目录
模型背景
CLIP模型介绍
相关资料
原理和方法
Image Encoder
Text Encoder
对比学习
预训练
Zero Shot预测
优势和劣势
总结
OpenClip模型介绍
相关资料
原理
结果
用法
模型总结
模型背景
Stable Diffusion主要由三个核心模块组成:
-
Text Encoder(文本编码器)
-
Image Information Creator(图像信息生成器)
-
Image Decoder(图像生成器)

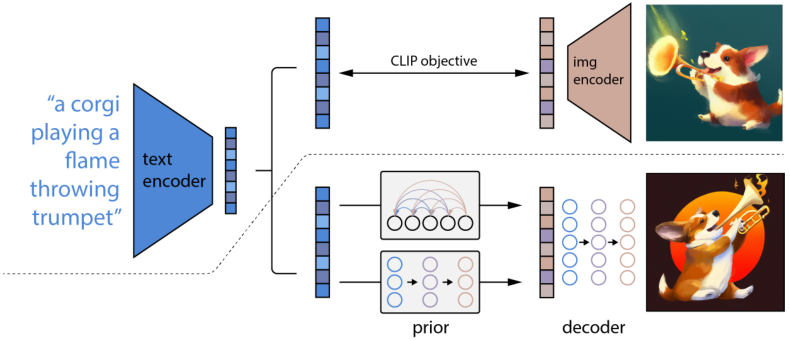
文本编码器负责处理语义信息。通常是利用CLIP(v1版本)、OpenCLIP(v2版本)等模型将人类语言(文字)编码为计算机语言(语义向量)。训练CLIP(OpenCLIP)则需要一个图文配对的数据集。数据集来自LAION-5B,由50亿个图片以及图片对应的标签组成。包含23.2亿的英文描述,22.6亿个100+其他语言以及12.7亿的未知语。
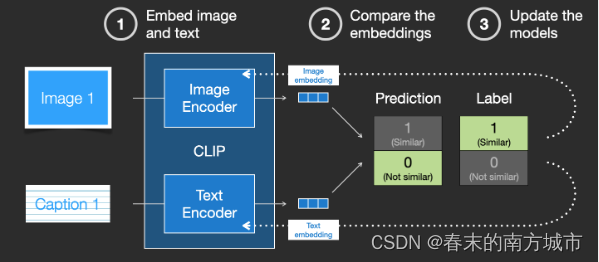
CLIP模型介绍
CLIP(Contrastive Language-Image Pretraining), 是OpenAI利用4亿张互联网上找到的图片,以及图片对应的Alternative文字训练的多模态模型。不仅可以拿来做常见的图片分类、目标检测,也可用来优化业务场景的商品搜索和内容推荐。CLIP能够基于视觉和语言相互关联的方式,实现无监督或弱监督的图像分类任务,并在多项视觉和语言任务中取得了优异的性能。Stable Diffusion V1中使用OpenAI的CLIP的 ViT-L/14进行文本嵌入。
相关资料
论文地址:https://arxiv.org/pdf/2103.00020.pdfarxiv.org/pdf/2103.00020.pdf
代码地址:https://github.com/OpenAI/CLIPgithub.com/OpenAI/CLIP
官方解读博客:https://openai.com/research/clipopenai.com/research/clip
一些好的博客:
https://zhuanlan.zhihu.com/p/625165635
https://juejin.cn/post/7264503343996747830
https://juejin.cn/post/7241859817563389989
原理和方法
CLIP模型的核心思想是将视觉和语言的表示方式相互联系起来从而实现图像任务。CLIP模型由两个主体部分组成:Text Encoder和Image Encoder。这两部分可以分别理解成文本和图像的特征提取器。CLIP模型采用了对比学习(Contrastive Learning)和预训练(Pre-Training)的方法,使得模型能够在大规模无标注数据上进行训练,并学习到具有良好泛化能力的特征表示。
Image Encoder
对于 Image Encoder,CLIP使用“ViT-L/14@336px”这个模型,也就是架构为Large,patch_size = 14的ViT,同时在整个CLIP预训练结束后,用更高分辨率(336*336)的图片做了一个epoch的fine-tune,目的是让CLIP能涌现出更好的效果。与Text Encoder类似,每张图片对应一个最终特征表示向量Ii。
Text Encoder
对于 Text Encoder,使用改进版的 Transformer,一个带有8个注意头的 63M 参数的12层512宽 Transformer 模型,CLIP借鉴的是GPT2的架构。对于每条prompt,在进入Text Encoder前,都会添加表示开始和结束的符号[SOS]与[EOS]。最终将最后一层[EOS]位置的向量作为该prompt的特征表示向量。然后通过 LN,后接 Linear 层投影到多模态空间中。
对比学习
对比学习是一种学习相似性度量的方法,是通过将同一组数据中的不同样本对进行比较,来学习它们之间的相似度或差异度。在CLIP模型中,对比学习被用来训练模型学习视觉和语言的相互关系。CLIP模型将图像和文本映射到同一表示空间,并通过对比不同图像和文本对之间的相似性和差异性进行训练,从而学习到具有良好泛化能力的特征表示。假设一个batch中共有N对<图像,文字>对,那么它们过完各自的Encoder后,就会分别产生:
-
N条文字向量[T1,T2,...,TN]
-
N条图片向量[I1,I2,...,IN]
这两组向量,将会分别过一次多模态Embedding(multimodal embedding) ,也就是在图中代表文字的紫色向量下,还有一层参数Wt(图中没有画出来),文字向量需要先和Wt做矩阵相乘后,才能得到最终的文字向量。对图片向量,同理也有个对应的Wi。Wt,Wi 的作用是把文字、图片特征投影到多模态的特征空间中去。
如图所示,给定一个 Batch 的 N 个 (图片,文本) 对,图片输入给 Image Encoder 得到表征 I1, I2, ..., IN ,文本输入给Text Encoder得到表征 T1, T2, ..., TN, 然后通过“对比学习”,找到图像和文字的相似关系。对于图中列出的N*N个格子,只需计算每个格子上对应的向量点积(余弦相似度)。由于对角线上的图片-文字对是真值,希望对角线上的相似度可以最大,据此可设置交叉熵函数,来求得每个batch下的Loss。

预训练
预训练是指在大规模无标注数据上训练模型,使其学习到通用的特征表示。在CLIP模型中,预训练包括两个阶段:视觉预训练和视觉-语言预训练。
-
视觉预训练:在大规模无标注图像数据上训练模型,使其学习到视觉特征表示。在视觉预训练阶段,CLIP模型使用对比学习的方法,将不同图像对进行比较,从而学习到具有区分度的视觉特征。CLIP模型使用了一个基于Transformer的编码器来将图像转换为特征表示,然后通过对比学习使得同一张图像的不同裁剪或变换间距离更近,不同图像间距离更远。这样模型就能学习有区分度的视觉特征表示。
-
视觉-语言预训练:在大规模无标注图像和文本数据上训练模型,使其学习到视觉和语言的相互关系。在视觉-语言预训练阶段,CLIP模型使用了对比学习和跨模态对比学习的方法,使得模型能够学习到视觉和语言的相互关系。CLIP模型使用了一个基于Transformer的编码器将图像和文本转换为特征表示,并通过对比学习的方法,使得相同含义的不同图像和文本之间的距离更近,而不同含义的图像和文本之间的距离更远。这样模型就能学习到有良好泛化能力的视觉和语言特征表示,并用于各种视觉和语言任务中。
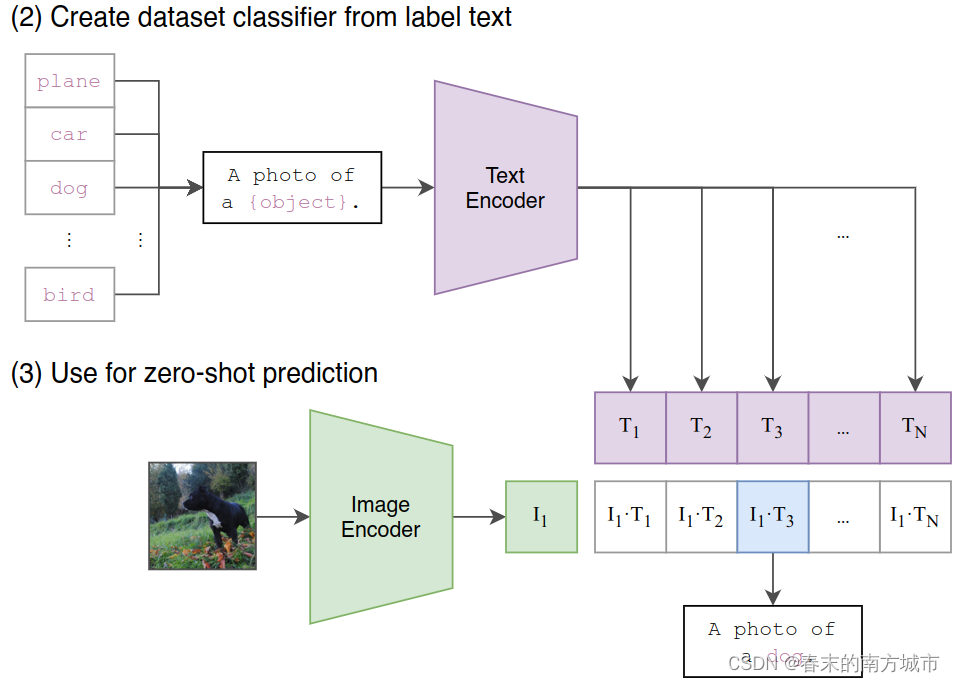
Zero Shot预测
Zero-Shot 预测:如下图所示,当做完模型对比学习和预训练后,就能用模型进行zero-shot预测:
-
首先,创建一个标签全集,如图中(2)所示,并得到每一个标签的特征向量
-
然后,取一张图片,如图中(3)所示,过Image Encoder后得到该图片的特征向量
-
最后,计算图片向量和文字向量间的相似度,取相似度最高的那条label即可。
优势和劣势
CLIP模型优势:
-
无监督或弱监督的学习方法:CLIP模型采用了对比学习和预训练的方法,使得模型能够在大规模无标注数据上进行训练,并学习到具有良好泛化能力的特征表示,因此不需要大量标注数据。
-
泛化能力强:CLIP模型能够学习到具有良好泛化能力的特征表示,并在多项视觉和语言任务中取得优异性能。
-
可解释性好:CLIP模型使用了一个基于Transformer的编码器,能够对输入的图像和文本进行编码,并输出对应的特征表示,因此具有很好的可解释性。
CLIP模型劣势:
-
计算资源消耗大:由于CLIP模型采用了大规模无标注数据进行训练,并使用了较大的模型,因此需要大量计算资源进行训练和推理。
-
文字标签是个闭集:模型预测一张新的图像,只能从已有的标签集合中找出最相似的,不能预测一个新标签。
总结
通过 CLIP 模型,可以对任意物品名称进行零样本分类,还能进行零样本的目标检测。而文本和图片在同一个向量空间的这个特性,也能够直接利用这个模型进一步优化商品搜索功能。可以拿文本的向量,通过找到余弦距离最近的商品图片来优化搜索的召回过程。也能直接拿图片向量,实现以图搜图这样的功能。
OpenClip模型介绍
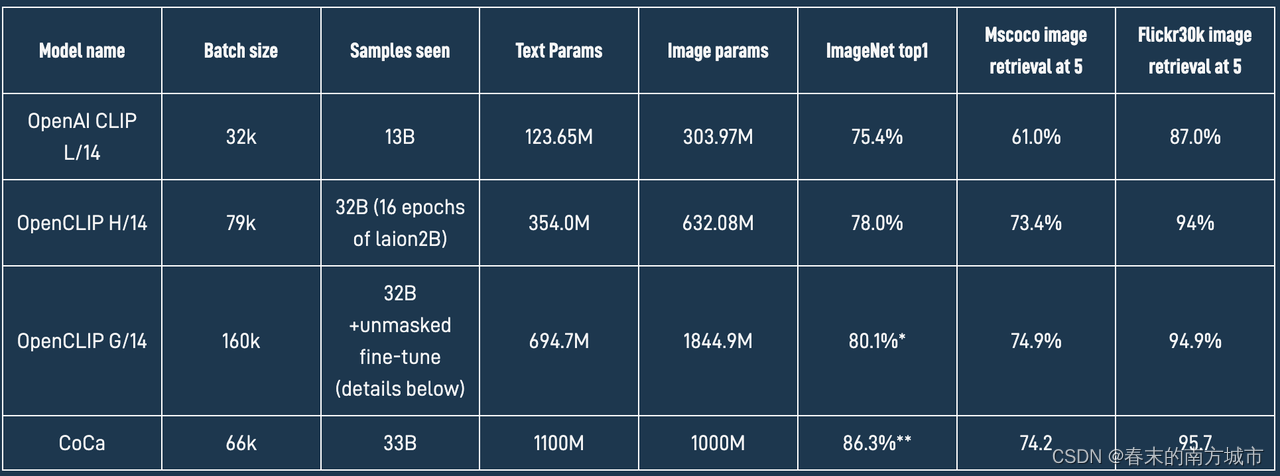
CLIP 使计算图像和文本的表示形式以测量它们的相似程度成为可能。CLIP 模型以自我监督的方式在数亿或数十亿图像-文本对上进行训练。例如:LAION-5B 数据集,包含 58 亿个密切相关的图像-文本对。2022 年 9 月,LAION机构利用这个数据集的 OpenCLIP 项目,对CLIP论文完成了开源实现即OpenCLIP。在 ImageNet数据集上,原版OpenAI CLIP的准确率只有75.4%,而OpenCLIP实现了80.1% 的zero-shot准确率,在 MS COCO 上实现了74.9% 的zero-shot图像检索(Recall@5),这也是目前性能最强的开源 CLIP 模型。
2022年11月,OpenAI发布了Stable Diffusion 2.0。与最初的v1版本相比,Stable Diffusion 2.0版本使用全新的文本编码器(OpenCLIP)训练文本到图像模型,这大大提高了生成图像的质量。与SD 1.0中所使用的含有630万文本模型参数的ClipText相比,OpenCLIP文本模型参数多达3.54亿。此版本的文生图模型可以生成默认分辨率为512x512像素以及768x768像素的图像。此外,该模型在LAION-Aesthetics(LAION-5B的美学子集)进行训练。与v1版本不同的是,v2版本使用LAION的NSFW(色情和性内容过滤器)过滤掉了数据集中的成人内容。
相关资料
OpenCLIP源码地址:GitHub - mlfoundations/open_clip: An open source implementation of CLIP.
官网介绍:https://laion.ai/blog/giant-openclip/
原理
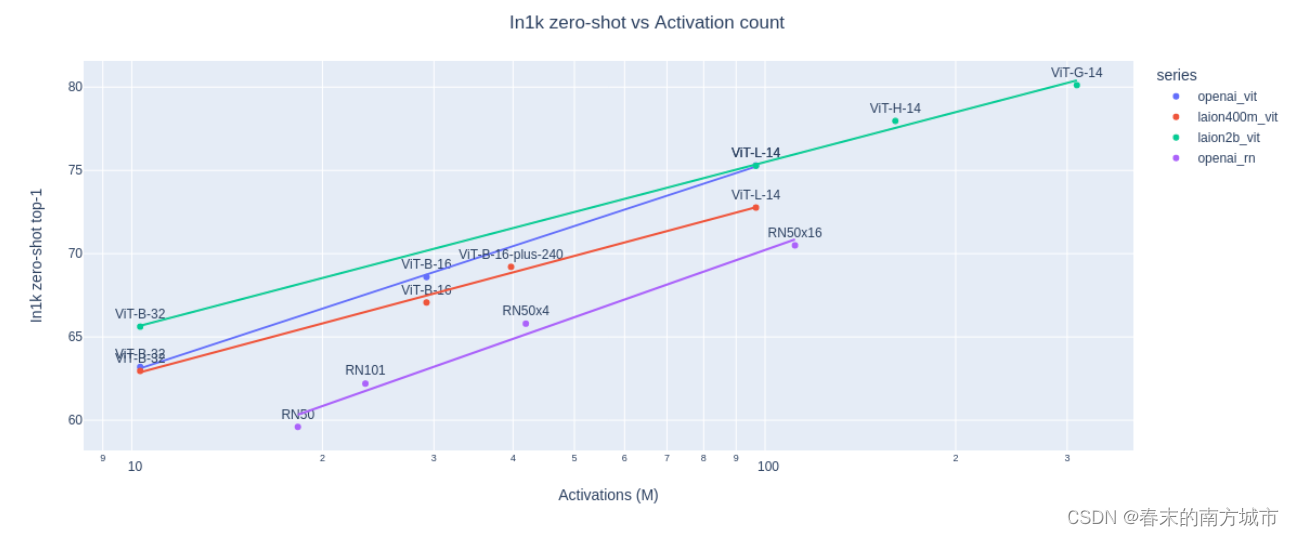
LAION 使用 OpenCLIP 训练了三个大型 CLIP 模型:ViT-L/14、ViT-H/14 和 ViT-g/14(与其他模型相比,ViT-g/14 的训练周期仅为三分之一左右),并在其官方网站上称它自己是当年开源 CLIP 模型之最佳,OpenCLIP原理和CLIP一样,只是在不同数据集上的实现,如下图所示:
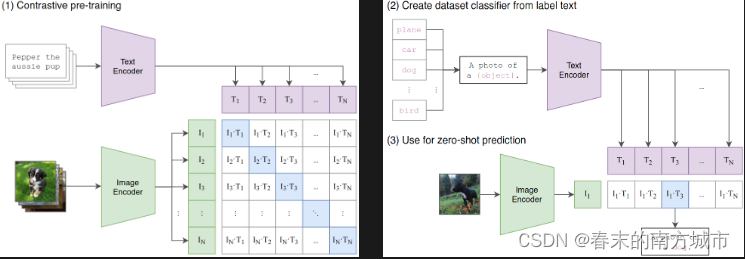
结果
用法
pip install open_clip_torchimport torch from PIL
import Image
import open_clip model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')
tokenizer = open_clip.get_tokenizer('ViT-B-32') image = preprocess(Image.open("CLIP.png")).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"]) with torch.no_grad(), torch.cuda.amp.autocast(): image_features = model.encode_image(image) text_features = model.encode_text(text) image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1) print("Label probs:", text_probs) # prints: [[1., 0., 0.]]模型总结
-
二者都是OpenAI公司开发的,CLIP是2021年初发布,是多模态研究领域的经典之作,在多任务表现上达到了SOTA 。2022年9月发布OpenCLIP,包含三个大规模CLIP模型:ViT-L/14, ViT-H/14 和ViT-g/14。
-
CLIP是指CLIP模型本身,而OpenCLIP则是指CLIP模型的开源实现。两者有着紧密的联系,OpenCLIP是对CLIP模型的应用和推广,使更多的人可以使用CLIP模型进行相关的研究和开发。
-
CLIP利用4亿张互联网上找到的图片对应的Alternative文字训练的多模态模型。OpenCLIP在 LAION-5B的美学子集进行训练。与v1版本不同的是,v2版本使用LAION的NSFW过滤掉了数据集中的成人内容。
-
Stable Diffusion 1.0中所使用ClipText的含有630万文本模型参数。Stable Diffusion 2.0版本使用的OpenCLIP文本模型参数多达3.54亿。
-
使用OpenCLIP版本的SD2.0文生图模型可以生成默认分辨率为512x512像素以及768x768像素的图像,而使用CLIP版本的SD1.0文生图模型只能生成默认分辨率为512x512像素的图像。