如果你是人工神经网络 (ANN) 的初学者,你可能会问一些问题。 比如要使用的隐藏层数量是多少? 每个隐藏层有多少个隐藏神经元? 使用隐藏层/神经元的目的是什么? 增加隐藏层/神经元的数量总是能带来更好的结果吗? 使用什么损失函数? 使用多少个epoch? 使用什么权重初始化方法?
回答这些问题构成了设计基于神经网络的项目架构的基础。 因此,明智地选择这些参数当然非常重要。
我很高兴地告诉你我们可以回答此类问题。 需要明确的是,如果要解决的问题很复杂,那么回答这些问题可能会太复杂。 读完本文后,你至少可以了解如何回答这些问题,并能够根据简单的示例自己进行测试。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、基本的神经网络结构
基于自然,神经网络是我们对大脑的通常表示:神经元与其他神经元互连形成网络。 一条简单的信息在成为实际事物之前会在许多人中传递,例如“移动手拿起这支铅笔”。
完整的神经网络的操作很简单:输入变量作为输入(例如,如果神经网络应该告诉图像上的内容,则输入图像),经过一些计算后,返回输出(按照第一个示例, 给出猫的图像应该返回单词“cat”)。
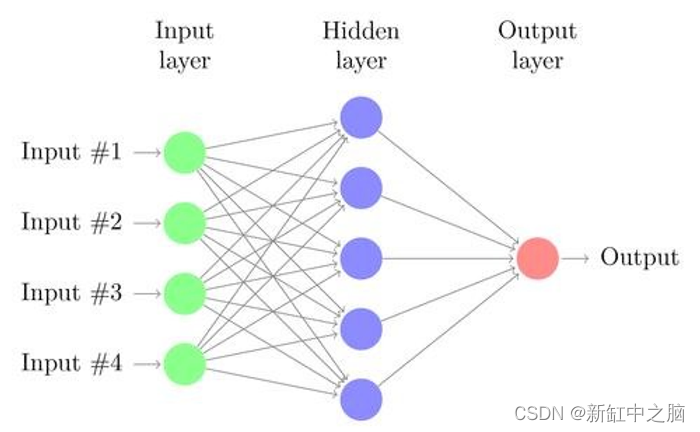
2、输入神经元
这是神经网络用于进行预测的特征数量。
输入向量的每个特征需要一个输入神经元。 对于表格数据,这是数据集中相关要素的数量。 您需要仔细选择这些特征,并删除任何可能包含无法泛化到训练集之外(并导致过度拟合)的模式的特征。 对于图像,这些是图像的尺寸(对于 MNIST,为 28*28=784)。
3、输出神经元
这是你想要做出的预测数量。
回归:对于回归任务,这可以是一个值(例如房价)。 对于多变量回归,每个预测值有一个神经元(例如,对于边界框,它可以是 4 个神经元 - 边界框高度、宽度、x 坐标、y 坐标各一个)。
分类:对于二元分类(垃圾邮件-非垃圾邮件),我们为每个正类使用一个输出神经元,其中输出表示正类的概率。 对于多类分类(例如,在对象检测中,一个实例可以被分类为汽车、狗、房子等),我们每个类有一个输出神经元,并在输出层使用 softmax 激活函数来确保 最终概率总和为 1。
4、隐层神经元
隐藏层的数量很大程度上取决于问题和神经网络的架构。 你本质上是在尝试进入完美的神经网络架构——不太大,也不太小,恰到好处。
一般来说,1-5 个隐藏层就可以很好地解决大多数问题。 在处理图像或语音数据时,你希望网络具有数百层,但并非所有层都完全连接。 对于这些用例,有预先训练的模型(YOLO、ResNet、VGG),它们允许你使用其网络的大部分,并在这些网络之上训练你的模型以仅学习高阶特征。 在这种情况下,你的模型仍然只有几层需要训练。
一般来说,所有隐藏层使用相同数量的神经元就足够了。 对于某些数据集,拥有较大的第一层并随后使用较小的层将带来更好的性能,因为第一层可以学习许多较低级别的特征,这些特征可以输入后续层中的一些高阶特征。
通常,添加更多层会比在每层中添加更多神经元获得更多的性能提升。
我建议从 1-5 层和 1-100 个神经元开始,然后慢慢添加更多层和神经元,直到开始过度拟合。 你可以在权重和偏差仪表板中跟踪损失和准确性,以查看哪些隐藏层+隐藏神经元组合会带来最佳损失。
选择较少数量的层/神经元时需要记住的是,如果这个数量太小,你的网络将无法学习数据中的底层模式,从而变得毫无用处。 解决这个问题的方法是从大量隐藏层 + 隐藏神经元开始,然后使用 dropout 和提前停止来让神经网络为你缩小自身规模。 再次,我建议尝试一些组合并跟踪权重和偏差仪表板中的性能,以确定适合你的问题的完美网络大小。
著名研究员 Andrej Karpathy 也推荐过拟合然后正则化的方法——“首先获得一个足够大的模型,使其能够过拟合(即关注训练损失),然后对其进行适当的正则化(放弃一些训练损失以改善验证损失)。”
5、损失函数
损失函数用于衡量预测输出与提供的目标值之间的误差。 损失函数告诉我们算法模型距离实现预期结果还有多远。 “损失”一词是指模型因未能产生预期结果而受到的惩罚。

- 回归
均方误差是最常见的优化损失函数,除非存在大量异常值。 在这种情况下,使用平均绝对误差 (MAE) 或 Huber 损失。
- 分类
在大多数情况下,交叉熵会很好地为您服务。
你可以从这篇文章中更深入地了解神经网络中的损失函数。
6、批大小
批大小是指一次迭代中使用的训练示例的数量。
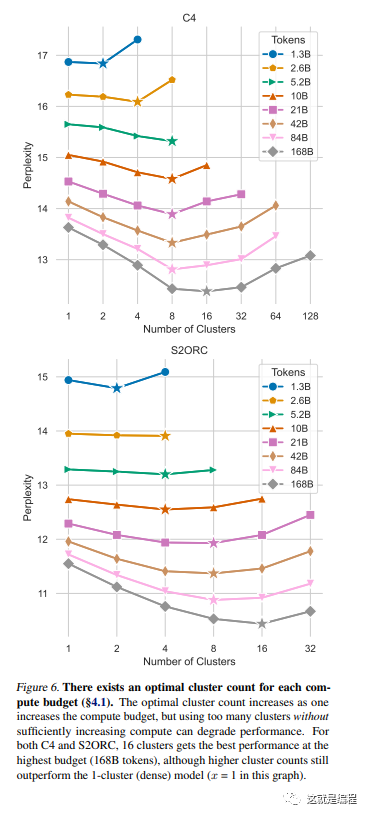
大的批可能会很棒,因为它们可以利用 GPU 的强大功能每次处理更多训练实例。 OpenAI 发现较大的批量大小(图像分类和语言建模为数万个,强化学习代理为数百万个)非常适合扩展和并行化。
然而,也有适合较小批量的情况。 根据 Masters 和 Luschi 的这篇论文,通过运行大批量提高并行性所获得的优势被小批量提高的性能通用性和更小的内存占用所抵消。 他们表明,增加批量大小会降低提供稳定收敛的可接受的学习率范围。 他们的结论是,事实上,越小越好; 并且最佳性能是通过 2 到 32 之间的小批量大小获得的。
如果你没有进行大规模操作,我建议你从较小的批大小开始,然后慢慢增加大小并在权重和偏差仪表板中监控性能以确定最适合的。
7、轮次数
我建议人们应该从大量的 epoch 开始,并在每个 epoch 的性能停止改善时使用 Early Stopping 来停止训练。
8、学习率
选择学习率非常重要,你要确保正确选择! 理想情况下,当你调整网络的其他超参数时,希望重新调整学习率。
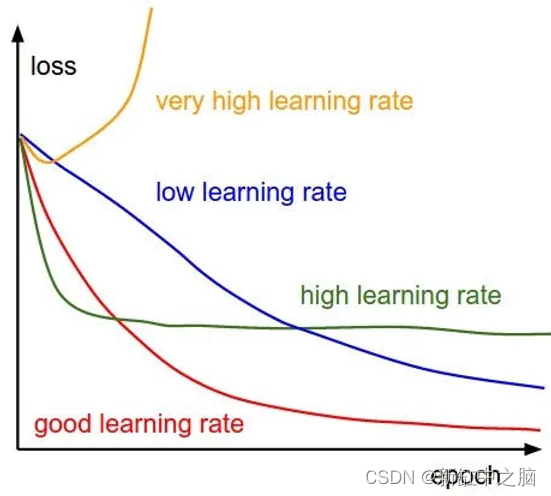
要找到最佳学习率,请从非常低的值 (10^-6) 开始,然后慢慢地将其乘以常数,直到达到非常高的值(例如 10)。 在权重和偏差仪表板中测量模型性能(相对于学习率的对数),以确定哪个速率可以很好地解决你的问题。 然后,你可以使用此最佳学习率重新训练你的模型。
最佳学习率通常是导致模型发散的学习率的一半。 请随意在随附的代码中为 learn_rate 设置不同的值,并查看它如何影响模型性能,以培养你对学习率的直觉。
我还建议使用 Leslie Smith 提出的学习率查找方法。 这是为大多数梯度优化器(SGD 的大多数变体)找到良好学习率的绝佳方法,并且适用于大多数网络架构。
另请参阅下面有关学习率表的部分。
9、动量
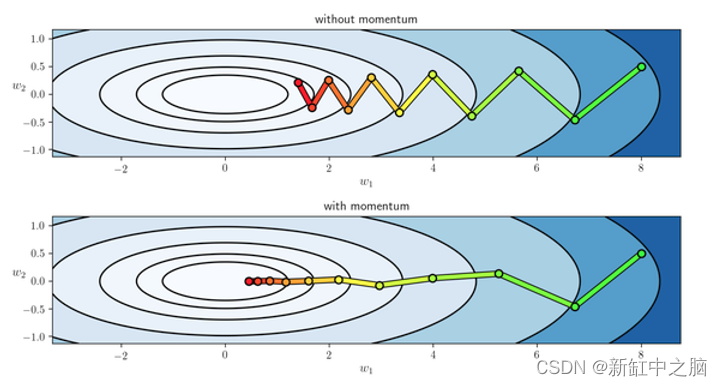
比较有动量和没有动量的 SGD 算法的学习路径
梯度下降采取微小、一致的步骤接近局部最小值,当梯度很小时,可能需要很长时间才能收敛。 另一方面,动量考虑了之前的梯度,并通过更快地越过山谷并避免局部最小值来加速收敛。
一般来说,你希望动量值非常接近 1。 对于较小的数据集来说,0.9 是一个不错的起点,数据集越大,你希望逐渐接近 1 (0.999)。 (设置nesterov=True可以让动量考虑到当前点之前几步的成本函数的梯度,这使得它稍微更准确和更快。)
10、梯度消失和爆炸
就像人一样,并非所有神经网络层都以相同的速度学习。 因此,当反向传播算法将误差梯度从输出层传播到第一层时,梯度会变得越来越小,直到到达第一层时几乎可以忽略不计。 这意味着第一层的权重在每一步都不会显着更新。
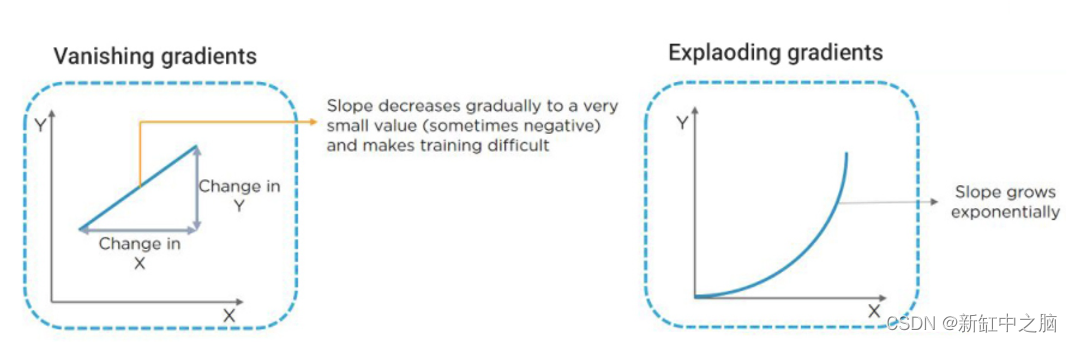
这就是梯度消失的问题。 (当某些层的梯度逐渐变大时,就会出现类似的梯度爆炸问题,导致某些层而不是其他层的权重大量更新。)
有几种方法可以抵消梯度消失。 现在让我们来看看它们吧!
11、隐层激活函数
一般来说,使用不同激活函数的性能按以下顺序提高(从最低→最高性能):
logistic → tanh → ReLU → Leaky ReLU → ELU → SELU
ReLU 是最流行的激活函数,如果您不想调整激活函数,ReLU 是一个很好的起点。 但是,请记住,ReLU 的吸引力越来越不如 ELU 或 GELU。
如果你感觉很热闹,可以尝试以下操作:
- 对抗神经网络过度拟合:RReLU
- 减少运行时延迟:leaky ReLU
- 对于大规模训练集:PReLU
- 快速推理:leaky ReLU
- 如果你的网络没有自我规范化:ELU
- 对于整体稳健的激活函数:SELU
与往常一样,不要害怕尝试不同的激活功能,并转向你的权重和偏差仪表板来帮助您选择最适合你的激活函数!
可以参考这篇研究论文,该论文深入探讨了神经网络中使用的不同激活函数的比较。
12、输出层激活函数
回归:回归问题的输出神经元不需要激活函数,因为我们希望输出具有任何值。 如果我们希望输出值限制在某个范围内,我们可以对 -1→1 值使用 tanh,对 0→1 值使用logistic函数。 如果我们只寻找正输出,我们可以使用 softplus 激活(ReLU 激活函数的平滑逼近)。
分类:使用sigmoid激活函数进行二分类,保证输出被挤压在0和1之间。使用softmax进行多类分类,保证输出概率加起来为1。
13、权重初始化方法
正确的权重初始化方法可以大大加快收敛时间。 初始化方法的选择取决于你的激活函数。 一些值得尝试的事情:
- 当使用ReLU或leaky RELU时,使用He初始化
- 当使用SELU或ELU时,使用LeCun初始化
- 当使用softmax、logistic或tanh时,使用Glorot初始化
- 大多数初始化方法都是均匀分布和正态分布的。
14、批归一化
批归一化学习每层输入的最佳均值和尺度。 它通过零中心化和标准化其输入向量,然后缩放和移动它们来实现这一点。 它也像一个正则化器,这意味着我们不需要 dropout 或 L2 reg。

使用批归一化可以让我们使用更大的学习率(这会导致更快的收敛),并通过减少梯度消失问题在大多数神经网络中带来巨大的进步。 唯一的缺点是它几乎不会增加训练时间,因为每层都需要额外的计算。
15、梯度剪裁
减少梯度爆炸的好方法之一,特别是在训练 RNN 时,就是在梯度超过某个值时简单地对其进行裁剪。 我建议尝试剪辑标准化而不是剪辑值,这使我们能够保持梯度向量的方向一致。 剪辑归一化包含 l2 范数大于特定阈值的任何梯度。
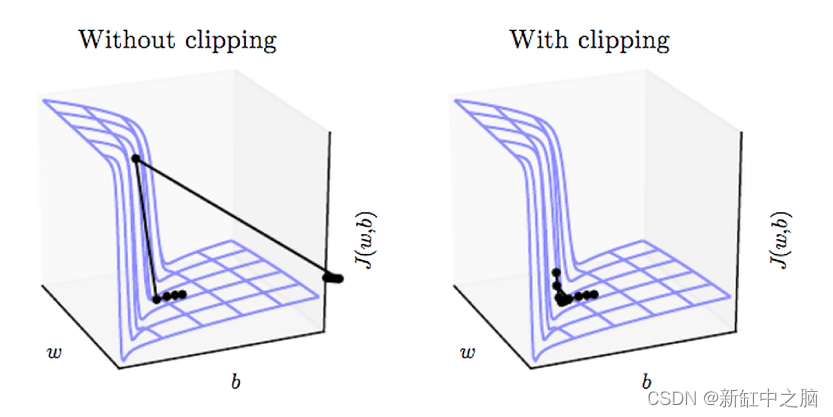
尝试几个不同的阈值以找到最适合你的阈值。
16、提前停止
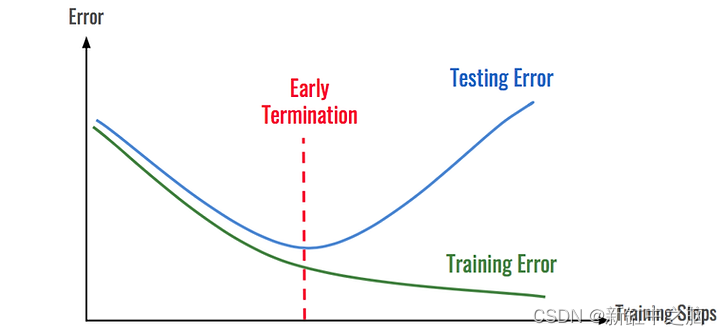
提前停止可以让你通过训练具有更多隐藏层、隐藏神经元和比你需要的更多时期的模型来实现它,并且当性能在 n 个时期连续停止改善时停止训练。 它还为你保存性能最佳的模型。 可以通过在适合模型时设置回调并设置 save_best_only=True 来启用提前停止。
17、Dropout
Dropout 是一种出色的正则化技术,它为我们带来了巨大的性能提升(对于最先进的模型来说约为 2%),而该技术实际上是多么简单。 Dropout 所做的就是在每个训练步骤中随机关闭每一层的一定比例的神经元。 这使得网络更加稳健,因为它不能依赖任何特定的输入神经元集来进行预测。 知识分布在整个网络中。 在训练过程中会生成大约 2^n(其中 n 是架构中神经元的数量)稍微独特的神经网络,并将其集成在一起以进行预测。
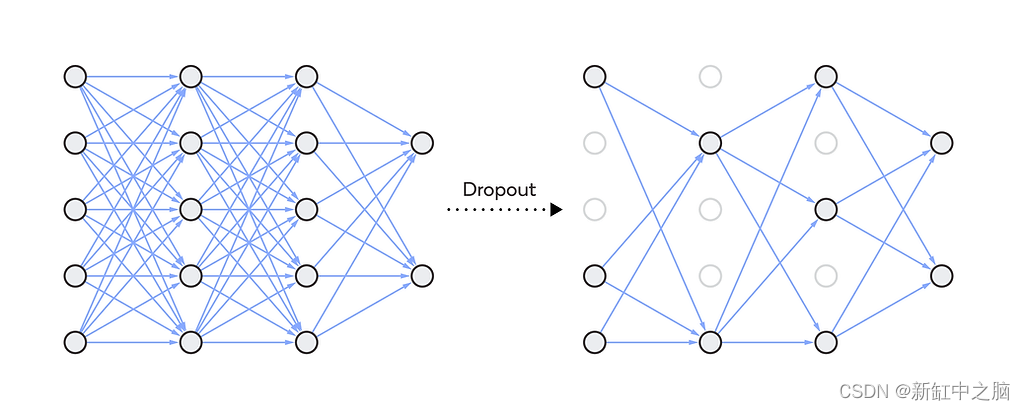
良好的dropout率在 0.1 到 0.5 之间; RNN 为 0.3,CNN 为 0.5。 对于更大的层使用更大的速率。 增加 dropout 率可以减少过拟合,而降低 dropout 率则有助于对抗欠拟合。
你想要在网络的早期层中试验不同的丢失率值,并检查权重和偏差仪表板以选择性能最佳的一个。 你绝对不想在输出层中使用 dropout。
在将 Dropout 与 BatchNorm 结合使用之前,请阅读本文。
在此内核中,我使用了 AlphaDropout,这是一种普通 dropout,通过保留输入的均值和标准差,可以与 SELU 激活函数很好地配合。
18、优化器
梯度下降并不是神经网络中使用的唯一优化器。 我们可以选择几种不同的。 在本文中,我只是描述一些你可以选择的优化器。 可以查看这篇文章,其中我详细讨论了所有优化器。
如果你非常关心收敛的质量并且时间不是最重要的,我建议使用随机梯度下降(SGD)。
如果你关心收敛时间并且接近最佳收敛的点就足够了,请尝试使用 Adam、Nadam、RMSProp 和 Adamax 优化器。 你的权重和偏差仪表板将引导你找到最适合的优化器!
Adam/Nadam 通常是很好的起点,并且往往对学习迟缓和其他非最佳超参数相当宽容。
根据 Andrej Karpathy 的说法,就 ConvNet 而言,“经过良好调整的 SGD 几乎总是会稍微优于 Adam”。
在此内核中,我从 Nadam 获得了最佳性能,这只是带有 Nesterov 技巧的常规 Adam 优化器,因此比 Adam 收敛得更快。
19、学习率调度
我们已经讨论过良好学习率的重要性 - 我们不希望它太高,以免成本函数围绕最佳值跳舞并发散。 我们也不希望它太低,因为这意味着收敛将需要很长时间。
照顾学习率可能很困难,因为较高和较低的学习率都有其优点。 好消息是我们不必承诺一个学习率! 通过学习速率调度,我们可以从较高的速率开始,以更快地通过梯度斜率,并在我们到达超参数空间中的梯度谷时放慢速度,这需要采取更小的步长。
调度学习率的方法有很多,包括以指数方式降低学习率、使用阶跃函数、在性能开始下降时调整学习率或使用 1cycle 调度。 在此内核中,我向你展示了如何使用ReduceLROnPlateau回调在n个时期内性能下降时将学习率降低一个常数因子。
我强烈建议也尝试 1cycle 调度。
使用恒定的学习率,直到训练完所有其他超参数。 并在最后实施学习率衰减调度。
与大多数事情一样,我建议使用不同的调度策略运行一些不同的实验,并使用权重和偏差仪表板来选择能够产生最佳模型的模型。
原文链接:神经网络设计FAQ — BimAnt