HDFS之Java客户端操作
文章目录
- HDFS之Java客户端操作
- 写在前面
- 准备Windows关于Hadoop的开发环境
- 下载依赖
- 配置HADOOP_HOME环境变量
- 配置Path环境变量
- 创建Maven工程
- XML文件
- 创建新的Package
- 创建HdfsClient类
- 执行程序
- HDFS的API操作
写在前面
- Hadoop版本:Hadoop-3.1.3
- Linux版本:CentOS7.5
- IDE工具:IntelliJ IDEA(Windows环境下)
HDFS的Java客户端操作也是入门Hadoop开发的学习重点
准备Windows关于Hadoop的开发环境
下载依赖
https://github.com/steveloughran/winutils
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kp9sqiA6-1676719698127)(0.png)]](https://img-blog.csdnimg.cn/7dfe70b2750b443085b2d2f91c403f93.png)
根据自己的Hadoop安装版本选择对应版本的依赖,如果需要更高版本的依赖,请从以下地址下载
https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.0/bin
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WIN6suQi-1676719698128)(1.png)]](https://img-blog.csdnimg.cn/c41d93cdd47648808516920f298f0c35.png)
将下载的文件拷贝到你存储Hadoop依赖的路径中(比如是E:\Development目录下)
配置HADOOP_HOME环境变量
选择系统变量,跟JAVA_HOME的配置是一样的
配置Path环境变量
- 编辑环境变量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GM0msSjX-1676719698128)(2.png)]](https://img-blog.csdnimg.cn/be8cc5600d0b44108965286b2b1b39eb.png)
需要重启电脑,使得环境生效
创建Maven工程
XML文件
创建一个Maven工程
HdfsClientDemo,并导入相应的依赖坐标+日志添加,pom.xml文件内容如下:
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>2.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency>
</dependencies>
在项目的
src/main/resources目录下,新建一个文件,命名为log4j2.xml,在文件中填入以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig"><Appenders><!-- 类型名为Console,名称为必须属性 --><Appender type="Console" name="STDOUT"><!-- 布局为PatternLayout的方式,输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here --><Layout type="PatternLayout"pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" /></Appender></Appenders><Loggers><!-- 可加性为false --><Logger name="test" level="info" additivity="false"><AppenderRef ref="STDOUT" /></Logger><!-- root loggerConfig设置 --><Root level="info"><AppenderRef ref="STDOUT" /></Root></Loggers>
</Configuration>创建新的Package
包名:cn.whybigdata.hdfs
创建HdfsClient类
尝试连接Hadoop集群并创建新的目录
/xiyouji/sunwukong
public class HdfsClient{ @Testpublic void testMkdirs() throws IOException, InterruptedException, URISyntaxException{ // 1 获取文件系统Configuration configuration = new Configuration();// 配置在集群上运行// configuration.set("fs.defaultFS", "hdfs://node01:9820");// FileSystem fs = FileSystem.get(configuration);FileSystem fs = FileSystem.get(new URI("hdfs://node01:9820"), configuration, "whybigdata"); // 2 创建目录fs.mkdirs(new Path("/xiyouji/sunwukong")); // 3 关闭资源fs.close();}
}
执行程序
运行时需要配置用户名称whybigdata
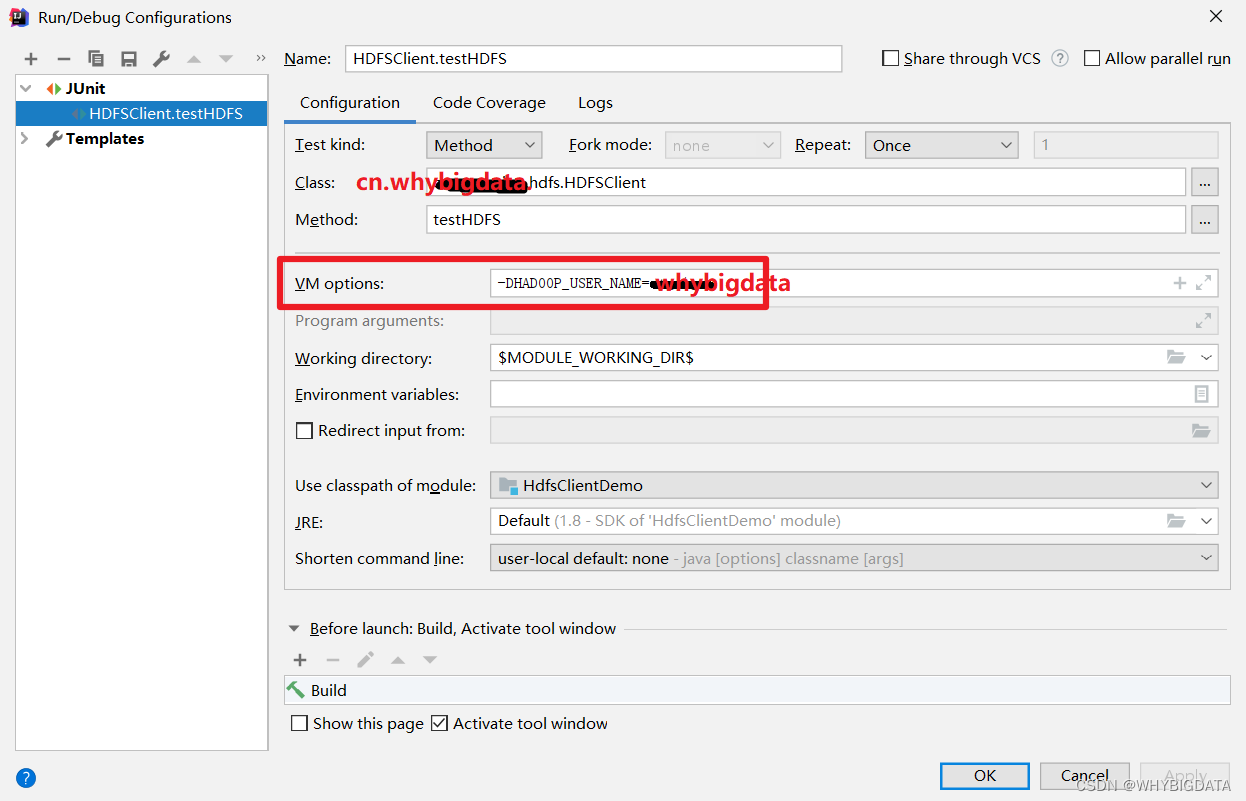
客户端去操作HDFS时,是有一个用户身份的。默认情况下,HDFS客户端API会从JVM中获取一个参数来作为自己的用户身份:
-DHADOOP_USER_NAME=whybigdata,whybigdata为用户名称。
HDFS的API操作
常见的API操作包括:文件上传、下载;删除文件和目录;文件重命名、移动、查看文件详情;HDFS文件和文件夹的判别。带如下所示:
package cn.whybigdata.hdfs;/*** @author whybigdata* @create 2022-12-17-16:21*/import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
import java.net.URI;/*** 1. 和 HDFS 建立连接* 2. 调用 API 完成具体功能* 3. 关闭连接*/
public class HdfsClientTest {private FileSystem fs;/*** TODO 判断是文件还是目录* @throws IOException*/@Testpublic void testFileStatus() throws IOException{FileStatus[] fileStatuses = fs.listStatus(new Path("/"));for (FileStatus status : fileStatuses) {if (status.isDirectory()) {System.out.println("DIR:" + status.getPath().getName());} else {System.out.println("FILE:" + status.getPath().getName());}}}/*** TODO 查看文件详情* @throws IOException*/@Testpublic void testListFiles() throws IOException{RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();System.out.println("文件名" + fileStatus.getPath().getName());System.out.println("块大小" + fileStatus.getBlockSize());System.out.println("副本数" + fileStatus.getReplication());System.out.println("权限信息:" + fileStatus.getPermission());}}/*** TODO HDFS文件更名和移动* @throws IOException*/@Testpublic void testRename() throws IOException{// 移动文件
// fs.rename(new Path("/sanguo/liubie.txt"), new Path("/client_test"));// 更名fs.rename(new Path("/client_test/liubie.txt"), new Path("/client_test/xiaoqiao.txt"));}/*** TODO 删除文件和目录**/@Testpublic void testDelete() throws IOException {fs.delete(new Path("/client_test/hello.txt"), true);}/*** TODO 下载文件**/@Testpublic void testCopyToLocal() throws IOException {fs.copyToLocalFile(false, new Path("/client_test/hello.txt"),new Path("E:\\Test"), true);}/*** TODO 上传文件* 测试配置的优先级 Configuration > hdfs-site.xml > hdfs-default.xml*/@Testpublic void testCopyFromLocal() throws IOException {fs.copyFromLocalFile(false, true,new Path("E:\\hello.txt"),new Path("/client_test"));}/*** TODO 获取 HDFS 对象* @throws IOException* @throws InterruptedException*/@Beforepublic void init() throws IOException, InterruptedException {// HDFS访问路径 hdfs://node01:9820URI uri = URI.create("hdfs://node01:9820");// conf : 配置对象Configuration conf = new Configuration();conf.set("dfs.replication", "6");// user : 操作用户(用哪个用户操作HDFS)String user = "whybigdata";// 获取HDFS的客户端连接(文件系统对象)fs = FileSystem.get(uri, conf, user);}/*** TODO 关闭资源*/@Afterpublic void close() throws IOException {fs.close();}/*** TODO 获取HDFS的客户端连接* uri : HDFS访问路径 hdfs://node01:9820* conf : 配置对象* user : 操作用户(用哪个用户操作HDFS)*/@Testpublic void testCreateHdfsClient() throws IOException, InterruptedException {// HDFS访问路径 hdfs://node01:9820URI uri = URI.create("hdfs://node01:9820");// conf : 配置对象Configuration conf = new Configuration();// user : 操作用户(用哪个用户操作HDFS)String user = "whybigdata";// 获取HDFS的客户端连接(文件系统对象)FileSystem fileSystem = FileSystem.get(uri, conf, user);System.out.println(fileSystem.getClass().getName());// 关闭资源fileSystem.close();}
}
注意:
- 获取HDFS对象操作封装为一个
init()方法- HDFS文件更名和移动:调用的是同一个方法rename()
- 使用之后记得要关闭资源
fileSystem.close()
全文结束!