列表中每个数据又是一个字典,包含image_path、caption、union_label_id、parse_label_id字典,以vg_ram.json标签举列,我们取第一个元素,如下图所示:
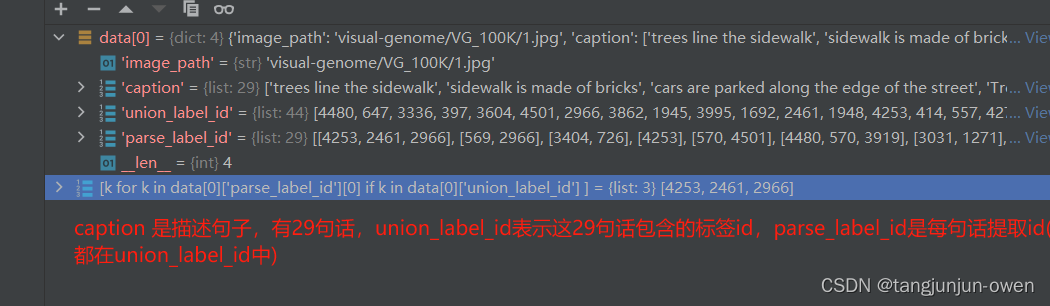
我们进一步展开该数据,你会重点发现parse_label_id是一个二维列表,每一行是对对应caption描述取的tag而union_label_id是一维列表,parse_label_id中tag都能在union_label_id找到,反之不行。如下图:
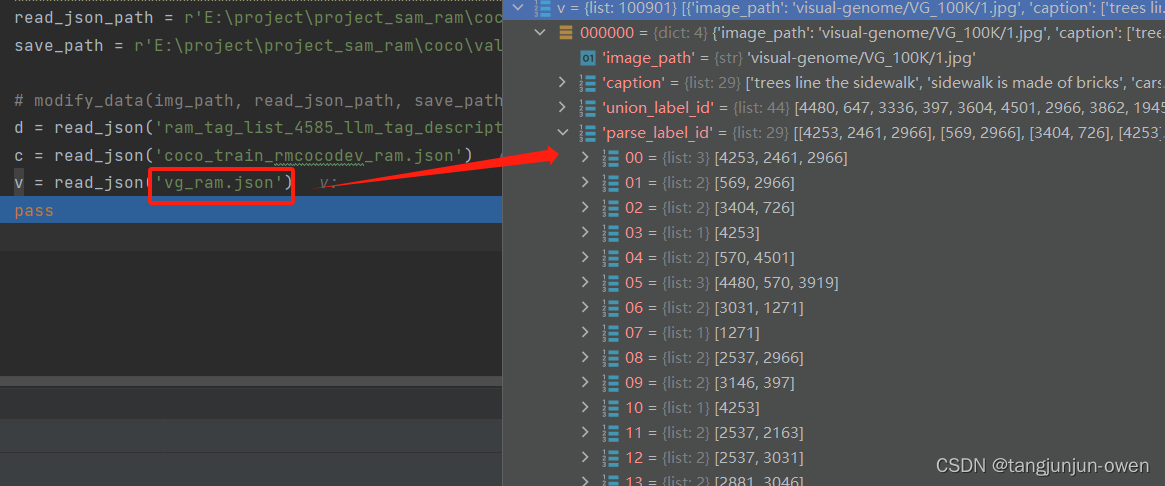
3.标签map内容解读
我们在上面可看到parse_label_id与union_label_id是数字,那么这些数字如何得到,必然有一个映射表,该表是ram_tag_list_4585_llm_tag_descriptions.json文件中,该文件也是一个列表,列表中每个元素是一个字典,该字典key就是tag,value是一个列表,是对key的描述,我查看value的列表有50个描述。其中该文件列表位置(索引)就代表key(tag),这也是parse_label_id与union_label_id的数字。如下:
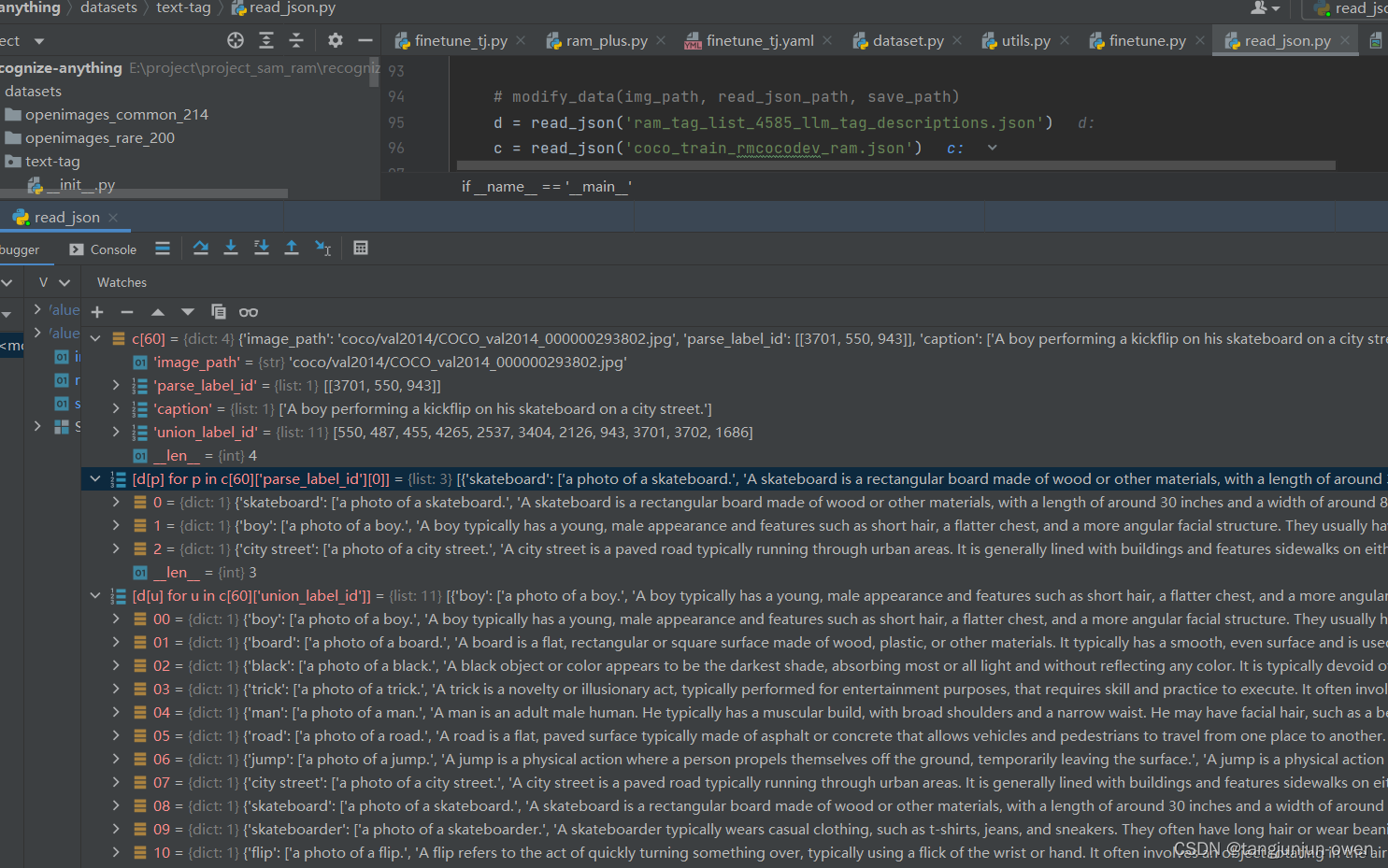
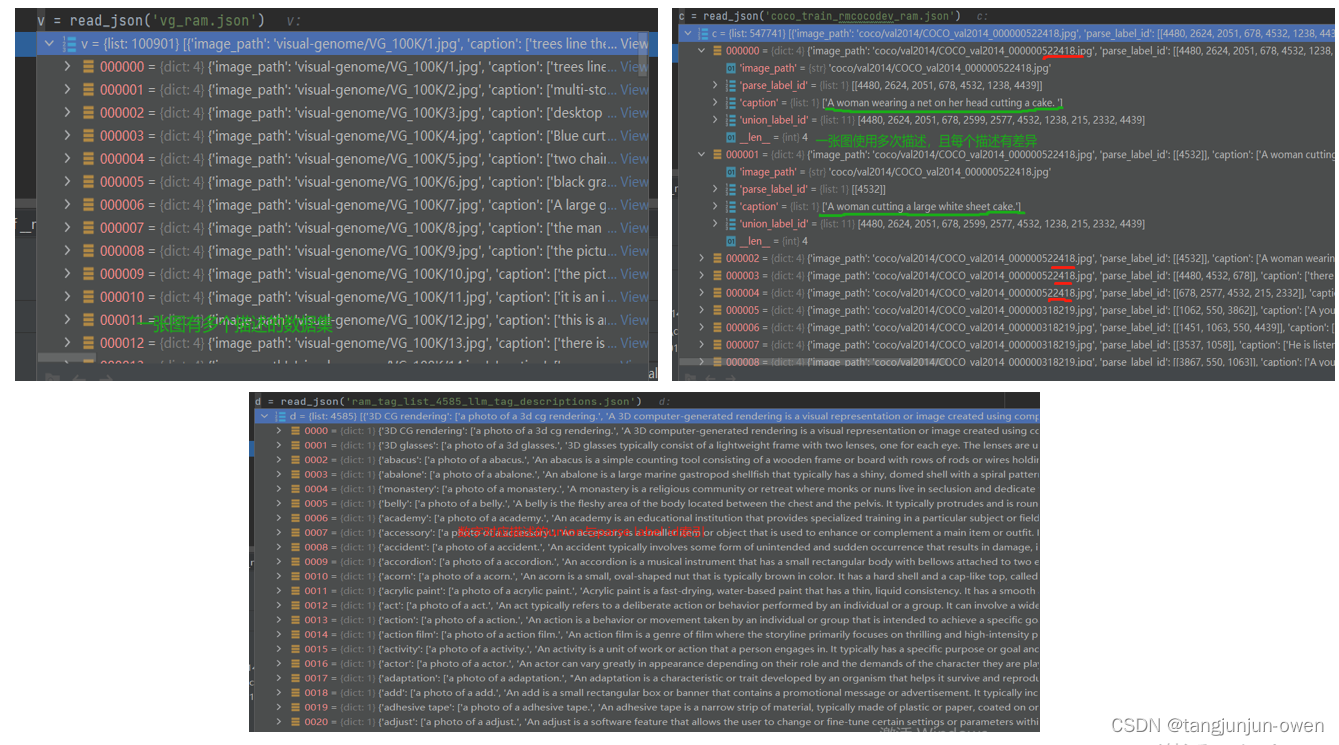
当然,RAM模型数据可以一个元素的一张图有多个描述如下左图,也可以多个元素表示同一张图,进行多个描述,如下:
三、finetune训练
1.微调训练命令
可看出训练使用finetune.py文件,参数配置是finetune.yaml文件,模型类型选择是ram_plus文件,如下:
python -m torch.distributed.run --nproc_per_node=8 finetune.py \ --model-type ram_plus \ --config ram/configs/finetune.yaml \ --checkpoint outputs/ram_plus/checkpoint_04.pth \ --output-dir outputs/ram_plus_ft
我是直接运行finetune.py文件,使用远程链接方式运行的!
2.load载入参数问题
当执行微调命令时,我遇到yaml载入问题,如下图:
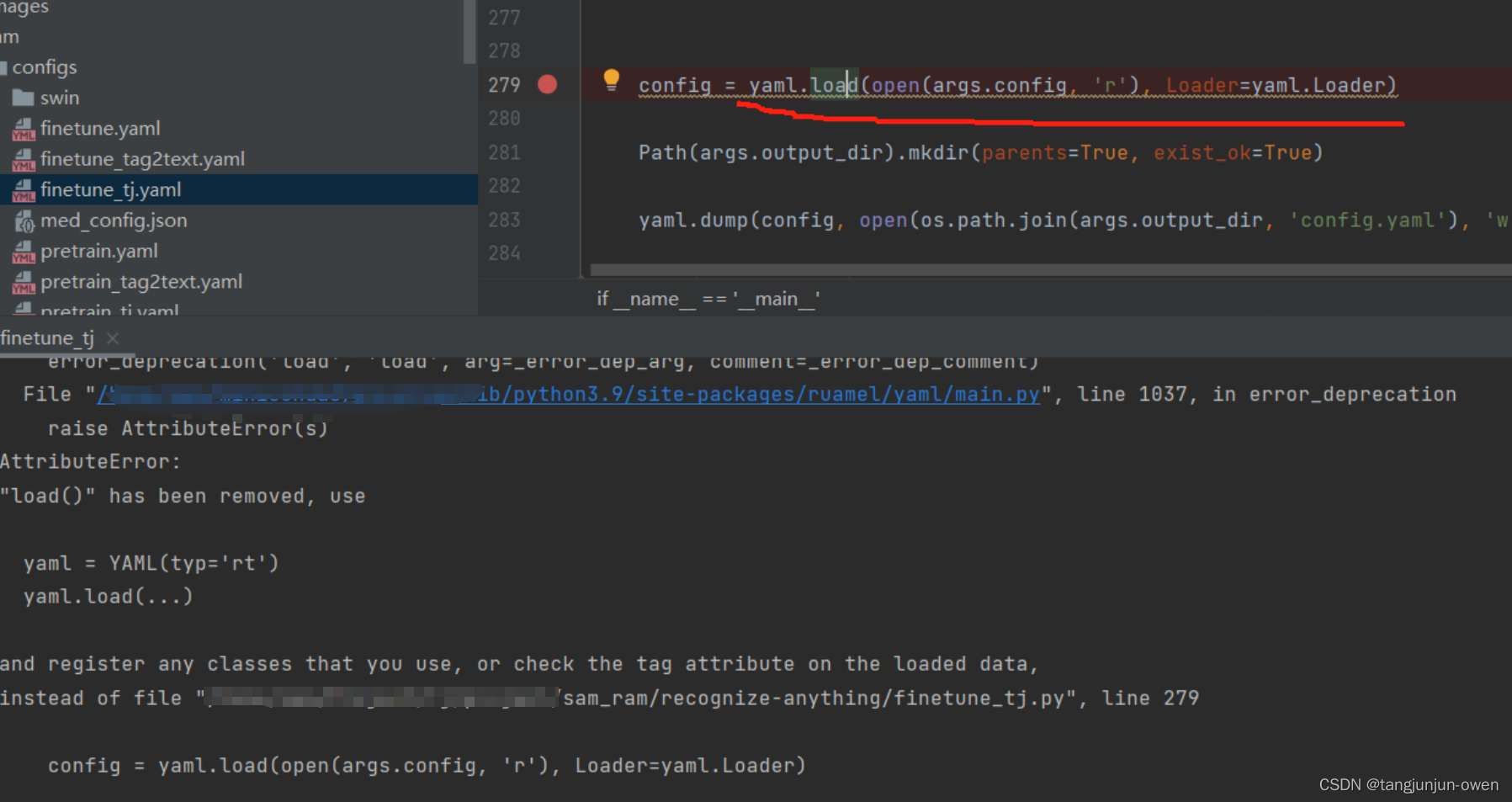
当然这个是个小问题,与环境相关,可能你们不会遇到,若遇到可尝试我的解决方法:
导入包ruamel.yaml,更改原有代码
config = yaml.load(open(args.config, 'r'), Loader=yaml.Loader)
为以下代码即可:
import ruamel.yaml yaml = ruamel.yaml.YAML(typ='rt') config = yaml.load(open(args.config, 'r'))
注:该问题pretrain可能也会遇到。
3.权重载入
第二个问题,模型权重 模型权重载入需要修改,根据你的需求可修改权重路径,如下图: 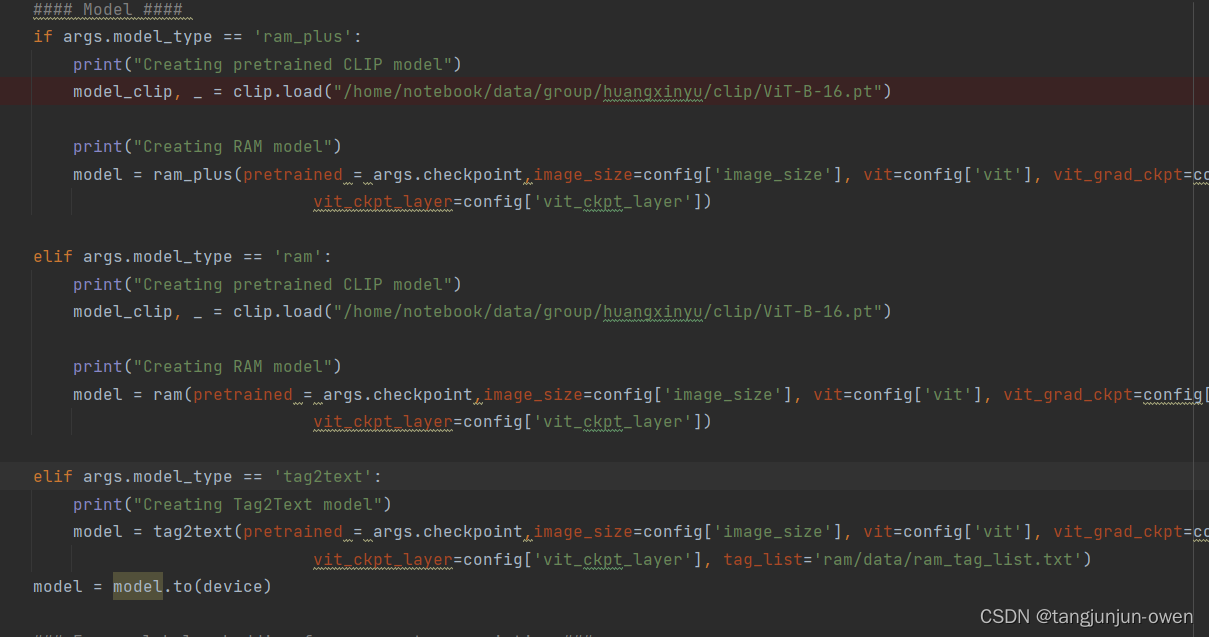 我使用ram++,将
我使用ram++,将model_clip, _ = clip.load("/home/notebook/data/group/huangxinyu/clip/ViT-B-16.pt")中的地址替换即可。
权重下载地址如下:
_MODELS = {
"RN50":"https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101":"https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4":"https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
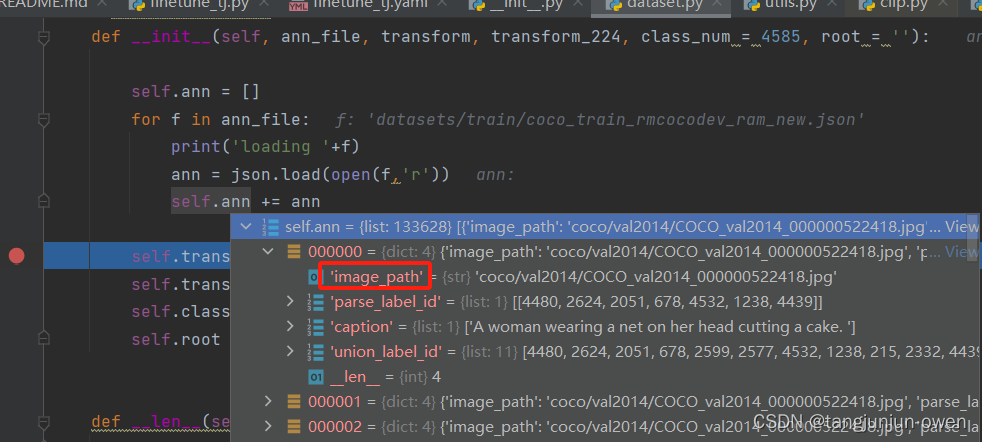
4.数据加载问题
需在finetune.yaml文件中设定image_path_root: “” 参数,使得该参数与下图image_path合并为图像绝对路径,我设定如下:
image_path_root: "/home/Project/recognize-anything/datasets/train"
图像路径如下图所示:
5.设备不匹配报错
运行预训练命令依然会报错,如下:
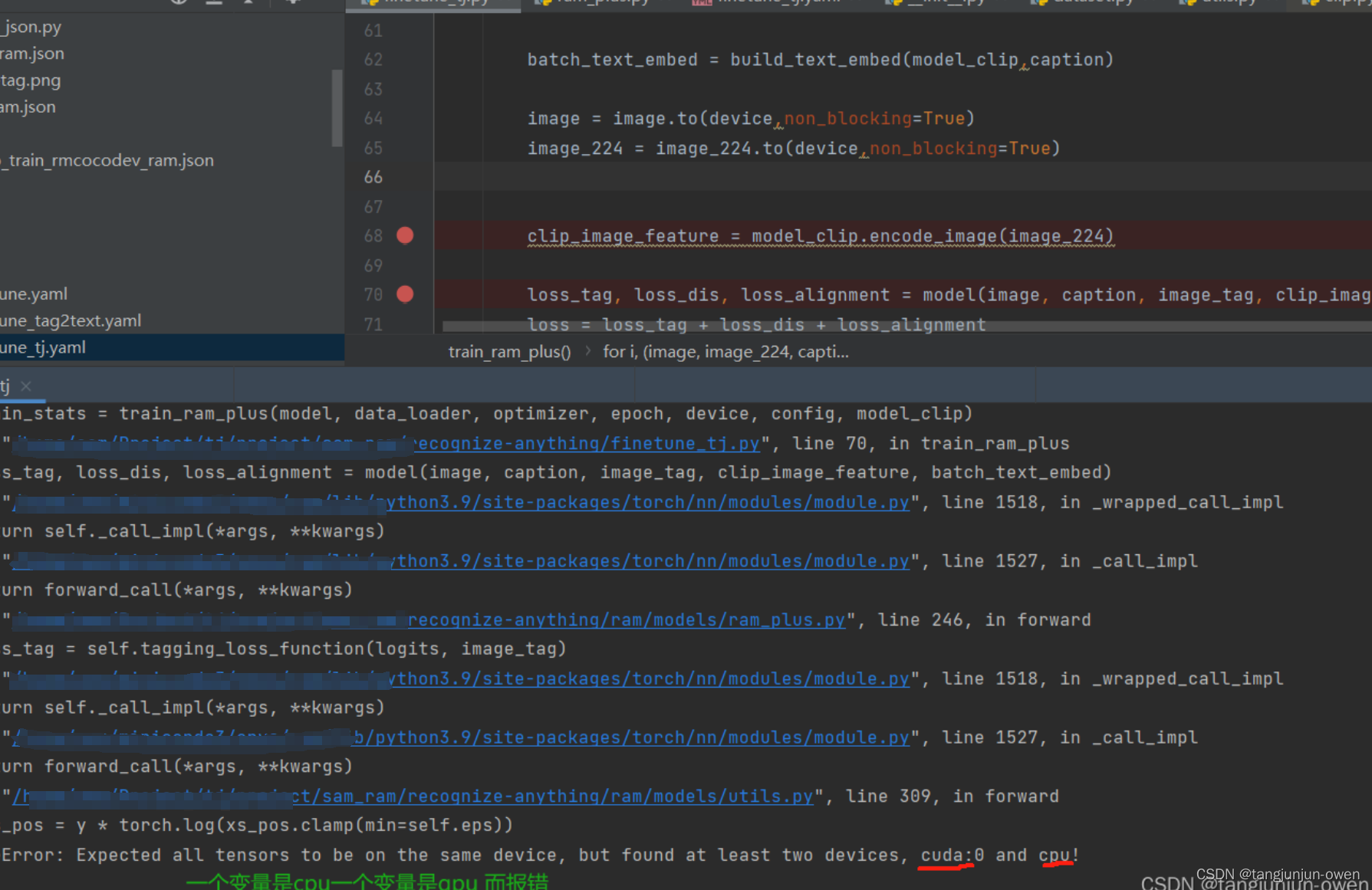
该问题也是小问题,就是变量设备不匹配问题,在finetune.py文件,为image_tag变量指定设备,添加一句代码:
image_tag = image_tag.to(device,non_blocking=True)
修改后整体代码如下:
for i, (image, image_224, caption, image_tag, parse_tag) in enumerate(metric_logger.log_every(data_loader, print_freq, header)): optimizer.zero_grad() batch_text_embed = build_text_embed(model_clip,caption) image = image.to(device,non_blocking=True) image_224 = image_224.to(device,non_blocking=True) image_tag = image_tag.to(device,non_blocking=True) clip_image_feature = model_clip.encode_image(image_224) loss_tag, loss_dis, loss_alignment = model(image, caption, image_tag, clip_image_feature, batch_text_embed) loss = loss_tag + loss_dis + loss_alignment
6.运行结果
之后运行结果如下: 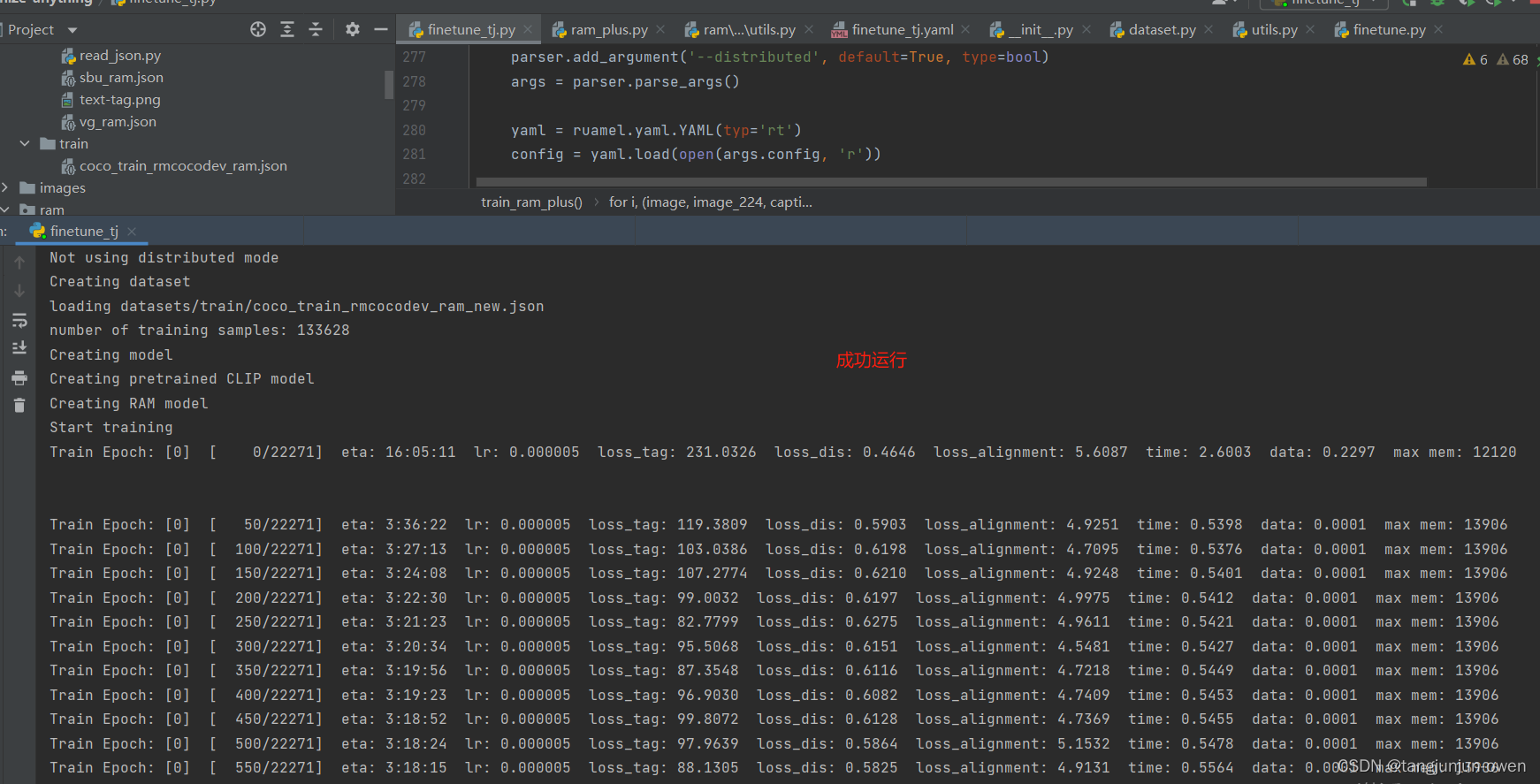
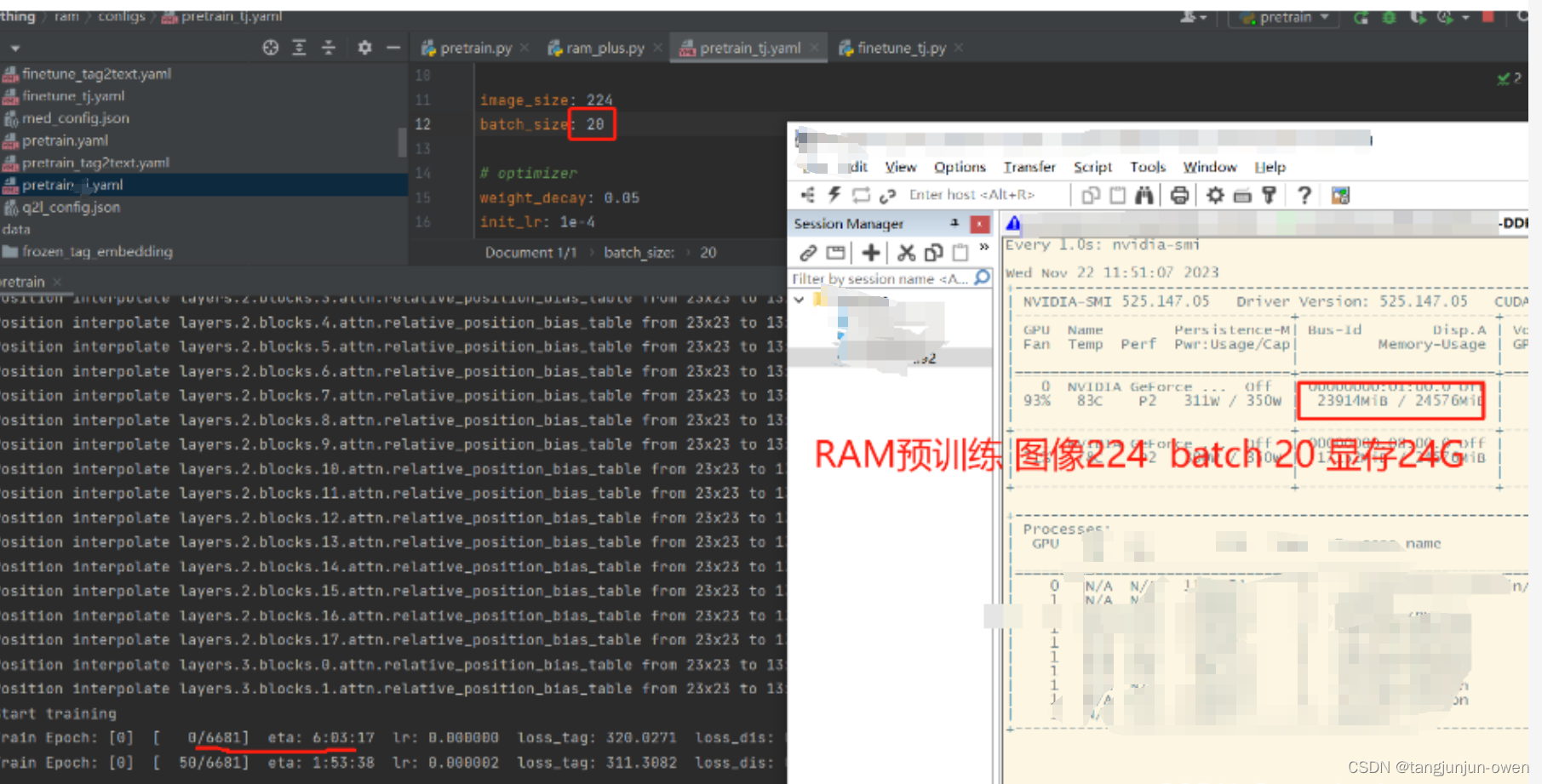
我们进一步可发现使用一张3090显卡,batch为20即可满负载,如下:
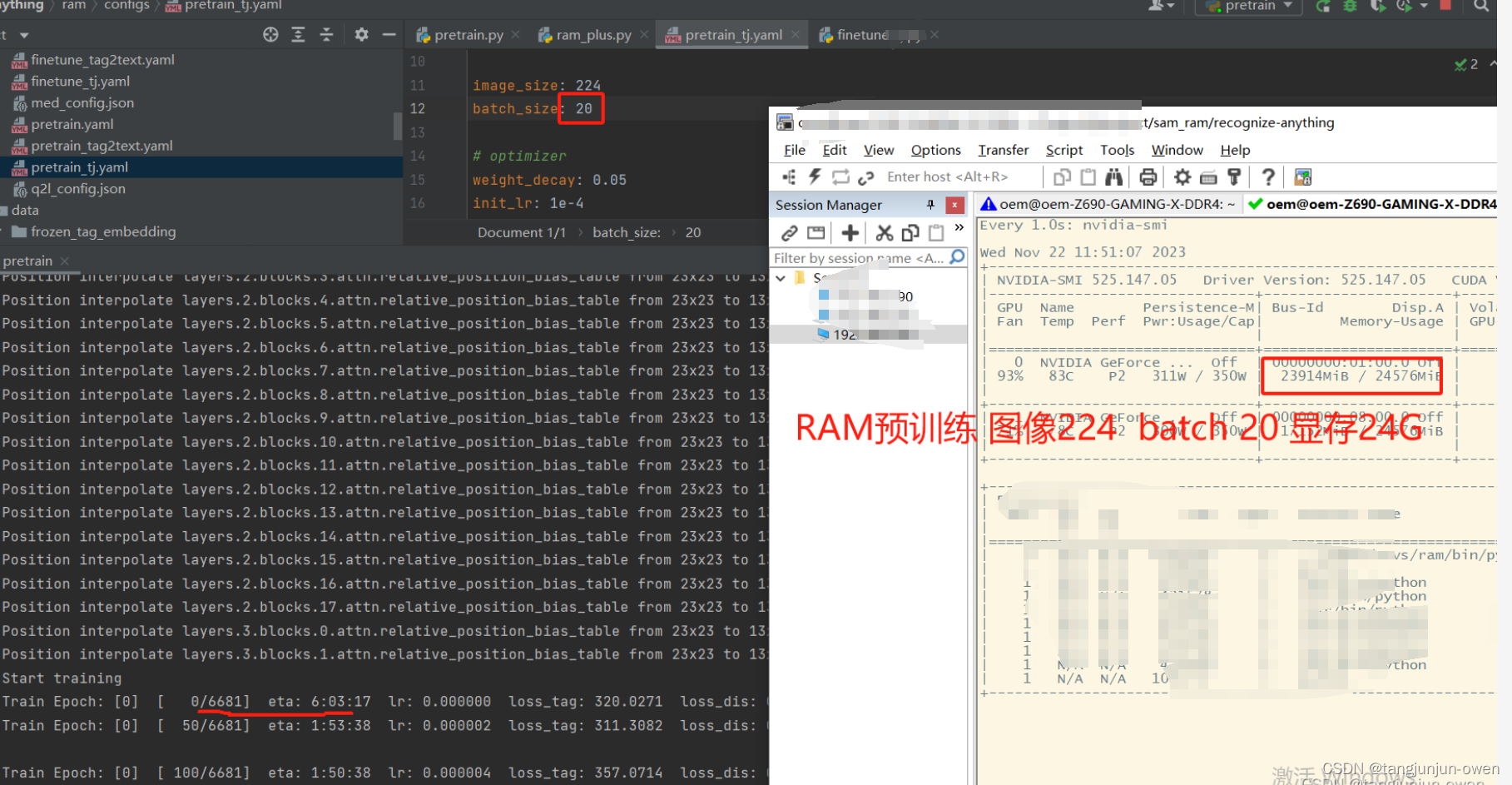
注:以上微调内容某些在训练时候遇到,按其修改即可!
四、pretrain预训练
1.预训练命令
可看出预训练使用pretrain.py文件,参数配置是pretrain.yaml文件,模型类型选择是ram_plus文件,如下:
python -m torch.distributed.run --nproc_per_node=8 pretrain.py \--model-type ram_plus \--config ram/configs/pretrain.yaml \--output-dir outputs/ram_plus
2.swin_large_patch4_window12_384_22k.pth权重
a.下载
但你直接使用该命令时候,会报如下错误:
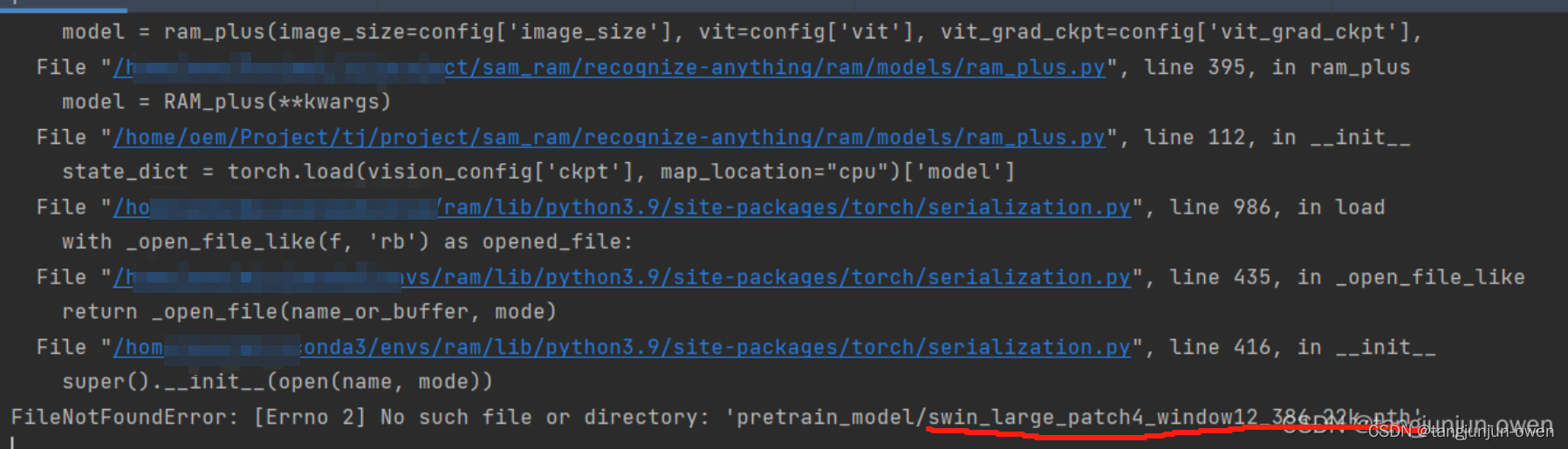
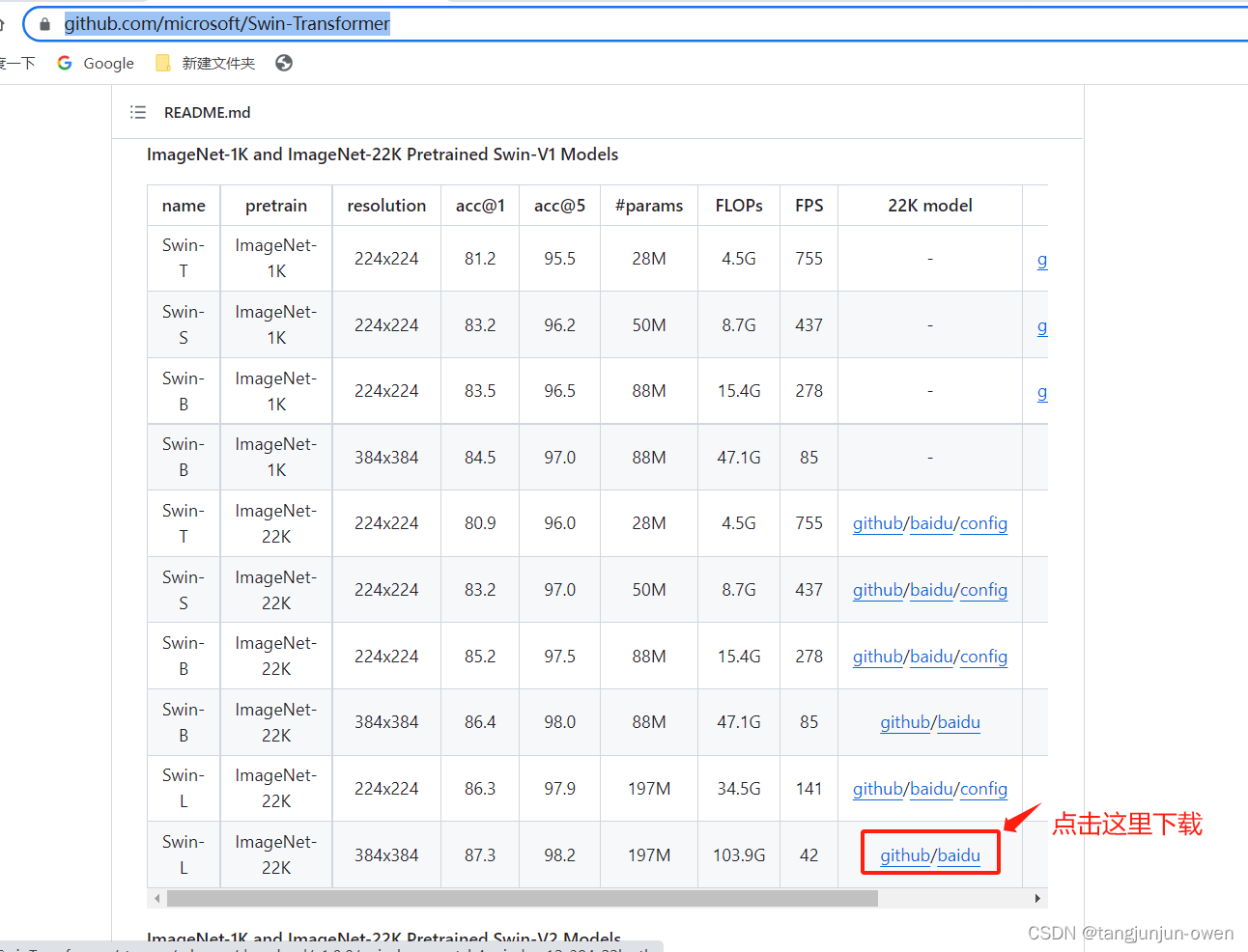
以上报错是因为缺失相应权重swin_large_patch4_window12_384_22k.pth,我们只需通过下面链接点击这里,获得如下图权重下载即可,如下:
b.权重加载修改
对应权重下载实际是pretrain.yaml参数设置的vit: 'swin_l'与image_size: 224共同决定,我们将其定位为config_swinl_224.json文件,如下图:
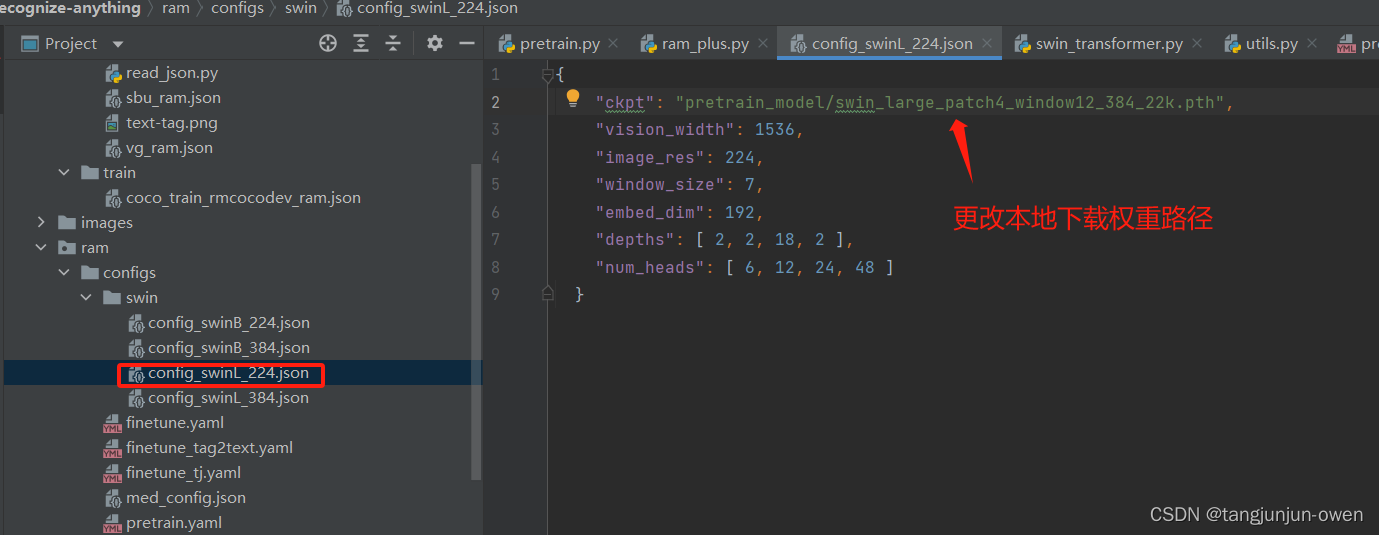
上面我们已知权重路径更改位置,我们将其下载权重绝对路径替换即可,如下代码示列:
{
{"ckpt": "绝对路径位置/swin_large_patch4_window12_384_22k.pth","vision_width": 1536,"image_res": 224,"window_size": 7,"embed_dim": 192,"depths": [ 2, 2, 18, 2 ],"num_heads": [ 6, 12, 24, 48 ]}}
3.ram_plus_tag_embedding_class_4585_des_51.pth权重
a.下载
当你再次使用该命令时候,会报如下错误:

不要慌张,依然是权重问题,我们只需链接:点击这里,可在huggingface下载我们想要的权重文件。
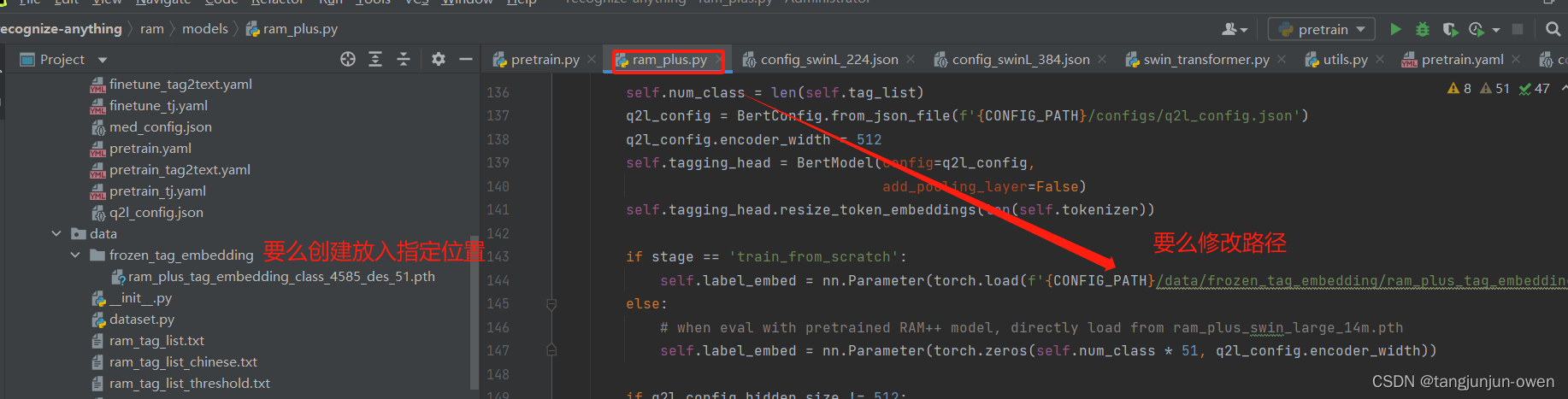
b.权重加载修改
对应权重下载后有2种方法可实现权重正确加载,第一将下载权重放到指定路,第二将在源码ram_plus.py改成绝对路径,如下图:
4.变量设备匹配问题
当你很开心再次使用预训练命令时,会报如下错误(该错误在finetune也会出现):
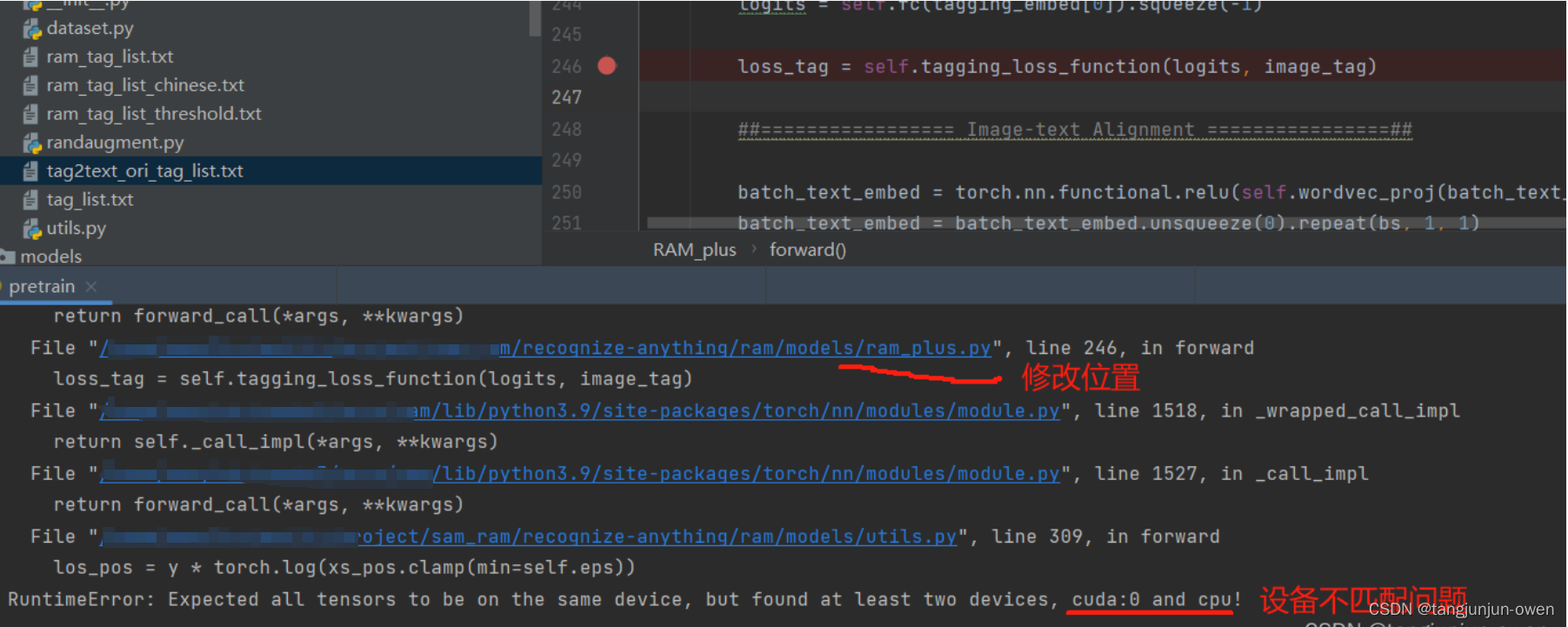
该问题也是小问题,就是变量设备不匹配问题,从上图报错地方可追述到ram_plus.py文件除了问题,实际决定该问题是在pretrain.py文件调用那里,主要是image_tag是一个传入参数未能给定device,我们在pretrain.py下面代码给定即可,我也建议在pretrain.py修改,而不要动报错地方修改,你只需添加image_tag = image_tag.to(device, non_blocking=True)指定设备,修改如下:
for i, (image, caption, image_tag, parse_tag) in enumerate(metric_logger.log_every(data_loader, print_freq, header)):if epoch==0:warmup_lr_schedule(optimizer, i, config['warmup_steps'], config['warmup_lr'], config['init_lr'])optimizer.zero_grad()batch_text_embed = build_text_embed(model_clip,caption)image = image.to(device,non_blocking=True)image_tag = image_tag.to(device, non_blocking=True) #5. 预训练成功显示
如出现下图表示预训练成功,如下:
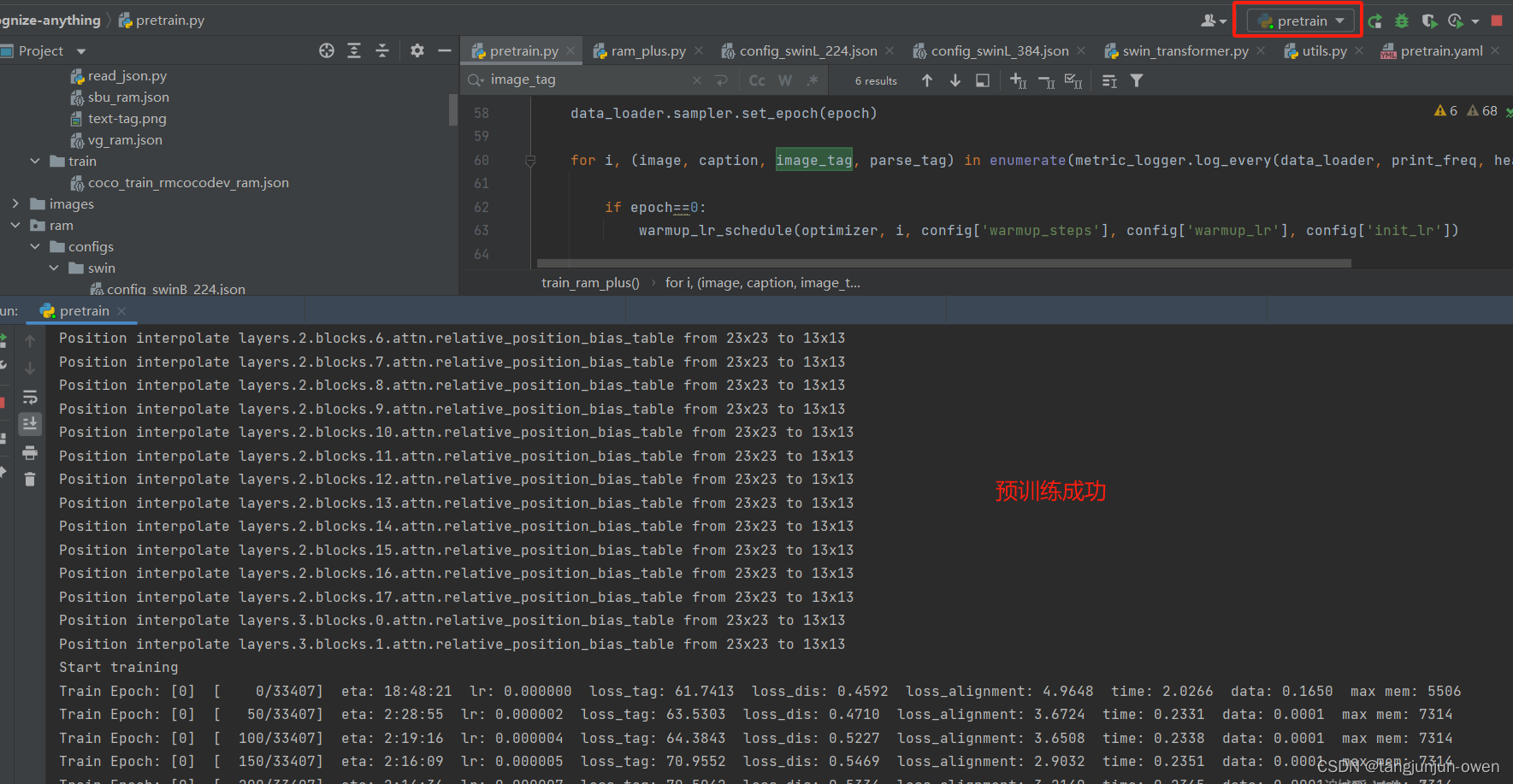
我们进一步可发现使用一张3090显卡,batch为20即可满负载,如下:
五、数据加载源码简单解读
标签源码如下,可看到图像做了2次加工一次该模型本身使用image,一次为图像特征提取swin模型使用image_224,而caption为一句话(若为多句随机选择一句),该句话直接通过clip的文本编码获得特征,image_tag 是union_label_id, parse_tag是parse_label_id,具体如下代码:
def __getitem__(self, index): ann = self.ann[index] image_path_use = os.path.join(self.root, ann['image_path'])image = Image.open(image_path_use).convert('RGB') image = self.transform(image)image_224 = Image.open(image_path_use).convert('RGB') image_224 = self.transform_224(image_224)# image_tag 是union_label_idnum = ann['union_label_id']image_tag = np.zeros([self.class_num])image_tag[num] = 1image_tag = torch.tensor(image_tag, dtype = torch.long)caption_index = np.random.randint(0, len(ann['caption'])) # 有的数据集有多个描述caption = pre_caption(ann['caption'][caption_index],30)# parse_tag是parse_label_idnum = ann['parse_label_id'][caption_index]parse_tag = np.zeros([self.class_num])parse_tag[num] = 1parse_tag = torch.tensor(parse_tag, dtype = torch.long)return image, image_224, caption, image_tag, parse_tag六、推理
推理可直接使用命令,指定权重我在pretrain已给出链接,可自行下载:
python batch_inference.py \ --model-type ram_plus \ --checkpoint pretrained/ram_plus_swin_large_14m.pth \ --dataset openimages_common_214 \ --output-dir outputs/ram_plus
当然,你也可以使用我的代码,我是将一个文件夹循环推理,并将推理结果打印于图上便于查看,如下:
'''* The Recognize Anything Plus Model (RAM++)* Written by Xinyu Huang
'''
import argparse
import osimport numpy as np
import randomimport torchfrom PIL import Image
from ram.models import ram_plus
from ram import inference_ram as inference
from ram import get_transformparser = argparse.ArgumentParser(description='Tag2Text inferece for tagging and captioning')
parser.add_argument('--image',help='path to dataset',default='images/demo/demo1.jpg')
parser.add_argument('--pretrained',help='path to pretrained model',default='路径位置/ram_plus_swin_large_14m.pth')
parser.add_argument('--image-size',default=384,type=int,metavar='N',help='input image size (default: 448)')import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFontdef cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=20):if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 创建一个可以在给定图像上绘图的对象draw = ImageDraw.Draw(img)# 字体的格式fontStyle = ImageFont.truetype("/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", textSize, encoding="utf-8") # 绘制文本draw.text((left, top), text, textColor, font=fontStyle)# 转换回OpenCV格式return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)def build_dir(out_dir):if not os.path.exists(out_dir):os.makedirs(out_dir,exist_ok=True)return out_dirif __name__ == "__main__":args = parser.parse_args()device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')transform = get_transform(image_size=args.image_size)#######load modelmodel = ram_plus(pretrained=args.pretrained,image_size=args.image_size,vit='swin_l')model.eval()model = model.to(device)total = sum(p.numel() for p in model.parameters()) # 统计个数print("模型参数总量: %.2f million\t" % (total / 1e6), " 以float32模型内存占用:%.2f M" % (total * 4 / 1e6))# 下面是推理file_root='/推理文件路径/sam_test' # 这个是多个文件夹路径save_file_path=build_dir('runs')for file_name in os.listdir(file_root):save_path=os.path.join(save_file_path,file_name)img_root=os.path.join(file_root,file_name)for img_name in os.listdir(img_root):img_path=os.path.join(img_root,img_name)image = transform(Image.open(img_path)).unsqueeze(0).to(device)res = inference(image, model)# print("Image Tags: ", res[0])# print("图像标签: ", res[1])img = cv2.imread(img_path)N=int(len(res[1])/2)r1 = res[1][:N]r2 = res[1][N:]# r3 = res[1][2*N:]img = cv2ImgAddText(img, r1, 40, 50, textColor=(255, 0, 0), textSize=20)img = cv2ImgAddText(img, r2, 40, 200, textColor=(255, 0, 0), textSize=20)# img = cv2ImgAddText(img, r2, 40, 300, textColor=(255, 0, 0), textSize=40)build_dir(save_path)cv2.imwrite(os.path.join(save_path, img_name), img)