📟作者主页:慢热的陕西人
🌴专栏链接:Linux
📣欢迎各位大佬👍点赞🔥关注🚓收藏,🍉留言
本博客主要内容通过进程通信的概念,引入管道,实操了管道的五种特性和四种场景,以及对应的管道的特点最后我们写了一个例子让我们对于管道,重定向等的只是更加的印象深刻
文章目录
- 1.进程通信的介绍
- 1.1进程通信目的
- 1.2进程间通信发展
- 1.3进程通信的分类
- 2.管道
- 2.1什么是管道
- 2.2实操一下见见管道
- 2.3管道的原理
- 2.4直接编写样例代码
- 2.5做实验,推导出管道
- a.五种特性
- b.四种场景:
- 2.6管道的特点
- 2.7添加一点设计,来完成一个基本的多进程控制代码
1.进程通信的介绍
1.1进程通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
1.2进程间通信发展
管道
System V进程间通信
System V 是一种基于本地版的进程通信,它是不能跨网络的,因为它只能本主机的内部进行进程间的通信,所以这也是它为什么会现在被边缘化的原因。关于System V我们只需要了解一个共享内存即可.
POSIX进程间通信
POSIX 是一种基于网络版的进程通信。
System V 和 POSIX相当于是进程间的通信的两套标准。
1.3进程通信的分类
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
①首先进程是具有独立性的—无疑增加了通信的成本
②要让两个不同的进程通信,进行通信,前提条件是:先让两个进程,看到同一份“资源”。(进程的本质和前提)
③任何进程通信手段都需要遵循如下的原则解决进程间的通信问题:
我们在操作系统内创建一份公共的资源,例如一段缓冲区,它既不属于进程A,也不属于进程B,那么我们这一份资源既可以被进程A看到,也可以被进程B看到。所以我们可以把进程A产生的数据放到缓冲区中,然后进程B就可以从缓冲区中拿到这部分数据从而完成了进程间的通信!
综上:
a.想办法,先让不同的进程,看到同一份资源。
b.让一方写入,一方读取,完成通信过程,至于,通信目的与后续工作需要结合具体场景。
2.管道
2.1什么是管道
- 管道是Unix中最古老的进程间通信的形式
- 我们把从一个进程连接到另一个进程的一个数据流成为一个“管道”
2.2实操一下见见管道
who命令:查看当前Linux系统中有用户登录信息
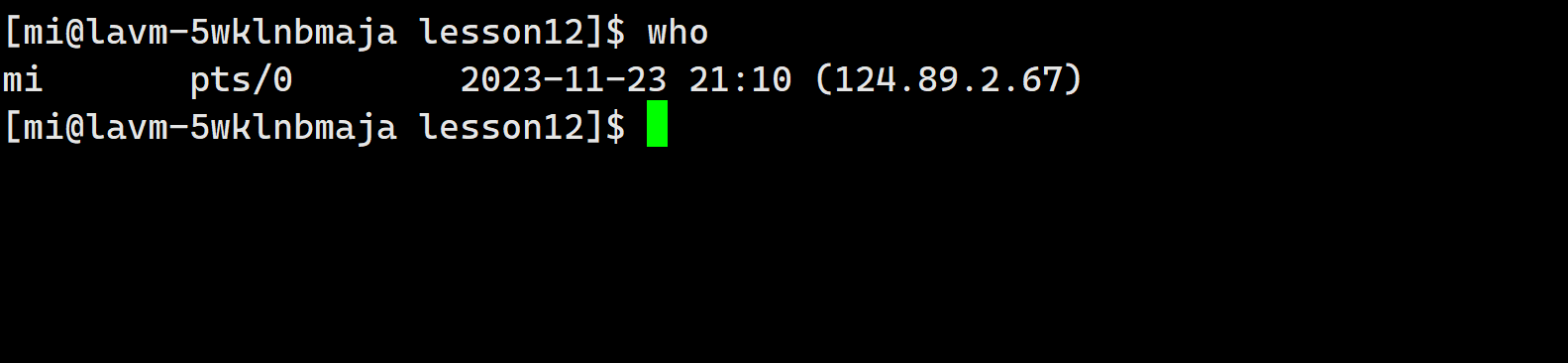
who | wc -l其中的wc -l表示统计输出结果的行数然后输出,那么整体的运行结果就表示的是当前Linux系统中有多少个用户登录
再看一个例子
//其中的&代表让当前的命令在后台执行[mi@lavm-5wklnbmaja lesson12]$ sleep 10000 | sleep 20000 | sleep 30000 &
[1] 24952
//我们可以查看到三个sleep进程,那么这三个进程被称为我们的兄弟进程,父进程都是我们的bash
[mi@lavm-5wklnbmaja lesson12]$ ps axj | head -1 && ps axj | grep sleepPPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
22692 24950 24950 22692 pts/0 24995 S 1000 0:00 sleep 10000
22692 24951 24950 22692 pts/0 24995 S 1000 0:00 sleep 20000
22692 24952 24950 22692 pts/0 24995 S 1000 0:00 sleep 30000
22692 24996 24995 22692 pts/0 24995 S+ 1000 0:00 grep --color=auto sleep
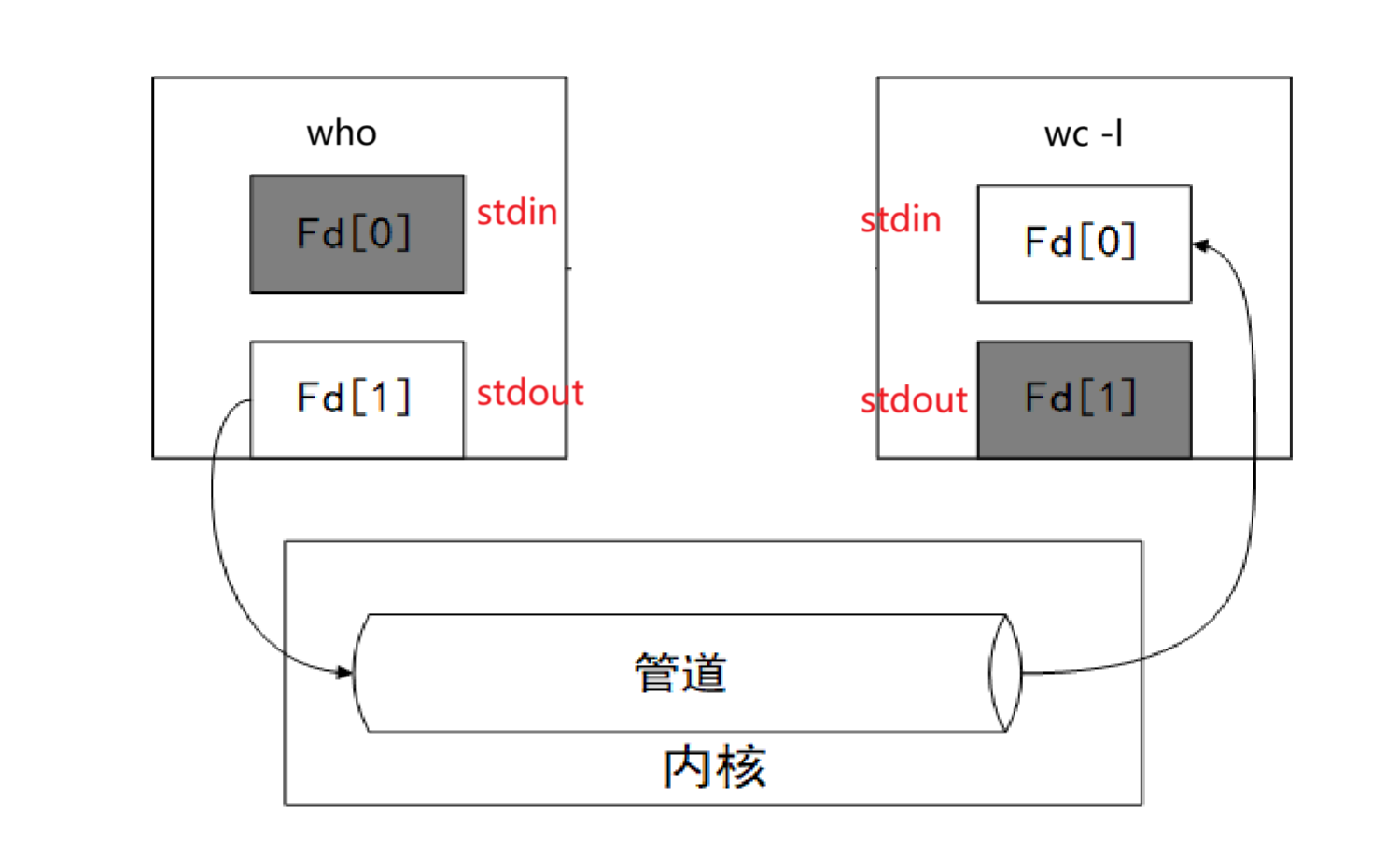
那么当我们使用管道执行命令的时候他是帮我们直接创建了这几个进程:比如上面例子中的sleep 10000 | sleep 20000 | sleep 30000和who | wc -l都是如此,那么它是如何实现进程之间的数据进行通信的?
以上为例,首先管道也是文件,所以我们对应的who进程以写的形式打开管道,并且将自己的标准输出重定向管道
对应的wc -l进程就以读的形式打开管道,并且将自己的标准输入重定向到管道。
2.3管道的原理
管道就是一个操作系统提供的纯内存级文件!
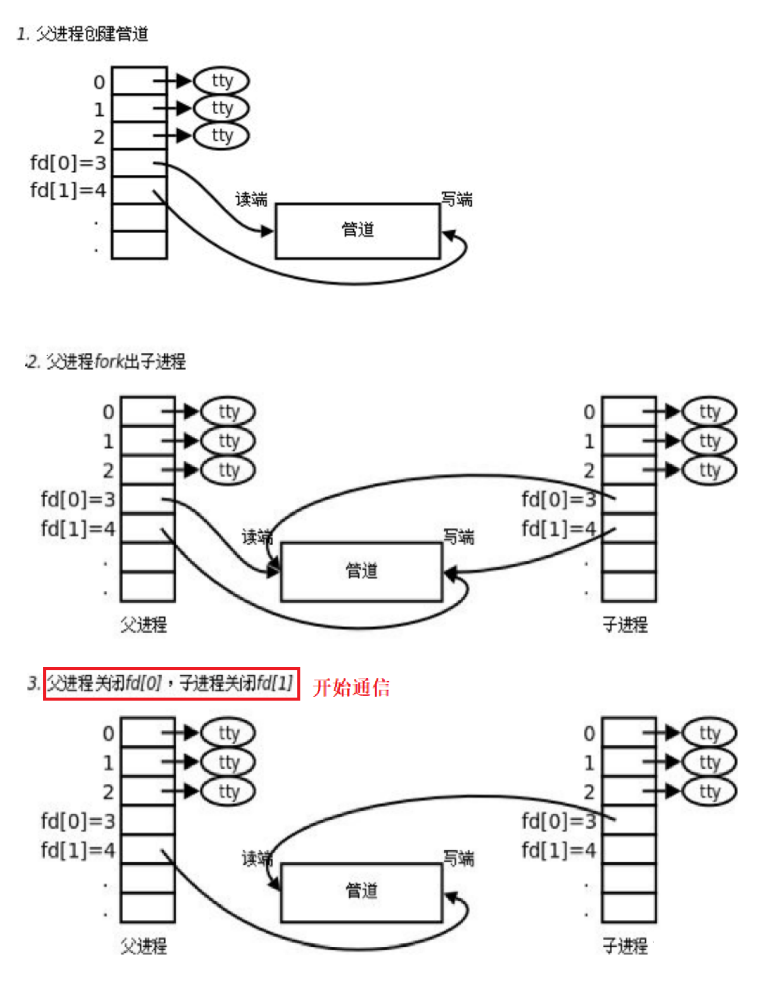
①父进程曾经打开的文件是不需要复制给子进程的,原因是子进程拷贝了一份父进程的struct files_struct,其中包含了父进程文件的描述符对应的数组,子进程可以通过这个数组依旧指向父进程的原来打开的文件,而不需要再打开一份造成资源的浪费。
②所以创建子进程的时候,fork子进程,只会复制进程相关的数据结构对象,不会复制父进程曾经打开的文件对象!
现象:这就是为什么fork之后,父子进程都printf,cout,都会向同一个显示器终端打印数据的原因!
因此我们的子进程也可以看到父进程创建的管道文件!完成了进程间通信的前提,让不同的进程看到了同一份资源!
这种管道只支持单向通信!!
③确定数据流向,关闭不需要的fd
所以我们在子进程关闭对应的读端,和父进程对应的写端,所以我们就可以通过管道将子进程的数据流向父进程。就可以进行正常的进程间的通信!
那么管道为什么是单向的?
原因是管道是基于文件进行通信的,文件读写缓冲区是分开的,当这种通信技术被发明出来的时候,我们发现进程的通信只能是单向的。首先作为父进程它打开管道是需要以读写方式打开,创建子进程之后才能关闭对应的读或者写,要不然子进程继承不到对应的读写方式打开文件,就不能进行一个写一个读了!
2.4直接编写样例代码
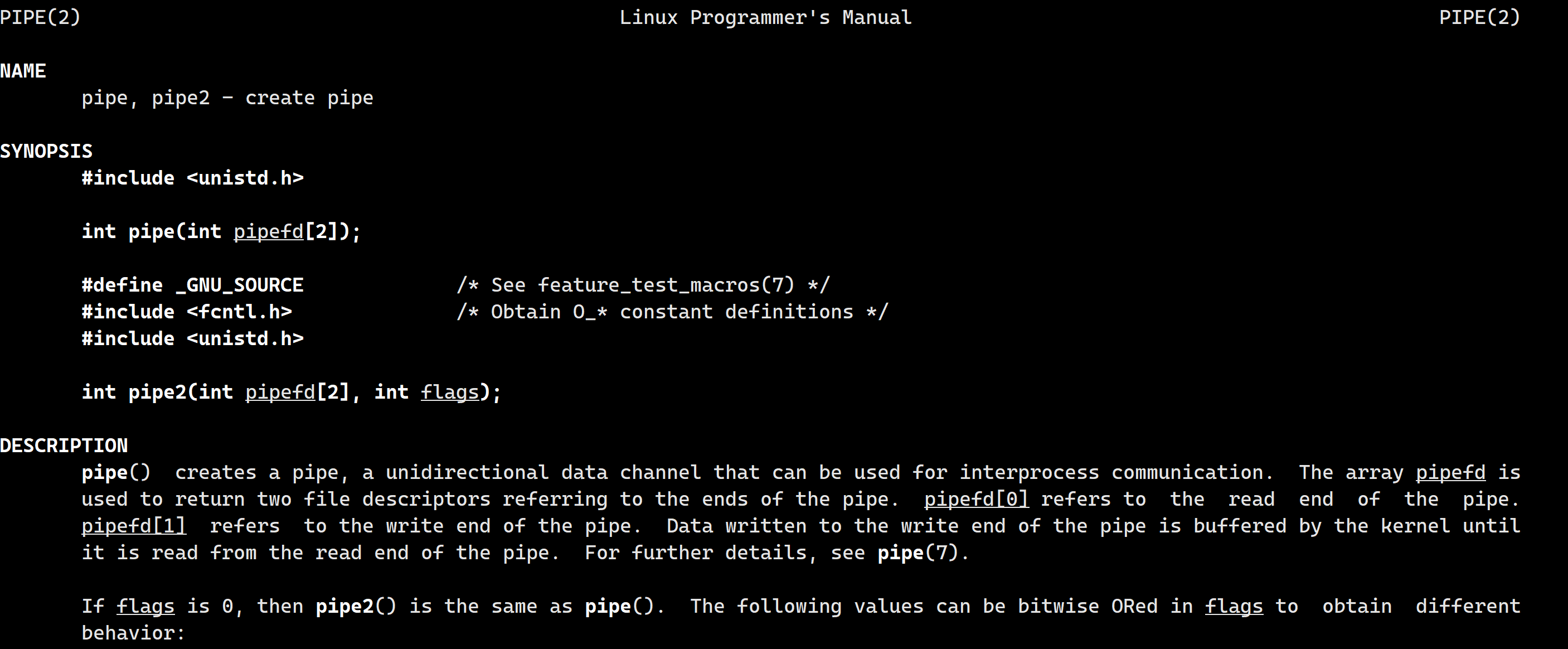
这里我们需要用到pipe接口:创建管道文件
其中它的参数int pipefd[2]被称为输出型参数,pipe接口将对应的读和写文件描述符写到这个数组里。
成功返回0,否则返回-1.
#include<iostream>
#include<unistd.h>
#include<cerrno>
#include<assert.h>
#include<string.h>
#include<string>using namespace std;int main()
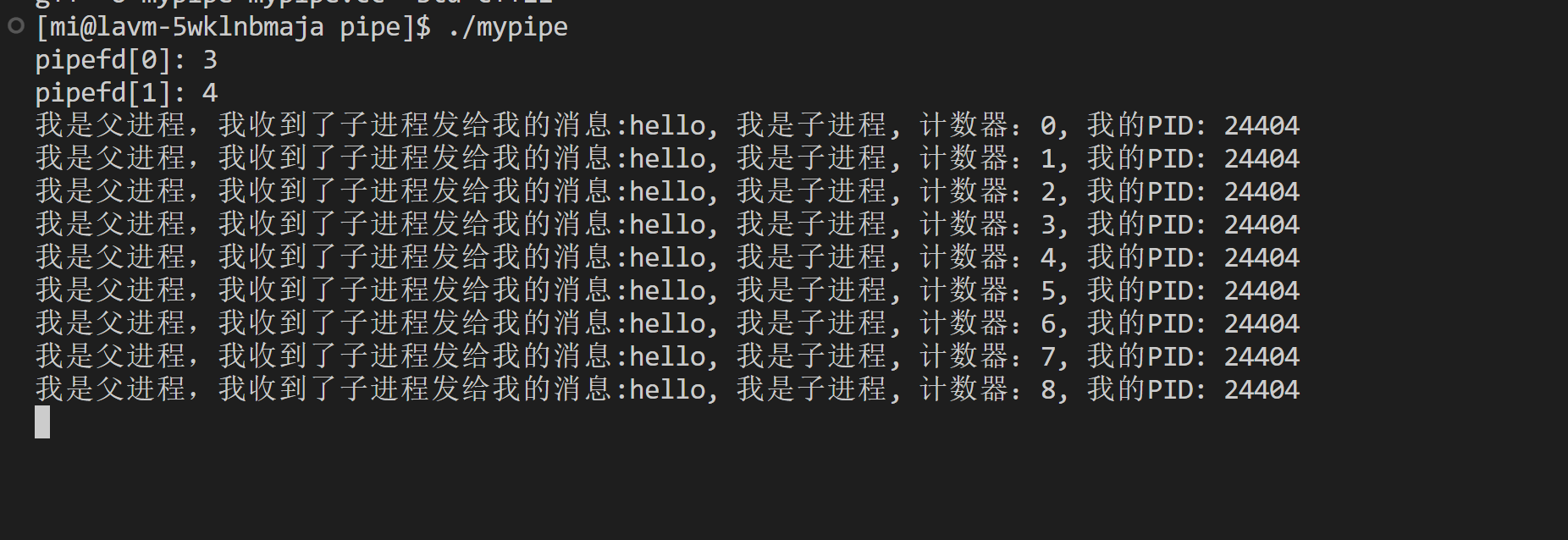
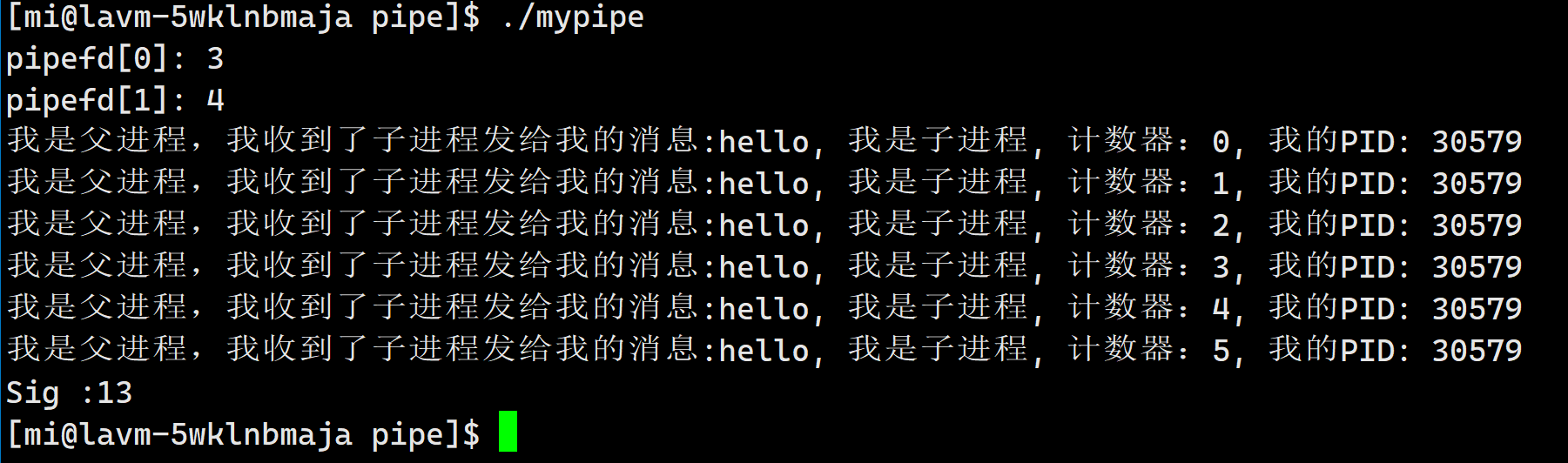
{//让不同的进程看到同一份资源!//任何一种任何一种进程间的通信中//,一定要 先 保证不同的进程之间看到同一份资源int pipefd[2] = { 0 };//1.创建管道int ret = pipe(pipefd);//创建失败if(ret < 0){cout << "pipe error," << errno << ": " << strerror(errno) << endl;return 1;}//打印对应的pipefdcout << "pipefd[0]: " << pipefd[0] << endl; //读端cout << "pipefd[1]: " << pipefd[1] << endl; //写端//2.创建子进程pid_t id = fork();assert(id != -1); //正常应该用判断//意料之外用if,意料之内用assertif(id == 0){//子进程//关闭对应的读端close(pipefd[0]);//4.开始通信---结合场景const string msg = "hello, 我是子进程";int cnt = 0;char buffer[1024];while(true){snprintf(buffer, sizeof(buffer), "%s, 计数器:%d, 我的PID: %d", msg.c_str(), cnt, getpid());write(pipefd[1], buffer, strlen(buffer));sleep(1);cnt++;}close(pipefd[1]);exit(0);}//父进程//3.关闭不需要的文件描述符,父读子写,关闭对应的写端close(pipefd[1]);//4.开始通信---结合场景char buffer[1024];while(true){//sleep(1);int n = read(pipefd[0], buffer, sizeof(buffer) - 1);if(n > 0){buffer[n] = '\0';cout << "我是父进程,我收到了子进程发给我的消息:" << buffer << endl;}}close(pipefd[0]);return 0;
}
2.5做实验,推导出管道
a.五种特性
1.单向通信
2.管道的本质是文件,因为fd的声明周期随进程,管道的声明周期是随进程的
3.管道通信,通常用来进行具有“血缘”关系的进程,进行进程间通信。常用于父子通信—pipe打开管道,并不清楚管道的名字,匿名管道。
4.在管道通信中,写入的次数,和读取的次数,不是严格匹配的,读写次数的多少没有强相关—表现—字节流
5. 具有一定的协同能力,让reader和writer能够按照一定的步骤进行通信—自带同步机制
b.四种场景:
1.如果我们read读取完毕了所有的管道数据,如果对方不发,我就只能等待
2.如果我们writer端管道写满了,我们还能写吗?不能!
我们每次写入四个字节,写入了65535次管道就满了!
snprintf(buffer, 4, "s");
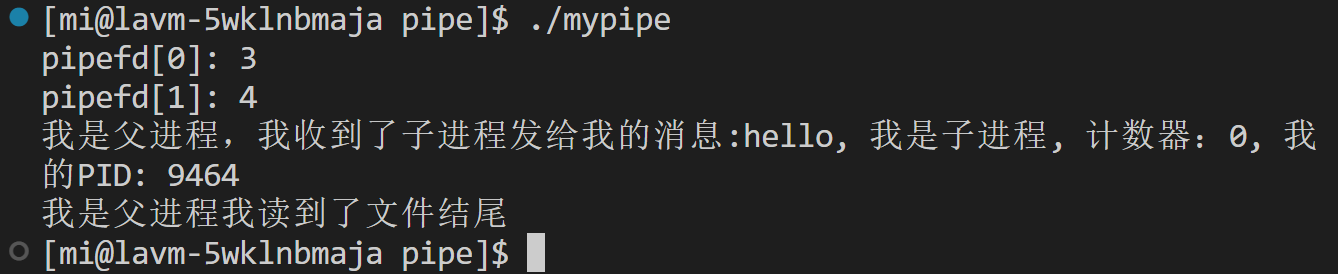
3.如果关闭了写端,读取完毕,在读,read就返回0,表明读到了文件结尾。
4.写端一直写,读端关闭,会发生什么?没有意义!OS不会维护无意义,低效率,或者浪费资源的事情,OS会杀死一直在写入的进程!OS会通过信号来终止进程,13)SIGPIPE
我们收一条指令之后五秒之后关闭父进程对应的读端,发现子进程也退出了!

2.6管道的特点
- 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
- 管道提供流式服务
- 一般而言,进程退出,管道释放,所以管道的生命周期随进程
- 一般而言,内核会对管道操作进行同步与互斥
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
2.7添加一点设计,来完成一个基本的多进程控制代码
需求:父进程有多个子进程,父进程和这些子进程之间都有管道,父进程可以通过向子进程写入特定的消息,唤醒子进程,甚至让子进程执行某种任务。
首先搭建大体的框架:
#include<iostream>
#include<string>
#include<unistd.h>
#include<assert.h>
#include<vector>using namespace std;const int gnum = 5; //表示子进程数int main()
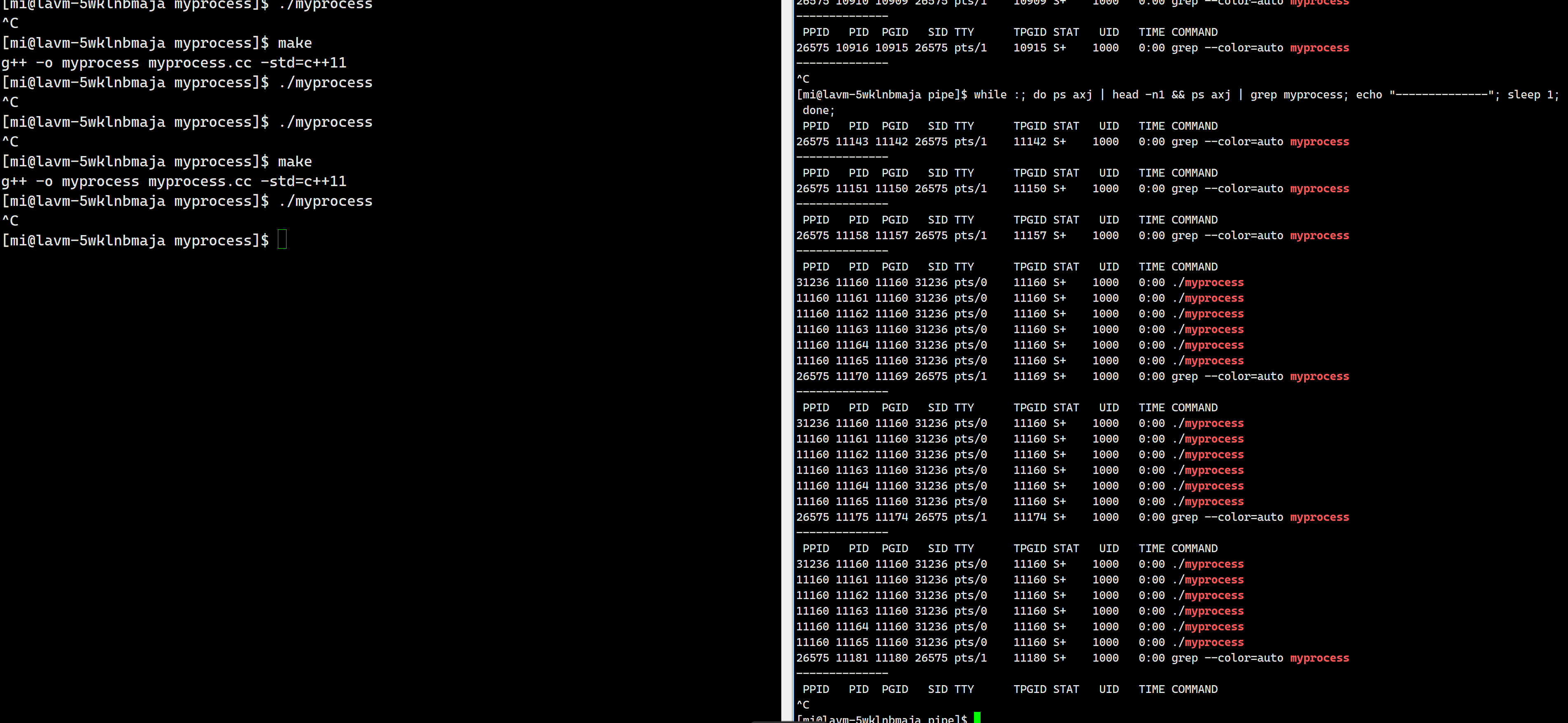
{//1.先进行构建控制结构,父进程写,子进程读for(int i = 0; i < gnum; ++i){//1.1创建管道int pipefd[2] = {0};int ret = pipe(pipefd);assert(ret == 0); //0正常 -1不正常(void)ret;//1.2创建进程pid_t id = fork();assert(id != -1);if(id == 0){//子进程//1.关闭对应的fd,也就是写close(pipefd[1]);close(pipefd[0]);exit(0);}//父进程//1.3关闭不要的fdclose(pipefd[0]);}return 0;
}
但是我们应该理解到,父进程有这么多的子进程,我们父进程在操作的时候,怎么分的清对应的子进程是哪一个?所以这时候我们应该将这些子进程组织起来,这就要利用到我们操作系统内部一直在践行的:先描述再组织
创建一个对应的结构体,然后用vector将其组织起来
//先描述
class EndPoint
{
public:pid_t _child; //子进程pidint _write_fd;//对应的文件描述符public://构造EndPoint(pid_t id, int fd) :_child(id), _write_fd(fd){}//析构~EndPoint(){}
};//在组织vector<EndPoint> end_points;然后我们将以上的步骤封装成一个函数:
void creatProcesses(vector<EndPoint>& end_points)
{//1.先进行构建控制结构,父进程写,子进程读for(int i = 0; i < gnum; ++i){//1.1创建管道int pipefd[2] = {0};int ret = pipe(pipefd);assert(ret == 0); //0正常 -1不正常(void)ret;//1.2创建进程pid_t id = fork();assert(id != -1);if(id == 0){//子进程//1.3关闭不要的fdclose(pipefd[1]);//我们期望,所有的子进程读取“指令”的时候,都从标准输入读取//1.3.1所以我们进行输入重定向dup2(pipefd[0], 0);//1.3.2子进程开始等待获取命令WaitCommend();close(pipefd[0]);exit(0);}//父进程//1.3关闭不要的fdclose(pipefd[0]);//1.4将新的子进程和他的管道写端构建对象。end_points.push_back(EndPoint(id, pipefd[1]));}
}
主函数这样写:先让程序跑起来
int main()
{//在组织vector<EndPoint> end_points;creatProcesses(end_points);//2.那么我们这里就可以得到了五个子进程的id和对应的写端while(true){sleep(1);}return 0;
}
我们运行了之后用ps去监视查看进程确实生成了我们对应了五个子进程:
设计 WaitCommend();函数
这个函数就是让子进程去一直去读取管道中信息,读取到之后执行对应的任务。
void WaitCommend()
{while (true){int command;int n = read(0, &command, sizeof(int));if (n == sizeof(int)) // 读取成功{t.Execute(command);}else if (n == 0) // 表示链接已经关闭{// 则不需要去读了break;}else // 读取错误{break;}}
}
主函数内部父进程调度发配任务:
主要分为三步:
- 确定任务
- 确定执行任务的子进程
- 执行任务
int main()
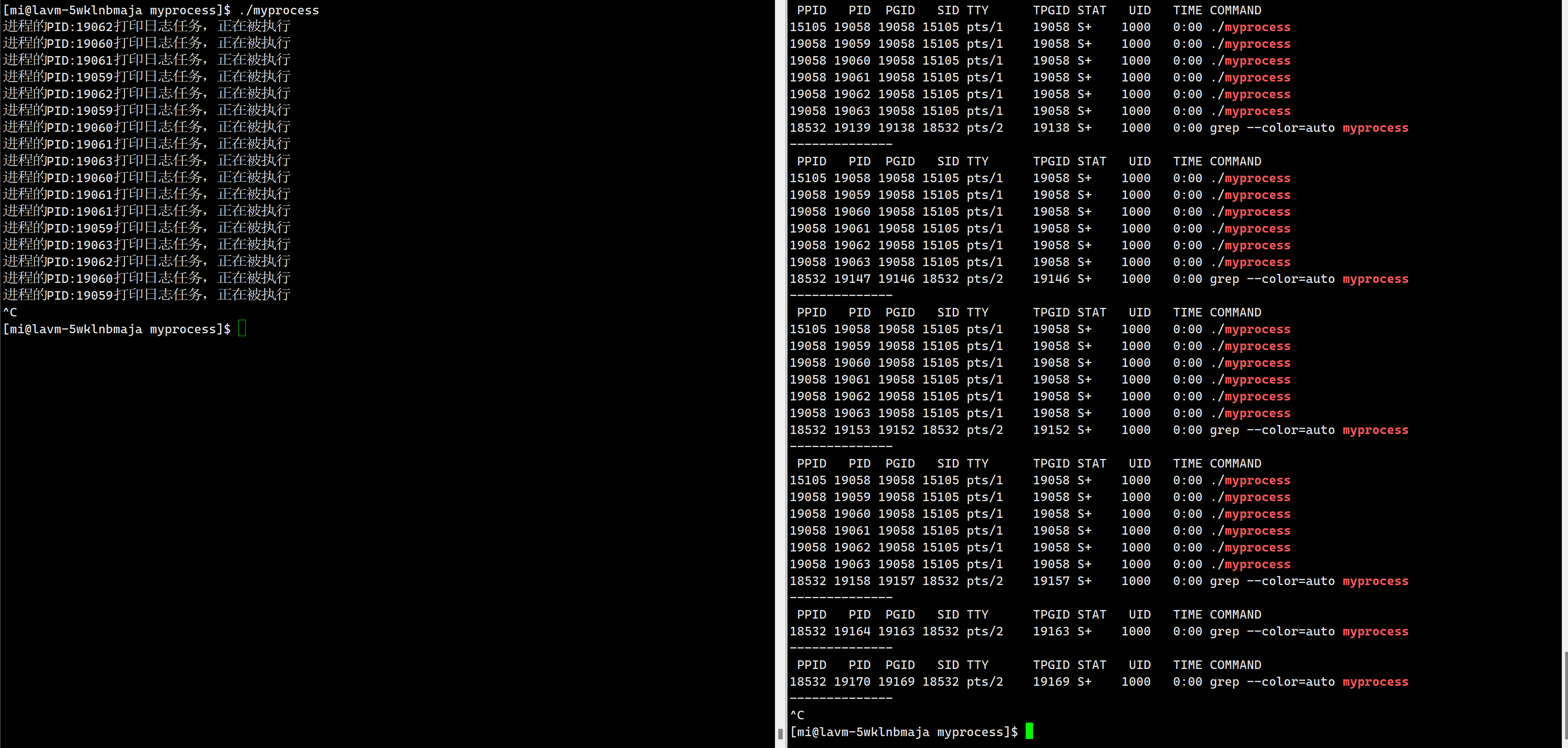
{// 在组织vector<EndPoint> end_points;creatProcesses(end_points);// 2.那么我们这里就可以得到了五个子进程的id和对应的写端while (true){//1.确定任务int command = COMMAND_LOG;//2.确定执行任务的子进程int child = rand() % end_points.size();//3.执行任务write(end_points[child]._write_fd, &command, sizeof(command));sleep(1);}return 0;
}
运行结果:
所有源码:
Task.hpp
#pragma once#include<iostream>
#include<vector>
#include<unistd.h>using namespace std;typedef void (*fun_t)(); //函数指针//任务对应的操作码,约定每一个command是四个字节
#define COMMAND_LOG 0
#define COMMAND_MYSQL 1
#define COMMAND_REQUEST 2//三个任务
void PrintLog()
{cout <<"进程的PID:" <<getpid()<< "打印日志任务,正在被执行" << endl;
}void InsertMySQL()
{cout << "执行数据库任务,正在被执行" << endl;
}void NetRequest()
{cout << "执行网络请求任务,正在被执行" << endl;
}class Task
{
public:Task(){funcs.push_back(PrintLog);funcs.push_back(InsertMySQL);funcs.push_back(NetRequest);}//任务执行函数void Execute(int command){if(command >= 0 && command < funcs.size()) funcs[command]();}~Task(){}public:vector<fun_t> funcs;};myprocess.cc
#include <iostream>
#include <string>
#include <unistd.h>
#include <assert.h>
#include <vector>#include "Task.hpp"using namespace std;const int gnum = 5; // 表示子进程数// 定义对应的任务对象
Task t;// 先描述
class EndPoint
{
public:pid_t _child; // 子进程pidint _write_fd; // 对应的文件描述符public:// 构造EndPoint(pid_t id, int fd): _child(id), _write_fd(fd){}// 析构~EndPoint(){}
};void WaitCommend()
{while (true){int command;int n = read(0, &command, sizeof(int));if (n == sizeof(int)) // 读取成功{t.Execute(command);}else if (n == 0) // 表示链接已经关闭{// 则不需要去读了break;}else // 读取错误{break;}}
}void creatProcesses(vector<EndPoint> &end_points)
{// 1.先进行构建控制结构,父进程写,子进程读for (int i = 0; i < gnum; ++i){// 1.1创建管道int pipefd[2] = {0};int ret = pipe(pipefd);assert(ret == 0); // 0正常 -1不正常(void)ret;// 1.2创建进程pid_t id = fork();assert(id != -1);if (id == 0){// 子进程// 1.3关闭不要的fdclose(pipefd[1]);// 我们期望,所有的子进程读取“指令”的时候,都从标准输入读取// 1.3.1所以我们进行输入重定向dup2(pipefd[0], 0);// 1.3.2子进程开始等待获取命令WaitCommend();close(pipefd[0]);exit(0);}// 父进程// 1.3关闭不要的fdclose(pipefd[0]);// 1.4将新的子进程和他的管道写端构建对象。end_points.push_back(EndPoint(id, pipefd[1]));}
}
int main()
{// 在组织vector<EndPoint> end_points;creatProcesses(end_points);// 2.那么我们这里就可以得到了五个子进程的id和对应的写端while (true){//1.确定任务int command = COMMAND_LOG;//2.确定执行任务的子进程int child = rand() % end_points.size();//3.执行任务write(end_points[child]._write_fd, &command, sizeof(command));sleep(1);}return 0;
}
到这本篇博客的内容就到此结束了。
如果觉得本篇博客内容对你有所帮助的话,可以点赞,收藏,顺便关注一下!
如果文章内容有错误,欢迎在评论区指正