文章目录
- 一、什么是“强化学习”
- 二、强化学习包括的组成部分
- 二、Q-Learning算法
- 三、迷宫-强化学习-Q-Learning算法的实现
- 全部代码(复制可用)
- 可用状态空间
- 检查是否超出边界
- epsilon 的含义
- 更新方程
- 总结
一、什么是“强化学习”
本文要记录的大概内容:
强化学习是一种机器学习方法,旨在让智能体通过与环境的交互学习如何做出最优决策以最大化累积奖励。在强化学习中,智能体通过尝试不同的行动并观察环境的反馈(奖励或惩罚)来学习。它不依赖于预先标记的训练数据,而是通过与环境的实时交互进行学习。
强化学习的核心概念包括以下几个要素:
智能体(Agent):执行动作并与环境进行交互的学习主体。
环境(Environment):智能体所处的外部环境,它对智能体的动作做出反应,并提供奖励或惩罚信号。
状态(State):在特定时间点,环境所处的情境或配置,用于描述环境的特征。
动作(Action):智能体在某个状态下可以执行的操作或决策。
奖励(Reward):环境根据智能体的动作提供的反馈信号,用于评估动作的好坏。
策略(Policy):智能体采取行动的方式或决策规则,它映射状态到动作的选择。
价值函数(Value Function):评估在特定状态下采取特定动作的长期价值或预期回报。
Q值(Q-Value):表示在给定状态下采取特定动作的预期回报值。
强化学习的目标是通过学习最优策略或价值函数来使智能体能够在不同的状态下做出最佳决策,以最大化累积奖励。学习过程通常使用基于迭代的方法,例如Q-learning、SARSA、深度强化学习等。强化学习在许多领域具有广泛的应用,包括自动驾驶、机器人控制、游戏智能以及优化和决策问题等。
以下是本篇文章正文内容
二、强化学习包括的组成部分
当涉及到设计一个完整的强化学习过程时,需要考虑多个方面,包括环境、代理程序、奖励函数、状态空间、动作空间等。为了提供一个简单而完整的示例,下面以设计一个基于强化学习的迷宫求解问题为例进行分析:
环境 Environment:
我们选择一个简单的方格迷宫作为环境。迷宫由多个方格组成,其中包括起点和终点。
迷宫中可能存在障碍物,代表着无法通过的区域。
环境会提供代理程序当前的状态信息,并接受代理程序的动作。
代理程序 Agent:
代理程序就是智能体,就是我们所设计算法
我们设计一个简单的代理程序,它会根据当前的状态选择一个动作。
代理程序将使用强化学习算法来学习如何在迷宫中移动,以找到终点。
在这个示例中,我们将使用Q-learning算法作为强化学习算法。
状态空间 state_space:
状态空间定义了代理程序可能处于的不同状态。在迷宫中,状态可以表示为当前的位置坐标。
动作空间定义了代理程序可以执行的不同动作。
动作空间 action_space:
在迷宫中,可选的动作可以是上、下、左、右四个方向的移动。
奖励函数 reward:
我们定义奖励函数来指导代理程序的学习过程。
当代理程序达到终点时,奖励为正值,表示取得了成功。
当代理程序遇到障碍物时,奖励为负值,表示不可行的移动。
其他情况下,奖励为零。
这是一个基本的强化学习过程的设计示例。要使其运行,需要实现Q-learning算法和迷宫环境的交互逻辑,并根据定义的状态空间、动作空间和奖励函数进行训练和学习,下面介绍Q-Learning算法。
二、Q-Learning算法
Q-Learning(Q学习)是一种强化学习算法,用于解决马尔可夫决策过程(MDP)。它是一种无模型算法,意味着它不需要显式地了解环境动态。Q-Learning的目标是学习一个最优的动作值函数,称为Q函数,它表示在给定状态下采取特定动作的预期累积奖励。Q-Learning的主要目标是学习一个能够最大化累积奖励的策略。
注意: 传统的Q-Learning算法不涉及深度学习的知识
以下是Q-Learning算法的详细步骤:
-
初始化:对所有状态(s)和动作(a),使用任意值初始化Q函数,记作Q(s, a)。通常,Q函数以表格或矩阵的形式表示。
-
探索与利用:选择在当前状态下执行的动作。在探索与利用之间存在一个权衡。初期通常会更多地进行探索,以便探索不同的状态和动作,随着学习的进行逐渐增加利用已知的高价值动作。
-
执行动作:根据选择的动作,与环境进行交互,观察下一个状态(s’)和获得的即时奖励(r)。
-
更新Q函数:使用Q-Learning更新Q函数的值。根据观察到的即时奖励和下一个状态的最大Q值,更新当前状态和动作的Q值。更新公式为:Q(s, a) = (1 - α) * Q(s, a) + α * (r + γ * max(Q(s’, a’))),其中α是学习率(控制新信息的重要性),γ是折扣因子(控制未来奖励的重要性)。
-
转移到下一个状态:将当前状态更新为下一个状态,继续执行步骤2-4,直到达到终止状态或达到指定的停止条件。
-
收敛:通过不断地与环境交互和更新Q函数,最终Q函数会收敛到最优的动作值函数,表示了在每个状态下采取最佳动作的预期累积奖励。
Q-Learning算法的核心思想是基于试错学习,通过与环境的交互不断优化动作策略,以获得最大的累积奖励。通过迭代更新Q函数,Q-Learning能够学习到最优的策略,从而在复杂的环境中实现自主决策。
三、迷宫-强化学习-Q-Learning算法的实现
全部代码(复制可用)
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import joblib# 定义迷宫环境
class MazeEnvironment:def __init__(self):self.grid = np.array([[0, 0, 0, 0, 0],[0, -1, -1, -1, 0],[0, 0, 0, 0, 0],[0, -1, -1, -1, 1],[0, 0, 0, 0, 0]]) # 0表示可通过的空格,-1表示障碍物,1表示目标self.state_space = np.argwhere(self.grid == 0).tolist() # 可用的状态空间self.victory = np.argwhere(self.grid == 1).tolist()self.state_space.extend(self.victory) # # 最终可用的状态空间self.action_space = ['up', 'down', 'left', 'right'] # 动作空间self.num_states = len(self.state_space)self.num_actions = len(self.action_space)self.current_state = Nonedef reset(self):self.current_state = [0, 0] # 设置起始状态return self.current_statedef step(self, action):if action == 'up':next_state = [self.current_state[0] - 1, self.current_state[1]]elif action == 'down':next_state = [self.current_state[0] + 1, self.current_state[1]]elif action == 'left':next_state = [self.current_state[0], self.current_state[1] - 1]elif action == 'right':next_state = [self.current_state[0], self.current_state[1] + 1]# 检查下一个状态是否合法if (next_state[0] < 0or next_state[0] >= self.grid.shape[0]or next_state[1] < 0or next_state[1] >= self.grid.shape[1]or self.grid[tuple(next_state)] == -1):next_state = self.current_state# 判断是否到达目标状态done = (self.grid[tuple(next_state)] == 1)self.current_state = next_statereturn next_state, int(done)# 定义强化学习代理程序
class QAgent:def __init__(self, state_space, action_space):self.state_space = state_spaceself.action_space = action_spaceself.num_states = len(state_space)self.num_actions = len(action_space)self.q_table = np.zeros((self.num_states, self.num_actions))def choose_action(self, state, epsilon=0.1):if np.random.uniform(0, 1) < epsilon:action = np.random.choice(self.action_space)else:state_idx = self.state_space.index(state)q_values = self.q_table[state_idx]max_q = np.max(q_values)max_indices = np.where(q_values == max_q)[0]action_idx = np.random.choice(max_indices)action = self.action_space[action_idx]return actiondef update_q_table(self, state, action, next_state, reward, learning_rate, discount_factor):state_idx = self.state_space.index(state)next_state_idx = self.state_space.index(next_state)q_value = self.q_table[state_idx, self.action_space.index(action)]max_q = np.max(self.q_table[next_state_idx])new_q = q_value + learning_rate * (reward + discount_factor * max_q - q_value)self.q_table[state_idx, self.action_space.index(action)] = new_q# 训练强化学习代理程序
def train_agent(agent, environment, num_episodes, learning_rate, discount_factor, epsilon):for episode in range(num_episodes):state = environment.reset()done = Falsewhile not done:action = agent.choose_action(state, epsilon)next_state, reward = environment.step(action)# 更新 Q 值表agent.update_q_table(state, action, next_state, reward, learning_rate, discount_factor)state = next_state # 更新当前状态为下一个状态if reward == 1: # 到达目标状态,结束当前回合done = Truejoblib.dump(agent, './Agent.agt') # 保存智能体# 创建迷宫环境实例
maze_env = MazeEnvironment()# 创建强化学习代理实例
agent = QAgent(maze_env.state_space, maze_env.action_space)# 训练强化学习代理
num_episodes = 1000
learning_rate = 0.1
discount_factor = 0.9
epsilon = 0.1 # 在强化学习中,ε(epsilon)通常用于控制智能体在选择动作时的探索与利用的平衡。train_agent(agent, maze_env, num_episodes, learning_rate, discount_factor, epsilon)可用状态空间
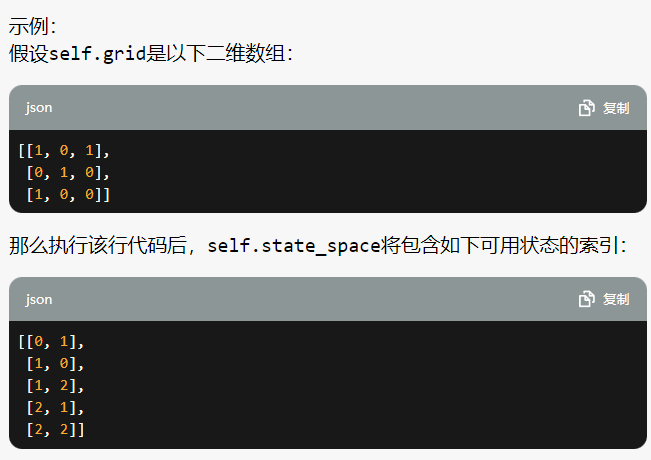
self.state_space = np.argwhere(self.grid == 0).tolist()
检查是否超出边界

epsilon 的含义
在强化学习中,ε(epsilon)通常用于控制智能体在选择动作时的探索与利用的平衡。
ε-greedy策略是一种常见的动作选择策略,其中ε表示以随机动作进行探索的概率,而1-ε表示以具有最高Q值的动作进行利用的概率。
具体含义如下:
当随机数小于ε时,智能体会随机选择一个动作,以便在尚未探索或不确定的状态下进行探索。这有助于发现新的、可能更好的动作。
当随机数大于或等于ε时,智能体会选择具有最高Q值的动作,以利用已经学到的知识和经验。
ε的取值范围通常为0到1之间,根据具体问题和需求进行调整。较小的ε值会更倾向于利用已知的最优动作,而较大的ε值会更倾向于探索未知的动作。
需要注意的是
在训练初期,智能体通常会更多地进行探索,因此ε的初始值可能会较高,随着训练的进行逐渐减小,以便智能体更多地进行利用。
示例:
假设ε的值为0.2,即以20%的概率进行随机动作选择,80%的概率进行利用。
在某个状态下,智能体根据ε-greedy策略进行动作选择:
如果随机数小于0.2,智能体会以20%的概率随机选择一个动作进行探索。
如果随机数大于等于0.2,智能体会以80%的概率选择具有最高Q值的动作进行利用。
通过调整ε的值,可以在探索与利用之间找到适当的平衡,以使智能体能够有效地学习和提高性能。
更新方程
new_q = q_value + learning_rate * (reward + discount_factor * max_q - q_value)
self.q_table[state_idx, self.action_space.index(action)] = new_q
这行代码使用贝尔曼方程更新当前状态和动作对应的Q值。贝尔曼方程表示当前状态和动作的Q值等于当前收益加上折扣因子乘以下一个状态的最大Q值,再减去当前状态和动作的Q值。学习率乘以这个差值,控制了新Q值的更新速度。最后,将更新后的Q值存储回Q表中,以便在后续的训练中使用。
总结
无




![Halcon [fill_up_shape],[close_circle],[dilation_circle]和[shape_trans]图像处理时填充区别](https://img-blog.csdnimg.cn/26b37f1895af4e3ebff0e9ed2031adaf.png)