作者:Valerio Arvizzigno, Dimitri Marx, Francesco Di Stefano

这是一篇通过生成式 AI/LLM、自定义模型和 Elasticsearch 相关性引擎 (ESRE) 支持制药行业更快的药物创新和发现的综合指南。更快的药物发现带来有前途的候选药物是制药行业的主要目标。 为了支持这一目标,该行业必须找到更好的方法来快速且安全地利用公共和专有数据。
根据产权组织(WIPO)的说法,研发专利分析可以帮助研究人员和创新者:
- 避免重复研发工作
- 确定其发明的可专利性
- 避免侵犯其他发明人的专利
- 估计他们或其他发明人的专利的价值
- 利用从未授予、在某些国家/地区无效的专利申请或不再有效的专利中的技术
- 获取有关业务竞争对手的创新活动和未来方向的情报
- 改进业务决策规划,例如许可、技术合作伙伴关系以及并购
- 确定公共利益特定技术领域的主要趋势,例如与健康或环境相关的技术领域,并为政策规划提供基础
随着生成式人工智能(GAI)的出现,实现这一目标的可能性从未如此接近。 然而,也存在挑战。 其中之一是如何将公司的私有、专有数据融入 GAI 的功能中。
Elasticsearch Relevance Engine™ (ESRE™ ) 与生成式 AI 问答功能的结合可以帮助研发团队开发强大的解决方案。 ESRE 旨在为基于人工智能的搜索应用程序提供支持。 它用于应用具有开箱即用的卓越相关性的语义搜索(无需域适应)、执行矢量搜索、与外部大语言模型 (LLM) 集成、实现混合搜索以及使用第三方或你自己的转换器模型。
在本博客中,你将了解如何利用 ESRE 和 GAI 使研发组织能够有效地与数据交互并在药物发现过程中做出更好的决策。 隐私和上下文缺失的挑战将得到解决。
虽然我们这篇博文的目标是制药行业,但概述的方法对于任何从事研发的组织都有效。
情境化的挑战
在知识产权和创新领域,研究人员、专业人士和分析师面临着一些重大挑战。 让我们来探讨其中的一些。
碎片化的信息格局
与专利和相关领域相关的数据分布在多个来源,每个来源都有自己的结构、格式和访问方法。 专利本身通常由不同的国家和国际专利局公布,这使得收集全面的数据集进行分析变得很麻烦。 此外,与现有技术、专利诉讼和科学文献相关的信息可以在各种数据库、出版物和存储库中找到。 缺乏集中和标准化的系统可能会导致数据发现、收集和集成效率低下。

混淆(obfuscation)的力量
一些发明人可能会采用一种战略方法来混淆专利文档中的发明。 使用模棱两可的语言、复杂的措辞和故意模糊可以让他们掩盖其创作的内部运作和技术细节。 这种故意的黑暗有多种目的。 首先,它可以防止竞争对手仅根据专利说明轻易复制该发明。 其次,它为发明人提供了根据不同背景和新兴技术调整其权利要求的灵活性。 最后,它引入了不确定性因素,增加了潜在侵权者的复杂性,并增加了诉讼成功的可能性。
幻觉和一般背景
GAI 面临的挑战之一是幻觉现象。 幻觉是指人工智能模型生成听起来自信但错误的输出,特别是当它被问到特定领域的问题时。
以下是了解幻觉的要点:
上下文理解有限
像 LLMs(Large Language Models)这样的人工智能模型接受了来自各种来源的大量数据的训练,但它们可能仍然缺乏对特定领域(例如医疗保健和制药)的全面知识和理解。 当遇到特定领域的问题或复杂的场景时,模型可能会提供听起来似乎合理但实际上不正确或具有误导性的响应。
对训练数据的依赖
训练数据的质量和多样性对人工智能模型的性能起着至关重要的作用。 如果训练数据没有充分涵盖所有相关方面或包含偏差,则模型可能会生成与训练数据中存在的模式一致但不能准确反映现实的幻觉。
对反应过度自信
包括 LLMs 在内的人工智能模型即使在不确定或问题超出其知识范围时也能表现出提供自信答案的倾向。 这种过度自信可能会导致向用户提供误导性或不正确的信息,特别是当他们不知道模型的局限性时。
寻求解决方案
数据源整合
Elastic® 提供灵活的数据摄取选项,使研发团队能够无缝地从各种来源引入数据。 它支持 JSON 和 CSV 等结构化数据格式,以及文本文档、图像嵌入(密集向量)和音频文件等非结构化数据。 Elastic 丰富的摄取 API(例如 Bulk API、Agents 和 Logstash®)可实现高效且自动化的数据摄取流程。
除了上面提到的灵活的数据摄取选项之外,Elastic 还提供了通过网络爬行集成网站数据的强大功能。 借助网络爬虫,研发团队可以自动从网站中提取和摄取数据,扩大可分析的信息源范围。 有关网络爬虫的精彩示例,请阅读这篇博客文章。
情境可视化
Kibana® 将专利数据集转化为具有视觉吸引力和互动性的见解。 凭借其直观的界面和多样化的可视化选项,研究人员可以轻松探索和分析专利趋势、模式和关系。 从动态图表和地图到强大的过滤功能,Kibana 使研究人员能够提取有价值的知识、识别关键参与者并做出数据驱动的决策。 其协作功能可实现见解的无缝共享和讨论,促进跨职能协作并加速研究成果。
反混淆新颖的方面
Elasticsearch 的重要文本聚合是一项强大的功能,可让你识别一组文档或特定字段中的重要术语。 它通过突出显示具有统计意义的术语并将其与常见或背景术语区分开来帮助你发现有意义的见解。
重要文本聚合的工作原理是将数据集中每个术语的术语频率与基于背景语料库的预期频率进行比较。 背景语料库通常是较大的文档集或代表性样本,用作确定哪些术语是常见的以及哪些术语是重要的参考。
以下是专利数据集的示例。 该查询可能如下所示:
GET patent-publications-1/_search
{"size" : 0,"query": {"match": {"abstract_localized.text": {"query": "covid"}}},"aggs": {"hidden_terms": {"significant_text": {"field": "claims_localized_html.text"}}}
}回复揭示了专利中使用的一组 “hidden” 术语:
"aggregations": {"hidden_terms": {"doc_count": 218,"bg_count": 14899225,"buckets": [{"key": "covid","doc_count": 32,"score": 3776.7204780742363,"bg_count": 85},{"key": "remdesivir","doc_count": 3,"score": 564.3033204275735,"bg_count": 5},{"key": "coronavirus","doc_count": 7,"score": 150.57538997839688,"bg_count": 102},{"key": "cov","doc_count": 6,"score": 142.83756108838813,"bg_count": 79},{"key": "sars","doc_count": 7,"score": 137.1282917578487,"bg_count": 112}]}
}通过这些术语,研究人员可以完善调查。
此外,我们将展示如何将这一强大的功能与 LLM 集成。
私人数据和通用 LLMs 之间的桥梁
研究人员最好的朋友:PatChat
为了进行现有技术检索及其他功能,我们的演示应用程序 PatChat 演示了研究人员如何与专利、科学文献、临床研究、诉讼和专有信息进行交互。 演示中的方法展示了公司如何应对上述有关幻觉和一般背景的挑战。 在 ESRE 功能的支持下,Elastic 以一种非常优雅的方式弥合了这一点。
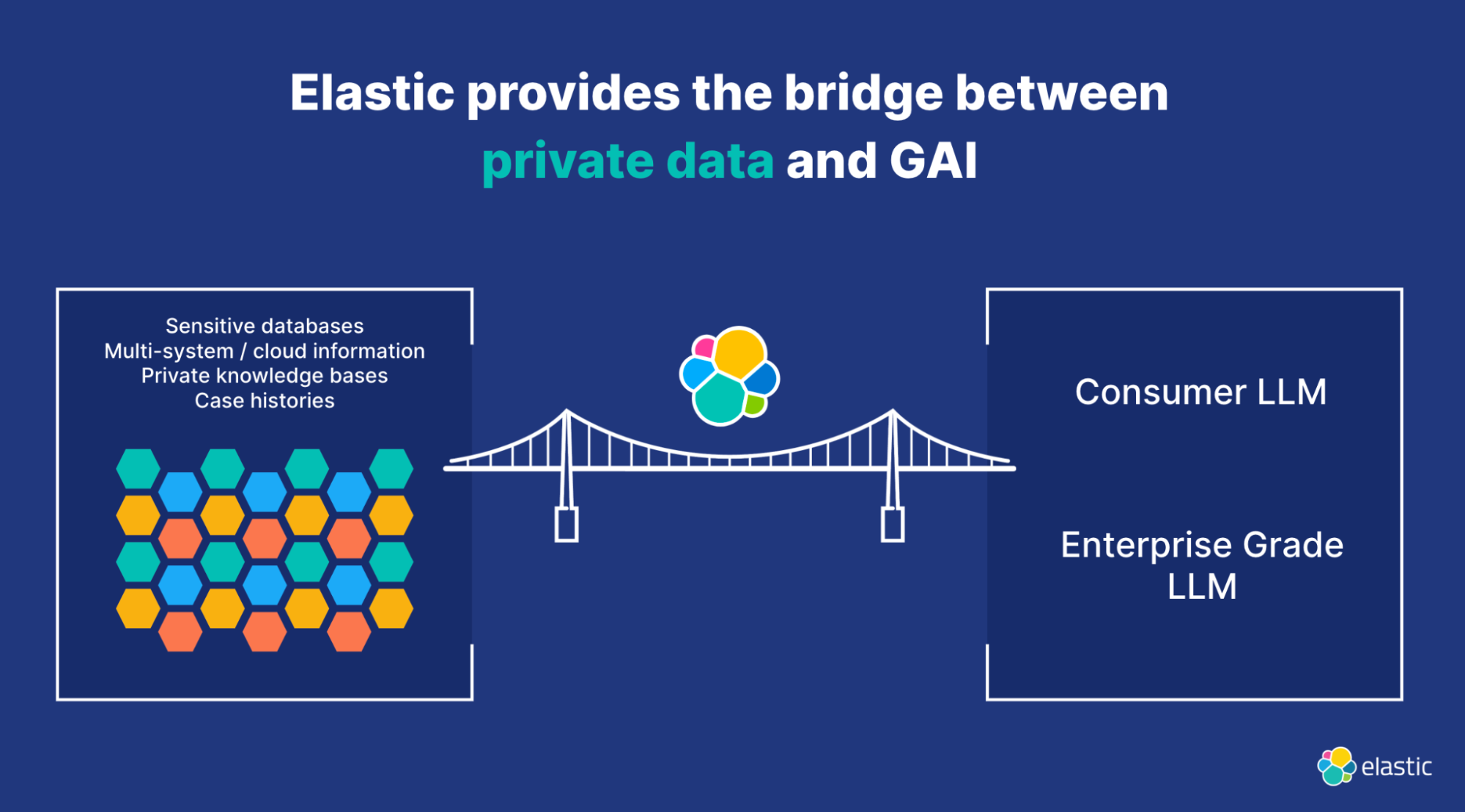
该应用程序使用 GAI 展示了一种直观、高效地探索复杂信息环境的方法。 研究人员可以提出具体问题,接收实时和上下文感知的见解,并轻松导航数据。 该应用程序的用户友好界面、交互式可视化和领域定制有助于提高研究效率、促进发现并推动跨学科创新。 使用 PatChat 体验一种改变游戏规则的方法,从不同的信息源中提取有价值的知识。
警告说明:请将此应用程序视为一个快速完成的程序,到目前为止还没有用于生产用途。

矢量搜索
我们先来谈谈一些基础知识。 在查询 LLM 之前,我们利用矢量搜索和自定义模型从 Elasticsearch 服务中检索上下文。 以下是在 _search API 调用中使用的查询示例。
首先,我们构建一个经典查询来搜索、过滤甚至聚合特定字段:
query = {"bool": {"must": [{"match": {"abstract_localized.text": {"query": query_text,"boost": 1}}}],"filter": [{"exists": {"field": "abstract-vector.predicted_value"}}]}
}其次,我们基于模型定义 KNN 查询:
knn = {"field": "abstract-vector.predicted_value","k": 3,"num_candidates": 20,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-distilroberta-v1","model_text": query_text}},"boost": 24
}以下是关键要素及其意义:
1)query:这是一个布尔查询,使用 match 子句在 abstract_localized.text 字段中搜索提供的 query_text。 它的值提升为 1,表明其重要性。 filter 子句确保仅考虑存在 abstract-vector.predicted_value 字段的文档。
2)knn:这是一个 K 近邻(KNN)查询,用于向量相似度搜索。 它将字段 abstract-vector.predicted_value 指定为要在其中搜索的向量字段。 参数 k 和 num_candidates 分别确定最近邻居的数量和要考虑的候选者的数量。 Elastic 前一阶段摄取的所有专利数据均由 Transformer 模型进行处理,以丰富其矢量表示形式。
在映射中,字段 vector 被定义为 dense_vector:
"vector": {"type": "dense_vector","dims": 768,"index": true,"similarity": "cosine"
}3)query_vector_builder:此部分旨在为用户的查询创建动态文本嵌入,然后与存储的数据向量进行比较,从而找到语义匹配。 它指定用于推理的模型和构建查询向量的文本。 在本例中,使用 ID 为 sentence-transformers__all-distilroberta-v1 的模型,并将用户提示的查询作为 model_text 输入传递。
4)boost:该参数为 KNN 查询分配 boost 值 24,表明其在文档整体相关性评分中的重要性。
现在我们需要将两个查询(匹配和 knn 查询)联系在一起:
resp = es.search(index=index,query=query,knn=knn,fields=fields,size=1,source=False
)这一切都很棒,但是我们如何简化它并实现与 LLM 的一系列多重交互?
链中之链:LangChain
关于 LangChain 的介绍以及具体 SequentialChain 的概念,请参考此文档。
以下是来自 LangChain 网站的快速摘要:
LangChain 是一个用于开发由语言模型支持的应用程序的框架。 它支持以下应用程序:
- 数据感知:将语言模型连接到其他数据源
- Agentic:允许语言模型与其环境交互
据世界知识产权组织称,现在有多种策略可以进行现有技术检索。 出于本博文的目的,我们将回顾以下策略的一些步骤以及如何通过 ESRE 和 LangChain 实施它们:
- 识别与创新相关的概念
- 确定关键词
- 确定 IPC 符号
- […]
1. 定义一条链来识别创新的关键概念
该功能会提示你识别专利相关上下文中的关键概念。 它包括一个用于询问有关上下文的问题的模板,并需要语言模型 (LLM) 作为输入。 该函数返回一个 LLMChain 对象,该对象用于生成与根据给定上下文识别专利中的关键概念相关的响应。
def step_1_identify_key_concepts_chain():
key_concepts_question = """
You are a scientist or patent layer.
It is your job to find prior art in patents.
The following context describes patents consisting of title, abstract, publication number and some other information: {context}
Identify the key concepts of the patent.
When providing an answer, put the publication number followed by the title first.
Ignore any citation publication numbers.
When asked: {question}
Your answer to the questions using only information in the context is: """
key_concepts_prompt = PromptTemplate(template=key_concepts_question, input_variables=["context", "question"])
return LLMChain(prompt=key_concepts_prompt, llm=llm,output_key="key_concepts")2. 定义一条链来确定专利中的关键字(用于查询生成)
该功能会提示生成关键字,以根据给定的专利关键概念进行进一步的现有技术研究。 它需要语言模型 (LLM) 作为输入。 该函数返回一个 LLMChain 对象,该对象用于生成与根据提供的关键概念识别专利研究关键字相关的响应。
def step_2_identify_keywords_chain():
keywords_question = """
Given the key concepts of a patent, generate keywords for further prior art research.
Use synonyms and related keywords based on your knowledge.
Here are the identified key concepts: {key_concepts}"""
keywords_prompt = PromptTemplate(input_variables =['key_concepts'], template=keywords_question)
return LLMChain(prompt=keywords_prompt, llm=llm, output_key="keywords")现在,让我们使用 Elasticsearch 的向量搜索功能根据问题查询相似文档并将其输入到顺序链中。
def ask_question(question):
similar_docs = es_db.similarity_search(question)context= similar_docs[0].page_content
return chain({"question": question, "context": context})作为响应,你应该能够看到如下内容:
{"key_concepts": "\n The information processing method includes receiving a selection of a garment from a user, calculating a price of the garment on the basis of a type of the selected garment and parameters relating to a design and materials set for the garment, causing a display part to display the calculated price, and changing the parameters in conjunction with an input from the user. The display controlling includes causing the display part to display the price that reflects the changed parameters in response to the change of the parameters. The information processing method further includes generating an appearance image of the garment on the basis of the parameters, wherein the display controlling includes causing the display part to display the appearance image that reflects the changed parameters in response to an input from the user. Additionally, the price calculating includes calculating a price of the garment further on the basis of a parameter relating to a manufacturing process set for the garment.", "keywords": "\nKeywords:\nInformation processing, garment selection, price calculation, parameters, design, materials, display part, input, appearance image, manufacturing process."}3. 确定 IPC 符号
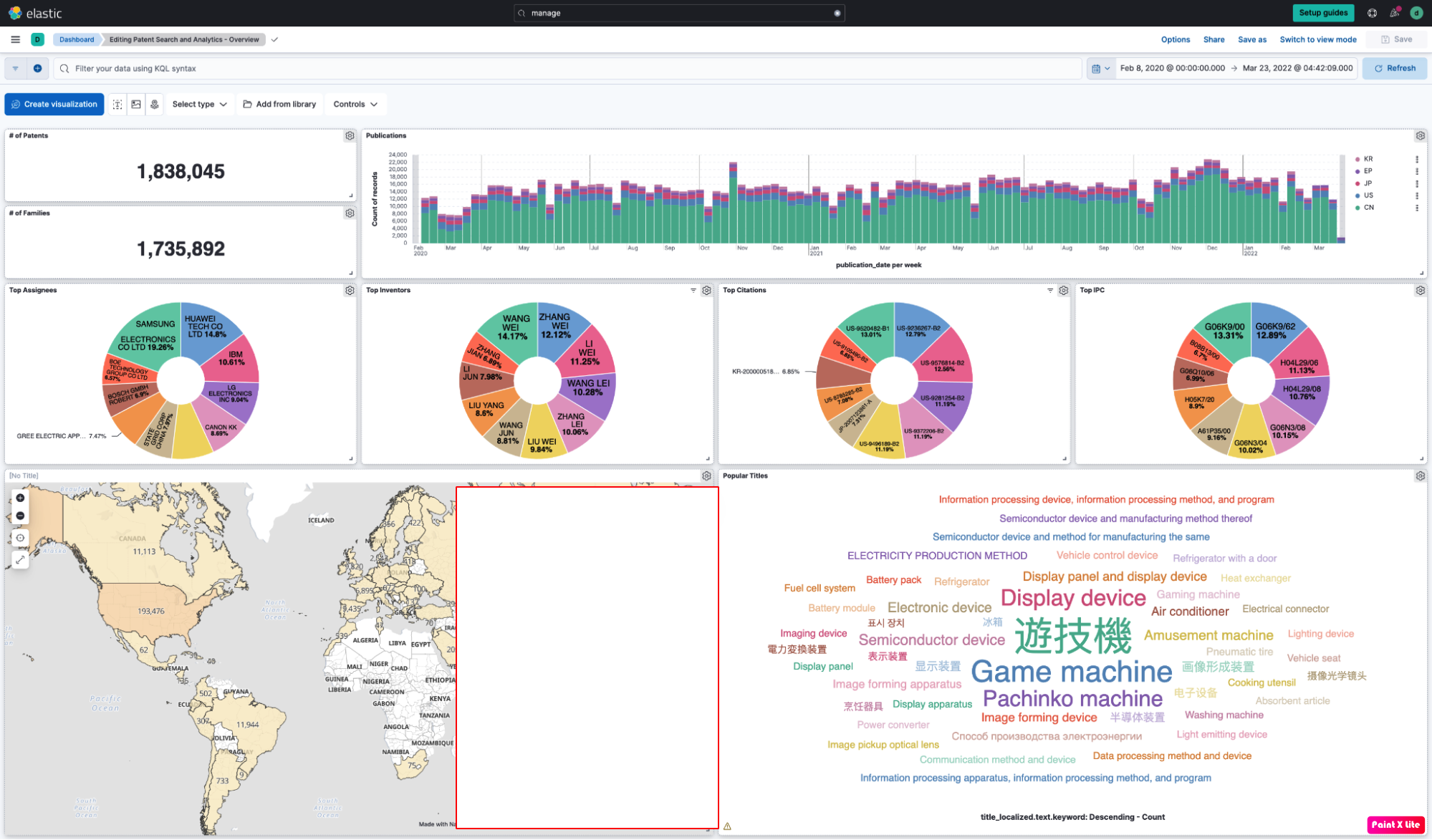
提醒一下,我们将使用关键字(LLM 根据上下文或通过重要文本聚合生成,或两者兼而有之,或其他方式生成)来过滤专利,然后确定相关的 IPC 符号。 有多种方法可以做到这一点。 一个非常引人注目的方法是使用 Kibana 可视化数据的能力,如该屏幕截图所示。
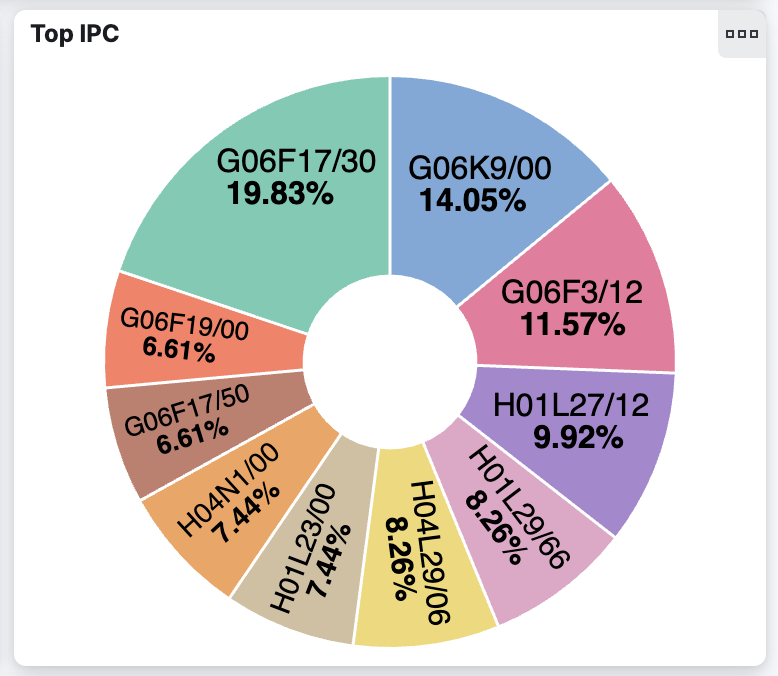
在 Kibana 中,我们使用这些术语来查询数据集:
"information processing" or "garment selection" or "price calculation" or "display part" or "appearance image" or "manufacturing process"游戏化的转变
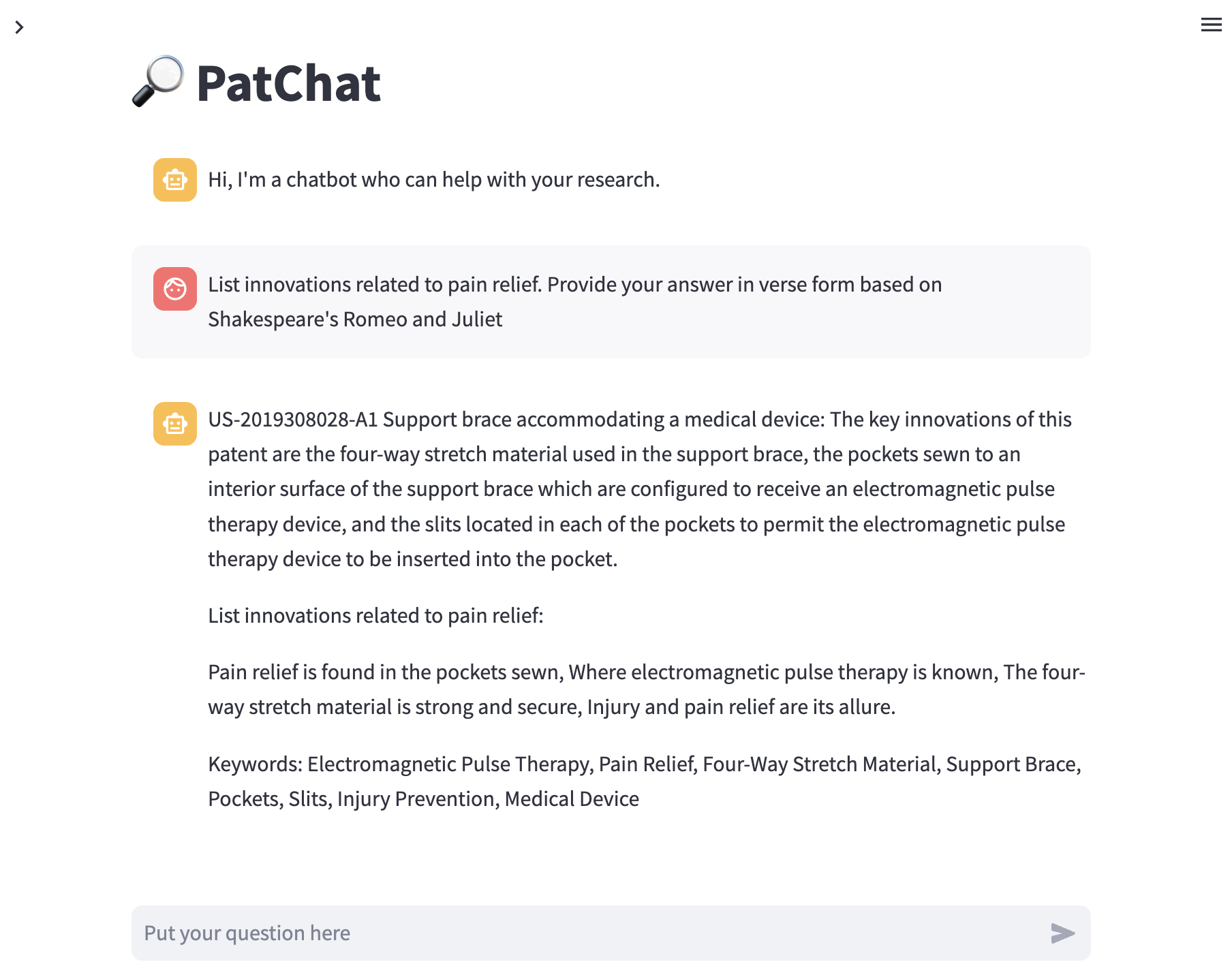
当好奇的研究人员从 PatChat 应用程序中寻求见解时,他们可以通过询问创新来解锁令人愉快的惊喜。 PatChat 带着顽皮的笑容,变身为数字莎士比亚诗人,用罗密欧与朱丽叶风格的答案让研究人员着迷。 每一个回应都是学术知识和吟游诗人本人的诗意天赋的异想天开的融合。 从抑扬格五音步到诗意隐喻,研究人员被带入了一个学术界和戏剧交织在一起的世界。 这是一个迷人的转折,为对知识的追求增添了一丝幽默和创造力,展示了 PatChat 带来惊喜和愉悦的能力。 因此,如果你有勇气,请大胆向 PatChat 询问莎士比亚的创新。
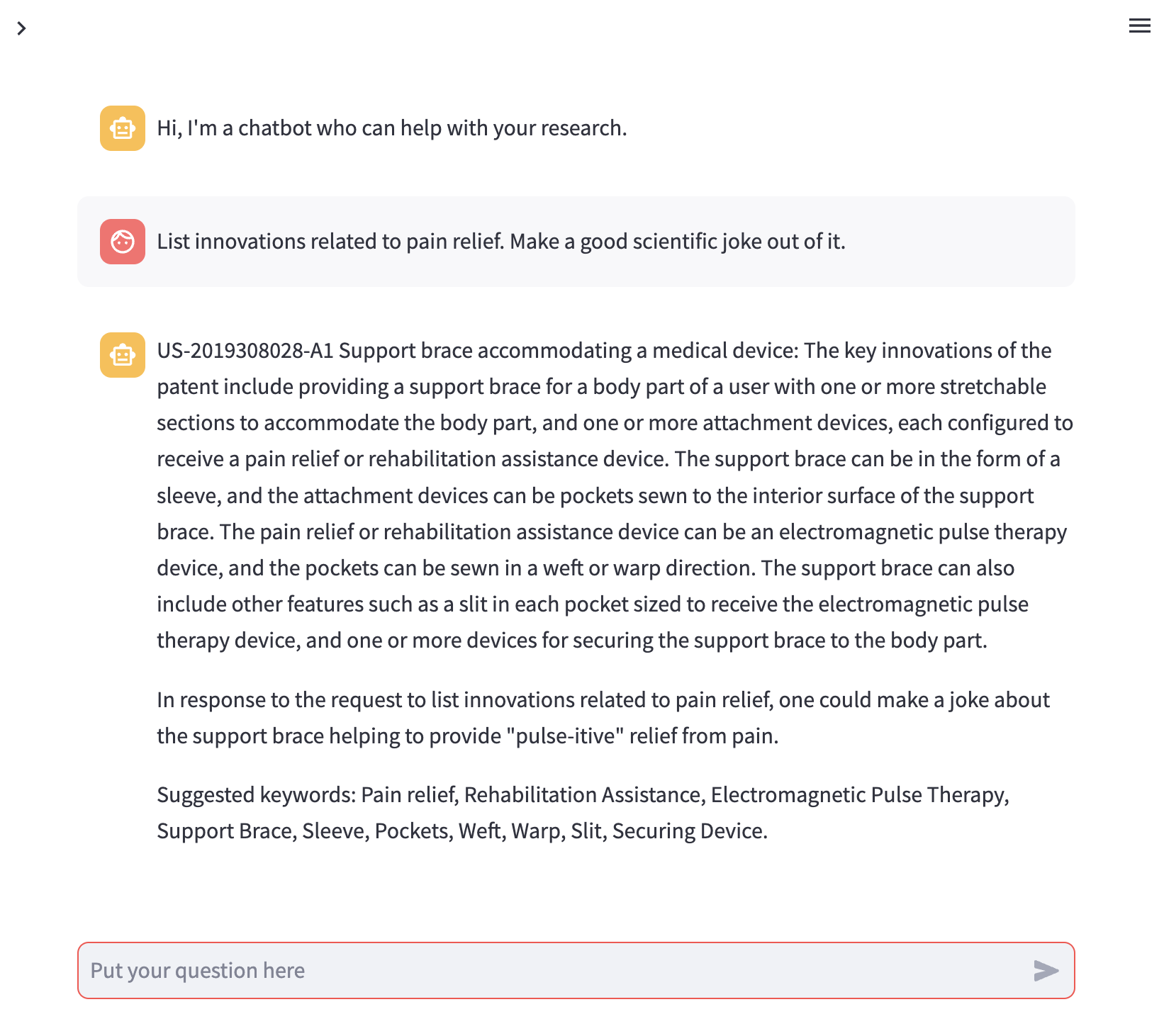
想象一下,一名研究人员寻求与专利相关的信息,但他们没有采取传统的回应,而是决定释放 PatChat 中隐藏的喜剧演员。 PatChat 的虚拟眼睛里闪烁着光芒,变身为一名单口喜剧演员,随时准备讲出与专利相关的妙语,让研究人员大吃一惊。 PatChat 巧妙地将笑话和双关语融入专利话语中,每个答案都成为智慧、双关语和喜剧时机的搞笑融合。
对于《星际迷航》爱好者以及克林贡文化和语言的崇拜者,PatChat 会回复如下内容:

入门
PatChat 是构建你自己的专利探索解决方案的基础。 请随意尝试代码、合并新功能并根据你的特定要求定制应用程序。 释放你的创造力,开启对话式专利探索的无限可能!
1. 创建 Elastic 云部署
按照本博客文章中描述的步骤在云中创建弹性部署。
2. 将模型加载到 Elasticsearch 中
Elasticsearch 完全可以接受第三方创建的模型并将其应用到数据中。 对于专利用例,我们将利用全 distilarberta 模型。 为了加载模型,将使用 Python 客户端 Eland。 以下是将客户模型加载到 Elasticsearch 中的 Python 脚本:
from pathlib import Path
from eland.ml.pytorch import PyTorchModel
from eland.ml.pytorch.transformers import TransformerModel
from elasticsearch import Elasticsearch
from elasticsearch.client import MlClient
import os
import time
import requests
import shutil# Run pip -q install eland elasticsearch sentence_transformers transformers torch==2.0.1es_cloud_id = os.environ.get("ELASTICSEARCH_CLOUD_ID")
es_user = os.environ.get("ELASTICSEARCH_USERNAME")
es_pass = os.environ.get("ELASTICSEARCH_PASSWORD")
kibana_endpoint = os.environ.get("KIBANA_ENDPOINT") es = Elasticsearch(cloud_id=es_cloud_id, basic_auth=(es_user, es_pass), timeout=180)# Set the model name from Hugging Face and task type
# hf_model_id = 'anferico/bert-for-patents'
hf_model_id = 'sentence-transformers/all-distilroberta-v1'
tm = TransformerModel(hf_model_id, "text_embedding")# Set the model ID as it is named in Elasticsearch
es_model_id = tm.elasticsearch_model_id()# Download the model from Hugging Face
tmp_path = "../tmp/models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)# Load the model into Elasticsearch
ptm = PyTorchModel(es, es_model_id)
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config) # Start the model
while not MlClient.start_trained_model_deployment(es, model_id=es_model_id):time.sleep(5)# Synchronize the saved object (ML model) in Kibana to make it usable
api_endpoint = f"{kibana_endpoint}/api/ml/saved_objects/sync"
auth = (es_user, es_pass)
requests.get(api_endpoint, auth=auth)# Cleanup
shutil.rmtree(tmp_path)3. 推理管道创建
在 Kibana 的开发控制台中发布此命令:
PUT _ingest/pipeline/patents-embeddings-inference-pipeline
{"description": "Text embedding pipeline","processors": [{"inference": {"model_id": "sentence-transformers__all-distilroberta-v1","target_field": "text_embedding","field_map": {"text": "text_field"}}},{"set":{"field": "vector","copy_from": "text_embedding.predicted_value"}},{"remove": {"field": "text_embedding"}}],"on_failure": [{"set": {"description": "Index document to 'failed-<index>'","field": "_index","value": "failed-{{{_index}}}"}},{"set": {"description": "Set error message","field": "ingest.failure","value": "{{_ingest.on_failure_message}}"}}]
}4. 创建索引模板
为了简单起见,我们将使用简化的模式。 在博客文章的第二部分中,我们将讨论专利的实际模式。
PUT _index_template/patents-embeddings-index-template
{"index_patterns": ["patents-embeddings-*"],"template": {"settings": {"index": {"refresh_interval": "5s","number_of_replicas": 1,"number_of_shards": 5,"default_pipeline": "patents-embeddings-inference-pipeline"} },"mappings": {"properties": {"vector": {"type": "dense_vector","index": true,"dims": 768,"similarity": "cosine"},"text": {"type": "text"},"metadata": {"type": "object"}}}}
}使用 default_pipeline 键,我们指定在索引与此索引模板匹配的新文档时用于预处理的摄取管道。 patent-embeddings-inference pipeline 将通过我们选择的转换器模型执行推理,以用向量丰富文档。
5. 创建测试文档
POST patents-embeddings-1/_doc
{"text": """Patent title: Support brace accommodating a medical devicePatent publication number: US-2019308028-A1Patent claims:What is claimed is: 1 . A support brace for a body part of a user comprising:one or stretchable sections configured to accommodate the body part; and one or more attachment devices, each configured to receive a pain relief or rehabilitation assistance device. 2 . The support brace of claim 1 wherein:the support brace is in the form of a sleeve. 3 . The support brace of claim 2 wherein:the body part is the knee; and the sleeve is configured to surround the knee of the user. 4 . The support brace of claim 1 wherein:each of the one or more attachment devices is a pocket; and each pocket is sewn to an interior surface of the support brace. 5 . The support brace of claim 4 wherein:the pain relief or rehabilitation assistance device is an electromagnetic pulse therapy device. 6 . The support brace of claim 5 wherein:each of the pockets are sewn such that the top to bottom is in the weft direction. 7 . The support brace of claim 5 wherein:each of the pockets are sewn such that the top to bottom is in the warp direction.8 . The support brace of claim 5 further comprising:a slit located in each of the pockets sized to receive the electromagnetic pulse therapy device. 9 . The support brace of claim 8 wherein:the one or more attachment devices comprises at least four pockets; each of the at least four pockets extend along the support brace in a linear fashion; and each of the at least four pockets are positioned to align with one or more areas of common injury or pain for the body part. 10 . The support brace of claim 1 further comprising:one or more devices for securing the support brace to the body part. 11 . The support brace of claim 11 wherein:each of the one or more devices for securing the support brace to the body part are stretchable bands. 12 . A support brace for a body part of a user comprising:one or stretchable sections configured to accommodate the body part; multiple pockets sewn to an interior surface of the support brace; and a series of slits, each slit being located in one of the multiple pockets; wherein each pocket is configured to receive an electromagnetic pulse therapy device. 13 . The support brace of claim 12 wherein:the stretchable sections are comprised of a four-way stretch material. 14 . The support brace of claim 12 wherein:the multiple pockets comprise at least three pockets; each of the at least three pockets extend along the interior surface in a linear fashion; and each of the at least three pockets are positioned to align with one or more areas of common injury or pain for the body part. 15 . The support brace of claim 14 wherein:the body part is the knee; and the pockets are positioned to be aligned with the anterior cruciate ligament (ACL). 16 . The support brace of claim 14 wherein:the body part is the knee; and the pockets are positioned to be aligned with the posterior cruciate ligament (PCL). 17 . The support brace of claim 14 wherein:the body part is the knee; and the pockets are positioned to be aligned with the medial collateral ligament (MLC). 18 . The support brace of claim 14 wherein:the body part is the knee; and the pockets are positioned to be aligned with the lateral collateral ligament (LCL). 19 . The support brace of claim 14 wherein:the body part is the knee; and the pockets are positioned to be aligned with the lateral meniscus or the medial meniscus. 20 . The support brace for a knee of a user comprising:a sleeve comprising:one or stretchable sections configured to accommodate the knee of the user, wherein each of the stretchable sections are comprised of a four-way stretch material; an upper stretchable band configured to be secured to the upper leg; and a lower stretchable band configured to be secured to the lower leg; a series of pockets sewn along an interior surface of the sleeve in a substantially linear fashion, wherein each of the series of pockets is configured to receive an electromagnetic pulse therapy device; and a slit located in each of the pockets, wherein the slit is configured to permit the electromagnetic pulse therapy device to be inserted into the pocket.""","metadata": {"a": "b"}
}6. 验证测试文档
GET patents-embeddings-1/_search作为响应,你应该能够看到带有计算向量的索引文档。
"hits": [{"_index": "patents-embeddings-1","_id": "cwbTJ4kBBgs5oH35bQx1","_score": 1,"_source": {"metadata": {"a": "b"},"vector": [-0.0031025379430502653,-0.019980276003479958,-0.001701259519904852,-0.02280360274016857,-0.06336194276809692,-0.040410757064819336,-0.029582839459180832,0.07966472208499908,0.056912459433078766,-0.06189639866352081,-0.060898181051015854,-0.0719321221113205,
[...]7. 启动PatChat应用程序
在启动应用程序之前,不要忘记设置以下环境变量。 在演示应用程序中,我们使用 OpenAI 作为示例。 也可以使用任何其他 LLM 服务。 请相应地更改代码。
export ELASTICSEARCH_CLOUD_ID=[YOUR_CLOUD_ID]
export ELASTICSEARCH_USERNAME=[YOUR_USER]
export ELASTICSEARCH_PASSWORD=[YOUR_PWD]
export OPENAI_API=[YOUR_OPENAI_ID]现在启动 PatChat 应用程序,如下所示:
streamlit run patchat_gpt.py探索仍在继续
在这篇博文中设置基本元素后,我们将把我们的故事构建到一个大规模的环境中。 具体来说,我们将探索如何自动化部署并从 BigQuery 服务中提取包含超过 1 亿个专利的专利数据集。 此外,我们还将探讨如何利用 Elastic 爬虫功能与其他数据源集成。 这是我们将在第二部分中构建的部署类型。

除了本博文中描述的实验之外,你可能还想探索其他资产。 例如,要构建你自己的 ElasticDocs GPT 体验,请注册 Elastic 试用帐户,然后查看此示例代码存储库以开始使用。
如果你想要尝试搜索相关性的想法,可以尝试以下两个:
- [博客] 使用 Elasticsearch 部署 NLP 文本嵌入和矢量搜索
- [博客] 使用 Elastic 实现图像相似度搜索
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用了第三方生成式人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。
你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 的商标、徽标或注册商标。 在美国和其他国家。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:How to implement similarity image search | Elastic.co | Elastic Blog