Golang学习之结构体和内存对齐、map设计思路
- 结构体和内存对齐
- 内存对齐
- 如何确定一个结构体的对其边界
- map设计思路
- 哈希表与扩容
- bmap的结构
- 练习
- map扩容规则
结构体和内存对齐
- cpu要想从内存读取数据,需要通过地址总线,把地址传输给内存,内存准备好数据,输出到数据总线,交给CPU。
- 如果地址总线只有8根,那这个地址就只有8位,可以表示256个地址,因为表示不了更多的地址就用不了更大的内存。
- 所以256就是8根地址总线最大的寻址空间,要使用更大的内存,就要有更宽的地址总线。
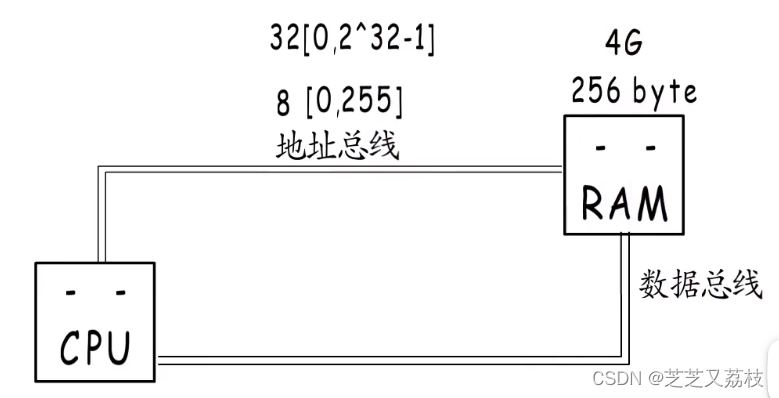
- 每次操作一字节太慢,那就加宽数据总线。
- 要每次操作4字节,就要至少32位数据总线。8字节64位。每次操作的字节数就是机器字长。
- 逻辑上的内存:可以访问任意地址并将其输出到总线。
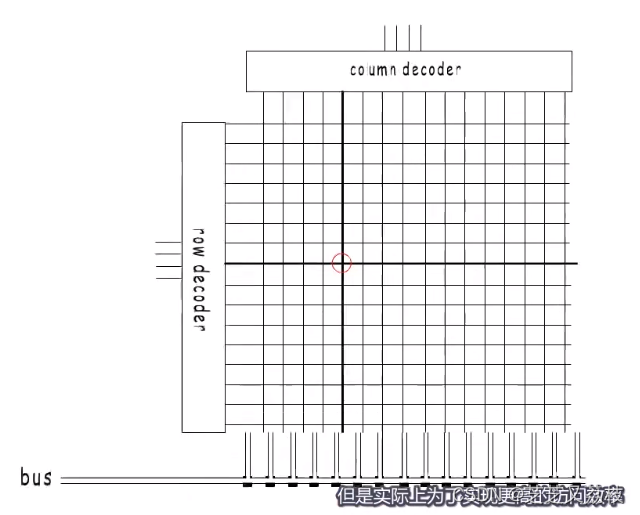
- 实际上为了实现更高的访问效率,典型的内存布局。
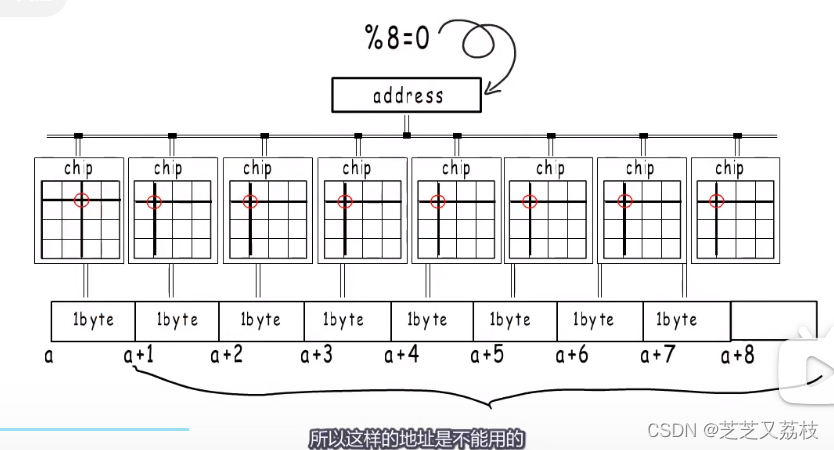
- 一个内存条的一面是一个Rabk,一个Chip包括8个Banks,到Banks就可以通过选择行和列来定位一个地址。

- 非逻辑上连续的存在,但能共用一个地址,各自选择同一个位置的一个字节,再组合起来,作为我们逻辑上认为的连续8个字节。
- 通过这样的并行操作,提高了内存访问效率。
- 但这种方式地址必须是8的倍数,
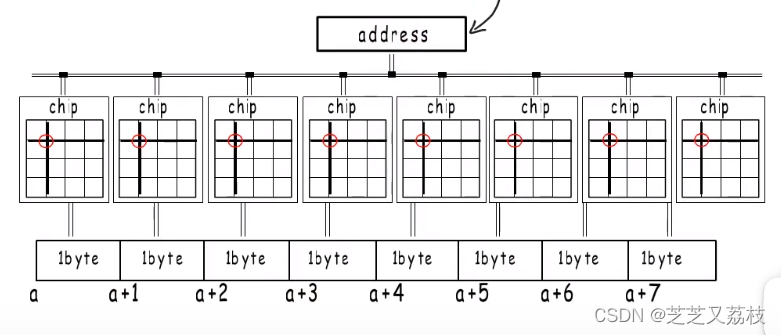
- 不能在一次操作中被同一个地址选中,这样的地址是不能用的。硬件不支持。
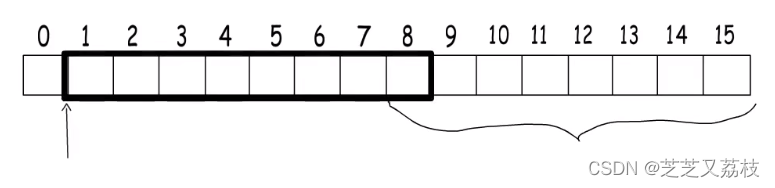
- 之所以有些cpu能支持访问任意地址,是因为其多做了许多处理。
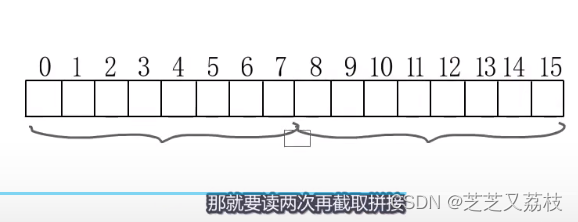
- 例如,想从1开始读8字节的数据,CPU会分两次读,第一次从0到7,但只取后7字节,第二次从8到15,但只取1字节。拼接获得所需数据,但这样做会影响性能。
内存对齐
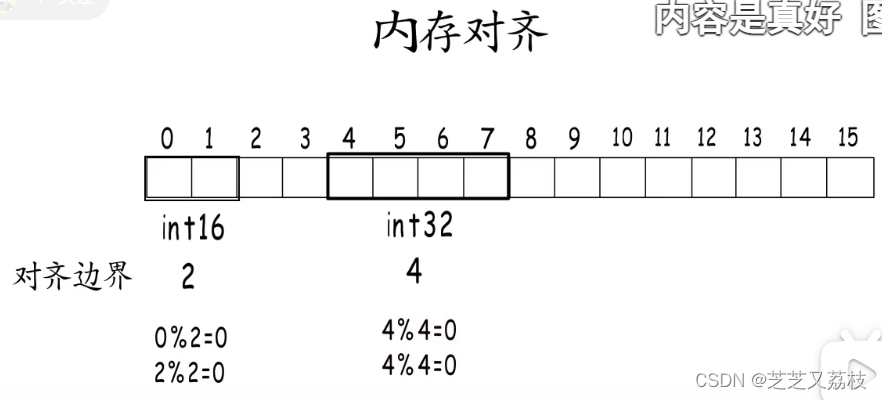
- 编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,这就是内存对齐。
- 每种类型的对齐值就是它的对其边界。
- 内存对齐要求数据存储地址以及占用的字节数都要是它对齐边界的倍数,所以int32不能从2开始,要从4开始。
- 如何确定每种类型的对应边界?这与平台有关

- 被Go语言成为寄存器宽度的这个值,可以理解为机器字长,也是平台对应的最大对齐边界。
- 而数据类型的对齐边界是取类型大小与平台最大对齐边界中较小的那个


- 为何不统一平台最大对齐边界
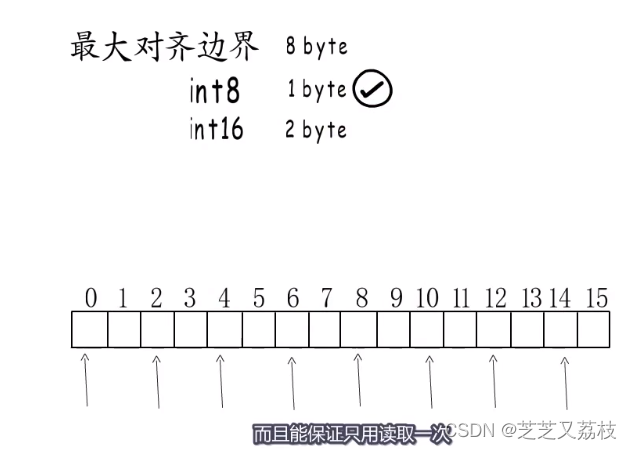
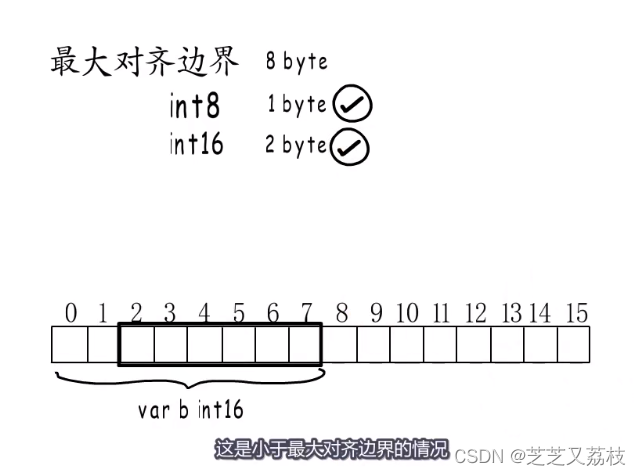
- 这是小于最大对齐边界的情况
- 假设要在32位平台存储一个Int64类型的数据,选择4,减少浪费,提高性能。
如何确定一个结构体的对其边界
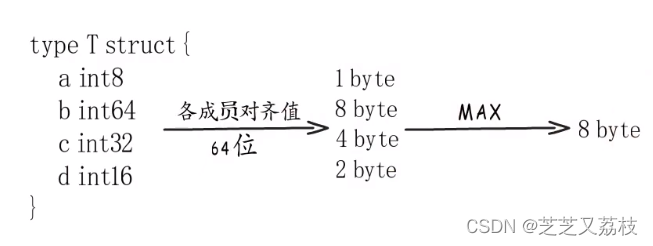
- 首先确定每个成员的对齐边界,然后取其中最大的,这就是结构体类型的对齐边界。
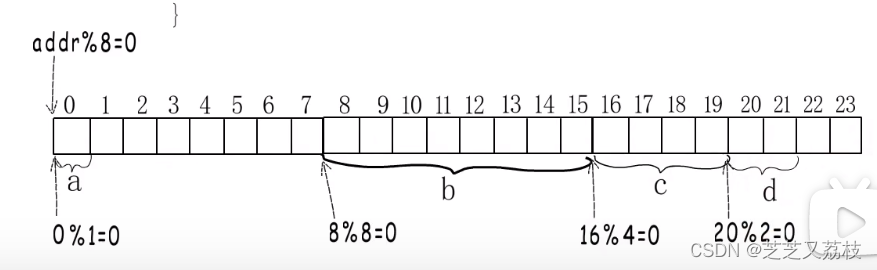
- 结构体整体占用字节数需要是类型对齐边界的倍数,不够的话要向后扩张,所以要扩充到相对地址23这里。
- 最终,结构体类型的大小就是24字节。
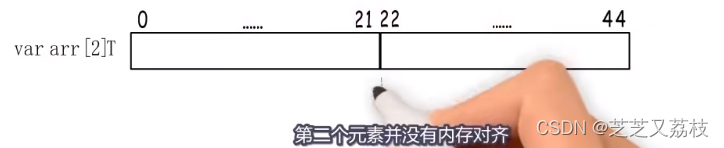
- 只有每个结构体的大小是对齐值的整数倍,才能保证数组里每一个都是内存对齐的。

map设计思路
哈希表与扩容
- 哈希表通常会有一堆桶来存储键值对。
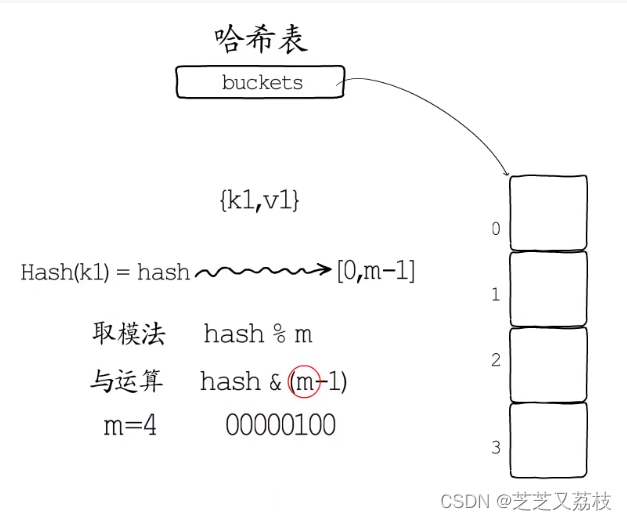
- 若要利用哈希值从m个桶中选择一个,桶的编号区间为[0,m-1]
- 方法一:取模法,得到桶编号
- 方法二:与运算法,
- 要限制桶的个数m必须是2的整数次幂,否则将出现某些桶绝对不会被选中。
- 如果又有新的键值对选择了该桶,就是发生了哈希冲突,遍历桶找到key相等的桶。(开放地址法)
- 冲突时,在它后面链一个新桶存储这个键值对,会顺着链表往后查找(拉链法)
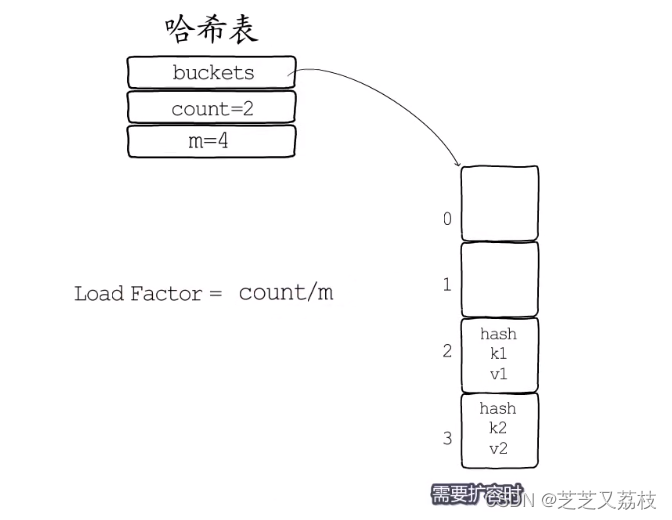
- 哈希冲突的发生会影响哈希表的读写效率,选择散列均匀的哈希函数可以减少哈希冲突的发生。适时的对哈希表进行扩容也是保障读写效率的有效手段。
- 通常会把存储键值对的数目与桶的数目的比值,作为是否需要扩容的判断依据,这个比值被称为“负载因子”。需要扩容时就要分配更多的桶。
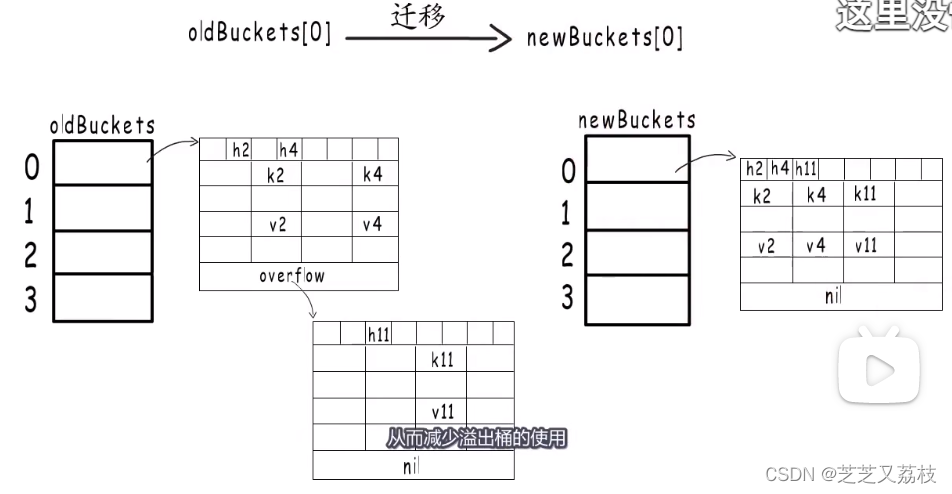
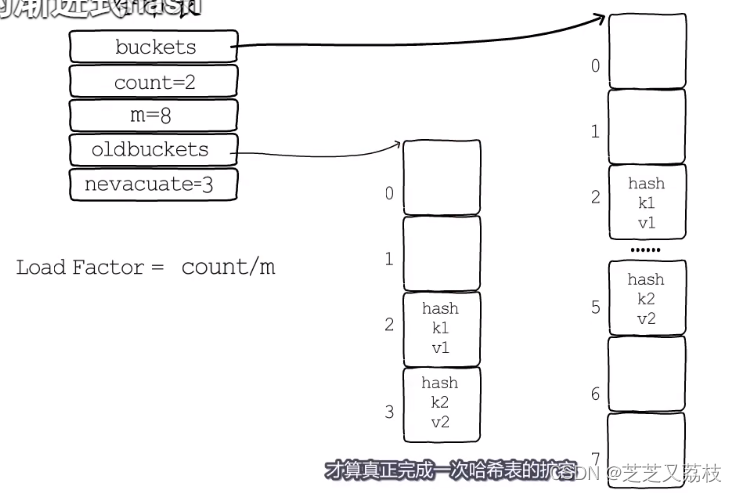
- 需要在扩容时,先分配足够多的新桶,然后用一个字段记录旧桶的位置,再增加一个字段记录旧桶迁移的进度,例如记录下一个要迁移的旧桶编号。
- 渐进式扩容:在哈希表每次读写操作时,如果检测到当前处于扩容阶段,就完成一部分键值对迁移任务,直到所有的旧桶迁移完成,旧桶不再使用,才算真正完成一次哈希表的扩容,像这样把键值对迁移的时间分摊到多次哈希表操作中的方式,就是渐进式扩容。
- 可以避免一次性扩容带来的性能瞬时抖动。
- Go语言中map类型的底层实现就是哈希表
- map类型的变量本质上是一个指针,指向hmap的结构体。
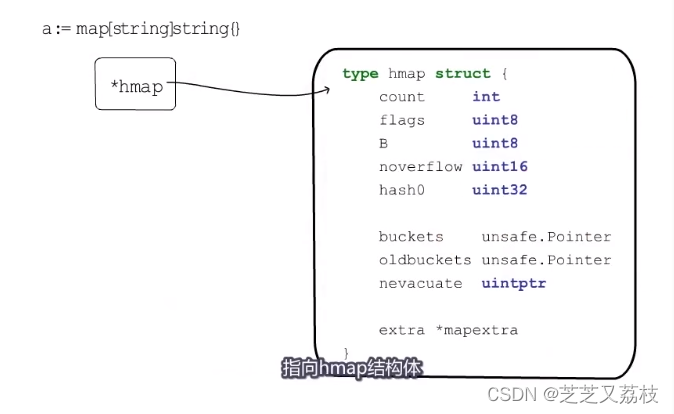
- count记录已经存储的键值对数目
- B记录桶的数目是2的多少次幂,因为这里选择桶时用的是与运算的方法。
- buckets记录桶在哪儿
- oldbuckets用于在扩容阶段保存旧桶在哪儿
- nevacuate记录渐进式扩容阶段下一个要迁移的旧桶编号

bmap的结构
- 为了使结构更紧密,含八个键值对
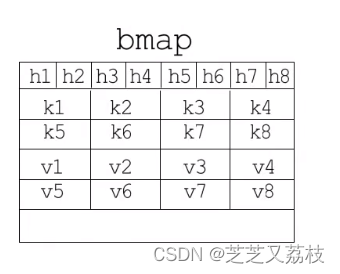
- 每个tophash都是对应哈希值的高8位
- 最后为一个bmap型指针,指向一个溢出桶,溢出桶的内存布局与“常规桶”相同,是为了减少扩容次数而引入的。
- 当一个桶存满了,还有可用的溢出桶时,就会在桶后面链一个溢出桶,继续往这里存。
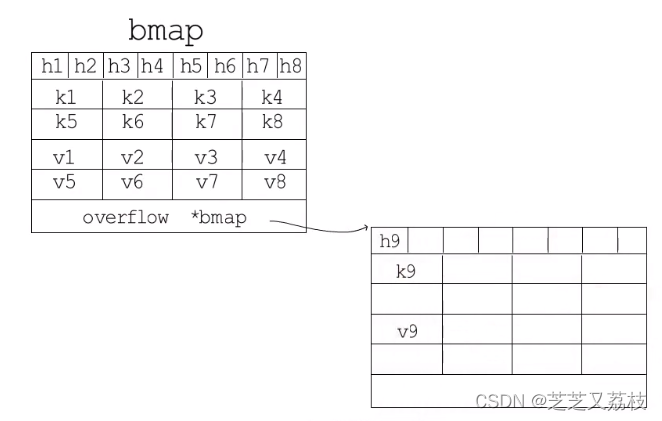
- 实际上,如果哈希表要分配的桶的数目大于2^4,就认为使用到溢出桶的几率较大,就会预分配
- 2^(B-4)个溢出桶备用。
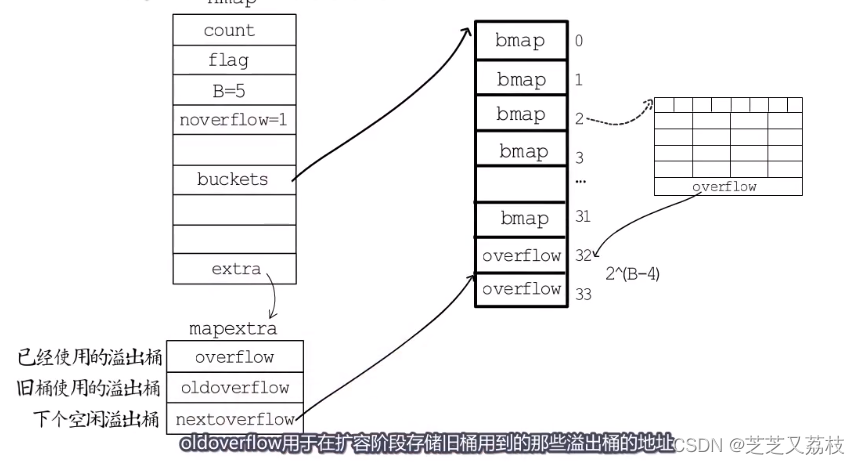
*这些溢出桶与常规桶在内存中是连续的,只是前2^B个用作常规桶,后面的用作溢出桶。
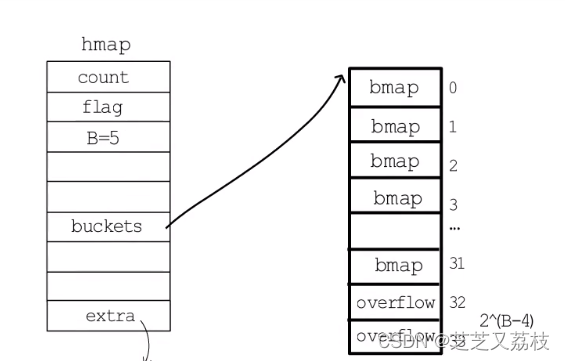
- hmap结构体最后有一个extra字段,指向一个mapextra结构体,里面记录的是溢出桶相关的信息。
- nextoverflow指向下一个空闲溢出桶;
- overflow是一个slice,记录目前已经被使用的溢出桶的地址
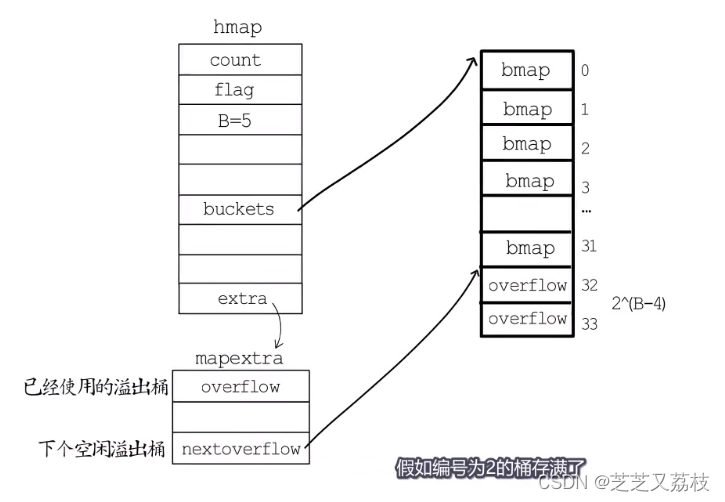
- 假如编号为2的桶存满了,就会在后面链一个溢出桶,nextoverflow指向下一个空闲桶,noverflow记录使用的溢出桶数量,oldoverflow用于在扩容阶段存储旧桶用到的那些溢出桶的地址。
练习
- key和value都是string类型,所以64位下每个key和value都占用16字节
- 取k1哈希值的高8位存在tophash
- 字符串内容为k1,占用字节数目为2,value同理。(16个bytes,8ptr,4len,4cap)
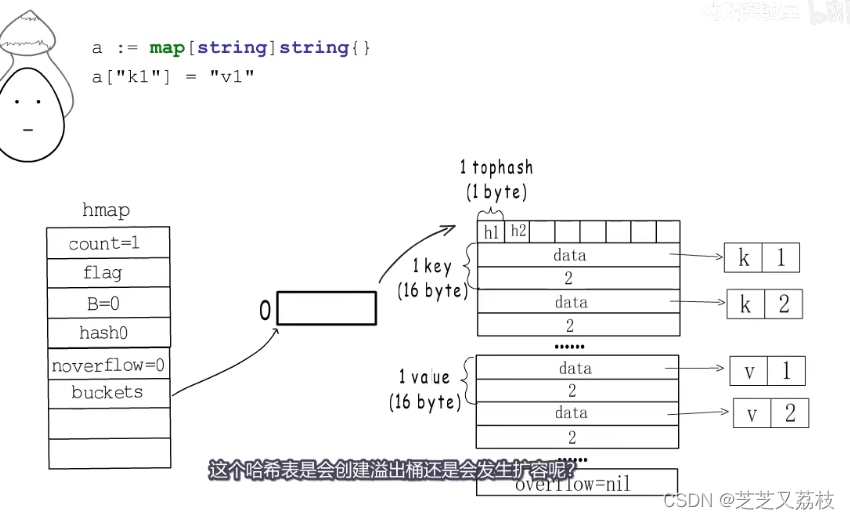
- 如果把这个桶存满,这个哈希表是会创建溢出桶还是会发生扩容呢
map扩容规则
- Go语言map的默认负载因子是6.5,超过这个数就会出发翻倍扩容,分配新桶的数目是旧桶的两倍,
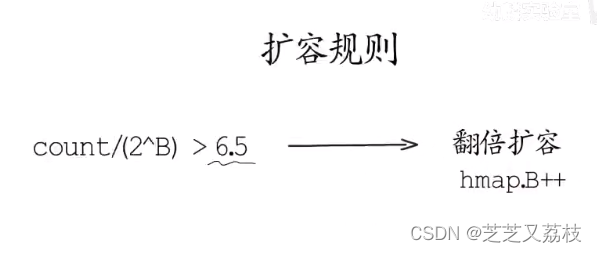
- 例如:如果旧桶数量为4,新桶数量就是8
- 如果一个哈希值选择0号旧桶,那么哈希值的二进制低两位一定为0。
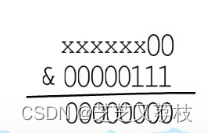
- 选择新桶的结果只有两种,取决于哈希值的第三位是0还是1,如果第三位为0,则选择编号为0的新桶;如果第三位为1,则选择编号为4的新桶,因为桶的数量一定是2的整数次幂。
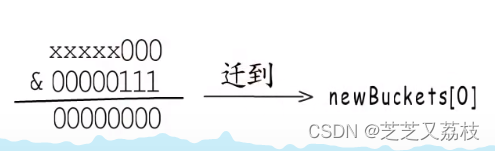
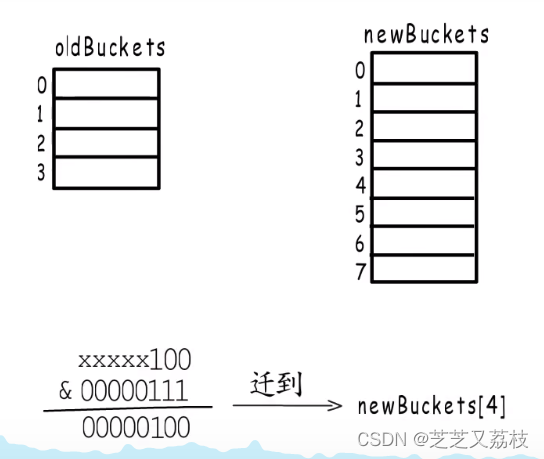
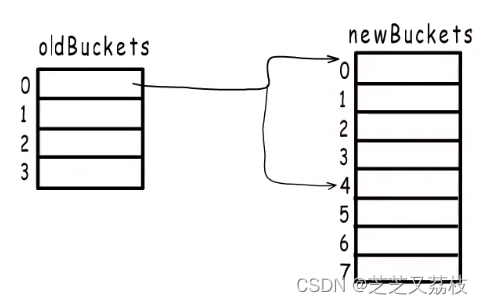
所以,无论容量为多少,翻倍扩容后,每个旧桶都会按照这样的规律,分流到两个新桶中,
- 如果负载因子没有超标,但是使用的溢出桶较多,也会触发扩容,但为等量扩容
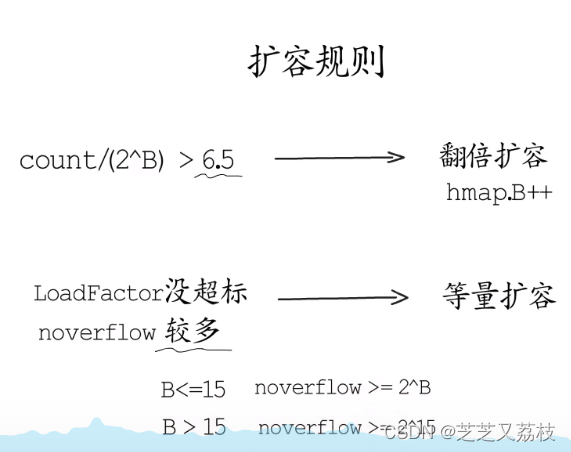
等量扩容就是创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中。
这种情况出现在有很多键值对被删除的情况,等量扩容的方式,使键值对排列的更加紧凑,从而减少溢出桶的使用