0 引言
论文地址:https://arxiv.org/abs/1706.03762
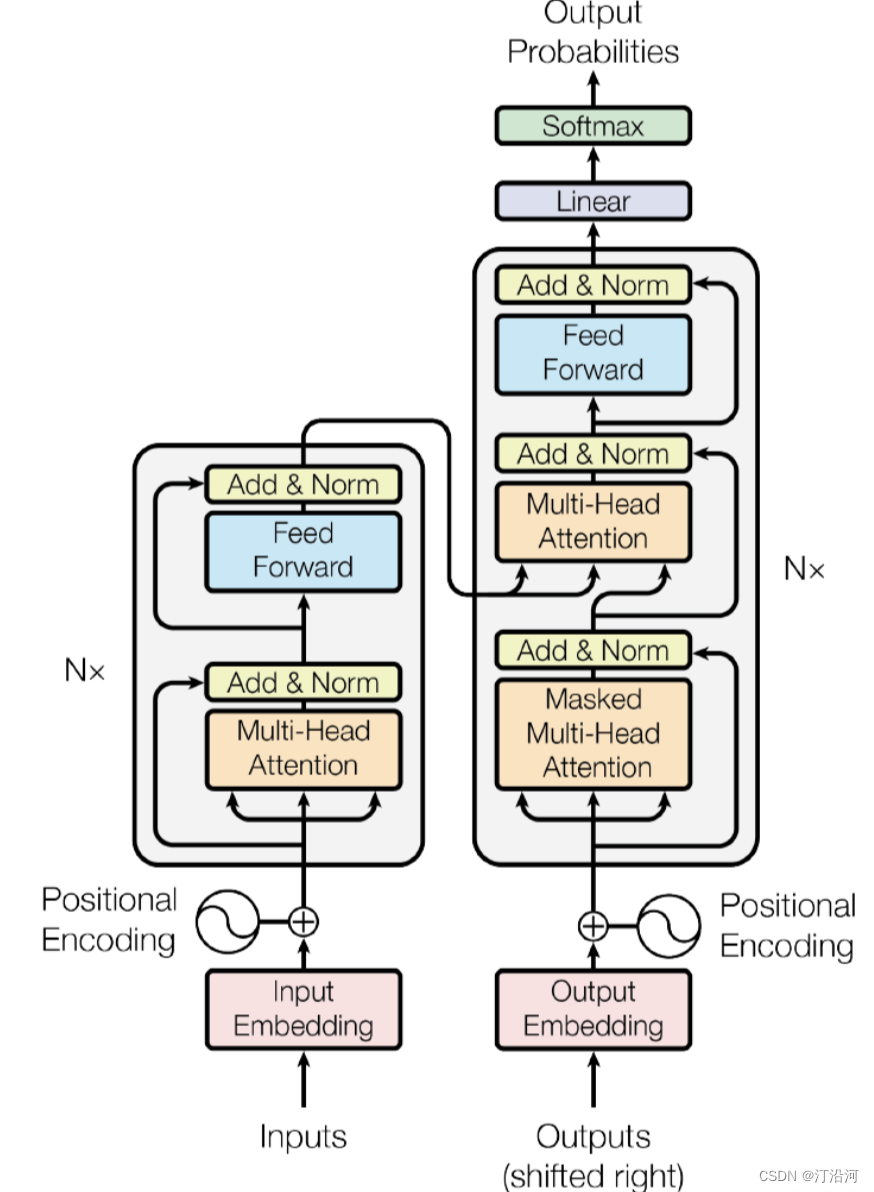
1 Transformer
Transformer 模型是一种用于处理序列数据的深度学习模型,主要用于解决自然语言处理(NLP)任务。它在许多 NLP 任务中取得了重大突破,如机器翻译、文本摘要、语言生成、问答系统等。
Transformer 模型的主要优势在于能够捕捉长距离依赖关系,而不需要使用递归或卷积等传统的序列模型。它引入了自注意力机制(self-attention),使得模型可以同时考虑输入序列中的所有位置,从而更好地理解上下文关系。
Transformer 模型还具有可并行计算的能力,因为它可以在整个序列上进行并行计算,而不需要按顺序处理每个位置。这使得 Transformer 在处理大规模数据时具有较高的效率。
除了 NLP 任务,Transformer 模型还可以应用于其他序列数据的建模和处理,如音频处理、时间序列预测等。它的灵活性使得它成为处理序列数据的重要工具之一。
Transformer 模型是一种基于自注意力机制(self-attention)的深度学习模型,用于处理序列数据。它最大的特点是:
1. 自注意力机制:Transformer 引入了自注意力机制,使得模型可以在处理序列时同时考虑输入序列中的所有位置。传统的序列模型通常使用固定的窗口或滑动窗口来捕捉上下文关系,而自注意力机制可以根据输入序列的不同部分自动调整权重,更好地捕捉长距离的依赖关系。
2. 并行计算:Transformer 模型可以在整个序列上进行并行计算,而不需要按顺序处理每个位置。这是由于自注意力机制的特性,每个位置的表示可以同时考虑整个序列的信息。这使得 Transformer 在处理大规模数据时具有较高的效率。
3. 编码器-解码器结构:Transformer 模型通常由编码器和解码器组成。编码器用于将输入序列编码为一系列表示,而解码器则根据编码器的输出和之前的预测生成输出序列。这种结构在机器翻译等任务中表现出色。
4. 多头注意力机制:Transformer 模型还引入了多头注意力机制,允许模型在不同的表示子空间中学习多个不同的注意力表示。这有助于模型更好地捕捉不同类型的关系和特征。
总的来说,Transformer 模型的最大特点是其能够处理长距离依赖关系、并行计算能力强、具有多头注意力机制等特性,使其成为处理序列数据的重要模型。
本文提出使用LSTM结合Transformer的结构提取数据信息,尝试预测。由于数据集与计算能力有限并不能很好的拟合。
数据集: https://download.csdn.net/download/qq_28611929/88573481?spm=1001.2014.3001.5503![]() https://download.csdn.net/download/qq_28611929/88573481?spm=1001.2014.3001.5503
https://download.csdn.net/download/qq_28611929/88573481?spm=1001.2014.3001.5503
2 pytorch模块介绍
```python
class torch.nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=2048, dropout=0.1, activation='relu')
```- `d_model`:输入和输出的特征维度(隐藏单元数)。
- `nhead`:多头注意力机制中的头数。
- `dim_feedforward`:前馈神经网络中间层的维度。
- `dropout`:Dropout 层的丢弃率。
- `activation`:激活函数的类型,默认为 ReLU。`nn.TransformerEncoderLayer` 的输入和输出形状如下:
输入形状:(序列长度, 批量大小, 特征维度) 或 (批量大小, 序列长度, 特征维度)。
输出形状:与输入形状相同。
注意,输入和输出的维度顺序取决于是否设置了 `batch_first=True`。如果设置了 `batch_first=True`,则输入和输出的维度顺序为 (批量大小, 序列长度, 特征维度)。否则,维度顺序为 (序列长度, 批量大小, 特征维度)。
```python
class torch.nn.TransformerEncoder(encoder_layer, num_layers, norm=None)
```- `encoder_layer`:一个 `nn.Module` 对象,表示 Transformer 编码器层。可以使用 `nn.TransformerEncoderLayer` 创建。
- `num_layers`:编码器层的数量。
- `norm`:可选的归一化层,用于对每个编码器层的输出进行归一化处理。`nn.TransformerEncoder` 的输入和输出形状如下:
输入形状:(序列长度, 批量大小, 特征维度) 或 (批量大小, 序列长度, 特征维度)。
输出形状:与输入形状相同。
请注意,输入和输出的维度顺序取决于是否设置了 `batch_first=True`。如果设置了 `batch_first=True`,则输入和输出的维度顺序为 (批量大小, 序列长度, 特征维度)。否则,维度顺序为 (序列长度, 批量大小, 特征维度)。
map: 输入输出的维度相同,就想做了一个转换,我的躯体还是我,只是灵魂变了;
y. = TransformerEncoder(input)
input (批量大小, 序列长度, 特征维度)
y (批量大小, 序列长度, 特征维度)
2.1 使用transformer的encoder模块
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.nn.utils import weight_norm
#import tushare as ts
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from torch.utils.data import TensorDataset
from tqdm import tqdm
from sklearn.model_selection import train_test_splitimport matplotlib.pyplot as plt
import sys
import os
import gc
import argparse
import warningswarnings.filterwarnings('ignore')class Config():data_path = '../data/data1/train/power.csv'timestep = 18 # 时间步长,就是利用多少时间窗口batch_size = 32 # 批次大小feature_size = 1 # 每个步长对应的特征数量,这里只使用1维,hidden_size = 64num_heads = 4output_size = 1 # 由于是单卷机和输出任务,最终输出层大小为1num_layers = 2 # lstm的层数epochs = 10 # 迭代轮数best_loss = 0 # 记录损失learning_rate = 0.003 # 学习率model_name = 'transformer' # 模型名称save_path = './{}.pth'.format(model_name) # 最优模型保存路径config = Config()# 读取数据
train_power_forecast_history = pd.read_csv('../data/data1/train/power_forecast_history.csv')
train_power = pd.read_csv('../data/data1/train/power.csv')
train_stub_info = pd.read_csv('../data/data1/train/stub_info.csv')test_power_forecast_history = pd.read_csv('../data/data1/test/power_forecast_history.csv')
test_stub_info = pd.read_csv('../data/data1/test/stub_info.csv')# 聚合数据
train_df = train_power_forecast_history.groupby(['id_encode','ds']).head(1)
del train_df['hour']test_df = test_power_forecast_history.groupby(['id_encode','ds']).head(1)
del test_df['hour']tmp_df = train_power.groupby(['id_encode','ds'])['power'].sum()
tmp_df.columns = ['id_encode','ds','power']# 合并充电量数据
train_df = train_df.merge(tmp_df, on=['id_encode','ds'], how='left')### 合并数据
train_df = train_df.merge(train_stub_info, on='id_encode', how='left')
test_df = test_df.merge(test_stub_info, on='id_encode', how='left')h3_code = pd.read_csv("../data/h3_lon_lat.csv")
train_df = train_df.merge(h3_code,on='h3')
test_df = test_df.merge(h3_code,on='h3')# 卡尔曼平滑
def kalman_filter(data, q=0.0001, r=0.01):# 后验初始值x0 = data[0] # 令第一个估计值,为当前值p0 = 1.0# 存结果的列表x = [x0]for z in data[1:]: # kalman 滤波实时计算,只要知道当前值z就能计算出估计值(后验值)x0# 先验值x1_minus = x0 # X(k|k-1) = AX(k-1|k-1) + BU(k) + W(k), A=1,BU(k) = 0p1_minus = p0 + q # P(k|k-1) = AP(k-1|k-1)A' + Q(k), A=1# 更新K和后验值k1 = p1_minus / (p1_minus + r) # Kg(k)=P(k|k-1)H'/[HP(k|k-1)H' + R], H=1x0 = x1_minus + k1 * (z - x1_minus) # X(k|k) = X(k|k-1) + Kg(k)[Z(k) - HX(k|k-1)], H=1p0 = (1 - k1) * p1_minus # P(k|k) = (1 - Kg(k)H)P(k|k-1), H=1x.append(x0) # 由输入的当前值z 得到估计值x0存入列表中,并开始循环到下一个值return x#kalman_filter()
train_df['new_label'] = 0
for i in range(500):#print(i)label = i#train_df[train_df['id_encode']==labe]['power'].valuestrain_df.loc[train_df['id_encode']==label, 'new_label'] = kalman_filter(data=train_df[train_df['id_encode']==label]['power'].values)### 数据预处理
train_df['flag'] = train_df['flag'].map({'A':0,'B':1})
test_df['flag'] = test_df['flag'].map({'A':0,'B':1})def get_time_feature(df, col):df_copy = df.copy()prefix = col + "_"df_copy['new_'+col] = df_copy[col].astype(str)col = 'new_'+coldf_copy[col] = pd.to_datetime(df_copy[col], format='%Y%m%d')#df_copy[prefix + 'year'] = df_copy[col].dt.yeardf_copy[prefix + 'month'] = df_copy[col].dt.monthdf_copy[prefix + 'day'] = df_copy[col].dt.day# df_copy[prefix + 'weekofyear'] = df_copy[col].dt.weekofyeardf_copy[prefix + 'dayofweek'] = df_copy[col].dt.dayofweek# df_copy[prefix + 'is_wknd'] = df_copy[col].dt.dayofweek // 6df_copy[prefix + 'quarter'] = df_copy[col].dt.quarter# df_copy[prefix + 'is_month_start'] = df_copy[col].dt.is_month_start.astype(int)# df_copy[prefix + 'is_month_end'] = df_copy[col].dt.is_month_end.astype(int)del df_copy[col]return df_copytrain_df = get_time_feature(train_df, 'ds')
test_df = get_time_feature(test_df, 'ds')train_df = train_df.fillna(999)
test_df = test_df.fillna(999)cols = [f for f in train_df.columns if f not in ['ds','power','h3','new_label']]scaler = MinMaxScaler(feature_range=(0,1))
scalar_falg = False
if scalar_falg == True:df_for_training_scaled = scaler.fit_transform(train_df[cols+['new_label']])df_for_testing_scaled= scaler.transform(test_df[cols])
else:df_for_training_scaled = train_df[cols+['new_label']]df_for_testing_scaled = test_df[cols]
#df_for_training_scaled
# scaler_label = MinMaxScaler(feature_range=(0,1))
# label_for_training_scaled = scaler_label.fit_transform(train_df['new_label']..values)
# label_for_testing_scaled= scaler_label.transform(train_df['new_label'].values)
# #df_for_training_scaled#x_train, x_test, y_train, y_test = train_test_split(df_for_training_scaled.values, train_df['new_label'].values,shuffle=False, test_size=0.2)
x_train_list = []
y_train_list = []
x_test_list = []
y_test_list = []for i in range(500):temp_df = df_for_training_scaled[df_for_training_scaled.id_encode==i]x_train, x_test, y_train, y_test = train_test_split(temp_df[cols].values, temp_df['new_label'].values,shuffle=False, test_size=0.2)x_train_list.append(x_train)y_train_list.append(y_train)x_test_list.append(x_test)y_test_list.append(y_test)x_train = np.concatenate(x_train_list)
y_train = np.concatenate(y_train_list)x_test = np.concatenate(x_test_list)
y_test = np.concatenate(y_test_list)# 将数据转为tensor
x_train_tensor = torch.from_numpy(x_train.reshape(-1,config.timestep,1)).to(torch.float32)
y_train_tensor = torch.from_numpy(y_train.reshape(-1,1)).to(torch.float32)
x_test_tensor = torch.from_numpy(x_test.reshape(-1,config.timestep,1)).to(torch.float32)
y_test_tensor = torch.from_numpy(y_test.reshape(-1,1)).to(torch.float32)# 5.形成训练数据集
train_data = TensorDataset(x_train_tensor, y_train_tensor)
test_data = TensorDataset(x_test_tensor, y_test_tensor)# 6.将数据加载成迭代器
train_loader = torch.utils.data.DataLoader(train_data,config.batch_size,True)test_loader = torch.utils.data.DataLoader(test_data,config.batch_size,True)class Transformer(nn.Module):# d_model : number of featuresdef __init__(self,feature_size=1,hidden_size=128,num_layers=3,nhead=4,dropout=0.2):super(Transformer, self).__init__()self.lstm = nn.LSTM(feature_size, hidden_size, num_layers, batch_first=True)"""`d_model`:模型的维度,也就是输入和输出的特征维度。`nhead`:注意力头数,控制多头注意力的并行度。"""self.encoder_layer = nn.TransformerEncoderLayer(d_model=hidden_size, nhead=4, dropout=dropout,batch_first=True)self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers,mask_check=False) self.decoder = nn.Linear(hidden_size, 1) #feature_size是input的个数,1为output个数self.init_weights()#init_weight主要是用于设置decoder的参数def init_weights(self):initrange = 0.1 self.decoder.bias.data.zero_()self.decoder.weight.data.uniform_(-initrange, initrange)def _generate_square_subsequent_mask(self, sz):mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))return maskdef forward(self, src, device='cpu'):output, (h0,c0) = self.lstm(src)# output (batch_size, time_stamp, hidden_size)batch_size, time_stamp, hidden_size = output.shape#print(output.reshape (time_stamp,batch_size,hidden_size).shape)#print(output.shape, h0.shape)#mask = self._generate_square_subsequent_mask(len(x)).to(device)mask = None#output = output.reshape(time_stamp,batch_size,hidden_size)output = self.transformer_encoder(output)#print(output.shape)output = self.decoder(output[:,-1,:])return output
model = Transformer(feature_size=config.feature_size,hidden_size=config.hidden_size,nhead=config.num_heads,dropout=0.2)loss_function = nn.MSELoss() # 定义损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) # 定义优化器
# 8.模型训练
for epoch in range(50):model.train()running_loss = 0train_bar = tqdm(train_loader) # 形成进度条for data in train_bar:x_train, y_train = data # 解包迭代器中的X和Yoptimizer.zero_grad()y_train_pred = model(x_train)loss = loss_function(y_train_pred, y_train.reshape(-1, 1))loss.backward()optimizer.step()running_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,config.epochs,loss)# 模型验证model.eval()test_loss = 0with torch.no_grad():test_bar = tqdm(test_loader)for data in test_bar:x_test, y_test = datay_test_pred = model(x_test)test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1))if test_loss < config.best_loss:config.best_loss = test_losstorch.save(model.state_dict(), save_path)print('Finished Training')ref:
Transformer 模型详解_空杯的境界的博客-CSDN博客