💯 博客内容:从零带你实现unordered_map
😀 作 者:陈大大陈
🚀 个人简介:一个正在努力学技术的准C++后端工程师,专注基础和实战分享 ,欢迎私信!
💖 欢迎大家:这里是CSDN,我总结知识和写笔记的地方,喜欢的话请三连,有问题请私信 😘
目录
闭散列/哈希桶 拉链法
开散列图示:
开散列代码:
增容代码:
哈希/散列:映射,关键字和另一个值建立一个关联关系。
哈希表/散列表:映射,关键字和储存位置建立一个关联关系。
哈希/散列是一种算法思想,而哈希表/散列表是基于这种算法思想而实现的一种数据结构,这点很容易混淆。
上一篇博客介绍了两个解决哈希冲突的方法,
1.线性探测 hashi+i (i>=0)
2.二次探测 hashi+i^2 (i>=0)
这两种方法都不算是什么灵丹妙药,还是太慢。
最好的方法是下面这个。
闭散列/哈希桶 拉链法
哈希每一个存的不是唯一的值,而是一个指针数组。
这样一来,key值相同的值都会存到一个指针数组里面,查找就方便了很多。
它的查找直接‘’内部消化‘’,不会影响到别的值。
这样的每一个节点,我们称之为桶。
当一个桶的节点过多时吗,这个桶的存储结构由链表变为红黑树。
平均时间复杂度是O(1)。
当存储的值是string等类型的话,不能直接入表。
要使用仿函数来类型转换。
HashFunc的作用是转成整型值。
直接把字母的ASCII值加起来看行不行。
需要特别注意的是,汉字的ASCII值是负数,存储的时候需要用到特殊的方法。
否则会发生整形提升,简单的两个汉字加起来就能有好几亿。
上篇文章也说过了:
解决哈希冲突 两种常见的方法是:闭散列和开散列
闭散列,也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有
空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
今天咱们就来提提开散列。
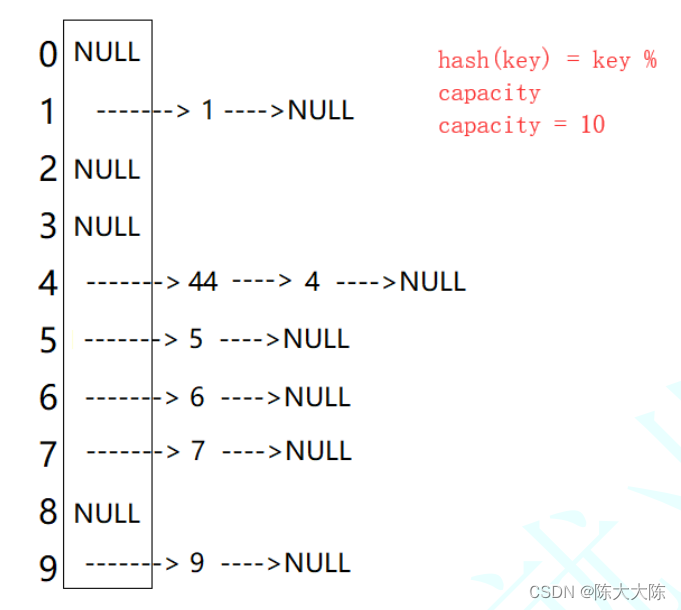
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。
开散列图示:
开散列代码:
#define _CRT_SECURE_NO_WARNINGS
template<class V>
struct HashBucketNode
{HashBucketNode(const V& data): _pNext(nullptr), _data(data){}HashBucketNode<V>* _pNext;V _data;
};
template<class V>
class HashBucket
{typedef HashBucketNode<V> Node;typedef Node* PNode;
public:HashBucket(size_t capacity = 3) : _size(0){_ht.resize(GetNextPrime(capacity), nullptr);}// 哈希桶中的元素不能重复PNode* Insert(const V& data){// 确认是否需要扩容。。。// _CheckCapacity();// 1. 计算元素所在的桶号size_t bucketNo = HashFunc(data);// 2. 检测该元素是否在桶中PNode pCur = _ht[bucketNo];while (pCur){if (pCur->_data == data)return pCur;pCur = pCur->_pNext;}// 3. 插入新元素pCur = new Node(data);pCur->_pNext = _ht[bucketNo];_ht[bucketNo] = pCur;_size++;return pCur;}// 删除哈希桶中为data的元素(data不会重复),返回删除元素的下一个节点PNode* Erase(const V& data){size_t bucketNo = HashFunc(data);PNode pCur = _ht[bucketNo];PNode pPrev = nullptr, pRet = nullptr;while (pCur){if (pCur->_data == data){if (pCur == _ht[bucketNo])_ht[bucketNo] = pCur->_pNext;elsepPrev->_pNext = pCur->_pNext;pRet = pCur->_pNext;delete pCur;_size--;return pRet;}}return nullptr;}PNode* Find(const V& data);size_t Size()const;bool Empty()const;void Clear();bool BucketCount()const;void Swap(HashBucket<V, HF>& ht;~HashBucket();
private:size_t HashFunc(const V& data){return data % _ht.capacity();}
private:vector<PNode*> _ht;size_t _size; //哈希表中有效元素的个数
};桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可
能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希
表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,
再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可
以给哈希表增容。
增容代码:
void _CheckCapacity()
{size_t bucketCount = BucketCount();if(_size == bucketCount){HashBucket<V, HF> newHt(bucketCount);for(size_t bucketIdx = 0; bucketIdx < bucketCount; ++bucketIdx){PNode pCur = _ht[bucketIdx];while(pCur){// 将该节点从原哈希表中拆出来_ht[bucketIdx] = pCur->_pNext;// 将该节点插入到新哈希表中size_t bucketNo = newHt.HashFunc(pCur->_data);pCur->_pNext = newHt._ht[bucketNo];newHt._ht[bucketNo] = pCur;pCur = _ht[bucketIdx];}}newHt._size = _size;this->Swap(newHt);}
}这块东西实在是太多,下篇博客咱们继续实现。


![[栈溢出+参数跟踪] [ZJCTF 2019]Login](https://img-blog.csdnimg.cn/9c051971900c4b38a80e504b5b4b2f94.png)