文章目录
- JVM 中的垃圾回收策略
- 死亡对象的判断算法
- 引用计数
- 可达性分析
- 垃圾回收算法
- 标记-清除算法
- 复制算法
- 标记-整理算法
- 分代算法
JVM 中的垃圾回收策略
C 语言中,malloc 的内存必须 手动 free,否则容易出现内存泄漏(光申请内存,不释放,内存用完了,导致程序崩溃)。
JVM 的垃圾回收,GC,可以帮助程序员自动释放内存。GC 能够有效的减少内存泄漏出现的概率!
Java 运行时的各个内存区域,对于程序计数器、虚拟机栈、本地方法栈这三个区域来说,内存的分配和回收具有确定性,都是随着线程的销毁而销毁。元数据区/方法区中存放的类对象,很少会“卸载”。所以堆是 GC 的主要目标,堆中存放着 new 出来的实例对象,GC 就是以对象为单位进行内存释放的。
GC 中主要分成两个阶段:
- 寻找死亡对象。
- 释放死亡对象的内存。
死亡对象的判断算法
死亡对象的定义
一个对象,后续再也不使用了,就可以认为是死亡对象。
如果一个对象,没有引用指向它,此时这个对象一定无法再被使用,这个对象就被认为是死亡对象了。
但是一个对象,已经不再使用了,但是还有引用指向它,这个对象也不能被认为是死亡对象。所以 Java 对于死亡对象的识别是比较保守的,避免了误判。
那么 Java 如何知道一个对象是否有引用指向呢?
- 引用计数
- 可达性分析
引用计数
给对象安排一个额外的空间,保存一个整数,表示该对象有几个引用指向。
缺陷:
-
浪费内存空间,需要额外的内存空间来计数。
-
循环引用的情况下,会导致引用计数的判定逻辑出错。
缺陷举例:
-- 伪代码
class Test{public Test n;
}Test a = new Test();
Test b = new Test();
a.n = b;
b.n = a;
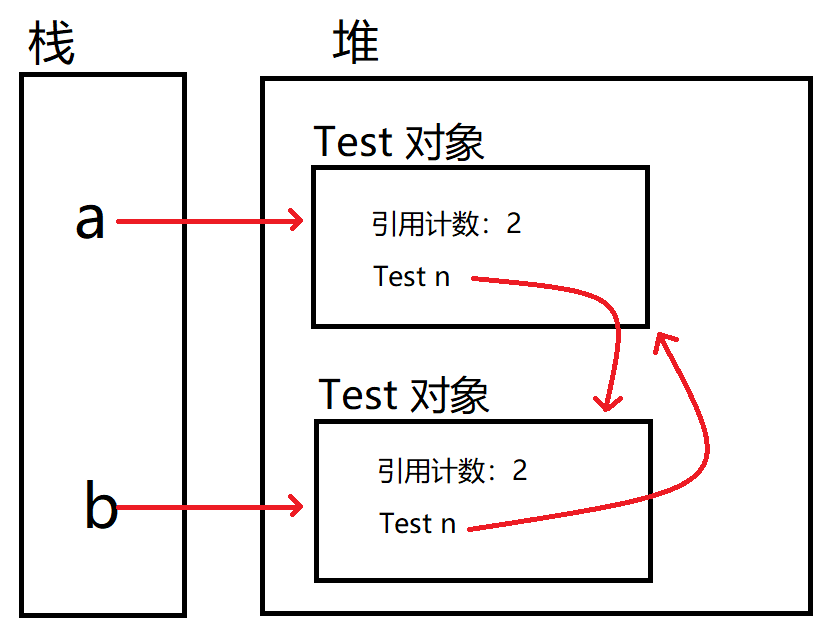
说明: 可以看到,此时一个 a 引用的 Test 对象,被 a 引用的 Test 对象的成员变量 n 引用。b 引用的 Test 对象,被 a 引用的 Test 对象的成员变量 n 引用。这就构成了循环引用。此时,两个 Test 对象都有两个引用指向。
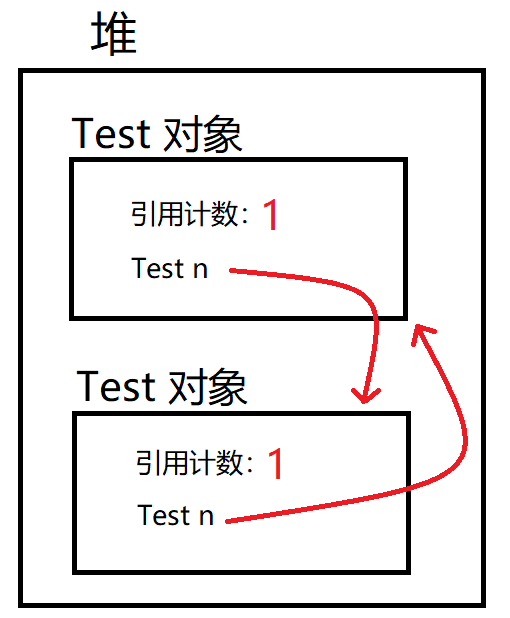
说明: 当 a 和 b 这两个局部变量销毁后,两个 Test 对象的引用计数各自减一,此时两个 Test 对象的引用计数都为 1,不能作为死亡对象,但是这两个对象已经无法使用了。
可达性分析
这是 JVM 采用的方案。
把对象之间的引用关系,理解成一个树型结构。从一些称为 GC Roots 的对象作为起点出发,进行遍历。
只要能遍历访问到的对象,就是“可达”。不能遍历到的对象,就是“不可达”,就是死亡对象。
举例:
class Node {int val;Node left;Node right;public static Node createTree() {Node a = new Node();Node b = new Node();Node c = new Node();a.left = b;a.right = c;// ......}public static void main(String[] args) {Node root = createTree();}
}
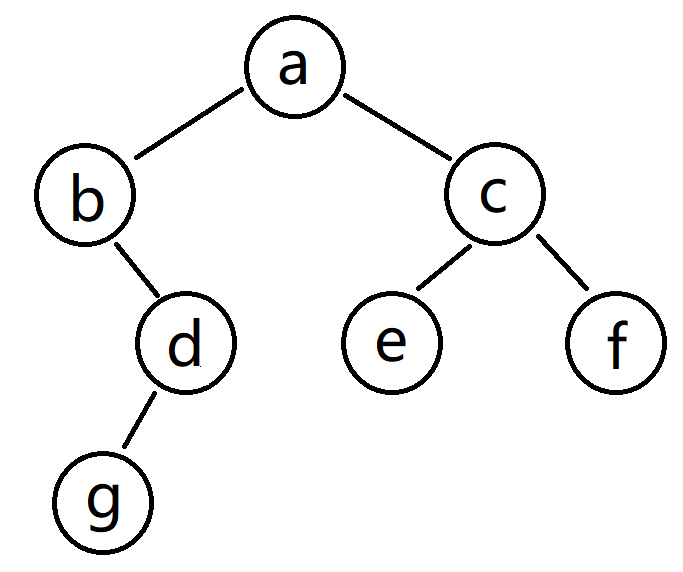
说明: 假设执行了上述代码后,生成了下图那样的一颗二叉树。
root 是一个局部变量,root 引用了 a 对象,a 对象就是一个 GC Roots。
此时,从 a 对象这个起点开始遍历,二叉树上每个节点都能遍历到,所以每个节点都是可达的。
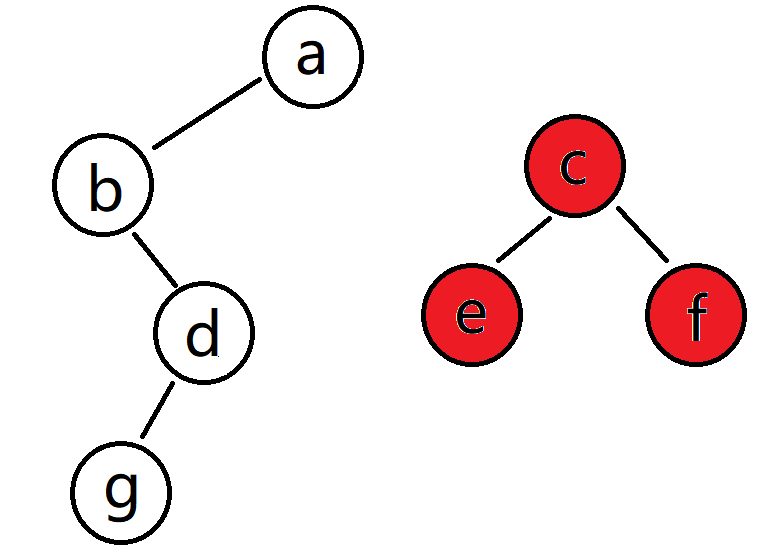
a.right = null;
说明: 当执行了这个代码后,就不能遍历到 c、e、f这三个节点,这三个节点就变为不可达,这三个节点就是死亡对象了。
当 root 这个局部变量销毁后,就找不到 a 节点了,那么这整个二叉树上的节点都是死亡对象了。
Java 中,可作为 GC Roots 的对象有以下几种:
- 栈中的局部变量引用的对象。
- 方法区中的常量引用的对象。
- 方法区中的类静态属性引用的对象。
可达性分析,就是从所有的 GC Roots 的起点出发,进行遍历,将遍历到的所有对象标记为 ”可达“,剩下的就是“不可达”,就是死亡对象了。
缺陷:
- 消耗更多的时间。遍历需要时间,因此某个对象成为死亡对象,也不一定能及时发现。
- STW(stop the world) 问题。在进行可达性分析的过程中,对象中的引用关系发生了变化,就比较麻烦了,所以为了判断的准确性,需要让其他的业务线程暂停工作。
垃圾回收算法
标记-清除算法
分为标记和清除两个阶段:
- 标记所有需要回收的对象。
- 将标记的对象进行统一回收。
缺陷:
内存碎片。这个算法会产生大量不连续的内存碎片,这可能导致后续分配内存时,找不到一块连续的较大的内存空间。
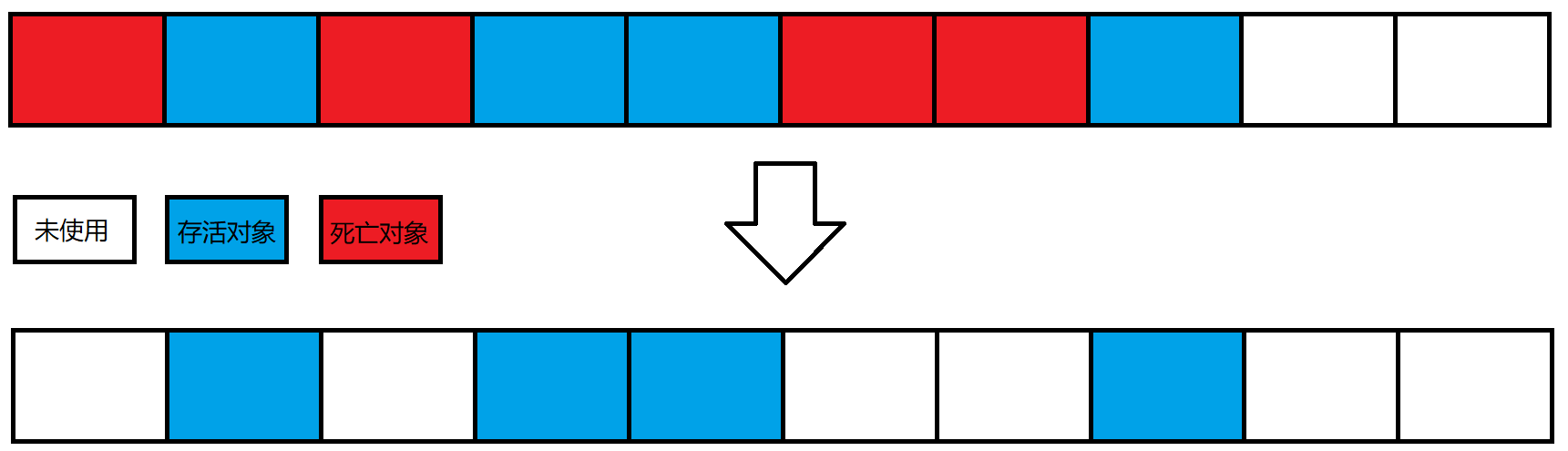
复制算法
把整个内存空间分成两半,一次只用一半。
垃圾回收时,将存活对象,拷贝到另一半内存中,然后再统一回收。
这个算法解决了内存碎片的问题,但是也有缺点。
缺陷:
- 内存利用率低
- 如果死亡对象较少,大部分都是存活对象,那么复制的成本就比较高。
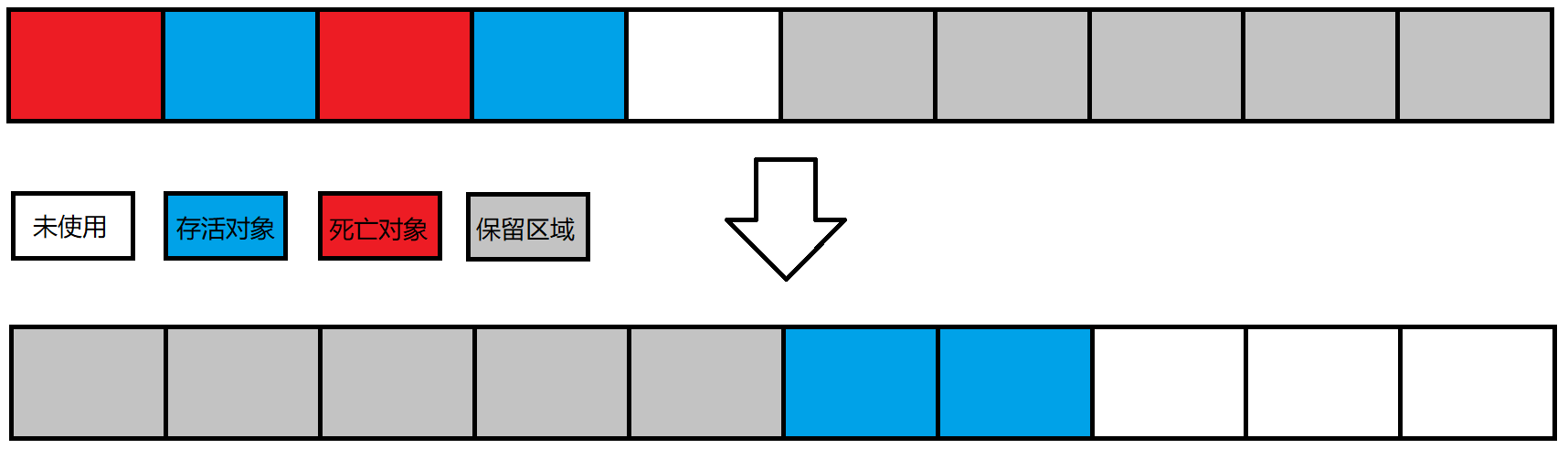
标记-整理算法
将所有存活对象向一端移动,然后再统一回收后面一段内存。
这个算法也能解决内存碎片问题,但是搬运开销比较大。

分代算法
JVM 采用的算法。
这个算法结合上述三种算法,针对不同的情况,使用不同的回收策略。
根据对象的存活周期的不同将内存分为几块区域。一般将内存划分为新生代区域和老年代区域。
关于对象的存活周期:每经过一次垃圾回收,没有被回收的对象,存活周期都会加一。
在新生代区域,每次垃圾回收都有大量的对象死去,只有少量对象存活,因此使用复制算法。在老年代区域,对象的存活率高,每次垃圾回收只有少量对象死去,因此没有额外的空间进行复制算法,那么就必须采用标记-整理算法。
经验规律:对于存活周期长的对象,这些对象大概率会继续存活。
分代算法:
-
新创建的对象,存放在伊甸区
在伊甸区中,大部分对象在第一轮 GC 中就被回收了。少量经过一轮 GC 没被回收的对象,会被拷贝到生存区。
-
经过伊甸区一轮 GC 没被回收的对象,存放在生存区。
生存区使用复制算法,将整个生存区分为两半。经过多次 GC 后,生存周期到达一定程度的对象,会被拷贝到老年代区域。
-
生产周期到达一定程度的对象,存放在老年代区域
在老年代区域中的对象,生产周期都挺长,消亡的概率较小,因此针对老年代区域的 GC 扫描频率就会降低很多。每次 GC,这个区域的对象大部分存活,少部分消亡,因此可能没有足够的空间使用复制算法,所以采用标记-整理算法。
特殊情况: 如果对象非常大,那么直接放在老年代区域,因为大对象进行复制算法,成本比较高,而且大对象也不会很多。