本资料仅供参考,不保证信息的严谨性和准确性。在使用本资料时,请务必进一步核实相关信息,并在必要时寻求专业意见。

请大家扫码【AI写稿助手】免费使用ChatGPT和Midjourney绘画及所有大模型
ChatGPT写稿专家ChatGPT,prompts,midjourney,AI写稿,AI对话,AI绘画![]() https://www.promptspower.com/
https://www.promptspower.com/
消息来源
原文:https://www.reuters.com/technology/sam-altmans-ouster-openai-was-precipitated-by-letter-board-about-ai-breakthrough-2023-11-22/
一位知情人士告诉路透社,OpenAI的一些人认为Q*(发音为Q-Star)可能是这家初创公司寻找所谓的通用人工智能(AGI)的一个突破。OpenAI 将 AGI 定义为在最具经济价值的任务中超越人类的自主系统。
鉴于巨大的计算资源,新模型能够解决某些数学问题,该人士不愿透露姓名,因为该人没有被授权代表公司发言。消息人士称,虽然只在小学生的水平上进行数学测试,但通过这样的测试,研究人员对Q*未来的成功非常乐观。
假说:思想树+过程奖励模型
Nathan Lambert
原文:https://twitter.com/natolambert/status/1728069713584877879
https://www.interconnects.ai/p/q-star
Nathan Lambert现在就职于Allen Institute for AI,之前是Berkeley的博士,HuggingFace科学家。
Nathan推测Q*主要的假说:
-
思维树搜索:寻找思考的过程。
-
过程奖励模型:对所有推理步骤进行排序。
-
使用 GPT-4 为思维树的所有顶点打分(强化学习和人工智能框架)。
-
应用 Q 学习进行优化。
他觉得Q*被夸大的原因是,它将大语言模型的训练和使用与Deep RL的核心组件联系起来,而这些组件,成功实现了AlphaGo的功能——自我博弈和前瞻性规划。
Q*似乎正在使用PRM,对ToT推理数据进行评分,然后再使用Offline RL进行优化。

Jim Fan
原文:https://twitter.com/DrJimFan/status/1728100123862004105
Jim Fan的推测和Nathan的基本意思一致,内容更偏向跟AlphaGo的类比
Jim Fan在在Nvidia做Senior AI Scientist。博士在Stanford Vision Lab,导师是李飞飞。
之前实习经历:NVIDIA, Google Cloud AI, OpenAI, Baidu Silicon Valley AI Lab, Mila-Quebec AI Institute.
转译:
在我投身人工智能领域的十年里,我从未见过有这么多人对一个算法如此富有想象。仅凭一个名字,没有任何论文、数据或产品。那么,让我们来揭开 Q* 幻想的神秘面纱,这可能是一段颇长的探索。
首先,要理解搜索与学习这两大 AI 技术的强大结合,我们得回溯到 2016 年,重新审视 AlphaGo 这一 AI 历史上的辉煌成就。它主要由四大要素构成:
-
策略神经网络(Policy NN,学习部分):它的任务是选择好的行动,通过估计每个行动带来胜利的可能性。
-
价值神经网络(Value NN,学习部分):这部分负责评估棋盘状况,并预测围棋中任何合法位置的胜负。
-
蒙特卡洛树搜索(MCTS,搜索部分):它代表着“Monte Carlo Tree Search”。这个过程利用策略神经网络模拟出从当前位置开始的多种可能的移动序列,然后综合这些模拟的结果来决定最有希望的行动。它是一个“慢思考”环节,与大语言模型(LLM)快速采样 Token 的方式形成对比。
-
真实信号:这是推动整个系统运作的动力源泉。在围棋中,这个信号非常简单,就是一个二元标签“谁获胜”,由固定的游戏规则决定。可以将其视为维持学习进程的能量源泉。
那么,这些组件是如何相互协作的呢?
AlphaGo 通过自我对弈不断进步,即它与自己之前的版本进行对弈。在这个过程中,策略神经网络和价值神经网络通过迭代不断优化:随着策略在选择动作方面变得更加高效,价值神经网络从中获取更优质的数据进行学习,并反过来为策略提供更精准的反馈。更强的策略也帮助蒙特卡洛树搜索探索出更优的策略。
这样形成了一个巧妙的“永动机”。通过这种方式,AlphaGo 自我提升能力,并在 2016 年以 4-1 的成绩击败了人类世界冠军李世石。仅仅模仿人类的数据,AI 是无法达到超人类水平的。
现在,让我们来探讨 Q* 的构成。它的四大组件是什么?
-
策略神经网络:这将是 OAI 最强大的内部大语言模型(GPT),负责实际执行解决数学问题的思维过程。
-
价值神经网络:另一个 GPT,用于评估每个中间推理步骤的正确性概率。OAI 在 2023 年 5 月发布了一篇名为《Let's Verify Step by Step》的论文,由 Ilya Sutskever(@ilyasut)、John Schulman(@johnschulman2)和 Jan Leike(@janleike)等共同撰写:https://arxiv.org/abs/2305.20050虽然它没有 DALL-E 或 Whisper 那么出名,但为我们提供了不少线索。这篇论文提出了“过程监督奖励模型”(PRM),它对思考链中的每一步提供反馈。相比之下,“结果监督奖励模型”(ORM)只在最终对整体输出作出判断。ORM 是强化学习从人类反馈(RLHF)中原始奖励模型的表达,但它太过粗略,无法适当评估长回应的各个子部分。换言之,ORM 不适合分配信用。在强化学习文献中,我们将 ORM 称为“稀疏奖励”(仅在最终给出),而 PRM 则是“密集奖励”,能够平滑地引导大语言模型朝我们期望的行为发展。
-
搜索:与 AlphaGo 的离散状态和动作不同,大语言模型操作的是“所有合理字符串”的更复杂空间。因此,我们需要新的搜索方法。在思考链(CoT)的基础上,研究社区已经发展了一些非线性 CoT:思考树(Tree of Thought):实际上是将 CoT 与树搜索结合起来:https://arxiv.org/abs/2305.10601,@ShunyuYao12,思考图(Graph of Thought):正如你所猜测的。将树变成图,就能得到一个更复杂的搜索操作符:https://arxiv.org/abs/2308.09687
-
真实信号:有几种可能性:(a) 每个数学问题都伴随着一个已知答案。OAI 可能已经收集了大量来自现有数学考试或竞赛的语料。(b) ORM 本身可以作为真实信号,但这样可能会被利用,从而“失去能量”维持学习。(c) 形式验证系统,如Lean定理证明器,可以将数学问题转化为编码问题,提供编译器反馈:https://lean-lang.org就像 AlphaGo 一样,策略大语言模型和价值大语言模型可以通过迭代相互促进改进,也可以在可能的情况下从人类专家的注释中学习。更优秀的策略大语言模型将帮助思考树搜索探索出更佳策略,反过来为下一轮迭代收集更好的数据。Demis Hassabis(@demishassabis)曾提到 DeepMind 的 Gemini 将使用“AlphaGo 风格的算法”来加强推理能力。即便 Q* 不是我们想象中的那样,谷歌肯定会用自己的方式紧随其后。如果我能想到这些,他们肯定也能。
需要指出的是,我所描述的仅仅是关于推理的部分。并没有说 Q* 在写诗、讲笑话 Grok(@grok)或角色扮演方面会更有创造力。提升创造力本质上是人类的事情,因此我相信自然数据仍会胜过合成数据。
非常欢迎大家的想法或反馈!
反对观点
https://twitter.com/ylecun/status/1728126868342145481
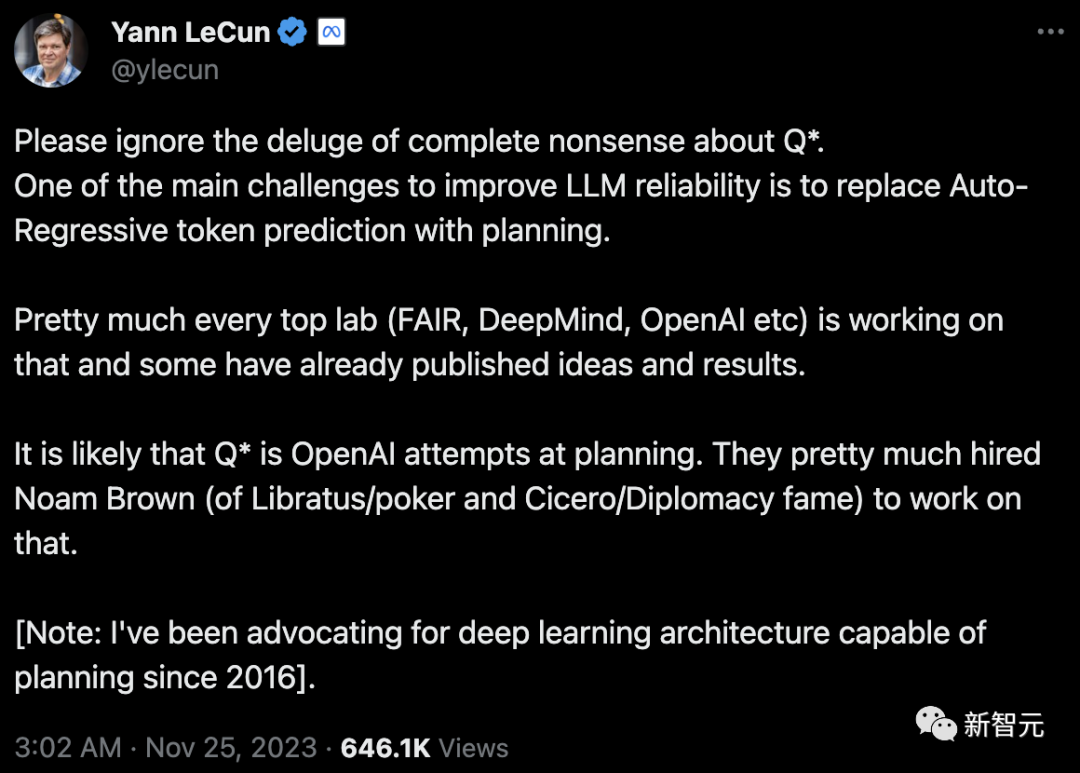
Yann LeCun
原文:https://twitter.com/ylecun/status/1728126868342145481
LeCun认为Q*只是OpenAI在规划领域的尝试
LeCun认为提升大LLM可靠性的一个主要挑战是,利用规划策略取代自回归token预测。几乎所有顶级实验室都在这方面进行研究,而Q*则很可能是OpenAI在规划领域的尝试。以及,请忽略那些关于Q*的毫无根据的讨论。
对此,Jim Fan深表赞同:担心「通过Q*实现AGI」是毫无根据的。「AlphaGo式搜索和LLM的结合,是解决数学和编码等特定领域的有效方法,同时还能提供基准真相的信号。但在正式探讨AGI之前,我们首先需要开发新的方法,将世界模型和具身智能体的能力整合进去。」
LeCun指出OpenAI雇佣了Noam Brown来做planning。
Noam Brown简介:
-
OpenAI 的研究科学家,专注于多步推理、自我对弈和多智能体 AI 领域。
-
之前在Meta的FAIR团队工作,团队开发了CICERO,这是首个在策略游戏《外交》中达到人类水平表现的AI。
-
研究应用于制作首个在无限注德州扑克中击败顶尖人类的 AI。他与CMU导师共同创建了Libratus 和 Pluribus,这两个系统在人机对抗赛中击败了顶尖的人类扑克专业选手。Libratus 获得了马文·明斯基杰出AI成就奖。Pluribus 曾登上《科学》杂志的封面,并在 2019 年被《科学》杂志评为年度突破的亚军。他还被《麻省理工科技评论》评为 35 岁以下的 35 位创新者之一。
-
从卡内基梅隆大学获得了计算机科学博士学位。在CMU之前,在联邦储备委员会的国际金融市场部门工作,研究金融市场的算法交易。在那之前,他从事算法交易工作。

总结与分析
-
未来模型提升的方向参考:(1)合成数据,(2)使用思维树而非单一宽度路径(思维链),这两种方法的突破使OpenAI解决了数据荒难题,这样就有了足够的高质量数据来训练下一代新模型。而这些数据,就是用计算机生成的数据,而非真实世界的数据。另外,Ilya多年研究的问题,就是如何让GPT-4等语言模型解决涉及推理的任务,如数学或科学问题。但是否能提升写作、角色扮演等需要创造力的任务的表现仍存疑。
-
其他如谷歌、Anthropic、Cohere等公司,创建预训练数据集用的还是过程监督或类似RLAIF的方法,轻易就会耗费数千个GPU小时。
-
Nathan Lambert表示,如果自己猜得没错,Q*就是生成的合成推理数据。通过类似剔除抽样(根据RM分数进行筛选)的方法,可以选出最优秀的样本。而通过离线RL,生成的推理可以在模型中得到改进。对于那些拥有优质大模型和大量算力资源的机构来说,这是一个良性循环。结合GPT-4给大家的印象,数学、代码、推理,都应该是最从Q*技术受益的主题。
-
Go靠真实数据进行训练,只能模仿人,用合成数据来训练的Zero自己和自己训练,合成数据无穷无尽,质量还远高于人类数据,Zero的效果远远超过人。
参考资料
https://mp.weixin.qq.com/s/0XG7wfcqKPfgkDPKw832hw
https://c.m.163.com/news/a/IK90TODF05418T7D.html?spss=newsapp&spsnuid=1V%2BjX%2F3b5rr7Vihh10cg1DKDBCJJ2Jzd3K3rbMKybuVFtAyg0BuuBqAMGJUs0UifLKLFB1b60t5bfMyo%2BfU9vA%3D%3D&spsdevid=1299BD07-A2EA-44E4-9636-68B6DF361E69&spsvid=&spsshare=wx&spsts=1700782918748&spstoken=iUL%2BefaxIfJdU7bIZc5ckljZOMULOFG1zm7vfESBV5S5M3n35%2FNEC04Y%2BaLRDoVP&spssid=4586a13aafbbfd6b28ac3efaa5036420&spsw=1&isFromH5Share=article
https://www.reuters.com/technology/sam-altmans-ouster-openai-was-precipitated-by-letter-board-about-ai-breakthrough-2023-11-22/
https://mp.weixin.qq.com/s/ueRbq_Ace7UCih1Od7qaDA
请大家扫码【AI写稿助手】免费使用ChatGPT和Midjourney绘画及所有大模型
ChatGPT写稿专家ChatGPT,prompts,midjourney,AI写稿,AI对话,AI绘画![]() https://www.promptspower.com/
https://www.promptspower.com/