🚩纸上得来终觉浅, 绝知此事要躬行。
🌟主页:June-Frost
🚀专栏:C++入门宝典

🔥本文主要探讨C++的语法,并深入了解C++如何针对C语言中存在的不合理之处进行优化改进。
目录:
- ⌛️ 前言
- ⏳ 命名空间
- ✉️ 命名空间的定义
- ✉️ 命名空间的访问
- ⏳输入和输出
- ⏳缺省参数
- ⏳函数重载
- ❤️ 结语
⌛️ 前言
简单了解C++相对于C语言的特性
C++相对于C语言,加入了面向对象的思想。C++提供了类和对象的概念,允许开发者定义自己的数据类型,并封装数据和操作数据的方法。此外,C++还引入了异常处理机制,可以使用try-catch块来捕获和处理异常。另一个重要的特性是模板,它允许开发者编写可处理多种数据类型的泛型代码。此外,C++还提供了许多标准库,包括输入/输出、字符串处理、容器等等,大大提高了开发效率。
⏳ 命名空间
✉️来看这一现象:
#include<stdio.h> #include<stdlib.h>int rand = 0;int main() {printf("%d ", rand);return 0; } //报错:“rand” : 重定义;以前的定义是“函数”
在C语言中,如果大量的变量、函数等都存在于全局作用域中,这可能会导致命名冲突,并且也无法解决这类问题。
命名冲突包含两种:
- 与库的冲突:当系统中包含多个库时,可能会出现命名冲突。特别是当使用开源库时,由于这些库是由不同人编写的,他们可能遵循不同的命名规则,因此很容易产生命名冲突。
- 程序员之间代码的冲突:当多个程序员在同一个项目中工作时,如果他们定义的函数或变量名称相同,就会产生命名冲突。此外,如果系统中有一部分是C语言实现的闭源的静态库或者动态库(有可能是第三方提供的库,或者是合作伙伴提供的库),没有源码,就很难避免命名冲突。
所以在C++中引入命名空间来解决命名冲突和代码保护问题。它允许程序员将相关的标识符(例如变量、函数、类等)组织在一个单独的命名空间中,从而避免与其他代码文件或库中的标识符发生冲突。
此外,命名空间还可以用于封装和隐藏实现细节。通过将实现代码放在一个单独的命名空间中,我们可以将其与使用这些实现的代码分开。这样可以使代码更加模块化和易于维护。
✉️ 命名空间的定义
在C++中,我们可以使用关键字namespace来定义一个命名空间。例如:
namespace example
{//可以定义变量int rand = 0;//可以定义函数int ADD(int x, int y){return x + y;}//可以定义类型struct Stack{int* arr;int top;int capacity;};
}
在这个例子中,我们定义了一个名为example的命名空间。一个命名空间就定义了一个新的作用域,在这个命名空间中定义的标识符将只在该命名空间内部可见,而不会与其它命名空间中的标识符发生冲突。
当然,命名空间也可以进行嵌套。
namespace example
{int rand = 0;namespace sample{int rand = 1;}
}
📙注意:在同一个工程中,如果有多个文件包含相同名称的命名空间,编译器会把它们合成为一个命名空间,这样可以方便管理和维护代码。
✉️ 命名空间的访问
我们可以将命名空间看作仓库,如果想搬运一些东西,就需要一把钥匙打开大门,在C++中,域作用限定符::就是这把钥匙。所以我们可以通过使用命名空间名称及域作用限定符的方式访问成员。

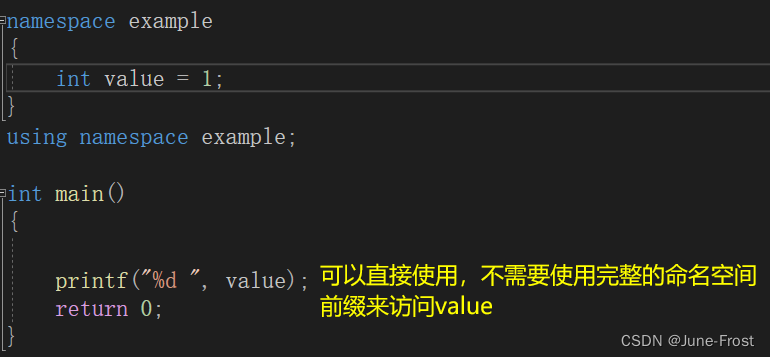
除了这种方式外,我们也可以将仓库的墙拆掉。使用using namespace 命名空间名称 的方式把命名空间展开进行访问。
注意:如果存在命名空间,系统默认不会直接访问它们。展开命名空间意味着将命名空间的成员暴露在全局中,也就是说,可以像访问全局成员一样访问命名空间成员。当然,展开命名空间需要格外注意命名冲突,保证全局成员和命名空间成员的名称不一样。
上述的两种方式都有些弊端:第一种在代码量很大的情况下每次都指定命名空间会很繁琐,第二种会有命名冲突的风险。所以C++还提供了部分展开的方式——使用using将命名空间中某个成员引入 。

⏳输入和输出
在C++中, std是C++标准库的命名空间名 ,C++将标准库的定义实现都放到这个命名空间中。
标准库为开发者提供了很多便利,可以解决常见问题,如输入/输出、字符串和数组操作、数学运算、文件处理等。通过包含特定的头文件,开发者可以方便地使用这些库的功能。
例如, iostream 是一个常见的C++头文件,它包含了用于输入输出的标准函数和类,其中cout输出流对象和cin输入流对象是std命名空间下定义的两个重要对象,分别进行输出操作和输入操作。
cout标准输出对象(控制台)用于将数据输出到终端或控制台。通过使用cout对象,可以将各种类型的数据(如整数、浮点数、字符串等)输出到屏幕上。
#include<iostream>using std::cout;
using std::endl;int main()
{cout << "Hello World" << endl;cout << 3.14 << endl;cout << 8 << endl;return 0;
}
说明:
📘endl是特殊的C++符号,表示换行输出,包含在iostream头文件中。
📘<<是流插入运算符,主要用于将数据插入到输出流中,在上面的代码中,使用流插入运算符将字符串,整数和浮点数插入到cout对象中,并在屏幕上显示相应的输出。
cin标准输入对象(键盘)用于从标准输入读取数据,并且读取数据也是从缓冲区中获取数据,缓冲区为空时,cin的成员函数会阻塞等待数据的到来,一旦缓冲区中有数据,就触发cin的成员函数去读取数据。
#include<iostream>using std::cout;
using std::endl;
using std::cin;int main()
{int value = 0;double num = 0;cin >> value >> num;cout << value << ' ' << num << endl;return 0;
}
说明:
📗>>是流提取运算符,主要用于从输入流中提取数据,这里从cin对象中提取了一个整数给value,提取了一个浮点数给num。
📗C++的输入输出可以自动识别变量类型(其实是运算符重载的应用)。
⏳缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。它允许你在函数调用中省略某些参数,而编译器会自动将它们设置为指定的默认值。如果调用时没有省略,那就使用指定的实参。
在C++,你可以通过在函数原型中为参数提供默认值来定义缺省值。

缺省参数可以分为全缺省和半缺省。
- 全缺省是指在函数声明或定义中为所有参数都指定了默认值。当我们在调用函数时没有提供所有参数的值时,编译器会自动将它们设置为默认值。

- 半缺省是指在函数声明中只为部分参数指定了默认值。

📘 半缺省参数必须从右往左依次来给出,不能间隔着给
注意:
📙缺省参数不能在函数声明和定义中同时出现,防止函数声明和定义之时缺省参数定义的不一致,出现歧义。在多文件的情况下,缺省参数只能在函数声明中出现。
📙缺省值必须是常量或者全局变量。
⏳函数重载
在C语言中,函数的本质地址就是函数名,这意味着不能有多个同名的函数存在。为了实现类似的功能,程序员通常需要使用不同的函数名来区分具有相似功能的函数,这可能会导致函数命名冲突和降低代码的可读性。
C++通过函数重载解决了这个问题,它允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来实现功能类似而数据类型不同的问题。这种特性使得函数的使用更加灵活和方便,提高了代码的复用性和可读性。

有一种情况虽然构成了函数重载,但是实际上是不可以使用的:

重点来了:为什么C++支持函数重载,C语言却不行❓
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。假设现在有3个文件,Fun.c,Fun.h,Test.c,经过预处理后会生成Fun.i 和 Test.i 文件,经过编译会生成汇编代码,形成Fun.s和Test.s文件。
如果Test.c文件中调用过Fun.c的函数,函数没有地址也可以通过编译 ,因为编译器在编译时将函数的代码和信息(如返回类型、参数类型和数量)打包在一起,形成一个函数描述符或函数原型。这个函数描述符或原型包含了函数的元数据,但不包含函数的实际代码,在之后的汇编中,会形成符号表,产生Test.o和Fun.o文件。
在最后链接过程中,链接器会将所有的编译单元(例如.o文件)合并在一起,形成一个可执行文件。在这个过程中,链接器会解析函数调用指令并找到对应的函数地址(编译器发现Test.o调用的函数没有地址,就会去Fun.o的符号表去找地址,然后链接在一起)。如果找不到地址,链接器会报错并停止链接过程。
C语言是通过唯一的函数名称来识别和区分不同的函数,如果允许函数重载,那么同一个函数名称可能会对应多个不同的函数地址。在这种情况下,编译器和链接器将无法根据函数名称来确定正确的函数地址,从而导致链接错误或运行时错误。
C++支持函数重载是因为具有名字修饰(name Mangling),在Linux下,经过函数名修饰规则,会将函数名按照_Z+函数长度 +函数名+类型首字母 的样式修饰,那么只要参数类型不同或者个数不同,修饰出来的名字就不一样,可以匹配唯一地址,就支持了重载。
❤️ 结语
文章到这里就结束了,如果对你有帮助,你的点赞将会是我的最大动力,如果大家有什么问题或者不同的见解,欢迎大家的留言~