适用平台:Matlab 2020及以上
本程序参考中文EI期刊《基于MEA⁃BP神经网络的建筑能耗预测模型》,程序注释清晰,干货满满,下面对文章和程序做简要介绍。
适用领域:风速预测、光伏功率预测、发电功率预测、碳价预测等多种应用。

传统的BP(Backpropagation)神经网络算法是一种常用的神经网络训练算法,它通过信号的正向传播和误差的逆向传播来不断调整网络的权值和阈值,以实现对建筑能耗数据的预测。BP算法可以模拟人的思维过程,具有较低的计算成本和较快的处理速度,但在其超参数的选择方面存在一定的局限性。
思维进化算法(Mind evolutionary algorithm,MEA)算法是一种受遗传算法启发的进化算法,它通过随机生成个体、评价个体得分、产生优胜个体和临时个体等步骤来优化解空间中的个体。MEA-BP神经网络的创新点主要在于将MEA算法与BP神经网络相结合,并应用于建筑能耗预测模型。MEA-BP神经网络算法使用MEA算法来初始化BP神经网络的权值和阈值,从而加速神经网络的训练过程,提高能耗预测的准确度。
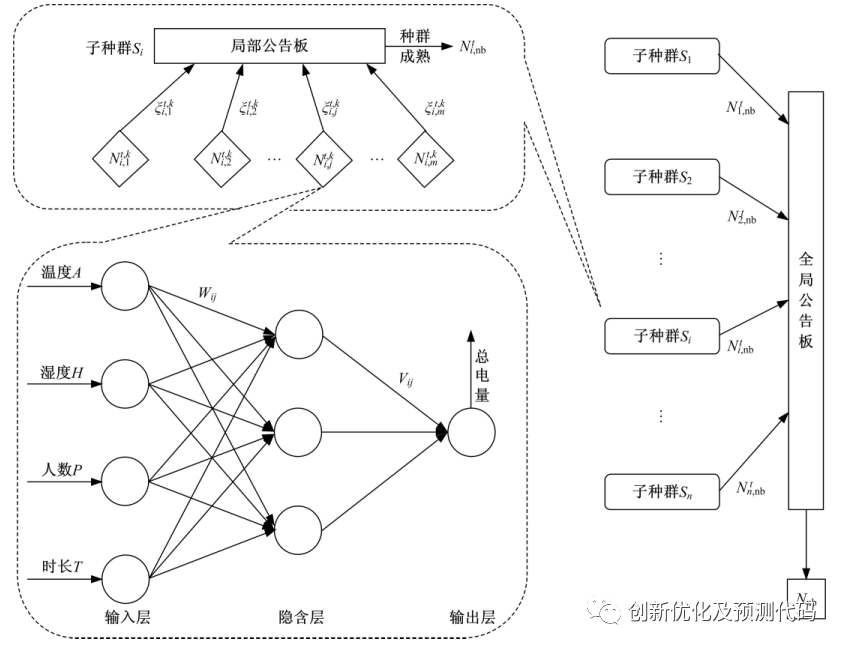
MEA-BP算法的创新点主要包括以下几个方面:
结合了思维进化算法和BP神经网络算法:MEA-BP算法将思维进化算法作为优化算法应用于BP神经网络中,利用MEA优化BP网络的初始权值和阈值,从而提高了BP网络的训练效率和预测精度。
引入了“趋同”和“异化”思想:MEA-BP算法在优化过程中引入了“趋同”和“异化”思想,取代了传统遗传算法中的“交叉”和“变异”操作。通过“趋同”步骤中的个体斗争,获得局部最优个体,然后在“异化”步骤中比较优胜子种群和临时子种群的得分,保留得分高的子种群,进一步优化解的搜索效果。
全局最优解作为BP神经网络的初始权值和阈值:MEA-BP算法通过优化得到的全局最优解作为BP神经网络的初始权值和阈值,从而缩短了BP网络的训练时间,并提高了网络的性能和预测准确性。
综上,MEA-BP算法通过结合思维进化算法和BP神经网络算法,并引入“趋同”和“异化”思想,提高了BP神经网络的训练效率和预测准确性,具有较好的优化选择效果。
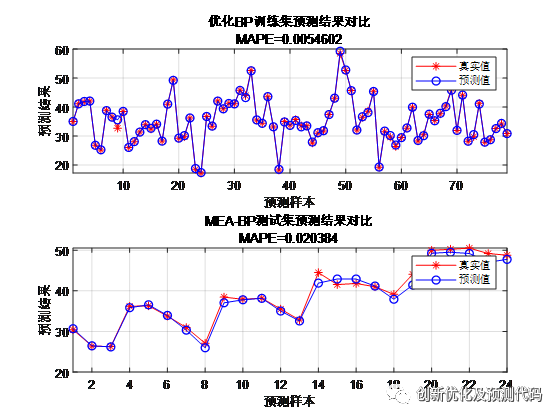
传统BP预测结果:
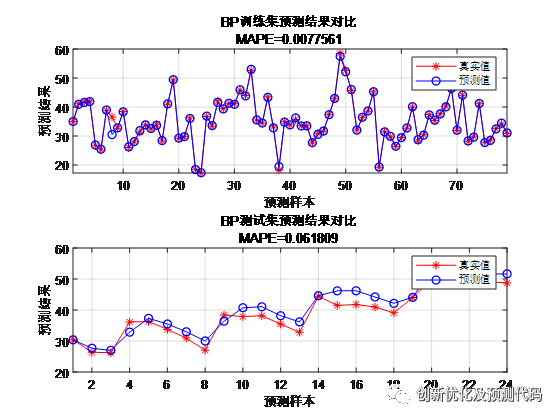
MEA-BP预测结果:
完整程序:
%% 思维进化算法应用于优化BP神经网络的初始权值和阈值
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行%% 导入数据
data = xlsread('时序数据集.xlsx');%% 随机划分训练集和测试集
temp = 1:103;P_train = data(temp(1: 79), 1 : 7)'; % 1~7列为特征
T_train = data(temp(1: 79), 8)'; % 第8列为真实值
M = size(P_train, 2);P_test = data(temp(80: end), 1 : 7)';
T_test = data(temp(80: end), 8)';
N = size(P_test, 2);%% 归一化
% 训练集
[Pn_train,inputps] = mapminmax(P_train);
Pn_test = mapminmax('apply',P_test,inputps);
% 测试集
[Tn_train,outputps] = mapminmax(T_train);
Tn_test = mapminmax('apply',T_test,outputps);%% 参数设置
popsize = 200; % 种群大小
bestsize = 5; % 优胜子种群个数
tempsize = 5; % 临时子种群个数
SG = popsize / (bestsize+tempsize); % 子群体大小
S1 = size(Pn_train,1); % 输入层神经元个数
S2 = 10; % 隐含层神经元个数
S3 = size(Tn_train,1); % 输出层神经元个数
iter = 500; % 迭代次数%% 随机产生初始种群
initpop = initpop_generate(popsize,S1,S2,S3,Pn_train,Tn_train);%% 产生优胜子群体和临时子群体
% 得分排序
[sort_val,index_val] = sort(initpop(:,end),'descend');
% 产生优胜子种群和临时子种群的中心
bestcenter = initpop(index_val(1:bestsize),:);
tempcenter = initpop(index_val(bestsize+1:bestsize+tempsize),:);
% 产生优胜子种群
bestpop = cell(bestsize,1);
for i = 1:bestsizecenter = bestcenter(i,:);bestpop{i} = subpop_generate(center,SG,S1,S2,S3,Pn_train,Tn_train);
end
% 产生临时子种群
temppop = cell(tempsize,1);
for i = 1:tempsizecenter = tempcenter(i,:);temppop{i} = subpop_generate(center,SG,S1,S2,S3,Pn_train,Tn_train);
endwhile iter > 0%% 优胜子群体趋同操作并计算各子群体得分best_score = zeros(1,bestsize);best_mature = cell(bestsize,1);for i = 1:bestsizebest_mature{i} = bestpop{i}(1,:);best_flag = 0; % 优胜子群体成熟标志(1表示成熟,0表示未成熟)while best_flag == 0% 判断优胜子群体是否成熟[best_flag,best_index] = ismature(bestpop{i});% 若优胜子群体尚未成熟,则以新的中心产生子种群if best_flag == 0best_newcenter = bestpop{i}(best_index,:);best_mature{i} = [best_mature{i};best_newcenter];bestpop{i} = subpop_generate(best_newcenter,SG,S1,S2,S3,Pn_train,Tn_train);endend% 计算成熟优胜子群体的得分best_score(i) = max(bestpop{i}(:,end));end%% 临时子群体趋同操作并计算各子群体得分temp_score = zeros(1,tempsize);temp_mature = cell(tempsize,1);for i = 1:tempsizetemp_mature{i} = temppop{i}(1,:);temp_flag = 0; % 临时子群体成熟标志(1表示成熟,0表示未成熟)while temp_flag == 0% 判断临时子群体是否成熟[temp_flag,temp_index] = ismature(temppop{i});% 若临时子群体尚未成熟,则以新的中心产生子种群if temp_flag == 0temp_newcenter = temppop{i}(temp_index,:);temp_mature{i} = [temp_mature{i};temp_newcenter];temppop{i} = subpop_generate(temp_newcenter,SG,S1,S2,S3,Pn_train,Tn_train);endend% 计算成熟临时子群体的得分temp_score(i) = max(temppop{i}(:,end));end%% 异化操作[score_all,index] = sort([best_score temp_score],'descend');% 寻找临时子群体得分高于优胜子群体的编号rep_temp = index(find(index(1:bestsize) > bestsize)) - bestsize;% 寻找优胜子群体得分低于临时子群体的编号rep_best = index(find(index(bestsize+1:end) < bestsize+1) + bestsize);% 若满足替换条件if ~isempty(rep_temp)% 得分高的临时子群体替换优胜子群体for i = 1:length(rep_best)bestpop{rep_best(i)} = temppop{rep_temp(i)};end% 补充临时子群体,以保证临时子群体的个数不变for i = 1:length(rep_temp)temppop{rep_temp(i)} = initpop_generate(SG,S1,S2,S3,Pn_train,Tn_train);endelsebreak;end%% 输出当前迭代获得的最佳个体及其得分if index(1) < 6best_individual = bestpop{index(1)}(1,:);elsebest_individual = temppop{index(1) - 5}(1,:);enditer = iter - 1;end%% 解码最优个体
x = best_individual;% 前S1*S2个编码为W1
temp = x(1:S1*S2);
W1 = reshape(temp,S2,S1);% 接着的S2*S3个编码为W2
temp = x(S1*S2+1:S1*S2+S2*S3);
W2 = reshape(temp,S3,S2);% 接着的S2个编码为B1
temp = x(S1*S2+S2*S3+1:S1*S2+S2*S3+S2);
B1 = reshape(temp,S2,1);%接着的S3个编码B2
temp = x(S1*S2+S2*S3+S2+1:end-1);
B2 = reshape(temp,S3,1);%% 创建/训练BP神经网络
net_optimized = newff(Pn_train,Tn_train,S2);
% 设置训练参数
net_optimized.trainParam.epochs = 100;
net_optimized.trainParam.show = 10;
net_optimized.trainParam.goal = 1e-4;
net_optimized.trainParam.lr = 0.1;
% 设置网络初始权值和阈值
net_optimized.IW{1,1} = W1;
net_optimized.LW{2,1} = W2;
net_optimized.b{1} = B1;
net_optimized.b{2} = B2;
% 利用新的权值和阈值进行训练
net_optimized = train(net_optimized,Pn_train,Tn_train);%% 仿真测试
t_sim1_optimized = sim(net_optimized,Pn_train);
t_sim2_optimized = sim(net_optimized,Pn_test); % 反归一化
T_sim1_optimized = mapminmax('reverse',t_sim1_optimized,outputps);
T_sim2_optimized = mapminmax('reverse',t_sim2_optimized,outputps); %% 计算各项误差参数
error1 = T_sim1_optimized-T_train; % 测试值和真实值的误差
error2 = T_sim2_optimized-T_test; % 测试值和真实值的误差
MAPE2=mean(abs(error2./T_test)); % 平均百分比误差
MAPE1=mean(abs(error1./T_train)); % 平均百分比误差
%% 优化BP绘图
figure
subplot(2, 1, 1)
plot(1: M, T_train, 'r-*', 1: M, T_sim1_optimized, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'优化BP训练集预测结果对比'; ['MAPE=' num2str(MAPE1)]};
title(string)
xlim([1, M])
gridsubplot(2, 1, 2)
plot(1: N, T_test, 'r-*', 1: N, T_sim2_optimized, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'MEA-BP测试集预测结果对比'; ['MAPE=' num2str(MAPE2)]};
title(string)
xlim([1, N])
grid%% 未优化的BP神经网络
net = newff(Pn_train,Tn_train,S2);
% 设置训练参数
net.trainParam.epochs = 100;
net.trainParam.show = 10;
net.trainParam.goal = 1e-4;
net.trainParam.lr = 0.1;
% 利用新的权值和阈值进行训练
net = train(net,Pn_train,Tn_train);%% 未优化的BP神经网络仿真测试
t_sim1 = sim(net,Pn_train);
t_sim2 = sim(net,Pn_test); % 反归一化
T_sim1 = mapminmax('reverse',t_sim1,outputps);
T_sim2 = mapminmax('reverse',t_sim2,outputps);%% 计算各项误差参数
error1 = T_sim1-T_train; % 测试值和真实值的误差
error2 = T_sim2-T_test; % 测试值和真实值的误差
MAPE2=mean(abs(error2./T_test)); % 平均百分比误差
MAPE1=mean(abs(error1./T_train)); % 平均百分比误差%% 优化BP绘图
figure
subplot(2, 1, 1)
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'BP训练集预测结果对比'; ['MAPE=' num2str(MAPE1)]};
title(string)
xlim([1, M])
gridsubplot(2, 1, 2)
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'BP测试集预测结果对比'; ['MAPE=' num2str(MAPE2)]};
title(string)
xlim([1, N])
grid%% 完整代码:https://mbd.pub/o/bread/ZZeUlJ5p注意:以上代码中的"时序数据集.xlsx"、"ismature"和"initpop_generate"等函数附赠在文末链接和公众号相应推文“阅读原文”处,下载完整压缩包解压即可直接运行。
部分图片来源于网络,侵权联系删除!
欢迎感兴趣的小伙伴关注下方公众号免费获取完整版代码哦~,小编会继续推送更有质量的学习资料、文章程序代码~



![[PyTorch][chapter 64][强化学习-DQN]](https://img-blog.csdnimg.cn/b5d6292946174382ba23a7ca9025f596.png)