一、作业
1、问:下面解压程序出错,什么原因?
string src = @"E:\1.txt";string des = @"E:\2.txt";using (FileStream read = File.OpenRead(src)){using (GZipStream gzip = new GZipStream(read, CompressionMode.Decompress)){using (FileStream write = File.OpenWrite(des)){byte[] bytes = new byte[read.Length];//aint bytesRead=gzip.Read(bytes, 0, bytes.Length);write.Write(bytes, 0, bytesRead);//b}}}
假定原文件(2.txt)大小为100,而压缩后的1.txt为20。现在将1.txt解压还原成2.txt.
上面定义的缓冲为20,还原时的大小也成了20,那么b处写入也是20,不会是100,解压
后的文件肯定不对,不应该是20而是100.
2、问:压缩流可以压缩多个文件吗?
答:Gzip压缩算法主要适用于单个文件的压缩。它使用GZipStream类来实现压缩和解压
缩操作,但只能处理单个文件流。如果你想要同时压缩多个文件,你需要分别对每个文
件进行压缩,然后将它们合并到一个压缩文件中。
private static void Main(string[] args){string scr1 = @"E:\1.txt", scr2 = @"E:\2.txt";CompressFile(@"E:\3.txt", scr1, scr2);Console.ReadKey();}public static void CompressFile(string outpath, params string[] scrpath){using (FileStream fsw = File.Create(outpath)){using (GZipStream Ugzip = new GZipStream(fsw, CompressionMode.Compress)){foreach (string scr in scrpath){using (FileStream fsr = File.OpenRead(scr)){byte[] buffer = new byte[1024 * 8];int bytesRead;while ((bytesRead = fsr.Read(buffer, 0, buffer.Length)) > 0){Ugzip.Write(buffer, 0, bytesRead);}}}}}}
但是,悲哀的,这个可以解压,但不支持解压成各自单独的文件。除非人为在buffer添
加分隔符,解压时再分隔区别。
要做到多个文件的压缩与解压,可以用ZipFile类和ZipArchive类
均来自using System.IO.Compression;
下面直接使用Zip类将一个目录进行压缩和解压。
string scrFolder = @"E:\1";string zipFile = @"E:\z.zip";string desFolder = @"E:\2";ZipFile.CreateFromDirectory(scrFolder, zipFile);//目录压缩ZipFile.ExtractToDirectory(zipFile, desFolder);//释放到目录 下面使用ZipFile与ZipArchive压缩多个文件并解压string[] files = { @"E:\1\1.txt", @"E:\1\2.txt" };string outFile = @"E:\zz.zip";using (ZipArchive za = ZipFile.Open(outFile, ZipArchiveMode.Create))//a{foreach (string file in files){za.CreateEntryFromFile(file, Path.GetFileName(file));//b}}ZipFile.ExtractToDirectory(outFile, @"E:\3");//解压
上面使用ZipFile.Open方法创建一个新的ZIP文件,并指定ZipArchiveMode.Create模式
以创建新的 ZIP 文件。(主要是返回一个压缩流)
通过 foreach 循环遍历源文件路径数组,并使用 archive.CreateEntryFromFile 方法
将每个文件添加到 ZIP 文件中,并使用原始文件名作为 ZIP 文件中的条目名。
b处第一参数是要参与压缩的文件,第二参数是压缩后显示的文件名称(条目名)。
提示:ZipFile只能压缩目录,不能直接压缩多个文件。
直接压缩多个文件,只能用ZipArchive。
3、初始化器
初始化器(Initializer)是一种用于初始化对象或集合的简便语法。通过使用初始化器,
可以在创建对象或集合的同时为其属性或元素赋值,提供了一种便捷的方式来初始化数据。
(1)对象初始化情况
internal class Program{private static void Main(string[] args){Person p1 = new Person();//1p1.Name = "First";p1.Age = 20;Person p2 = new Person("Second", 21);//2Person p3 = new Person() { Name = "Thirst", Age = 22 };//3Console.ReadKey();}}internal class Person{public string Name { get; set; }public int Age { get; set; }public Person(){}public Person(string name, int age){this.Name = name;this.Age = age;}}
上面第一方式:

实际上就是先构造对象,再用set赋值各属性。
上面第二方式:
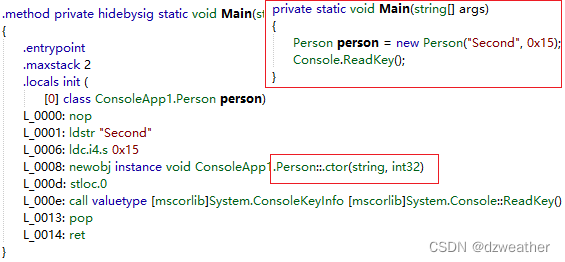
这个直接是使用的是构造函数。
上面第三种方式:
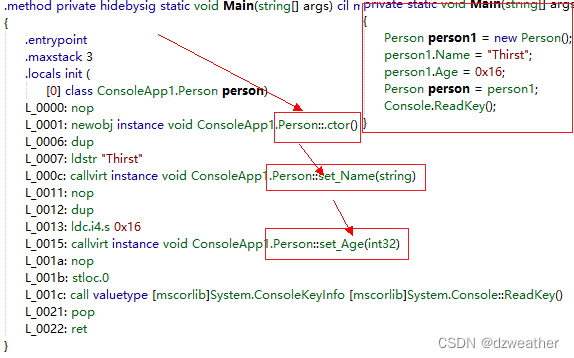
注意,它先构造了一个对象,命名随机,然后才将此对象赋值给p3.
3处的括号可以省略Person p3 = new Person{ Name = "Thirst", Age = 22 }
对于使用初始化器进行对象初始化,当使用默认的无参数构造函数创建对象时,可以省略().
省略()是为了使代码更加简洁和易读。如果你想要明确指定使用哪个构造函数进行初始化,
或者提供参数进行初始化,那么不应该省略 ()。
总结:初始化器,是创建一个对象,对象名随机,赋值后,再提供给原对象名。
(2)集合初始化器:
List<int> list1 = new List<int>();//1list1.Add(1); list1.Add(2); list1.Add(3);List<int> list2 = new List<int>() { 1, 2, 3 };//2List<int> list3 = new List<int>(3) { 1, 2, 3 };//3
上面的1和前面的1相似,都是构造一个集合后,加入三个值。
后面的2和3一样,构造一集合后,命名随机,再加入三个值,再赋值给原集合名。
注意:(1)初始器的值都是在{}中;
(2)初始化器在对象创建时立即执行,而构造函数在对象创建后的初始化阶段执行。
换句话说,初始化器是在对象创建过程中为属性赋值的一部分,而构造函数是对象
的初始化逻辑的一部分,可以包含更复杂的初始化操作。
简单地说:初始化器在构造函数之后
internal class Program{private static void Main(string[] args){Person p = new Person(19) { Age = 21 };Console.WriteLine(p.Age);//21Console.ReadKey();}}internal class Person{public int Age { get; set; }public Person(int age){this.Age = age;}}
上面结果是21,因为最后是初始化器执行,它覆盖了前面的构造函数的值。
另外,也可以直接写{},因为对象后面必须有(),{},[]之一。
Person p1 = new Person();Person p2 = new Person() { };Person p3 = new Person { };Person p4 = new Person;//错,必须有(),{},[]之一
4、什么是匿名类?
匿名类是一种临时创建的类,用于在声明时定义其属性并初始化这些属性的值。匿名类的定
义方式是通过使用关键字new和var并使用对象初始化器来创建。
匿名类通常用于临时存储一组属性,而不需要定义专门的自定义类。它是一种方便的方式来
创建临时的、只用于特定目的的数据结构。
var person = new{Name = "John",Age = 30,IsStudent = true};Console.WriteLine($"Name: {person.Name}, Age: {person.Age}, IsStudent: {person.IsStudent}");
上面创建了一个匿名类person,有Name、Age和IsStudent三个属性,并为它们分别赋予
了"John"、30和true作为初始值。输出时访问其属性。
注意:匿名类是只读的,无法对其属性进行修改。匿名类的属性和初始值在创建时确定,
之后无法更改。此外,匿名类的类型名由编译器自动分配,可以通过var关键字
隐式类型推断来声明匿名类的实例。
匿名类主要用什么什么场景?
匿名类在以下场景中非常有用:
(1). 数据传递:
匿名类可以用于在方法之间传递临时的数据结构。当你需要传递一组相关属性的数
据,但又不想为这些属性创建专门的类时,匿名类可以提供一种简洁的解决方案。
var pp = new { Name = "匿名", Age = 19 };ShowPerson(pp);private static void ShowPerson(object p){Console.WriteLine($"{((dynamic)p).Name},{((dynamic)p).Age}");}
注意:
(a).号的运算优先级高于(),所以(dynamic)p.Name是先运算.后(),也就是先p.Name
然后才是(dynamic)(p.Name)。因此这里要把p的转换后才取属性。
(b)dynamic是C#中的一个类型,它表示一种动态类型。与其他类型(如int、string等)
不同,dynamic类型的变量在编译时不进行静态类型检查,而在运行时进行类型检查
和解析。
因此使用dynamic关键字,可以在编译时不指定变量的具体类型,而是延迟类型的
确定,直到运行时才确定其类型。
上面使用了dynamic。因为匿名类的类型是在编译时未知的,需要使用dynamic来进
行运行时类型推断和访问。
例如,((dynamic)person).Name 表示我们在运行时以动态方式访问person对象的
Name 属性。由于编译器无法在编译时确定person的具体类型,因此使用dynamic
进行类型推断,使得编译器知道在运行时调用适当的属性。
注意:使用dynamic会带来一些性能上的开销,因为类型检查是在运行时进行的。
此外,由于缺乏编译时的类型检查,使用dynamic也增加了代码的不确定
性和潜在的运行时错误的风险。因此,在使用dynamic时需要谨慎,确保
在运行时操作正确的类型,并在必要时进行适当的类型转换和异常处理。
(2). LINQ查询:
在LINQ查询中,匿名类可以用于创建临时的投影查询结果。通过匿名类,你可以定
义仅包含你需要的属性的结果集,而不需要创建一个新的自定义类。
var students = new[]{new { Name = "John", Age = 20, Grade = "A" },new { Name = "Sarah", Age = 22, Grade = "B" },new { Name = "Emily", Age = 19, Grade = "A" }};var query = from student in studentswhere student.Age > 20select new { student.Name, student.Grade };foreach (var result in query){Console.WriteLine($"Name: {result.Name}, Grade: {result.Grade}");}
通过LINQ查询创建了一个包含部分属性的匿名类结果集,该结果集表示年龄大于20的学生的姓名和成绩。
注意:匿名类是临时的,其生命周期只存在于创建它的方法或语句块内部。在方法调用或
语句块结束后,匿名类的实例将被销毁。因此,匿名类适用于临时性的数据存
储和传递。
5、GZipStream压缩与解压过程。
这个代码不必死记,记住过程:
相同的:都得用FileStream打开读取流和写入流;
不同的:
压缩时,读取正常流fsr,然后写入正常流fsw,但在写入时得变换下,即压缩流gz写
入到磁盘。
解压时,读取正常流fsr,但这个流是被压缩的,因此这个需要解压出来gz,然后再按
正常流fsw进行写入。
//压缩
using (FileStream fsr = File.OpenRead(@"E:\2.jpg"))//1{using (FileStream fsw = File.OpenWrite(@"E:\2.rar"))//2{using (GZipStream gz = new GZipStream(fsw, CompressionMode.Compress))//3{byte[] buffer = new byte[1024 * 8];int bytesRead;while ((bytesRead = fsr.Read(buffer, 0, buffer.Length)) > 0)//4{gz.Write(buffer, 0, bytesRead);//5}}}}//解压using (FileStream fsr = File.OpenRead(@"E:\2.rar"))//6{using (FileStream fsw = File.OpenWrite(@"E:\3.jpg"))//7{using (GZipStream gz = new GZipStream(fsr, CompressionMode.Decompress))//8{byte[] buffer = new byte[1024 * 8];int bytesRead;while ((bytesRead = gz.Read(buffer, 0, buffer.Length)) > 0)//9{fsw.Write(buffer, 0, bytesRead);//10}}}}
上面压缩时,1打开源文件,2指定目标文件,最终需要利用2压缩即3处,在4处读取
是源文件fsr,最终是要压缩写入文件,所以5用gz写入。
下面解压时,同样6打开源文件,7指定解压的文件。由于filestream是正常流,若是
压缩流,需要解压释放出来成为正常的流,因此8处的解压应该是从源文件即6处的fsr
读取而来,这样源文件经解压后,就是正常的流了。因此9处用gz解压后的流进行读取,
后面都是正常流了,直接用直接写入流fsw进行写入即可。
上面区别的是:压缩在写入流后,用压缩流进行写入。
解压在读取流,最后正常流写入。
二、元字符
1、正则表达式前奏: 地狱
有时提取或替换字符串的某些有规律的字符或字符串,会感觉复杂或难以下手:
需求1:
"192.168.10.5[port=8080]"这个字符串表示IP地址为192.168.10.5的服务器的8080端口
是打开的,请用程序解析此字符串,然后打印出"IP地址为***的服务器的***端口是打开
的"。
需求2:
"192.168.10.5[port=21,type=ftp]",这个字符串表示IP地址为192.168.10.5的服务器
的21端口提供的是ftp服务,其中如果",type=ftp"部分被省略,则默认为http服务。请
用程序解析此字符串,然后打印出“IP地址为***的服务器的**端口提供的服务为***”
需求3:
判断一个字符串是否是Email? 必须含有@和.、不能以@或者.开始或者结束、@要在最后
一个.之前
需求4:
从一个文本中提取出所有的Email: 我有全部333M的照片,要的给我发email:me@wo.com。
我也要you@you.com,123456@163.com,楼主好人: 888888@qq.cn.
2、正则表达式入门: 天堂
正则表达式是用来进行文本处理的技术,是语言无关的,在几乎所有语言中都有实现。
javascript中还会用到。[正则表达式是对文本、对字符串操作的。]
一个正则表达式就是由普通字符以及特殊字符(称为元字符)组成的文字模式。该模式描
述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字
符模式与所搜索的字符串进行匹配。正则表达式用来描述字符串的特征。
就像通配符“*.jpg”、“%ab%”,它是对字符串进行匹配的特殊字符串
正则表达式是非常复杂的,不要希望一次都掌握,理解正则表达式能做什么 (字符串的
匹配、字符串的提取、字符串的替换),掌握常用的正则表达式用法,以后用到再查就行。
找工作的亮点。后面项目中的采集器、敏感词过滤、URLRewiteValidator也会涉及到正
则表达式
正则表达式是对字符串操作的。
3、元字符1
要想学会正则表达式,理解元字符是一个必须攻克的难关。不用刻意记.
问:什么是元字符?
答:元字符是具有特殊含义的字符。它们不仅仅匹配字面值,而是用于表示某种模式或
字符类型。这些元字符可以组合使用或与其他字符一起使用,构成复杂的匹配模式。
例如,\d+表示匹配一个或多个数字字符。使用元字符可以更灵活和准确地进行模式
匹配。
.:匹配除\n之外的任何单个字符。
例如:正则表达式"b.g"能匹配如下字符串:
"big"、"bug"、"b g",但是不匹配"buug","b..g"可以"buug”。
[]:字符组,匹配括号中的任何一个字符(范围,字符集合)。
例如:正则表达式"b[aui]g”匹配bug、big和bag,但是不匹配beg、baug。
可以在括号中使用连字符-”来指定字符的区间来简化表示,
例如正则表达式[0-9]可以匹配任何数字字符,这样正则表达式"a[0-9]c"等价
于a[0123456789]c"就可以匹配"a0c”、“a1c”、a2c"等字符串;
还可以制定多个区间,例如[A-Za-z]"可以匹配任何大小写字母,“[A-Za-z0-9]”可
以匹配任何的大小写字母或者数字。
思考:x[这里必须是元音]y,如何写正则?
当.出现在[]中,则表示普通字符,而不作为元字符。
-出现在[]中的非第一个字符时,认为是元字符 ,表示范围。
a[-a-z]b第一个-是字符不是元字符,后面第二个-是元字符不是字符。
|元字符在[]中也只表示一个普通的竖线,()在[]也表示普通的括号,类似的还有+,*,?等。
提示:因为在[]里面用转义\或不用,都是可以的,若不明白,就傻瓜式地加上转义。
例如: a[.x]b这里的.是普通字符,若不明白加上转义a[\.x]b表示一样的意思。
注意:在[]外的元字符要表示普通字符,需要转义。
例如:a\.b这里的.黑底后表示匹配a.b字符串。
问:[a-zA-Z]与[A-Za-z]谁正确?谁更节约资源?
答:两者均正确。两者消耗资源相差微小。
[]里并不按照ASC顺序进行比对,而是按[]里的先后顺序进行比对。例如,对
于字符类[aAbB],它会匹配小写字母’a’、大写字母’A’、小写字母’b’和大写
字母’B’中的任意一个字符,顺序并不影响匹配的结果。
至于哪个表达式更节约资源,实际上差异非常微小,可以忽略不计。在实际
使用中,这两个表达式的性能基本相同,无论选择哪个都不会对性能产生显
著影响。
问:[A-z]表示[A-Za-z]吗?
答:[A-z]与[A-Za-z]不是完全等价的。
[A-z]表示从大写字母’A’到小写字母’z’之间的字符范围。这包括大写字母、
小写字母以及一些其他特殊字符,如方括号与反斜杠。因此,使用[A-z]可
能匹配到你不期望的字符。
如果希望只匹配字母,应该使用[A-Za-z]而不是[A-z]。
问:[b-d]与[d-b]一样吗?
答:不一样.
[b-d]表示’b’、‘c’和’d’。而[d-b]则是一个无效的字符范围,因为它是一个逆
序的范围。
在字符范围中,起始字符应该在结束字符之前。因此,[d-b]没有有效的匹配。
无效字符范围,将无法匹配,或者正则表达式引擎报错。
|:将两个匹配条件进行逻辑"或"运算。
z|food能匹配z或food。(z|f)ood则配zood或food。
a(x|y)b只能匹配axb或ayb。
问:正则表达式的优先级是怎样的?
答:在C#常见的正则表达式运算符和它们的优先级从高到低的顺序:
1. `\`:转义符号。它用于转义特殊字符,使其失去其特殊含义。
例如,`\.`, `\\`。
2. `[]`:字符类。它用于匹配一个字符范围内的任意字符。
例如,`[a-z]`, `[0-9]`。
3. `()`:括号。它用于分组操作,控制运算符的作用范围并提供子表达式。
例如,`(ab)+`, `(abc|def)`。
4. `*`、`+`、`?`、`{n}`、`{n,m}`:重复匹配。它们用于规定前面的表达式可
以重复出现的次数。
例如,`a*`, `b+`, `c?`, `d{3}`, `e{1,3}`。
5. `^`、`$`:锚点。它们用于匹配字符串的开头和结尾位置。
例如,`^abc`, `xyz$`。
6. `|`:或。它用于设置多个表达式的选项,匹配其中之一。
例如,`a|b|c`。
7. `.`:通配符。它用于匹配除换行符外的任意一个字符。
例如,`a.b`。
8. `\b`、`\B`:单词边界。用于匹配单词的边界位置。
例如,`\bword\b`。
注意:括号可以改变运算符的优先级。在括号中的表达式最先被计算。
例如,`(ab)+`表示`ab`可以重复出现一次或多次。
():将()之间括起来的表达式定义为"组”(group),并且将匹配这个表达式的字符保存到一
个临时区域,这个元字符在字符串提取的时候非常有用。把一些字符表示为一个整体。
改变优先级、定义提取组两个作用。
4、元字符2(限定符)
总结: *{0,},+{1,},?{0,1}
*:匹配0至多个在它之前的子表达式,和通配符*没关系。等价于{0,}。
例如正则表达式"zo*”(等同于z(o))能匹配"z"、"zo"以及“oo”;
因此".*"意味着能配任意字符串。
"z(b|c)*"表示zb、zbc、zcb、zccc、zbbbccc。
"z(ab)*"能匹配z、zab、zabab(用括号改变优先级)
+:匹配前面的子表达式一次或多次,和*对比《0到多次)。等价于(1,}
例如正则表达式9+匹配9、99、999等。
“zo+"能队配zo"以及“zoo”,不能配"z"。
?:匹配前面的子表达式零次或一次。等价于: {0,1}
例如,"do(es)?”可以配"do"或"does"。
[colou?r、favou?r]一般用来配可选部分”。(终贪婪模式)
限定符:限定前面的正则表达式出现的次数。
{n} :匹配确定的 n 次。"zo{2)"表示zoo。
例如,"e{2}”不能配bed中的e,但是能配seed中的两个ee。 //seeeed,不可以。
问:[0-9]{3}表示任意的三个数字,若表示三个相同的数字呢?
答:^(\d)\1{2}$
^ 表示匹配字符串的开头位置。
(\d) 表示一个数字字符的捕获组。
\1 是一个反向引用,引用第一个捕获组中匹配的内容。
{2} 表示前一个表达式(即捕获组中的数字字符)匹配连续出现两次。
$ 表示匹配字符串的结尾位置。
可以匹配 “111”、“222”、“333” 等连续三个重复的数字字符,但无法匹配
“123”、“456” 等不连续或不重复的数字字符。
{n,} :至少匹配n次。例如,e{2,}不能匹配bed中的e,但能匹配seeeeeeeed中的所有e。
{n,m} :最少配 n 次最多配 m 次。e{1,3}将配seeeeeeeed中的前三个e。
{2,5}//bed,seed,seeed; beeeeed。
5、元字符3
^(shift+6) : 匹配一行的开始。
例如正则表达式“regex”能够匹配字符串“regex我会用”的开始,但是不能匹
配“我会用regex”。
^另外一种意思: 非! (^0-9)
a[^zxy]b匹配aab,但不匹配azx,ab
注意:[]匹配时必须要有一个字符出现,哪怕是用非^时,所以上面ab不匹配。
$:匹配行结束符。
例如正则表达式“浮云$”能够匹配字符串“一切都是浮云”的末尾,但是不能匹配字
符串“浮云呀”
^abc,匹配一个正则表达式的开始,这样来理解: 一字母a开头,后紧跟一个b,然后又紧
跟一个c
abcjflkdsjfkds
888$,匹配一个正则表达式的结束。
积分多少快乐解放路口的手机费888
问:正则中^是一行的开始,还是一句的开始?
答:^是匹配一行的开始位置,而不是一句的开始。
^用于匹配字符串的开头位置。如果正则表达式以^开头,它会尝试匹配输入字符串的
起始位置,而不是每行的起始位置。
假设我们有一个多行的输入字符串,每行都以数字开头,我们可以使用^\d来匹配每
行开头的数字。这里的^表示匹配每行的开头位置。
注意:默认情况下,C#正则表达式的匹配是在整个输入字符串上进行的,而不是逐行
匹配。如果你想要逐行匹配,可以使用RegexOptions.Multiline选项,这样^将
匹配每行的开头位置。
同理:$表示一行结束而不是一句结束。
问:RegexOptions.Multiline有什么作用?
答:RegexOptions.Multiline是一个标志,用于指定在匹配时是否将输入字符串视为多行。
使用RegexOptions.Multiline选项时,注意:
1. `^`和`$`的匹配行为:
默认情况下,`^`匹配字符串的开头,`$`匹配字符串的结尾。但是,使用RegexOpti
ons.Multiline`选项后,它们会匹配每行的开头和结尾(以换行符为界)。
2. `\A`和`\Z`的匹配行为:
`\A`匹配字符串的开头,`\Z`匹配字符串的结尾。如果使用`RegexOptions.Multil
ine`选项,它们将仍然匹配整个字符串的开头和结尾。
3. `.`匹配任意字符时是否包括换行符:
默认情况下,`.`匹配除换行符外的任意字符。然而,如果使用`RegexOptions.Mult
iline`选项,`.`将匹配包括换行符在内的任何字符。
4. `\b`和`\B`的匹配行为:
在默认情况下,`\b`匹配单词边界,`\B`匹配非单词边界。但是,如果使用`RegexO
ptions.Multiline`选项,`\b`和`\B`的行为不会受到影响。
通过使用`RegexOptions.Multiline`选项,你可以在匹配时将输入字符串视为多行
文本,以便更灵活地处理行级别的匹配需求。
6、简写表达式
注意这些表达式是不考虑转义符的。
正则表达式中的\表示是正则里生效的字符\,而不是C#字符串级别的\。因此正则表达式中
如果含有\字符,在C#代码中会被误认为是C#中的转义符。
因此,需要使用@或者\双重转义。先让C#识别有\字符,然后在正则表达式中\生效。
例如:正则表达式a\db表示ab之间有一数字,若用在C#代码中,会把\当作转义符,但C#
中没有\d的定义,就会报错。因此需要再保留\,可以在C#中用a\\db,或者用@"a\db"。
在C#看来@"\-"就是\-这个普通的字符串,只不过在正则表达式分析引擎看来他有了特殊
含义。
思路就是:先正则,后C#
例1:比如对于\d匹配数字,先正则就是\d,再C#中\需要转义,因此C#完整应该为\\d
例2:比如对于\d两个是普通字符时,不能当作\d来匹配数字:
先正则:\d中\要转义故写成\\d
后C#:对于上面的\\d,C#对\要转义,因此每一个都要转一次,最终:\\\\d
技巧:为了减少麻烦,对于第一步正则,可以按正常的写。
但对第二步“后C#”,可以直接用@来减少再次转义。
因此上面例1:\d先正则就是原样\d,第二步再C#,就直接用@"\d"
上面例2:\d普通字符,先正则就是\\d,再第二步C#:@"\\d"
这样就简单多了。因为@就是不需要转义。
\d:代表一个数字,等同[0-9]。\\d是\d
\D:代表非数字,等同[^0-9]
\s:代表换行符、Tab制表符等空白字符(空格、回车、制表符)
\S:代表非空白字符(a0%s@@)
\w:匹配字符或数字或下划线或汉字,即能组成单词的字符。如果通过ECMAScript
选项指定了符合ECMASctipt的行为,则\w等效于[a-zA-Z_0-9]
\W:非\w,等同于[^\w]%
\b: 单词的边界。一边是单词 (\w) ,一边不是单词(\W))。
Hello nihao,are you kidding? D-Day
d:digital; s: space、w: word。大写就是“非”
C#中当在字符串前使用@符号时,字符串中可以用两个双引号表示一个双引号。
例如:Console.WriteLine(@"aaaa""fdsafdsaf");
问:如何匹配任意的单个字符?[\s\S]
答:能用.吗?不能,因为.不包含\n
可以用[\s\S],[\w\W],[\d\D]
问:空白字符有哪些?
答:\s是一个特殊的字符转义序列,用于匹配空白字符(whitespace characters)。
空白字符包括下列字符:
空格(ASCII码为32)
制表符(ASCII码为9)
换行符(ASCII码为10)
回车符(ASCII码为13)
垂直制表符(ASCII码为11)
换页符(ASCII码为12)
问:如果对字符串的"\"进行匹配,正则表达式应该怎么写?
答:步骤:先正则后,再考虑C#转义写法。
1.正则:\需要转义,故应写成"\\"
2.C#:因为C#把\当作转义符,需要两次\\才是真正的\,因此上面有两个\\
第一个\写成\\,第二个\\还得写成\\,组合起来为\\\\
结果为:"\\\\"
如果用@替换,则写成@"\\",它分别消除每个转义,故@"\\\"是错误的。
三、Net中的正则表达式
1、正则表达式在.Net就是用字符串表示这个字符串格式比较特殊,无论具体什么含义由Regex
类多么特殊,在C#语言看来都是普通的字符串,具体什么含义由Regex类内部进行语法分
析。
如何匹配大于10小于20的字符串? (正则表达式是对字符串的操作。)
^[1][1-9]$,[11,12,13,14,15,16,17,18,19]观察字符串!自己写正则表达式之前先仔细
观察字符串,找规律。写正则表达式前,首先要做的就是找规律,根据规律写出相应的正
则表达式。
2、正则表达式 (Regular Expression)的主要类: Regex
常用的3种情况: (C#语法)
(1)判断是否匹配: Regex.IsMatch("字符串","正则表达式")
(2)字符串提取: Regex.Match("字符串","要提取的字符串的正则表达式");
//只能提取一个(提取一次)
字符串提取(循环提取所有): Regex.Matches(),(可以提取所有匹配的字符串。)
(3)字符串替换所有: Regex.Replace("字符串","正则","替换内容");
3、判断是否匹配: Regex.IsMatch("字符串","正则表达式")
Console.WriteLine(Regex.IsMatch("123456", "[0-9]{6}"));Console.WriteLine(Regex.IsMatch("12345678", "[0-9]{6}"));Console.WriteLine(Regex.IsMatch("12345678", "^[0-9]{6}$"));Console.WriteLine(Regex.IsMatch("bg", "^b.*g$"));//true *0或多个
注意:要完全匹配,需要加^与$
问:Regex.IsMatch("123456", "[0-9]${6}") 结果是多少?
答:True
实际上Regex.IsMatch("123456", "[0-9]${1}")结果也为true.
在C#正则表达式中,${6}是无效的表达式,它并不会被解释为后向引用或者重复次
数。所以在表达式a${6}中,${6}只会当作$,{6}被忽略掉了。
因此整个表达式变成了[0-9]$,因此匹配的是末尾6,显示为true.
问:Regex.IsMatch("123456", "([0-9]$){6}")结果是多少?
答:false
此时([0-9]$){6}是正常表达式,没有匹配成功。看下面结果:
string text = "12\n34\r\n5\n6";string pattern = @"[0-9]${2}";MatchCollection matches = Regex.Matches(text, pattern, RegexOptions.Multiline);foreach (Match match in matches){Console.WriteLine(match.Value);}
结果为2,5,6。因为多行模式下,2,5,6成功匹配。
提示:$与\Z的区别:
$:一般是字符串结尾判断,若多行模式进,还会对每行末尾判断,但以\n为标准而不
是以\r\n为标准,所以上面结果4并没有匹配成功。如果想以\r\n或\n来判断是否结
尾,用\r?$
特别提醒:^要么是开始,要么以行\r\n进行判断在开头。它不会认\n。
感觉这两口子的口味就是不一样。
\Z:只以字符串结尾为判断,无论是否有多行。
问:z|food 等效于 (z)|(food)还是(z|f)ood?
答:(z)|(food)
如果正则表达式中使用 | 而没有加括号,它会将两侧内容作为一个整体进行处理。
所以z,food,zood,都可以匹配上面(zood中有z)
注意:虽然二者等效,但捕获组会对匹配结果进行分组存储,相比于不使用捕获组的
情况,它可能会更费资源。相比引起误会情况,建议还是用()表明顺序。
|还可以多级套用,但只会选择其中之一进行匹配。
例如a|bc|cd|efg,对于a,bc,cd,efg都是可以匹配的,但一次只能选择之一。但是,
它都是从左向右依次匹配,谁先成功就马上返回,并且不会尝试继续匹配后续的子
模式。
匹配时注意优先级,例如z|food$,因为$优先级高于|,因此等效于(z)|(food$)。
问:判断是否为身份证号码?规律如下:
1.长度15或18,首位为不0;
2.如果15位,全为数字;
3.如果18位,前17为数字,末尾可能字母X
答:^[1-9]\d{14}(\d{2}[0-9X])?$
练习:判断字符串是否为正确的国内电话号码,不考虑分机。
010-8888888或010-88888880或010xxxxxxx
0335-8888888或0335-88888888(区号-电话号)03358888888
10086、10010、95595、95599、95588 (5位)
13888888888(11位都是数字)
^((\d{3,4}-?\d{7,8})|(\d{5})|(l\d{10})$
或者^((\d{3,4}\-?\d{7,8})|(\d{5}))$
注意:上面-可以不用转义
问:正则中需要单独转义的字符有哪些?
答:在 C# 的正则表达式中,以下符号需要进行转义:
1. 句点(.):
在正则表达式中,句点(.)表示匹配任意单个字符,为了匹配句点本身,需要
使用反斜杠进行转义,即 `\.`。
2. 反斜杠(\):
反斜杠在正则表达式中起到转义字符的作用,因此,在匹配字面意义的反斜杠
时,需要进行双重转义,即 `\\`。
3. 方括号([]):
方括号用于定义字符类,如果要匹配字面意义的方括号,需要进行转义,
即 `\[` 和 `\]`。
4. 连接符(-):
连接符用于定义字符范围,在某些情况下可能需要进行转义,比如要匹配字面意
义的连字符,可以使用 `\-` 或者将其放在字符类的开头或结尾避免被解释为范
围定义。
5. 问号(?):
问号用于表示前面的元素是可选的,如果要匹配字面意义的问号,需要进行转
义,即 `\?`。
6. 星号(*):
星号用于表示前面的元素可以出现零次或多次,如果要匹配字面意义的星号,
需要进行转义,即 `\*`。
7. 加号(+):
加号用于表示前面的元素可以出现一次或多次,如果要匹配字面意义的加号,
需要进行转义,即 `\+`。
8. 左大括号({):
左大括号用于表示重复次数,如果要匹配字面意义的左大括号,可以直接使
用 `{` 或者进行转义,即 `\{`。
9. 竖线(|):
竖线用于表示模式选择,如果要匹配字面意义的竖线,可以直接使用 `|`或者
进行转义,即 `\|`。
10. 括号(()):
括号用于分组和捕获,如果要匹配字面意义的括号,需要进行转义,即
`\(` 和 `\)。
练习:判断一个字符串是否是合法的Email地址。一个Email地址的特征就是以一个字符序
列开始,后面跟着@符号,后面又是一个字符序列,后面跟着符号.,最后是字符序列。
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$
问:.net默认使用的是Unicode的匹配模式?
答:是的。
例如:\d可以匹配半角或全角的数字例如123456
注意:[0-9]只能匹配半角的数字
Regex.IsMatch("12378","^\d+$"):trueRegex.IsMatch("12378","^[0-9]+$"):false
若不想匹配Unicode,请设置RegexOptions.ECMAscript,如:
Regex.IsMatch(("12378","^\d+$",RegexOptions.ECMAscript):false
同理,\w也是用的Unicode,所以包括汉字.
Regex.IsMatch(("123强国","^\w+$",RegexOptions.ECMAscript):falseRegex.IsMatch(("123强国","^\w+$"):true
同理,\s也能匹配全角的空格。
问:\d或\w等半角时是用RegexOptions.ASCII还是RegexOptions.ECMAScript?
答:用 RegexOptions.ECMAScript。
虽然 RegexOptions.ASCII 可以限制匹配范围为 ASCII 字符,但它同时会限制了其
他 Unicode 字符的匹配能力。这可能不符合你只想匹配半角模式的需求,因为半角
字符可能包含在 Unicode 字符集中,并非全部被包括在 ASCII 字符集内。
简言之:半角包括ASCII。因此RegexOptions.ECMAScript 选项更适合半角的需求。
它可以模拟 ECMAScript(JavaScript)的正则表达式引擎,其中的 \d 和 \w 是按
照半角模式进行匹配的。
练习:
1、匹配IP地址,4段用.分割的最多三位数字。
192.168.54.77、333.333.333.333假设都是正确的。
1.2.222.3、192.168.0.156
[1-9][0-9]{0,2}([.][0-9]{1,3}){3}
2、判断是否是合法的日期格式“2008-08-08”。四位数字-两位数字-两位数字。
[0-9]{1,4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])
3、判断是否是合法的url地址,
http://www.test.com/a.htm?id=3&name=aaa、
ftp://127.0.0.1/1.txt。字符串序列:
//字符串序列。http,https,ftp,file,thunder,ed2k
(http|https|ftp|file|thunder|ed2k)://([\w\-]+\.)+[\w\-]+(/[\w\-./?%&=]*)?
注意:\w:只匹配字符[a-zA-Z]或数字[0-9]或下划线[_]或汉字,即能组成单词的
字符注意它还支持全角的情况。
因此,对于-,?,&,%,=,.,/等符号,需要单独列出。
问:上面第三题[\w]是表示\w,还是表示:一个"\"和一个"w"?
答:在正则表达式的字符类(方括号[])中,特殊字符(例如 \w、\d)仍然保持其特殊
含义,而不是被解释为字面字符。所以,在 [\w] 中,\w 仍然表示匹配任意字母、数字
或下划线字符。
同样地,在 [\d] 中,\d仍然表示匹配任意数字字符。而不能拆分为\与d
四、字符串的提取与提取组
1、热身:提取字符串中的所有数字。
“大家好呀,hello,2010年10月10日是个好日子。恩,9494.吼吼!886.”
使用\d+而不是\d,\d只能提取单个的数字字符。
提示:一般IsMatch要使用^$,但若是提取一般不使用^$
string s = "大家好呀,hello,2010年10月10日是个好日子。恩,9494.吼吼!886.";Match m = Regex.Match(s, @"[0-9]+");while (m.Success){Console.Write(m.Value);Console.WriteLine($"\t新游标位置{m.Index}");m = m.NextMatch();}Console.WriteLine($"\t最后游标位置{m.Index}");//0
重要:
当定义Regex.Match(s,@"[0-9]+")时,就开始进行了第一次匹配。匹配成功与否由
Success决定,一旦成功Index就变得有效,无论后面m=m.NextMatch()如何变化成
新的match对象,但它的index结果,都是针对最原始的字符串s的位置。
简言之:一旦正则没匹配成功,match.success为false,且match.index为0,为0表
示没有找到,而不是索引位置为0.
另外,匹配中有一个隐藏的游标,匹配成功游标就到达匹配成功的位置。例如在索
引5处匹配成功,这个匹配字符长度是5,那么下一次匹配时,游标从5+5+1处进行
下一次的匹配(也即m=m.NextMatch()时).
2、Match类
Match类是C#中的一个类,位于System.Text.RegularExpressions命名空间中,用于表示
正则表达式的匹配结果。下面是它的常用属性和方法:
Success:一个bool类型的属性,表示匹配是否成功。如果匹配成功,则为true,
否则为false。
Index:一个int类型的属性,表示匹配的起始索引,即匹配的文本在原始字符串
中的起始位置。
Length:一个int类型的属性,表示匹配的长度,即匹配的文本的字符数。
Value:一个string类型的属性,表示匹配的文本值。
ToString():一个方法,将Match对象转换为字符串表示。返回的字符串包含匹配的
文本值以及其他相关信息。
NextMatch():用于获取下一个匹配结果,尽管返回的是一个新的match对象,但它的index
仍然是以原始的字符串位置为准。
Groups:用于获取匹配结果的分组信息等。通过这些属性和方法,可以方便地处理和操作
正则表达式的匹配结果。
注意:index是匹配成功后在原字符串的位置。不能以index=0来判断匹配成功或失败。
而是用success来判断,然后index才有效。
问:上面Value与ToString()有什么区别?
答:match.Value 和 match.ToString() 都用于获取匹配项的文本表示。
match.Value 是 Match 对象的属性,用于获取当前匹配项的文本值。它返回的是一个
字符串,表示在输入字符串中匹配到的具体内容。
match.ToString() 是 Match 对象的方法,该方法返回一个字符串,表示匹配项的文
本值。实际上,match.ToString() 方法内部调用的是 match.Value 属性来获取匹配
项的文本值,然后将其转换为字符串。
故Value 和 ToString() 的结果是一样的,它们都返回匹配项的文本值。你可以根据
个人喜好选择使用其中的一种方式来获取匹配项的文本表示。
分组介绍:
Groups是Match对象的一个属性,它表示匹配结果中的分组信息。当使用正则表达式进行匹
配时,可以使用括号来创建分组,以便在匹配成功后获取特定组的值。
Groups属性返回一个GroupCollection对象,其中包含与匹配的分组相对应的Group对象。
Group对象表示一个匹配的分组,它提供了获取和操作匹配分组的功能。
与Groups属性和Group对象相关的常用属性和方法:
Groups.Count:返回分组的数量。
Groups[i]:通过索引访问指定的分组,其中i表示分组的索引(从1开始)。
Groups["groupName"]:通过分组的名称访问指定的分组。分组的名称由正则表达式中的
捕获组指定。
Group.Value:返回分组的匹配值。
Group.Index:返回分组的起始索引。
Group.Length:返回分组的长度。
例如,可以使用Groups[1].Value来获取第一个分组的匹配值,
使用Groups["groupName"].Value来获取指定名称的分组匹配值。
这种分组功能非常有用,可以在正则表达式匹配结果中提取和操作特定的子匹配结果。
3、用Regex.Matches()提取字符串的所有匹配。
前面match是逐个提取,现在用Regex.Matches()一次性全部提取所有匹配。
因此前面的例子可以改写如下:
string s = "“大家好呀,hello,2010年10月10日是个好日子。恩,9494.吼吼!886.”";MatchCollection mc = Regex.Matches(s, @"\d+");foreach (Match m in mc){Console.WriteLine($"索引位置{m.Index}匹配值{m.Value}");}Console.WriteLine($"共计有{mc.Count}");Console.WriteLine($"第一个{mc[0]}");Console.ReadKey();
问:Regex.Match()与Regex.Matches()有什么区别?
答:当你只需要获取第一个匹配结果或简单判断是否匹配时,使用Regex.Match方法。
当你需要查找和处理多个匹配结果时,使用Regex.Matches方法(返回集合);
简言之:Matches着重多个匹配结果的获取。
Match着重单个匹配结果的具体处理。
4、MatchCollection类
MatchCollection 类在 C# 中用于存储一个或多个正则表达式匹配的结果。它
由 Regex.Matches 方法返回。
MatchCollection 类提供了一组方法和属性,用于访问和操作多个匹配结果。这
使得您可以轻松地处理匹配结果并进行进一步的操作。常用的方法和属性:
Count :获取匹配结果的数量。
Item 索引器(即 `matches[index]`):通过索引访问匹配结果的特定项。
GetEnumerator :返回一个枚举器(Enumerator),用于遍历
MatchCollection 中的匹配结果。
string input = "123 abc 456 def";string pattern = @"\d+";Regex regex = new Regex(pattern);MatchCollection matches = regex.Matches(input);Console.WriteLine("匹配的结果数量:" + matches.Count);foreach (Match match in matches)// 使用 foreach 遍历匹配结果{Console.WriteLine("匹配的值:" + match.Value);Console.WriteLine("匹配的索引位置:" + match.Index);Console.WriteLine();}if (matches.Count > 0)// 访问单个匹配结果{Match firstMatch = matches[0];Console.WriteLine("第一个匹配的值:" + firstMatch.Value);Console.WriteLine("第一个匹配的索引位置:" + firstMatch.Index);}
问:GetEnumerator请举一个例子?
答:
string s = "“123 abc 456 def";MatchCollection mc = Regex.Matches(s, @"\d+");IEnumerator imc = mc.GetEnumerator();while (imc.MoveNext()){Match m = (Match)imc.Current;Console.WriteLine($"索引位置{m.Index}匹配字串为{m.Value}");}GetEnumerator
上面实际是逐个在列举match对象.
问:MatchCollection已经有了foreach,为什么还要用GetEnumerator方法?
答:foreach遍历时,提供更简洁和易读的代码。GetEnumerator() 与其他集合类型保
持一致。使MatchCollection 也能够作为一个可枚举的对象被使用。
如果您希望手动控制遍历过程,可以使用 GetEnumerator() 方法和 while 循环,
以便在每次迭代中执行更多的自定义逻辑。这种情况下,在遍历过程中需要更多
的灵活性时,使用 GetEnumerator() 方法会更加有用。
简言之,它类似match一样逐个控制输出每一个匹配元素,如索引,长度等。
如果既要获取全部,又要精细控制每一个,可以用GetEnumerator()试试.
问: Regex r=new Regex(pattern)与mc=Regex.Matches(s,pattern)的区别?
答:前面是实例方法,后面是静态方法。都可以取得匹配。
区别在于性能和重用性。
如果您需要多次使用同一个正则表达式进行匹配,使用new Regex(pattern) 可以
将正则表达式编译为可重用的Regex对象,并在每次匹配时直接使用该对象,可以
提高性能。然而,如果只需要简单地执行一次匹配操作,而不需要重复使用该正则
表达式,使用 Regex.Matches(input, pattern) 可以避免显式创建Regex对象,
更加简洁。
选择使用哪种方式主要取决于您的具体需求。
4、练习:字符串提取:
提取字符串中的Email。如何提取所有的Email地址?Matches(),
返回值为MatchCollection,可以通过索引器访问到Match对象。
string s = File.ReadAllText(@"E:\1.txt");//含html源码//如果上面有乱码,用File.ReadAllText(filePath, Encoding.GetEncoding("GB2312"))等MatchCollection mc = Regex.Matches(s, @"\b[\w\-.+]+@[-\w]+(\.[-\w]+)+\b", RegexOptions.ECMAScript);foreach (Match m in mc){Console.WriteLine(m.Index);//也可列出匹配位置}for (int i = 0; i < mc.Count; i++){Console.WriteLine(mc[i].Value);}
引申:上面的邮件出来后是一个整体,对a@b.c形式,想直接提取前面的a或b或c部分,
怎么做呢?这里要使用“提取组”概念.
5、提取组
凡是正则表达式中用()的部分就是提取组
()既有改变优先级别的作用,又有分组进行提取组的功能。
例如:\b([\w\-.+]+)@([-\w]+)((\.[-\w]+)+)\b表示有4个分组。
对于分组嵌套的情况,从左向右数,以第一个左边括号为第一组,第二个左边括号为第二组
....依次数下去,是第几个左括号就是第几组。不用管右边的括号。例(()())()()有5组
对于的就是Match的属性Groups,表示匹配结果中的组集合。
返回值是一个GroupCollection对象,它包含了所有捕获的组。注意:它是只读的。
重要:
无论是否有捕获组,groups.Count始终为1,因为它包括整个正则表达式模式的匹配
结果本身,它被视为一个默认的零号组。
因此,对于匹配成功时groups[0]表示整个匹配成功的字符串.
string s = "My email is xxx@163.com or yyy@qq.com";MatchCollection mc = Regex.Matches(s, @"@(\w+)\.", RegexOptions.ECMAScript);foreach (Match m in mc){Console.WriteLine($"{m.Value}里用户名为{m.Groups[0]},域名为{m.Groups[1]}");Console.WriteLine(m.Groups.Count);}
结果:
@163.里用户名为@163.,域名为163
2
@qq.里用户名为@qq.,域名为qq
2
6、自定义提取组
自定义命名组为捕获组赋予了可读性强且有意义的名称,对于代码阅读和维护都非常
有帮助。
自定义命名组的语法为:
(?<name>pattern)
其中`name`是组的名称,`pattern`是组的正则表达式模式。
如何使用自定义命名组:
string text = "Hello, my name is John Doe.";string pattern = @"Hello, my name is (?<name>\w+ \w+).";Match match = Regex.Match(text, pattern);if (match.Success){GroupCollection groups = match.Groups;Console.WriteLine("Match: " + match.Value);Console.WriteLine("Name: " + groups["name"].Value);}
通过在`groups`属性中使用组名来访问捕获组的值,可以使用groups["name"].Value
来获取名字的值。又如:
string s = "My birthday is on 2023-07-12";MatchCollection mc = Regex.Matches(s, @"(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})");foreach (Match m in mc){Console.WriteLine(m.Value);//注意gourps[0]表示m.value即当前整个匹配串Console.WriteLine($"\t{m.Groups[1]}年{m.Groups[2]}月{m.Groups[3]}日");}
强调:Groups始终是1,哪怕没有匹配成功,它也是1,所以用groups时确保成功匹配。
string s = "My birthday is on aaaa-aa-aa";Match mc = Regex.Match(s, @"(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})");Console.WriteLine(mc.Groups.Count);//1Console.WriteLine(mc.Groups[0]);//""上面没匹配成功时count也是1,groups[0]是null。所以应该用success来判断使用:string s = "My birthday is on 2023-07-12";Match m = Regex.Match(s, @"(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})");while (m.Success){Console.WriteLine(m.Groups[0]);//2023-07-12Console.WriteLine($"\t{m.Groups[1]}年{m.Groups[2]}月{m.Groups[3]}日");//2023年07月12日m = m.NextMatch();}Console.WriteLine(m.Groups.Count);//1
或者用foreach来用,因为有集合就说明有匹配成功。
string s = "My birthday is on 2023-07-12";MatchCollection mc = Regex.Matches(s, @"(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})");foreach (Match m in mc){Console.WriteLine(m.Groups[0]);//2023-07-12Console.WriteLine($"\t{m.Groups[1]}年{m.Groups[2]}月{m.Groups[3]}日");//2023年07月12日Console.WriteLine(m.Groups.Count);//4 }//只有Match有Groups属性,所以mc是MatchCollection无Groups属性
上面m.Groups.Count为4,因为匹配成功一次中:本身索引为0,year1,month2,day3.
7、GroupCollection类
GroupCollection是一个类,用于表示正则表达式匹配结果中的所有组。
它是Match对象的一个属性,提供了对所有匹配组的访问。
GroupCollection类提供了以下重要成员:
Count:获取组的数量。
IsReadOnly:获取一个值,指示集合是否为只读状态。
Item[Int32]:通过组的索引获取指定的组。
Item[String]:通过组的名称获取指定的组。
string text = "Hello, my name is John Doe. I am 30 years old.";string pattern = @"my name is (?<name>\w+ \w+). I am (?<age>\d+) years old.";Match match = Regex.Match(text, pattern);if (match.Success){GroupCollection groups = match.Groups;Console.WriteLine("Group count: " + groups.Count);//3for (int i = 0; i < groups.Count; i++)// 遍历所有组{Group group = groups[i];Console.WriteLine("Group index: " + i);Console.WriteLine("Group name: " + group.Name);Console.WriteLine("Group value: " + group.Value);Console.WriteLine();}Group nameGroup = groups["name"];// 通过名称获取组Console.WriteLine("Group by name \"name\": " + nameGroup.Value);}
通过Regex.Match方法得到一个Match对象,并通过其Groups属性获取到匹配结果中的组。
通过遍历GroupCollection中的每个Group对象,我们可以获取每个组的索引、名称和值。
此外,我们还可以通过组的名称(如"name")来直接获取指定的组。
8、Group类
GroupCollection中的每个元素都是Group对象。
Group类表示正则表达式匹配结果中的一个组。 Group类具有以下一些常用属性:
Value:获取组的匹配结果字符串。string类型
Index:获取组匹配的开始位置索引。
Length:获取组匹配的长度。
Captures:获取与组匹配的所有捕获的集合。
string text = "Hello, my name is John Doe.";string pattern = @"Hello, my name is (?<name>\w+ \w+).";Match match = Regex.Match(text, pattern);if (match.Success){GroupCollection groups = match.Groups;foreach (Group group in groups){Console.WriteLine("Group value: " + group.Value);Console.WriteLine("Group index: " + group.Index);Console.WriteLine("Group length: " + group.Length);Console.WriteLine();}}
注意:每个匹配结果都作为Group对象存储在GroupCollection中,你可以通过foreach循
环或使用索引来遍历它们。每个Group对象都提供了有关具体匹配组的信息,如值、
索引和长度等。
提示:因为match.Groups[i]或match.Groups["name"]的类型是Group类,因此不能用它
和null或string.Empty直接进行比较。是否有值是用它的属性value来比较。
if(m.Groups["Age"].Value==String.Empty)
9、提取组的性能问题
(1)提取组与捕获组是相同的一个概念。可以相互换称。
(2)使用圆括号 () 可以创建捕获组。
这意味着括号内的表达式将被视为一个组,并且被用于捕获匹配的子字符串。
使用圆括号创建的捕获组可以提供以下功能:
将组内的子字符串作为单独的项进行提取。
使用组的索引或名称来访问匹配结果中的组。
(3)捕获组在正则表达式匹配期间会使用一些额外的资源,因为它们需要在匹配过程中进
行缓存。每个捕获组都会生成一个结果对象,用于存储匹配的子字符串。
当使用捕获组时,正则表达式引擎会为每个捕获组创建一个额外的对象,并将匹配的
子字符串存储在这些对象中。这些对象的创建和管理会占用一定的内存和处理时间。
当需要进行大量匹配操作时,使用过多的捕获组可能会导致性能问题,尤其是在匹配
大量文本时。因此,在设计正则表达式时要谨慎使用捕获组,只在需要提取和使用特
定子字符串时才使用它们。
如果你对某个组不感兴趣,或者不需要通过索引或名称来访问匹配结果中的组,可以
使用非捕获组 (?: ) 来排除它们的缓存和处理开销。
string s = "Hello, my name is John Doe. I am 30 years old.";Match m = Regex.Match(s, @"(?:\w+ \w+)\..+ (\d+)");if (m.Success){Console.WriteLine(m.Groups.Count);//2foreach (Group m2 in m.Groups){Console.WriteLine(m2.Value);//整体与30}}
上面用了(?:)后,Count就为2了,一个是整体的匹配,另一个是年龄的匹配。
而中的名字Jahn Doe因为用了非捕获组,所以Group中无法访问,它没有缓存。
从而减少了开销。
引申:?. 可空条件,可以为空,为空时不用执行后面的属性或方法,直接返回null
例p?.Age(),或a?[3]数组为空不用取第4元素直接返回null
! 不可为空,告诉编译器确定不为null。若真的为null,直接抛异常。
?:三目运算,为真第一个,为假第二。
例 a>3?1:2 若a=4则返回1
?? null合并,不为null返回原值,为空返回后面的默认值。
例 a=b??3 若b不为null,则a=b;若b为null则用后面默认值a=3
五、提取组练习
1、从文件路径中提取出文件名(包含后缀) @"^.+\(.+)$"。比如从c:\windows\testb.txt中
提取出testb.txt这个文件名出来。项目中用Path.GetFileName更好。贪婪模式。注意:
\在c#中与在正则表达式中的转义符问题。演示:见备注1.
string p = @"c:\windows\testb.txt";Match m = Regex.Match(p, @".+\\(.+)");if (m.Success){Console.WriteLine(m.Groups[1]);}
引申:贪婪模式
2、从“June 26 , 1951 ”中提取出月份June来。
@"([a-zA-Z]+)\s*(\d{1,2})\s*,\s*\(d{4})\s*$"进行匹配。月份和日之间是必须要有
空格分割的,所以使用空白符号“\s”匹配所有的空白字符,此处的空格是必须有的,所
以使用“+”标识为匹配1至多个空格。之后的“,”与年份之间的空格是可有可无的,所以
使用“*”表示为匹配0至多个.
string p = @"June 26 , 1951 ";Match m = Regex.Match(p, @"(?<Month>[a-zA-Z]+)\s+(?<day>\d{1,2})\s*,\s*(?<year>\d{4}\s*)");if (m.Success){Console.WriteLine(m.Groups["Month"]);}
3、从Email中提取出用户名和域名,比如从test@163.com中提取出test和163.com。
string p = @"June 26 , 1951 ";Match m = Regex.Match(p, @"(?<Month>[a-zA-Z]+)\s+(?<day>\d{1,2})\s*,\s*(?<year>\d{4}\s*)");if (m.Success){Console.WriteLine(m.Groups["Month"]);if (m.Groups["month"].Value == string.Empty){Console.WriteLine("为空串");}}
注意:如果尝试访问一个名为"month"的组时,返回的组的Value属性将是一个空字符
串,而不是null。因此,在使用match.Groups["month"].Value之前,建议检查
组的值是否为空字符串。
4、“192.168.10.5[port=21,type=ftp]”,这个字符串表示IP地址为192.168.10.5的服务器
的21端口提供的是ftp服务,其中如果“,type=ftp”部分被省略,则默认为http服务。请
用程序解析此字符串,然后打印出“IP地址为***的服务器的***端口提供的服务为***”
string p = @"192.168.10.5[port=21,type=ftp]";Match m = Regex.Match(p, @"(?<ip>(\d{1,3}\.){1,3}\d{1,3})\[port=(?<port>\d{1,5})(,type=(?<type>[a-zA-Z]+))?\]");if (m.Success){if (m.Groups["type"].Value == ""){Console.WriteLine($"IP地址为{m.Groups["ip"]}的服务器的{m.Groups["port"]}端口提供的服务为http");}else{Console.WriteLine($"IP地址为{m.Groups["ip"]}的服务器的{m.Groups["port"]}端口提供的服务为{m.Groups["type"]}");}}