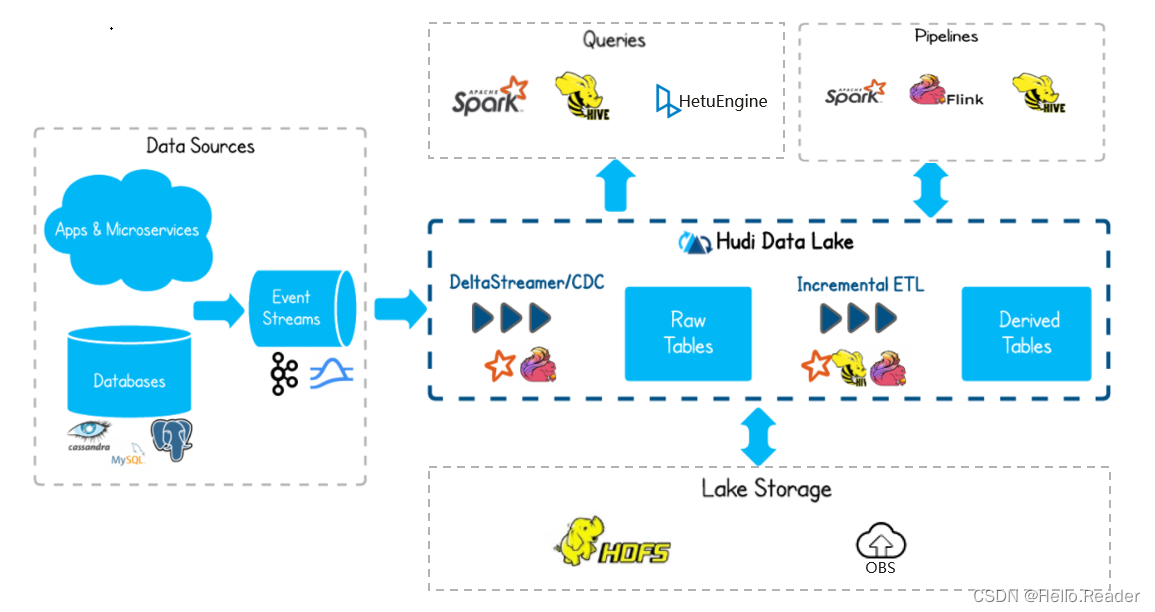
Hudi概述
Hudi是一种数据湖的存储格式,在Hadoop文件系统之上提供了更新数据和删除数据的能力以及消费变化数据的能力。支持多种计算引擎,提供IUD接口,在 HDFS的数据集上提供了插入更新和增量拉取的流原语。
基础架构图
Hudi特性
- ACID事务能力,支持实时入湖和批量入湖。
- 多种视图能力(读优化视图/增量视图/实时视图),支持快速数据分析。
- MVCC设计,支持数据版本回溯。
- 自动管理文件大小和布局,以优化查询性能准实时摄取,为查询提供最新数据。
- 支持并发读写,基于snapshot的隔离机制实现写入时可读取。
- 支持原地转表,将存量的历史表转换为Hudi数据集。
Hudi关键技术和优势
- 可插拔索引机制:Hudi提供多种索引机制,可以快速完成对海量数据的更新和删除操作。
- 良好的生态支持:Hudi支持多种数据引擎接入包括Hive、Spark、HetuEngine、Flink。
Hudi支持两种表类型
Copy On Write
写时复制表也简称cow表,使用parquet文件存储数据,内部的更新操作需要通过重写原始parquet文件完成。
- 优点 读取时,只读取对应分区的一个数据文件即可,较为高效
- 缺点 数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。且由于耗时,读请求读取到的数据相对就会滞后
Merge On Read
读时合并表也简称mor表,使用列格式parquet和行格式Avro两种方式混合存储数据。其中parquet格式文件用于存储基础数据,Avro格式文件(也可叫做log文件)用于存储增量数据。
- 优点 由于写入数据先写delta log,且delta log较小,所以写入成本较低
- 缺点 需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并
Hudi支持三种视图,针对不同场景提供相应的读能力
Snapshot View
实时视图:该视图提供当前hudi表最新的快照数据,即一旦有最新的数据写入hudi表,通过该视图就可以查出刚写入的新数据。
cow表和mor均支持这种视图能力。
Incremental View
增量视图:该视图提供增量查询的能力,可以查询指定COMMIT之后的增量数据,可用于快速拉取增量数据。
cow表支持该种视图能力, mor表也可以支持该视图,但是一旦mor表完成compact操作其增量视图能力消失。
Read Optimized View
读优化视图: 该视图只会提供最新版本的parquet文件中存储的数据。
该视图在cow表和mor表上表现不同:
对于cow表,该视图能力和实时视图能力是一样的(cow表只用parquet文件存数据)。
对于mor表,仅访问基本文件,提供给定文件片自上次执行compact操作以来的数据, 可简单理解为该视图只会提供mor表parquet文件存储的数据,log文件里面的数据将被忽略。 该视图数据并不一定是最新的,但是mor表一旦完成compact操作,增量log数据被合入到了base数据里面,这个时候该视图和实时视图能力一样。