SQLite,作为一款嵌入式关系型数据库管理系统,一直以其轻量级、零配置以及跨平台等特性而备受青睐。不同于传统的数据库系统,SQLite是一个库,直接与应用程序一同编译和链接,无需单独的数据库服务器进程,实现了数据库的零配置管理。这种设计理念使得SQLite成为许多嵌入式系统、移动应用和小型项目中的首选数据库引擎。
SQLite的特点包括:
- 嵌入式数据库引擎: SQLite 是一个嵌入式数据库引擎,意味着它是一个库,与应用程序一同编译和链接,而不是作为独立的进程运行。
- 零配置: 无需配置或管理。SQLite 不需要一个独立的数据库服务器进程,所有的操作都是直接在存储在文件中的数据库上执行。
- 轻量级: SQLite 是一个轻量级的数据库,相对于一些其他数据库管理系统来说,它的内存占用和资源消耗相对较小。
- 支持 SQL: SQLite 支持大部分标准的 SQL 语法,并提供了事务支持,包括隔离级别和回滚。
- 跨平台: SQLite 可以在各种操作系统上运行,包括 Windows、Linux、macOS 和其他嵌入式系统。
- 自给自足: SQLite 数据库是一个单一的磁盘文件,整个数据库被存储在一个文件中,这使得备份、复制或传输数据库变得非常容易。
- 开源: SQLite 是一个开源项目,采用公共领域授权(Public Domain License),可以在商业和非商业项目中免费使用。
SQLite 数据库以其独特的自给自足特性脱颖而出,整个数据库被存储在一个单一的磁盘文件中,使得备份、复制或传输数据库变得异常简单。而作为一款开源项目,SQLite采用了公共领域授权,可以在商业和非商业项目中免费使用。
- SQLiteSDK下载:https://download.csdn.net/download/lyshark_csdn/88568197
由于该数据库的小巧和简洁所以在使用上也非常容易,当读者下载好附件以后会看到如下图所示的文件;

使用时只需要将sqlite3.h与sqlite3.c文件导入到项目中并使用#include "sqlite3.h"即可,无需做其他配置,图中的sqlite3.dll是动态库,sqlite3.exe则是一个命令行版本的数据库可在测试时使用它。
打开与关闭库
sqlite3_open 用于打开或创建一个 SQLite 数据库文件。该函数的原型如下:
int sqlite3_open(const char *filename, /* Database filename (UTF-8) */sqlite3 **ppDb /* OUT: SQLite db handle */
);
filename: 要打开或创建的 SQLite 数据库文件的路径。如果文件不存在,将会创建一个新的数据库文件。ppDb: 用于存储 SQLite 数据库句柄(handle)的指针。SQLite 数据库句柄是与一个打开的数据库关联的结构,它在后续的 SQLite 操作中用作标识。
该函数返回一个整数值,代表函数的执行状态。如果函数成功执行,返回 SQLITE_OK。如果有错误发生,返回一个表示错误代码的整数值。可以通过 sqlite3_errmsg 函数获取更详细的错误信息。
sqlite3_close 用于关闭数据库连接的函数。其原型如下:
int sqlite3_close(sqlite3*);
sqlite3: 要关闭的 SQLite 数据库连接的句柄。
该函数返回一个整数值,用于表示函数的执行状态。如果函数成功执行,返回 SQLITE_OK。如果有错误发生,返回一个表示错误代码的整数值。
使用 sqlite3_close 函数可以释放与数据库连接相关的资源,并确保数据库文件被正确关闭。在关闭数据库连接之前,应该确保已经完成了所有需要执行的 SQL 语句,并在需要的情况下检查执行结果。
// 打开数据库并返回句柄
sqlite3* open_database(std::string database_name)
{int ref =-1;sqlite3 *db = 0;ref = sqlite3_open(database_name.c_str(), &db);if (ref == SQLITE_OK)return db;return false;
}// 关闭数据库
bool close_database(sqlite3 *db)
{int ref = sqlite3_close(db);if (ref == SQLITE_OK)return true;return false;
}
执行查询语句
sqlite3_exec 用于执行 SQL 语句的高级接口函数。它的原型如下:
int sqlite3_exec(sqlite3* db, /* Database handle */const char* sql, /* SQL statement, UTF-8 encoded */int (*callback)( /* Callback function */void*, /* Callback parameter */int, /* Number of columns in the result set */char**, /* Array of column values */char** /* Array of column names */),void* callback_param, /* 1st argument to callback function */char** errmsg /* Error msg written here */
);
db: SQLite 数据库连接的句柄。sql: 要执行的 SQL 语句,以 UTF-8 编码。callback: 回调函数,用于处理查询结果的每一行数据。callback_param: 传递给回调函数的参数。errmsg: 用于存储错误消息的指针。
sqlite3_exec 函数执行一个或多个 SQL 语句,并对每一条语句的执行结果调用指定的回调函数。回调函数的原型如下:
int callback(void* callback_param, /* 参数,由 sqlite3_exec 传递给回调函数 */int num_columns, /* 结果集中的列数 */char** column_values, /* 指向结果集中当前行的列值的数组 */char** column_names /* 指向结果集中列名的数组 */
);
callback_param: 回调函数的参数,由sqlite3_exec传递给回调函数。num_columns: 结果集中的列数。column_values: 指向结果集中当前行的列值的数组。column_names: 指向结果集中列名的数组。
回调函数返回一个整数,用于指示是否继续执行后续的 SQL 语句。如果回调函数返回非零值,sqlite3_exec 将停止执行 SQL,并立即返回。
sqlite3_prepare_v2 用于准备 SQL 语句的接口函数。它的原型如下:
int sqlite3_prepare_v2(sqlite3* db, /* Database handle */const char* sql, /* SQL statement, UTF-8 encoded */int sql_len, /* Length of SQL statement in bytes, or -1 for zero-terminated */sqlite3_stmt** stmt, /* OUT: Statement handle */const char** tail /* OUT: Pointer to unused portion of SQL statement */
);
db: SQLite 数据库连接的句柄。sql: 要准备的 SQL 语句,以 UTF-8 编码。sql_len: SQL 语句的长度,如果为 -1,则表示 SQL 语句以 null 结尾。stmt: 用于存储准备好的语句句柄的指针。tail: 用于存储未使用的 SQL 语句的指针。
sqlite3_prepare_v2 函数用于将 SQL 语句编译成一个 SQLite 语句对象(prepared statement)。这个对象可以被多次执行,每次执行时可以绑定不同的参数。stmt 参数将用于存储编译后的语句的句柄,以供后续的操作。
sqlite3_step 执行预编译 SQL 语句的接口函数。它的原型如下:
int sqlite3_step(sqlite3_stmt*);
sqlite3_stmt*: 由sqlite3_prepare_v2预编译的 SQL 语句的句柄。
sqlite3_step 函数用于执行由 sqlite3_prepare_v2 预编译的 SQL 语句。在执行过程中,可以通过不断调用 sqlite3_step 来逐行获取查询结果,直到结果集结束。对于非查询语句(如 INSERT、UPDATE、DELETE),sqlite3_step 函数执行一次即可完成操作。
该函数的返回值表示执行的结果,可能的返回值包括:
SQLITE_ROW: 成功获取一行数据。SQLITE_DONE: 执行完成,没有更多的数据可用(用于非查询语句)。- 其他错误码,表示执行过程中出现了错误。
sqlite3_column_text 用于获取查询结果集中某一列的文本值。其原型为:
const unsigned char *sqlite3_column_text(sqlite3_stmt*, int iCol);
sqlite3_stmt*: 由sqlite3_prepare_v2预编译的 SQL 语句的句柄。int iCol: 列的索引,从0开始。
该函数返回指向字符串值的指针,该字符串值是查询结果集中指定列的文本表示。需要注意的是,返回的指针指向 SQLite 内部的存储区,应该在使用完之后尽早释放资源。
sqlite3_column_int 用于获取查询结果集中某一列的整数值。其原型为:
int sqlite3_column_int(sqlite3_stmt*, int iCol);
sqlite3_stmt*: 由sqlite3_prepare_v2预编译的 SQL 语句的句柄。int iCol: 列的索引,从0开始。
该函数返回查询结果集中指定列的整数表示。需要注意的是,如果该列不是整数类型,或者包含的数据无法转换为整数,那么返回的结果可能不是有效的整数值。
sqlite3_finalize 用于释放一个预备语句对象(prepared statement)。在使用 sqlite3_prepare_v2 函数准备 SQL 语句后,需要使用 sqlite3_finalize 来释放相应的语句对象。
该函数的原型为:
int sqlite3_finalize(sqlite3_stmt *pStmt);
sqlite3_stmt *pStmt: 指向要释放的语句对象的指针。
该函数返回 SQLITE_OK 表示成功,返回其他错误码表示失败。
// 执行SQL语句
bool exec_sql(sqlite3 *db, char *sql)
{char *error_code = 0;int ref = sqlite3_exec(db, sql, 0, 0, &error_code);if (ref == SQLITE_OK){return true;}return false;
}// 插入数据
bool insert_data(sqlite3 *db, char *sql)
{sqlite3_stmt *stmt = 0;// 插入前检查语句合法性, -1自动计算SQL长度int ref = sqlite3_prepare_v2(db, sql, -1, &stmt, 0);if (ref == SQLITE_OK){sqlite3_step(stmt); // 执行语句sqlite3_finalize(stmt); // 清理语句句柄return true;}sqlite3_finalize(stmt);return false;
}// 查询数据集
bool select_data(sqlite3 *db, char *sql)
{sqlite3_stmt *stmt = 0;int ref = sqlite3_prepare_v2(db, sql, -1, &stmt, 0);if (ref == SQLITE_OK){// 每调一次sqlite3_step()函数,stmt就会指向下一条记录while (sqlite3_step(stmt) == SQLITE_ROW){// 取出第1列字段的值const unsigned char *name = sqlite3_column_text(stmt, 1);// 取出第2列字段的值int age = sqlite3_column_int(stmt, 2);std::cout << "姓名: " << name << " 年龄: " << age << std::endl;}}else{sqlite3_finalize(stmt);return false;}sqlite3_finalize(stmt);return true;
}
调用查询语句
创建数据库
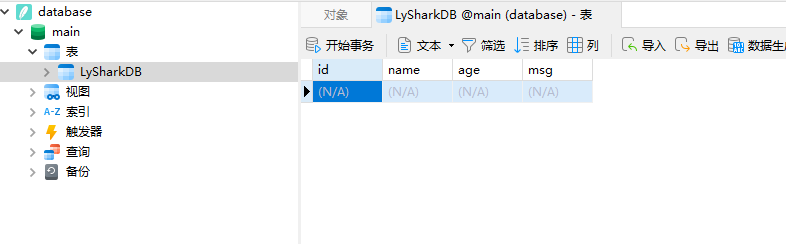
首先打开了名为 "database.db" 的 SQLite 数据库,并创建了一个名为 "LySharkDB" 的表,该表格包含了id、name、age 和 msg四个字段。随后,通过执行 SQL 语句创建了这个表格。最后,关闭了数据库连接。这段代码主要用于数据库初始化操作,确保了数据库中包含了指定的表格结构。
int main(int argc, char *argv[])
{sqlite3* open_db = open_database("database.db");if (open_db != false){bool create_table_ref;std::string sql = "create table LySharkDB(""id int auto_increment primary key,""name char(30) not null," "age int not null,""msg text default null"")";// 运行创建表操作char run_sql[1024] = { 0 };strcpy(run_sql, sql.c_str());create_table_ref = exec_sql(open_db, run_sql);}close_database(open_db);std::system("pause");return 0;
}
上述代码运行后则可以创建一个数据库database.db表名为LySharkDB读者可以使用数据库工具打开该表,其结构如下所示;
插入数据测试
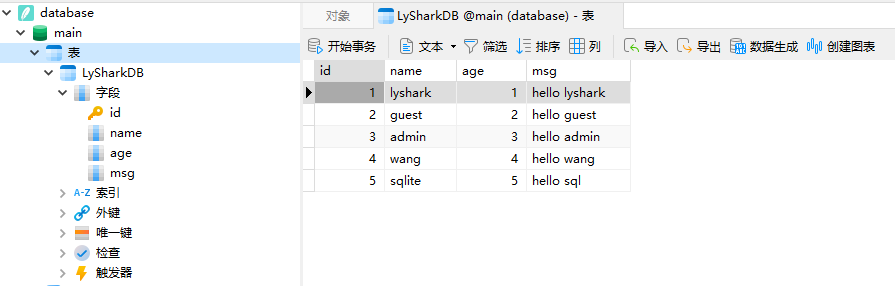
创建数据库后,接着就是插入数据测试,插入时可以使用insert_data,如下代码项数据库中插入5条记录;
int main(int argc, char *argv[])
{sqlite3* open_db = open_database("./database.db");if (open_db != false){bool create_table_ref;// 运行插入记录if (create_table_ref == true){bool insert_ref = 0;insert_ref = insert_data(open_db, "insert into LySharkDB(id,name,age,msg) values(1,'lyshark',1,'hello lyshark');");insert_ref = insert_data(open_db, "insert into LySharkDB(id,name,age,msg) values(2,'guest',2,'hello guest');");insert_ref = insert_data(open_db, "insert into LySharkDB(id,name,age,msg) values(3,'admin',3,'hello admin');");insert_ref = insert_data(open_db, "insert into LySharkDB(id,name,age,msg) values(4,'wang',4,'hello wang');");insert_ref = insert_data(open_db, "insert into LySharkDB(id,name,age,msg) values(5,'sqlite',5,'hello sql');");if (insert_ref == true){std::cout << "插入完成" << std::endl;}}}close_database(open_db);std::system("pause");return 0;
}
插入后,打开数据库管理软件,可看到插入后的记录;
查询与删除数据
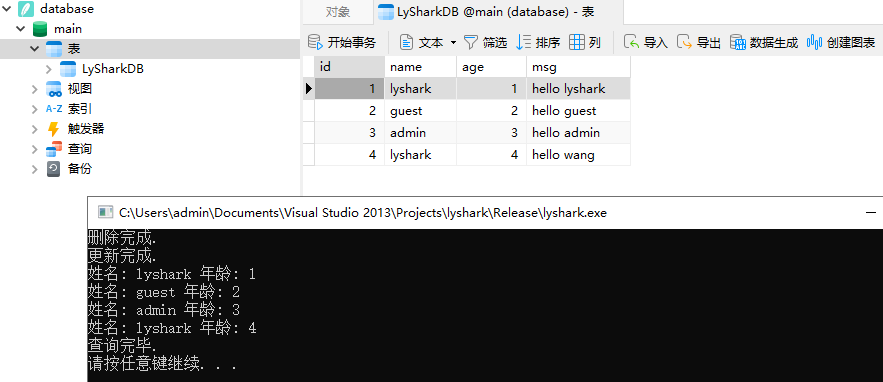
而查询删除与增加记录,我们这里直接使用exec_sql()函数,通过传入不同的SQL语句实现。
int main(int argc, char *argv[])
{sqlite3* open_db = open_database("./database.db");if (open_db != false){// 删除记录bool delete_ref = exec_sql(open_db, "delete from LySharkDB where id = 5;");if (delete_ref == true){std::cout << "删除完成." << std::endl;}// 更新记录bool update_ref = exec_sql(open_db, "update LySharkDB set name='lyshark' where id = 4;");if (update_ref == true){std::cout << "更新完成." << std::endl;}// 查询数据bool select_ref = select_data(open_db, "select * from LySharkDB;");if (select_ref == true){std::cout << "查询完毕." << std::endl;}}close_database(open_db);std::system("pause");return 0;
}
执行更新后的表记录如下所示;
查询区间数据
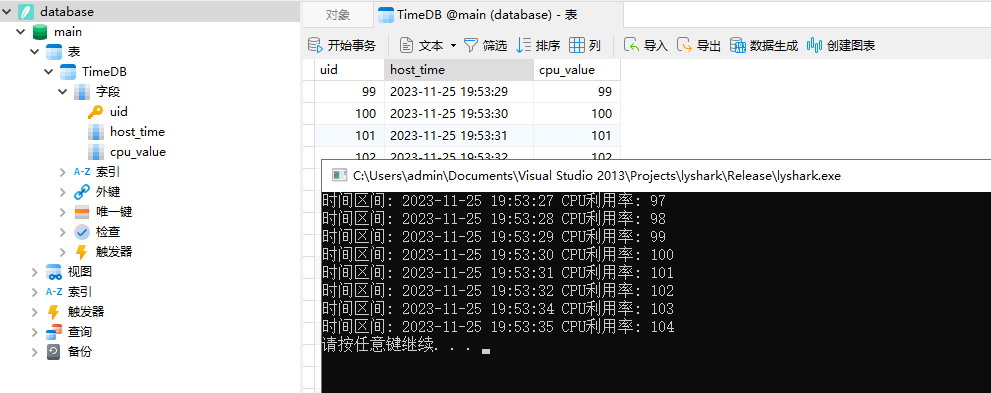
首先创建一些数据集,这里通过循环生成并插入数据,如下代码中新建一个TimeDB数据表,其中有三个字段uid,host_time,cpu_value;
#include <iostream>
#include <string>
#include <map>
#include <vector>
#include <time.h>
#include "sqlite3.h"#include <boost/lexical_cast.hpp>
#include <boost/format.hpp>using namespace std;
using namespace boost;// 获取本地时间日期
std::string get_local_datetime()
{char ct[80];time_t tt;struct tm *tblock;tt = time(NULL);tblock = localtime(&tt);strftime(ct, sizeof(ct), "%Y-%m-%d %H:%M:%S", tblock);return ct;
}// 初始化创建表结构
void Init_Database()
{sqlite3* open_db = open_database("./database.db");if (open_db != false){bool create_table_ref;std::string sql ="create table TimeDB(""uid primary key,""host_time char(128) not null,""cpu_value int not null"");";char run_sql[1024] = { 0 };strcpy(run_sql, sql.c_str());exec_sql(open_db, run_sql);}close_database(open_db);
}// 批量生成时间字符串并插入数据表
void Insert_Test()
{sqlite3* open_db = open_database("./database.db");for (int x = 0; x < 1000; x++){// 获取本地日期时间std::string local_times = get_local_datetime();std::string format_string = boost::str(boost::format("insert into TimeDB(uid,host_time,cpu_value) values(%d,'%s',%d);") % x %local_times %x);std::cout << "执行SQL: " << format_string << std::endl;char run_sql[1024] = { 0 };strcpy(run_sql, format_string.c_str());insert_data(open_db, run_sql);_sleep(1000);}close_database(open_db);
}int main(int argc, char *argv[])
{sqlite3* open_db = open_database("./database.db");Init_Database();Insert_Test();std::system("pause");return 0;
}
如下是五分钟的模拟数据;
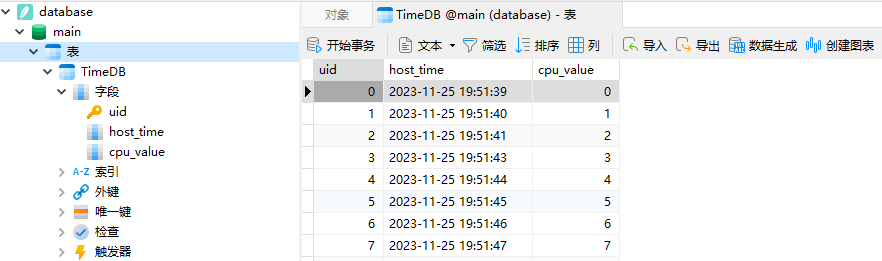
当有了数据则再查询,代码中Select_Time_List函数演示了如何通过时间查询一个区间的数据,并返回一个容器列表给被调用者使用,查询代码如下所示;
#include <iostream>
#include <string>
#include <map>
#include <vector>
#include <time.h>
#include "sqlite3.h"#include <boost/lexical_cast.hpp>
#include <boost/format.hpp>using namespace std;
using namespace boost;// 打开数据库并返回句柄
sqlite3* open_database(std::string database_name)
{int ref = -1;sqlite3 *db = 0;ref = sqlite3_open(database_name.c_str(), &db);if (ref == SQLITE_OK)return db;return false;
}// 关闭数据库
bool close_database(sqlite3 *db)
{int ref = sqlite3_close(db);if (ref == SQLITE_OK)return true;return false;
}// 执行SQL语句
bool exec_sql(sqlite3 *db, char *sql)
{char *error_code = 0;int ref = sqlite3_exec(db, sql, 0, 0, &error_code);if (ref == SQLITE_OK){return true;}return false;
}// 插入数据
bool insert_data(sqlite3 *db, char *sql)
{sqlite3_stmt *stmt = 0;// 插入前检查语句合法性, -1自动计算SQL长度int ref = sqlite3_prepare_v2(db, sql, -1, &stmt, 0);if (ref == SQLITE_OK){sqlite3_step(stmt); // 执行语句sqlite3_finalize(stmt); // 清理语句句柄return true;}sqlite3_finalize(stmt);return false;
}// 查询数据集
bool select_data(sqlite3 *db, char *sql)
{sqlite3_stmt *stmt = 0;int ref = sqlite3_prepare_v2(db, sql, -1, &stmt, 0);if (ref == SQLITE_OK){// 每调一次sqlite3_step()函数,stmt就会指向下一条记录while (sqlite3_step(stmt) == SQLITE_ROW){// 取出第1列字段的值const unsigned char *name = sqlite3_column_text(stmt, 1);// 取出第2列字段的值int age = sqlite3_column_int(stmt, 2);std::cout << "姓名: " << name << " 年龄: " << age << std::endl;}}else{sqlite3_finalize(stmt);return false;}sqlite3_finalize(stmt);return true;
}// 获取本地时间日期
std::string get_local_datetime()
{char ct[80];time_t tt;struct tm *tblock;tt = time(NULL);tblock = localtime(&tt);strftime(ct, sizeof(ct), "%Y-%m-%d %H:%M:%S", tblock);return ct;
}// 初始化创建表结构
void Init_Database()
{sqlite3* open_db = open_database("./database.db");if (open_db != false){bool create_table_ref;std::string sql ="create table TimeDB(""uid primary key,""host_time char(128) not null,""cpu_value int not null"");";char run_sql[1024] = { 0 };strcpy(run_sql, sql.c_str());exec_sql(open_db, run_sql);}close_database(open_db);
}// 批量生成时间字符串并插入数据表
void Insert_Test()
{sqlite3* open_db = open_database("./database.db");for (int x = 0; x < 1000; x++){// 获取本地日期时间std::string local_times = get_local_datetime();std::string format_string = boost::str(boost::format("insert into TimeDB(uid,host_time,cpu_value) values(%d,'%s',%d);") % x %local_times %x);std::cout << "执行SQL: " << format_string << std::endl;char run_sql[1024] = { 0 };strcpy(run_sql, format_string.c_str());insert_data(open_db, run_sql);_sleep(1000);}close_database(open_db);
}// 查询时间区间并返回 传入开始时间与结束时间,过滤出特定的记录
bool Select_Time_List(sqlite3 *db, std::vector<std::map<std::string, int>> &time_ref, std::string start_time, std::string end_time)
{sqlite3_stmt *stmt = 0;std::string format_string = boost::str(boost::format("select * from TimeDB where host_time >= '%s' and host_time <= '%s';") % start_time %end_time);char run_sql[1024] = { 0 };strcpy(run_sql, format_string.c_str());int ref = sqlite3_prepare_v2(db, run_sql, -1, &stmt, 0);if (ref == SQLITE_OK){while (sqlite3_step(stmt) == SQLITE_ROW){std::map < std::string, int > ptr;// 取出第一个和第二个字段const unsigned char *time_text = sqlite3_column_text(stmt, 1);const int cpu_value = sqlite3_column_int(stmt, 2);// 放入一个map容器中ptr[boost::lexical_cast<std::string>(time_text)] = cpu_value;time_ref.push_back(ptr);}sqlite3_finalize(stmt);return true;}sqlite3_finalize(stmt);return false;
}int main(int argc, char *argv[])
{sqlite3* open_db = open_database("./database.db");//Init_Database();//Insert_Test();// 查询 2023-11-25 19:52:31 - 2023-11-25 19:53:35 区间内的所有的负载情况std::vector<std::map<std::string, int>> db_time;bool is_true = Select_Time_List(open_db, db_time, "2023-11-25 19:52:31", "2023-11-25 19:53:35");if (is_true == true){for (int x = 0; x < db_time.size(); x++){// 输出该区间内的数据std::map < std::string, int>::iterator ptr;for (ptr = db_time[x].begin(); ptr != db_time[x].end(); ptr++){std::cout << "时间区间: " << ptr->first << " CPU利用率: " << ptr->second << std::endl;}}}std::system("pause");return 0;
}
例如代码中我们查询2023-11-25 19:52:31 - 2023-11-25 19:53:35这个区间内的数据信息,并返回一个map容器给被调用者,运行效果如下所示;