文章目录
- Python静态Web服务器开发
- Web静态服务器初识
- 搭建Python自带的静态Web服务器
- 静态Web服务器返回固定页面数据
- 静态Web服务器返回指定页面数据
- 静态Web服务器多任务版
- 静态Web服务器面向对象开发
- 静态Web服务器命令行启动动态绑定端口号
Python静态Web服务器开发
Web静态服务器初识
-
静态Web服务器是一种用于提供静态网页内容的服务器。静态网页是指在服务器上预先创建好的、不包含动态内容的网页,其内容在请求之前已经确定并存储在服务器上。
-
与动态Web服务器相比,静态Web服务器不会对请求的内容进行处理或生成。它仅仅将事先准备好的文件直接发送给客户端浏览器。这些文件可以是HTML、CSS、JavaScript、图像、视频等静态资源。
-
静态Web服务器的主要功能是接收HTTP请求,并根据请求的URL路径返回相应的静态文件。它通常具有以下特点:
-
提供静态文件:静态Web服务器可以按照请求的URL路径查找并返回相应的静态文件。例如,当用户请求
/index.html时,服务器会返回存储在服务器上的index.html文件。 -
不处理动态内容:静态Web服务器不会执行服务器端的脚本或处理动态内容。它仅仅将静态文件原样发送给客户端浏览器。
-
高效快速:由于不需要执行复杂的动态处理逻辑,静态Web服务器通常能够提供较高的性能和响应速度。
-
缓存支持:静态Web服务器通常支持缓存机制,可以在客户端浏览器和服务器之间减少重复的数据传输,提高加载速度和带宽利用率。
-
搭建Python自带的静态Web服务器
- 使用
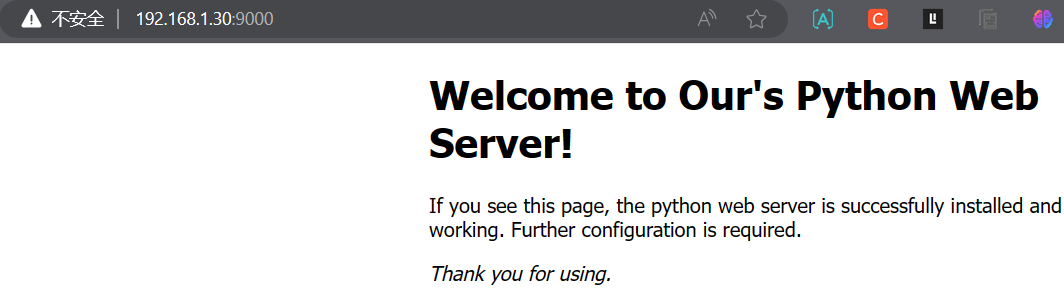
python3 -m http.server 9000命令可以启动一个简单的 HTTP 服务器,并将当前目录作为静态文件服务器根目录。这样,你就可以通过访问http://localhost:9000在本地浏览器中访问当前目录下的静态文件。 python3 -m http.server命令在Python 3中提供了一个简单的开发用途的 HTTP 服务器。它适用于开发和调试阶段,但不适合在生产环境中使用
root@armbian:/usr/python/static# python3 -m http.server 9000
Serving HTTP on 0.0.0.0 port 9000 (http://0.0.0.0:9000/) ...

静态Web服务器返回固定页面数据
- 开发步骤:
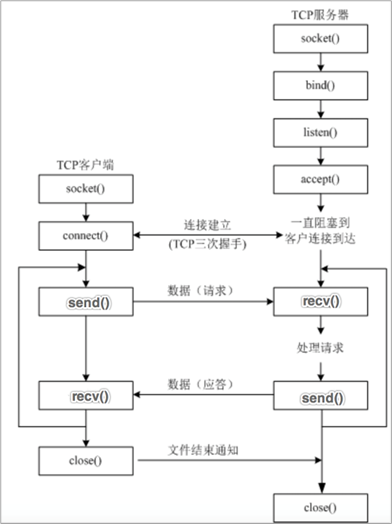
- 编写一个TCP服务端程序
- 获取浏览器发送的HTTP请求报文数据
- 读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器
- HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字。
- TCP服务端程序代码
import socketif __name__ == '__main__':# 1.编写一个TCP服务端程序# 创建socekttcp_server_socekt = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口复用 tcp_server_socekt.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定地址tcp_server_socekt.bind(("", 8080))# 设置监听tcp_server_socekt.listen(128)while True:# 2.获取浏览器发送的HTTP请求报文数据# 建立链接client_socekt, client_addr = tcp_server_socekt.accept()# 获取浏览器的请求信息client_request_data = client_socekt.recv(1024).decode()print(client_request_data)# 3.读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器with open("./static/index.html", "rb") as f:file_data = f.read()# 应答行response_line = "HTTP/1.1 200 OK\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = file_data# 应答数据response_data = (response_line + response_header + "\r\n").encode() + response_bodyclient_socekt.send(response_data)# 4.HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字client_socekt.close()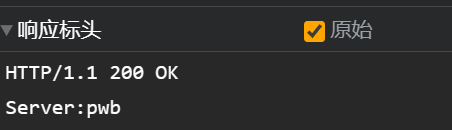
- 服务器终端输出的内容
GET / HTTP/1.1 Host: 192.168.1.30:8080 Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 Cookie: psession=74f200f6-b00b-4762-adea-c413ef6b9853
静态Web服务器返回指定页面数据
- 目前的Web服务器,不管用户访问什么页面,返回的都是固定页面的数据
- 分析步骤:
- 获取用户请求资源的路径
# GET /index2.html HTTP/1.1xxxxxxxclient_request_conent = client_request_data.decode(“utf-8”) # 使用空格分割用户请求的数据 request_list = client_request_conent.split(” ”) # 获取用户请求的资源路径 request_path = request_list[1] print(request_path) if request_path == "/":# 如果用户没有指定资源路径那么默认访问的数据是首页的数据request_path = "/index.html"- 根据请求资源的路径,读取指定文件的数据
# 读取指定文件数据 # 使用rb的原因是浏览器也有可能请求的是图片 with open("static" + request_path, "rb") as file:# 读取文件数据file_data = file.read()- 组装指定文件数据的响应报文,发送给浏览器
# 响应行 response_line = "HTTP/1.1 200 OK\r\n" # 响应头 response_header = "Server: PWS1.0\r\nContent-Type: text/html;charset=utf-8\r\n" # 响应体 response_body = file_data # 拼接响应报文数据 response_data = (response_line + response_header + "\r\n").encode("utf-8") + response_body # 发送响应报文数据 conn_socket.send(response_data) conn_socket.close()- 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器
try:# 打开指定文件,代码省略...except Exception as e:response_line = “HTTP/1.1 404 Not Found\r\n” response_header = “Server: PWS1.0\r\nContent-Type: text/html;charset=utf-8\r\n”response_body = “<h1>非常抱歉,您当前访问的网页已经不存在了</h1>”.encode(“utf-8”)response_data = (response_line + response_header + “\r\n”).encode(“utf-8”) + response_body# 发送404响应报文数据conn_socket.send(response_data)else: # 发送指定页面的响应报文数据,代码省略...finally:conn_socket.close()
- 完整的内容
import socket# 1 获取用户请求资源的路径
# 2 根据请求资源的路径,读取指定文件的数据
# 3 组装指定文件数据的响应报文,发送给浏览器
# 4 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器if __name__ == '__main__':# 1.编写一个TCP服务端程序# 创建socekttcp_server_socekt = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口复用 tcp_server_socekt.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定地址tcp_server_socekt.bind(("", 8080))# 设置监听tcp_server_socekt.listen(128)while True:# 2.获取浏览器发送的HTTP请求报文数据# 建立链接client_socekt, client_addr = tcp_server_socekt.accept()# 获取浏览器的请求信息client_request_data = client_socekt.recv(1024).decode()if len(client_request_data) <= 1:print("客户端已经关闭")print(client_request_data)else:# 获取用户请求资源的路径requst_data = client_request_data.split(" ")print(requst_data)# 求资源的路径request_path = requst_data[1]if request_path == "/":request_path = "/index.html"# 3.读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器# 根据请求资源的路径,读取指定文件的数据try:with open("./static" + request_path, "rb") as f:file_data = f.read()except Exception as e:# 返回404错误数据# 应答行response_line = "HTTP/1.1 404 Not Found\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = "404 Not Found sorry"# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n" + response_body).encode()client_socekt.send(response_data)else:# 应答行response_line = "HTTP/1.1 200 OK\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = file_data# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n").encode() + response_bodyclient_socekt.send(response_data)finally:# 4.HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字client_socekt.close()静态Web服务器多任务版
- 开发多任务版的Web服务器同时处理多个客户端的请求,可以使用多线程,比进程更加节省内存资源。
- 当客户端和服务端建立连接成功,创建子线程,使用子线程专门处理客户端的请求,防止主线程阻塞
while True:conn_socket, ip_port = tcp_server_socket.accept()# 开辟子线程并执行对应的任务sub_thread = threading.Thread(target=handle_client_request, args=(conn_socket,)) - 完整的代码
import socket import threading# 获取用户请求资源的路径 # 根据请求资源的路径,读取指定文件的数据 # 组装指定文件数据的响应报文,发送给浏览器 # 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器def handle_client_request(client_socekt):# 获取浏览器的请求信息client_request_data = client_socekt.recv(1024).decode()print(client_request_data)# 获取用户请求资源的路径requst_data = client_request_data.split(" ")print(requst_data)# 判断客户端是否关闭if len(requst_data) == 1:client_socekt.close()return# 求资源的路径request_path = requst_data[1]if request_path == "/":request_path = "/index.html"# 3.读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器# 根据请求资源的路径,读取指定文件的数据try:with open("./static" + request_path, "rb") as f:file_data = f.read()except Exception as e:# 返回404错误数据# 应答行response_line = "HTTP/1.1 404 Not Found\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = "404 Not Found sorry"# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n" + response_body).encode()client_socekt.send(response_data)else:# 应答行response_line = "HTTP/1.1 200 OK\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = file_data# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n").encode() + response_bodyclient_socekt.send(response_data)finally:# 4.HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字client_socekt.close()if __name__ == '__main__':# 1.编写一个TCP服务端程序# 创建socekttcp_server_socekt = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口复用 tcp_server_socekt.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定地址tcp_server_socekt.bind(("", 8080))# 设置监听tcp_server_socekt.listen(128)while True:# 2.获取浏览器发送的HTTP请求报文数据# 建立链接client_socekt, client_addr = tcp_server_socekt.accept()# 创建子线程sub_thread = threading.Thread(target=handle_client_request, args=(client_socekt,))sub_thread.start()
静态Web服务器面向对象开发
- 分析步骤:
- 把提供服务的Web服务器抽象成一个类(HTTPWebServer)
- 提供Web服务器的初始化方法,在初始化方法里面创建Socket对象
- 提供一个开启Web服务器的方法,让Web服务器处理客户端请求操作
class HttpWebServer(object):def __init__(self):# 初始化服务端套接字,设置监听,代码省略...# 启动服务器def start(self):while True:conn_socket, ip_port = self.tcp_server_socket.accept()# 连接建立成功,开辟子线程处理客户端的请求sub_thread = threading.Thread(target=self.handle_client_request, args=(conn_socket,))sub_thread.start()@staticmethoddef handle_client_request(conn_socket):# 根据用户请求,响应对应资源数据,代码省略...import socket
import threading# 获取用户请求资源的路径
# 根据请求资源的路径,读取指定文件的数据
# 组装指定文件数据的响应报文,发送给浏览器
# 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器
class HttpWebServer:def __init__(self):# 1.编写一个TCP服务端程序# 创建socektself.tcp_server_socekt = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口复用 self.tcp_server_socekt.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定地址self.tcp_server_socekt.bind(("", 8080))# 设置监听self.tcp_server_socekt.listen(128)def handle_client_request(self, client_socekt):# 获取浏览器的请求信息client_request_data = client_socekt.recv(1024).decode()print(client_request_data)# 获取用户请求资源的路径requst_data = client_request_data.split(" ")print(requst_data)# 判断客户端是否关闭if len(requst_data) == 1:client_socekt.close()return# 求资源的路径request_path = requst_data[1]if request_path == "/":request_path = "/index.html"# 3.读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器# 根据请求资源的路径,读取指定文件的数据try:with open("./static" + request_path, "rb") as f:file_data = f.read()except Exception as e:# 返回404错误数据# 应答行response_line = "HTTP/1.1 404 Not Found\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = "404 Not Found sorry"# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n" + response_body).encode()client_socekt.send(response_data)else:# 应答行response_line = "HTTP/1.1 200 OK\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = file_data# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n").encode() + response_bodyclient_socekt.send(response_data)finally:# 4.HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字client_socekt.close()def start(self):while True:# 2.获取浏览器发送的HTTP请求报文数据# 建立链接client_socekt, client_addr = self.tcp_server_socekt.accept()# 创建子线程sub_thread = threading.Thread(target=self.handle_client_request, args=(client_socekt,))sub_thread.start()if __name__ == '__main__':# 创建服务器对象my_web_server = HttpWebServer()# 启动服务器my_web_server.start()静态Web服务器命令行启动动态绑定端口号
-
获取终端命令行参数动态绑定端口号的web服务器程序
- 获取执行python程序的终端命令行参数
- 判断参数的类型,设置端口号必须是整型
- 给Web服务器类的初始化方法添加一个端口号参数,用于绑定端口号
-
完整代码演示:
import socket
import threading
import sys# 获取用户请求资源的路径
# 根据请求资源的路径,读取指定文件的数据
# 组装指定文件数据的响应报文,发送给浏览器
# 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器
class HttpWebServer:def __init__(self, port):# 1.编写一个TCP服务端程序# 创建socektself.tcp_server_socekt = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口复用 self.tcp_server_socekt.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定地址self.tcp_server_socekt.bind(("", port))# 设置监听self.tcp_server_socekt.listen(128)def handle_client_request(self, client_socekt):# 获取浏览器的请求信息client_request_data = client_socekt.recv(1024).decode()print(client_request_data)# 获取用户请求资源的路径requst_data = client_request_data.split(" ")print(requst_data)# 判断客户端是否关闭if len(requst_data) == 1:client_socekt.close()return# 求资源的路径request_path = requst_data[1]if request_path == "/":request_path = "/index.html"# 3.读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器# 根据请求资源的路径,读取指定文件的数据try:with open("./static" + request_path, "rb") as f:file_data = f.read()except Exception as e:# 返回404错误数据# 应答行response_line = "HTTP/1.1 404 Not Found\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = "404 Not Found sorry"# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n" + response_body).encode()client_socekt.send(response_data)else:# 应答行response_line = "HTTP/1.1 200 OK\r\n"# 应答头response_header = "Server:pwb\r\n"# 应答体response_body = file_data# 应答数据# 组装指定文件数据的响应报文,发送给浏览器response_data = (response_line + response_header + "\r\n").encode() + response_bodyclient_socekt.send(response_data)finally:# 4.HTTP响应报文数据发送完成以后,关闭服务于客户端的套接字client_socekt.close()def start(self):while True:# 2.获取浏览器发送的HTTP请求报文数据# 建立链接client_socekt, client_addr = self.tcp_server_socekt.accept()# 创建子线程sub_thread = threading.Thread(target=self.handle_client_request, args=(client_socekt,))sub_thread.start()def main():# 获取执行python程序的终端命令行参数print(sys.argv)# 检查 sys.argv 列表的长度是否为 2。如果长度不等于 2,说明传递给脚本的参数数量不正确if len(sys.argv) != 2:print("格式错误 python3 xxx.py 9090")return# 判断参数的类型,设置端口号必须是整型if not sys.argv[1].isdigit():print("格式错误 python3 xxx.py 9090")returnport = int(sys.argv[1])# 创建服务器对象# 给Web服务器类的初始化方法添加一个端口号参数,用于绑定端口号my_web_server = HttpWebServer(port)# 启动服务器my_web_server.start()if __name__ == '__main__':main()