指标、日志、链路是服务可观测性的三大支柱,在服务稳定性保障中,通常指标侧重于发现故障和问题,日志和链路分析侧重于定位和分析问题,其中日志实际上是串联这三大维度的一个良好桥梁。
但日志分析往往面临成本和效果之间的权衡问题,没有完美的方案只有适合的方案,本文将结合实战经验,介绍一种日志分析的实现,分析如何在稳定性保障中用好日志这个维度,以及日志如何与指标、链路相互配合形成故障定位的最佳实践。
日志分析难点
1)规范问题:服务模块的语言和框架各异,日志格式不规范,分析困难;
2)管理问题:微服务模块众多,日志收集和管理困难;
3)成本问题:日志的保存和计算分析需要消耗大量的资源,主要是存储计算资源,使用成本高;
日志分析方案
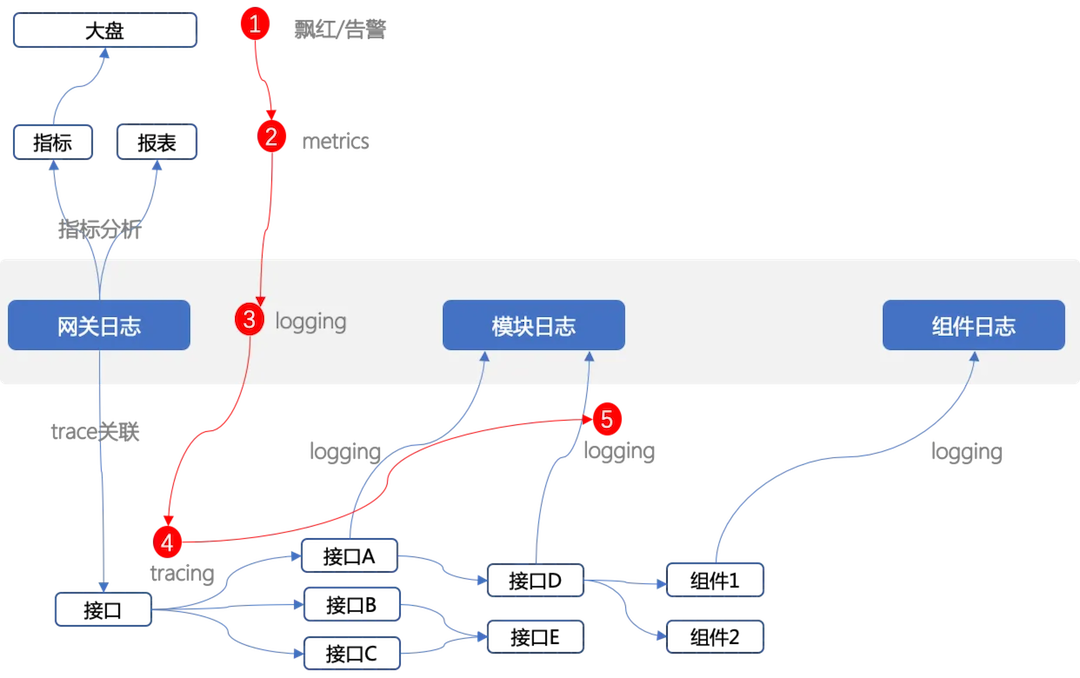
本文推荐一种在稳定性保障中,经过考量和实战的日志分析方案。故障处理场景中日志分析的核心思路:
- 日志到指标:基于网关日志分析接口、域名、渠道、端等维度的关键指标(流量、成功率、延迟);
- 指标到大盘:网关日志分析计算出的维度指标(流量、成功率、延迟)用作全局服务大盘/大屏的建设,用以观察服务的全局状态;
- 指标到日志:这类维度指标的生成来源于日志计算,天然可以实现指标到日志的关联,在发现指标趋势异常时,能够方便的调出相应时间的日志原文;
- 日志到链路:具体的日志原文中带有 traceid,或模块和接口的信息,基于此信息可打通trace系统,调出具体请求或模块的trace信息,展示请求的调用链路,分析调用异常的底层来源;
- 链路到日志:在trace的异常点下钻查询日志系统,调出对应模块和接口的详细日志,做进一步的异常判断;
- 日志到特征:另一个分析思路,基于网关日志做异常指标的特征分析,如,下单接口异常,则自动分析异常请求在来源IP、接入层实例分布、upstream分布等等维度上是否有聚集特征或特征变化,如果在某个特征上出现了特征的变化和聚集,则可以针对这类特征确定止损的方案或进一步追查的方向;
优点和权衡
这个方案的优点和权衡点在于:
- 分析性价比高:网关日志通常较为规范,如Nginx日志,并且也容易治理,同时网关日志也最为靠近用户端,无论从分析和治理的难易度,以及分析的价值上看,都是最佳的选择;
- 治理性价比高:程序模块日志由于语言格式各异,治理难度高,且分析的价值大打折扣。治理的重点可以转移到落地trace系统上来,程序模块一旦使用了trace的sdk或agent,则可以输出规范的trace信息和有价值的定位信息。落地trace也会有相当的成本,但对类似Java这类语言,成本会低很多,可以使用javaagent方案做到无侵入实现;
- 扬长避短:程序模块的日志原文格式可能各异也不标准,但异常日志的信息仍然是判断问题原因的重要依据,因此在这个过程中能在合适的分析步骤中查询调出即可,这部分日志的价值优势在于原文信息而不在于分析计算;
该方案以日志为中心,实现了一条日志、指标、trace相互串联的问题发现和分析路径,这条路径也是故障问题分析的典型路径。
同时从方案的落地和推动成本上来讲也是一个比较合适的取舍。如果可观测产品支持好这条路径信息的串联,会大幅提升异常问题定位分析的效率。
方案落地要点
混合云资源、观测系统众多,是目前很典型的企业基础设施现状,在此基础上要实现这个方案可能需要重点解决以下几个问题:
1)存量系统如何打通:指标、日志、trace都可能已经有各自独立的系统,如何串联融合不同系统的数据?
2)云上云下如何打通:很多企业使用了私有化和公有云的混合云方案,日志可能也同时使用了私有化的ELK和云上的日志系统,如阿里云SLS和腾讯云CLS;
3)风险成本如何控制:如果为此要全部推导重建,用一套系统替代原有系统,风险和成本都太高,周期长也不可控;
产品实践
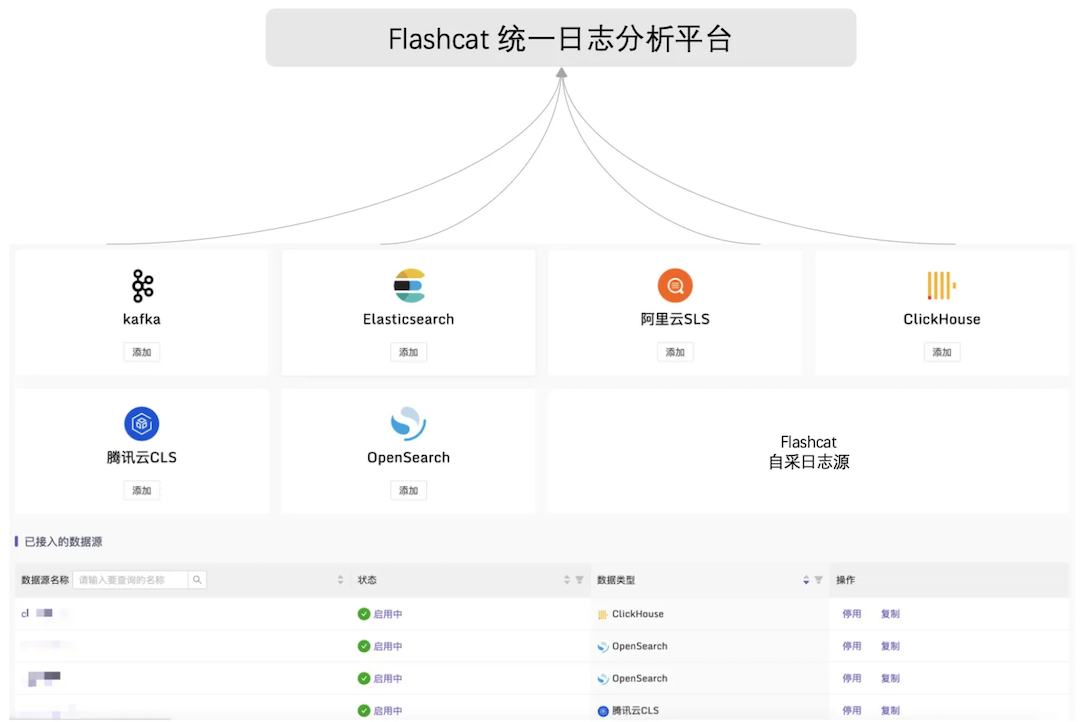
这里介绍快猫星云的 Flashcat 是如何解决这些问题的。
- 数据源抽象:常见的开源和云上现有的可观测系统都可以作为一个数据源注册到 Flashcat;
- 数据交互:Flashcat 底层通过 API 和各数据源交互;
- 统一分析:上层对来自各个数据源的数据,特别是日志数据做统一灵活的配置和分析,生成各类自定义维度的报表和指标数据;
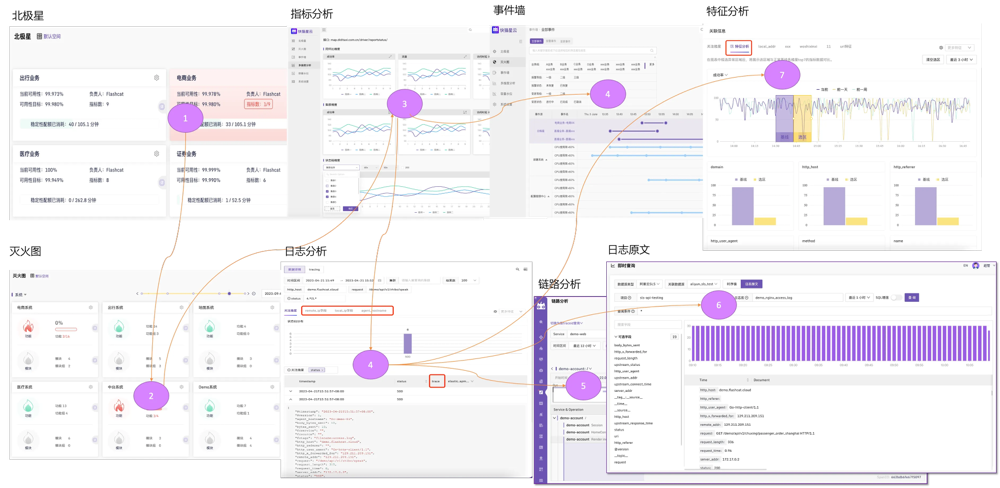
- 指标建设:日志生成的指标数据可以配置到北极星、灭火图,作为业务健康状态和系统健康状态的观测指标;
- 下钻关联:从 Flashcat 的北极星(业务健康度量化)和灭火图(系统健康度量化)可以下钻上面描述的问题分析路径,实现从业务异常的发现、到系统异常的范围收敛,到具体问题的分析确认的全链路串联;
Flashcat 问题下钻分析路径
总结
本文介绍了稳定性保障中日志分析系统建设面临的问题、挑战、需求和建设中的权衡取舍。并介绍了 Flashcat 如何解决这些问题,做到效果和成本最佳,也最具落地的可行性。