💓博主CSDN主页:杭电码农-NEO💓
⏩专栏分类:C++从入门到精通⏪
🚚代码仓库:NEO的学习日记🚚
🌹关注我🫵带你学习C++
🔝🔝

哈希结构
- 1. 前言
- 2. unordered系列容器
- 3. 哈希概念以及哈希结构
- 4. 哈希表详解(闭散列)
- 5. 哈希表模拟实现
- 6. 哈希桶详解(开散列)
- 7. 哈希桶模拟实现
- 8. 对于哈希结构的思考
1. 前言
相信大家一定听说过大名鼎鼎的
哈希结构吧,就算是没用过,也听说
过这句话:这道题无脑哈希就能做
哈希,哈希,到底什么是哈希?本篇文章
将带大家彻底搞懂这个问题!
本章重点:
本篇文章着重讲解关联式容器
unordered_map&set的底层结构
以及它们的模拟实现.并且将给大家
介绍unorder系列的接口函数!
2. unordered系列容器
不知道大家在刷题时有没有看见过
unordered_map和unordered_set
它们与map&set是什么关系?
什么时候可以用unordered系列?
带着这些疑问,进行今天的学习:

- unordered_map是
存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。 - 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,
unordered_map没有对<kye, value>按照任何特定的顺序排序 - unordered_map容器
通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。 - unordered_maps实现了直接访问操作符(operator[]),
它允许使用key作为参数直接访问value。
可以发现,其实unordered_map和
map使用起来没什么区别,可以说
是一模一样,那么什么时候应该用
unordered系列呢?答案是你只关
心键值对的内容而不关心是否有序
时,选择unordered系列
同理,unordered_set和set的用法
也基本一致,这里就不多做介绍了
如果你不知道map和set的用法,请
先看这篇文章:
map和set的熟悉
3. 哈希概念以及哈希结构
unordered_map&set的底层
结构实际上是哈希桶,也就是
哈希结构,下面来了解一下哈希思想:
最简易的哈希思想,数组下标0到100
存储的值代表数字0到100存不存在
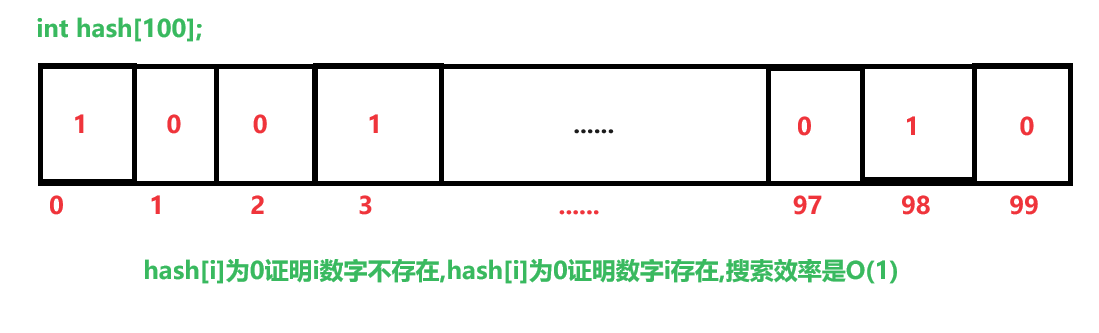
当然,实际情况下不可能最大值是几
就开辟多大的数组,因为会造成空间
的浪费,哈希的思路一般是根据某种
映射关系,把数据映射到数组中,查找
时也使用同样的映射关系来查找!
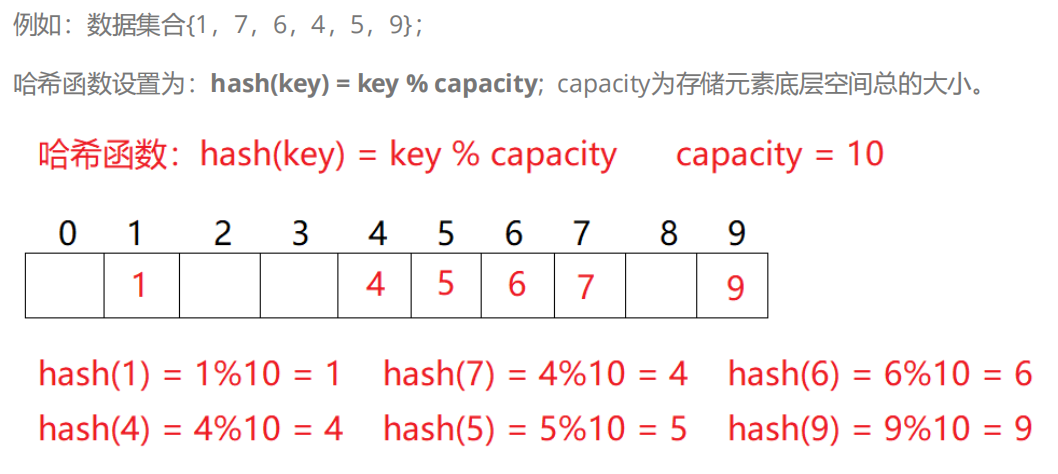
当然,当插入4后再插入14,此时会有问题
因为4这个位置已经被占用了,再次映射到
这个位置明显是行不通的,这个过程被称为
哈希冲突,具体内容会在后面讲解!
哈希结构又分为哈希表和哈希桶
下面就来一一讲解这两个的区别
4. 哈希表详解(闭散列)
引起哈希冲突的一个原因可能是:
哈希函数设计不够合理

然而不管哈希函数再怎么设计,都不能
完全保证不同的值映射到同一位置,所以
引申出了闭散列和开散列的解决方法
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去
寻找下一个空位置的方法有很多,如
线性探测(挨个往后找)
二次探测(以2^i为单位向后找)
这里只讲解线性探测

插入44后,位置4被占用了就往后找空位
哈希表的删除以及查找操作:
哈希表中的元素如果只是原生数据类型,
那么我们将4删除后,再去查找4肯定是找
不到的,但是此时去查找44也会找不到,因
为44本来应该映射到4位置,但是由于哈希
冲突跑到了8位置,并且我们并不知道它在
哪个位置,所以查找时会找不到!
解决方案:
存储数据不单单存储原生类型
再给每一个位置加上一个状态枚举
分别代表此位置是空,被删除还是有数
// 哈希表每个空间给个标记
// EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除
enum State {EMPTY, EXIST, DELETE};
查找元素时,若此位置是删除或存在
状态就继续向后找,若是空就代表此
元素并不在哈希表中!
5. 哈希表模拟实现
首先我们先将整个结构框架写出来:
enum State
{EMPTY,EXIST,DELETE
};template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state;HashData(const pair<K, V>& kv = make_pair(0, 0)):_kv(kv),_state(EMPTY){ }
};template<class K, class V>
class HashTable
{
private:vector<HashData<K, V>> _table;//数组中存储HashData封装的数据size_t _size = 0; //有效数据的个数
};
再来探讨一下插入时的扩容规则:
由于哈希表采用的是向后探测的方法
来存放不同的数据,那么当数据的个数
和数组的大小很接近时,会有很多冲突,
所以在容量到0.7或0.8时就应该要扩容了!
并且在扩容后,数据要重新根据先有的规则
进行挪动,也就是将旧数据挪动到新表!
bool insert(const pair<K, V>& kv)
{if (_table.size() == 0 || 10 * _size / _table.size() >= 7) // 扩容{size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;HashTable<K, V> newHT;newHT._table.resize(newSize);// 旧表的数据映射到新表for (auto e : _table){if (e._state == EXIST){newHT.insert(e._kv);}}_table.swap(newHT._table);}size_t index = kv.first % _table.size();//不能模capacity,如果模出来的数大于size了还插入进去了会报错//线性探测while (_table[index]._state == EXIST){index++;index %= _table.size();//过大会重新回到起点}_table[index]._kv = kv;_table[index]._state = EXIST;_size++;return true;
}HashData<K, V>* find(const K& key)
{if (_table.size() == 0)return nullptr;size_t index = key % _table.size();//负数会提升成无符号数,所以负数不影响结果,但是string类不能取模,需要加入一个仿函数size_t start = index;while (_table[index]._state != EMPTY){if (_table[index]._kv.first == key && _table[index]._state == EXIST)return &_table[index];index++;index %= _table.size();if (index == start)//全是DELETE时,必要时会breakbreak;}return nullptr;
}bool erase(const K& key)
{HashData<K, V>* ret = find(key);if (ret){ret->_state = DELETE;--_size;return true;}return false;
}
6. 哈希桶详解(开散列)
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
哈希桶实际上是这样的结构:
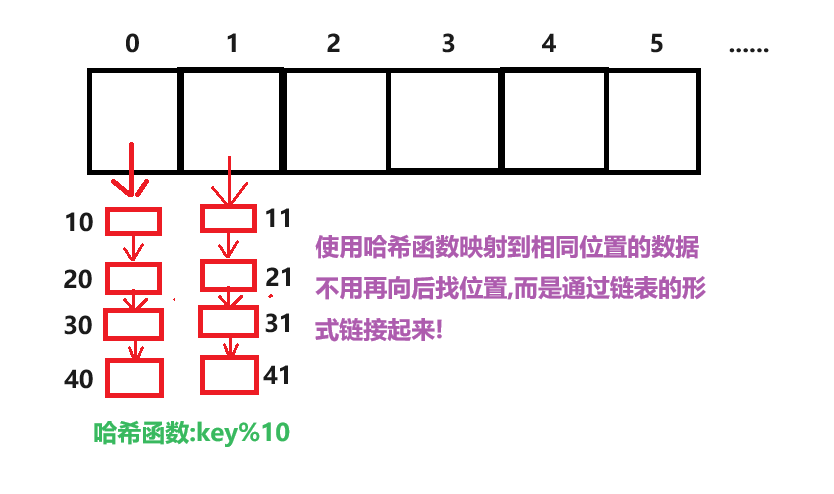
看似是一格数据,其实是一个链表指针
并且开散列的扩容旧不需要像
闭散列一样到0.7旧扩容了

可以把数组的每一个位置想象成
一个抽屉,当你远观时它就是一个
单一的格子,当你仔细把玩时它就
是一个可以拉开的存储结构!
7. 哈希桶模拟实现
首先先把基础框架写出来:
template<class K,class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;//以单链表的方式链接HashNode(const pair<K,V>& kv):_kv(kv),_next(nullptr){}
};template<class K,class V>
class HashTable
{typedef HashNode<K, V> Node;
private:vector<Node*> _table;size_t _size = 0;//有效数据个数
};
下一步,将新来的元素头插到链表中
因为头插的效率是O(1),并且扩容后
的策略和哈希表一样,重新将数据映射
到新表中
bool insert(const pair<K, V>& kv)
{//去重+扩容if (find(kv.first))return false;//负载因子到1就扩容if (_size == _table.size()){vector<Node*> newT;size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;newT.resize(newSize, nullptr);//将旧表中的节点移动到新表for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % newT.size();cur->_next = newT[hashi];newT[i] = cur;cur = next;}_table[i] == nullptr;}_table.swap(newT);}size_t hashi = kv.first % _table.size();//头插Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;++_size;return true;
}Node* find(const K& key)
{if (_table.size() == 0)return nullptr;size_t hashi = key % _table.size();Node* cur = _table[hashi];while (cur)//走到空还没有就是没用此数据{if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;
}bool erase(const K& key)
{Node* ret = find(key);if (ret == nullptr)return false;size_t hashi = key % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur && cur->_kv.first != key)//找到要删除的节点{prev = cur;cur = cur->_next;}Node* next = cur->_next;if (cur == _table[hashi])//注意头删的情况_table[hashi] = next;elseprev->_next = next;delete cur;cur = nullptr;_size--;return true;
}
对代码的解释都在注释中,还有问题欢迎私信!
8. 对于哈希结构的思考
我们会发现一个问题,不管是哈希
表还是哈希桶,都用到了cur.first模
上一个数,但是如果cur.first不是整型
不能取模怎么办?(如字符串)
这时需要在哈希类中再传入一个模板
参数,此模板参数为仿函数,只需将写好
的仿函数传入即可进行取模,比如string
仿函数可以这样写:
template<>
struct HashFunc<string>
{//BKDR算法:将字符串转换为整数size_t operator()(const string& str){size_t sum = 0;for (auto ch : str){sum *= 131;sum += (size_t)ch;}return sum;//将字符的asc码全部加起来再返回}
};