当下,深度学习已经成为人工智能研究和应用领域的关键技术之一。作为一个开源的高级编程语言,Python提供了丰富的工具和库,为深度学习的研究和开发提供了便利。本文将深入探究Python中的深度学习,重点聚焦于神经网络与卷积神经网络的原理和应用。
文章目录
- 1. 引言
- - 简介
- - 深度学习与Python的关系
- 2. 神经网络的原理
- - 神经网络基础知识
- - Python中的神经网络库与工具
- - 构建与训练神经网络模型的步骤
- 深度学习训练过程
- 3. 卷积神经网络的原理
- - 卷积层与池化层
- - 特征提取与全连接层
- - Python中的CNN库与工具
- 4. Python中深度学习的挑战和未来发展方向
- - 计算资源与速度
- - 迁移学习与模型压缩
- - 融合多种深度学习算法
1. 引言
- 简介
深度学习是机器学习的一个分支,通过建立和训练深层神经网络来实现对数据的高级抽象和学习能力。它利用多个处理层级的神经网络模型,实现了从低级特征到高级抽象的逐步提取和学习。深度学习在计算机视觉、自然语言处理、语音识别、人工智能等领域取得了令人瞩目的成果。
- 深度学习与Python的关系
Python作为一种简洁易读的高级编程语言,成为了深度学习领域的首选语言之一。Python拥有丰富而强大的科学计算库和深度学习框架,如NumPy、Pandas、TensorFlow、PyTorch等,为深度学习的研究、开发和应用提供了良好的支持。
Python的简洁语法和丰富的第三方库使得深度学习任务的实现更加高效和便捷。此外,Python社区活跃,有大量的教程、文档和资源、小程序可供学习和参考,使得深度学习的入门门槛降低,吸引了大量的开发者和研究者。
因此,Python与深度学习的关系紧密相连,为深度学习技术的发展和应用提供了强有力的支持与推动。 🐍🧠
2. 神经网络的原理
- 神经网络基础知识
神经网络是一种模拟生物神经系统工作方式的计算模型。它由神经元(或称为节点)组成,这些神经元通过连接来传递信息,并通过学习调整连接权重以适应输入数据。神经网络的基本组成包括输入层、隐藏层和输出层。输入层接收原始数据,隐藏层通过一系列非线性函数转化输入,输出层产生最终的预测结果。信息在网络中传播的过程被称为前向传播,而通过调整连接权重以优化模型性能的过程被称为反向传播。使用自下上升非监督学习,后自顶向下的监督学习。

- Python中的神经网络库与工具
Python提供了多个强大的神经网络库和工具,使得构建和训练神经网络模型变得更加方便和高效。一些流行的神经网络库包括:
- TensorFlow: 一个广泛使用的开源深度学习库,提供了灵活的工具和API来构建各种类型的神经网络模型。
- PyTorch: 另一个流行的深度学习库,具有易于使用的动态计算图和丰富的功能,广泛用于研究和实际应用。
- Keras: 一个高级神经网络API,可以在TensorFlow、PyTorch等后端引擎上运行,简化了神经网络模型的构建和训练流程。
- scikit-learn: 一个通用机器学习库,提供了许多标准的神经网络模型和工具,适用于小规模的问题和实验。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建序列模型
model = Sequential()# 添加全连接层
model.add(Dense(64, activation='relu', input_dim=10))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 创建输入特征和标签
x_train = [...] # 输入特征
y_train = [...] # 标签# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=32)# 进行预测
x_test = [...] # 测试集输入特征
predictions = model.predict(x_test)
- 构建与训练神经网络模型的步骤
- 数据准备:收集和准备训练数据集,包括数据清洗、标准化和划分为训练集和测试集。
- 网络搭建:选择适当的神经网络结构,并使用选定的库或工具创建网络模型,包括定义网络层、激活函数和损失函数等。
- 模型编译:配置模型的优化器(optimizer)、损失函数和评估指标,指定训练过程中的参数更新策略。
- 模型训练:使用训练数据对模型进行训练,通过反向传播算法更新模型的权重和偏置,不断优化模型的性能。
- 模型评估:使用测试数据评估训练后的模型的性能和准确度,根据需要进行调整和改进。
- 模型应用:将训练好的模型应用于新的数据进行预测或分类等任务。
深度学习训练过程
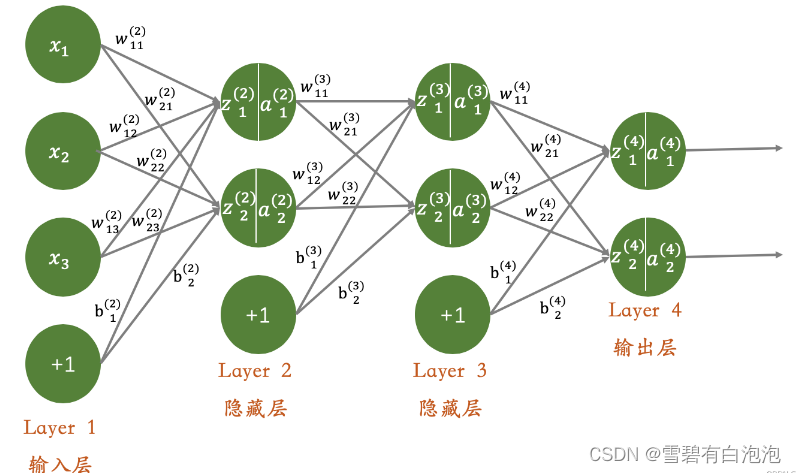
3. 卷积神经网络的原理
- 卷积层与池化层
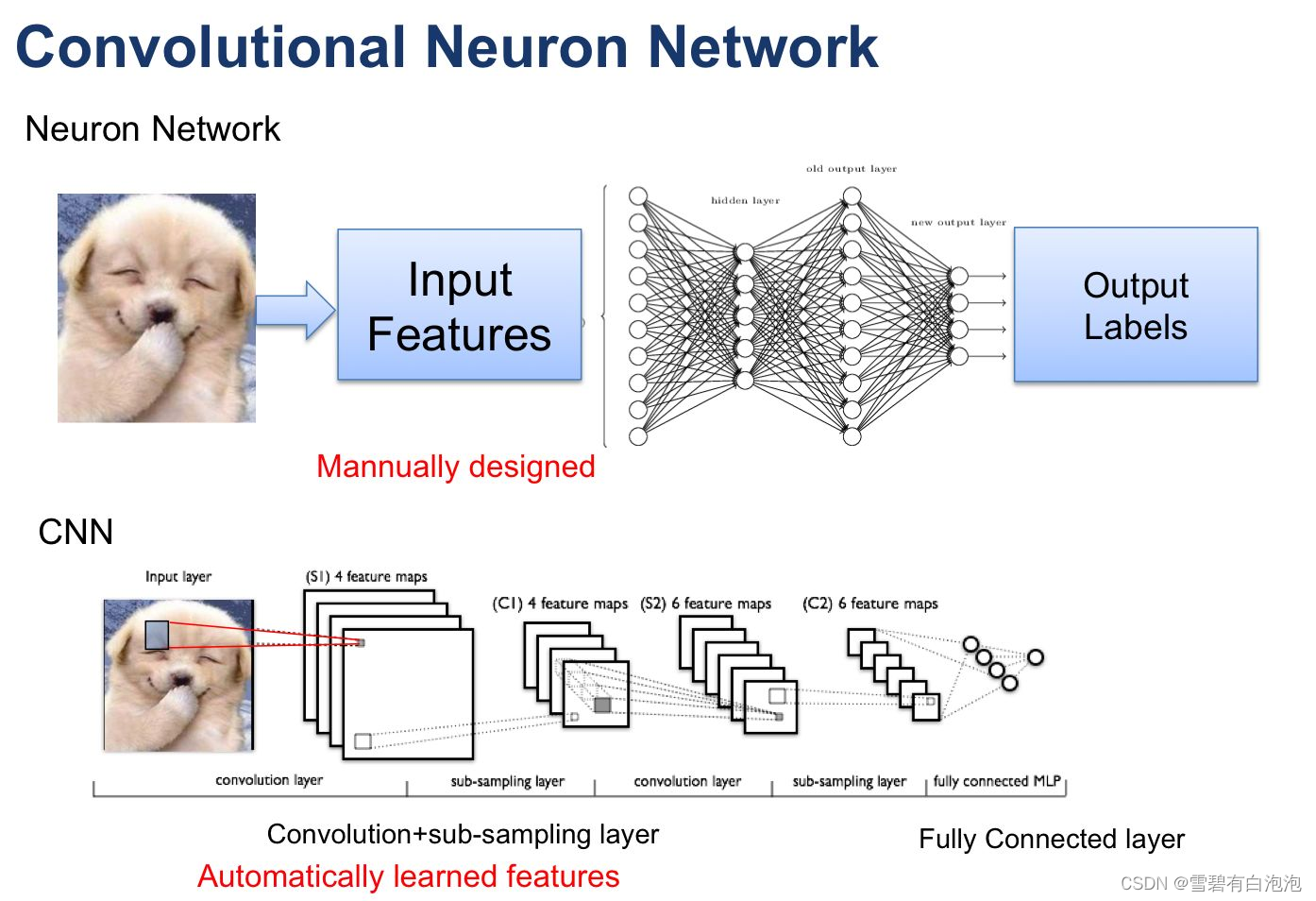
卷积神经网络(Convolutional Neural Network,CNN)是一种特殊类型的神经网络,主要应用于图像和语音等二维或多维数据的处理。它通过卷积层和池化层来提取输入数据中的空间结构特征。
卷积层使用一组可学习的过滤器(也称为卷积核)对输入数据进行卷积操作,产生一系列特征映射。每个过滤器通过滑动窗口的方式在输入数据上进行扫描,将局部区域与过滤器的权值进行乘积求和,得到一个输出值。经过多个过滤器的卷积操作,可以提取出不同的特征,如边缘、纹理等。
池化层用于减小特征图的尺寸并保留重要的特征。常见的池化操作包括最大池化和平均池化,它们通过在输入区域中选取最大值或平均值来生成池化后的输出。池化操作可减少数据的维度,并且对平移和尺度变化具有一定的不变性。这样可以减少模型的参数数量,提高计算效率,同时保留主要的特征信息。

- 特征提取与全连接层
在卷积层和池化层之后,通常会添加一个或多个全连接层。全连接层的神经元与前一层的所有神经元都连接在一起,通过权重矩阵进行线性变换,并通过激活函数(如ReLU)引入非线性性。全连接层负责将卷积和池化层提取的特征进行组合和转换,生成最终的输出。
全连接层可以看作是对高级特征的抽象和组合。它能够学习输入数据之间的复杂关系,并通过反向传播算法将这些关系反馈到前面的层,从而不断优化整个模型以更好地适应任务需求。
- Python中的CNN库与工具
使用Python构建卷积神经网络非常便捷,因为有许多强大的库和工具可供选择。一些常用的CNN库包括:
TensorFlow:提供了灵活的API和工具来构建和训练卷积神经网络模型。
Keras:作为TensorFlow的高级API,简化了模型构建和训练的过程,同时支持卷积神经网络。
PyTorch:具有动态计算图和丰富功能的深度学习库,支持卷积神经网络的构建和训练。
MXNet:一个高效且可扩展的深度学习库,对卷积神经网络提供了良好的支持。
Caffe:一个专门用于计算机视觉任务的深度学习框架,包括卷积神经网络在内的多种模型结构。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense# 创建序列模型
model = Sequential()# 添加卷积层和池化层
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))# 添加更多卷积层和池化层(可选)
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))# 展平特征图
model.add(Flatten())# 添加全连接层
model.add(Dense(128, activation='relu'))# 输出层
model.add(Dense(10, activation='softmax'))# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 打印模型结构
model.summary()
4. Python中深度学习的挑战和未来发展方向
- 计算资源与速度
深度学习算法的训练和推理通常需要大量的计算资源和时间。尤其是当模型规模变得更大、数据集变得更复杂时,对计算资源的需求会进一步增加。在Python中,面临的挑战之一就是如何有效地利用有限的计算资源,并寻求加速深度学习算法的方法。
为了应对这一挑战,研究人员和工程师们不断努力提高深度学习框架的计算效率和速度。他们通过并行计算、GPU加速、量化技术等方法来减少训练和推理的时间开销。此外,还有一些专门针对深度学习的硬件加速器(如GPU、TPU)被广泛应用,以提供更强大的计算能力。

- 迁移学习与模型压缩
迁移学习是指将已经在一个任务上训练好的模型应用于另一个相关任务中。在Python中,深度学习中的迁移学习被广泛探索和应用。通过复用预训练的模型,可以减少训练时间和数据需求,同时提高在新任务上的性能。
另一个与迁移学习相关的挑战是模型压缩。深度学习模型通常具有巨大的参数量,造成计算和存储的开销。为了解决这个问题,研究人员提出了一些模型压缩的技术,例如剪枝(pruning)、量化(quantization)和低秩近似(low-rank approximation)。这些方法可以大幅减少模型的大小和计算复杂度,同时保持较高的预测性能。
- 融合多种深度学习算法
深度学习领域涌现出了许多有效的算法和模型,如卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)等。在Python中,将多种深度学习算法进行融合成为一个研究方向。
融合多种深度学习算法可以利用它们各自的优势,提供更强大和多样化的学习能力。例如,将CNN用于图像特征提取,再将RNN用于序列建模,可以在多个层面上捕捉到数据的信息。此外,还有一些模型融合的技术,如集成学习(ensemble learning)和深度融合(deep fusion),用于整合多个模型的预测结果。
- 🎁本次送书1~3本【取决于阅读量,阅读量越多,送的越多】👈
- ⌛️活动时间:截止到2023-11月2号
- ✳️参与方式:关注博主+三连(点赞、收藏、评论)
购买链接:地址

私信我进送书互三群有更多福利哦可以在文章末尾或主页添加微信
如果你有B站\抖音\知乎\公号等媒体账号
那么就来加入我们#ITBOOK多得 荐书官召集令 活动吧!详情请参见下方海报~