基本概念
Cluster
集群,一个ES集群是由多个节点(Node)组成的,每个集群都有一个cluster name 作为标识, 在同一网段下的Es实例会通过cluster name 决定加入哪个集群下。
node
节点,一个ES实例就是一个node,一个机器可以有多个实例,所以并不是说一台机器就是一个node,大多数情况下,每个node运行在一个独立的环境或者虚拟机上。
index
索引,即一系列documents的集合
shard
1.分片,ES是分布式搜索引擎,每个索引有一个或多个分片,索引的数据被分配到各个分片上,相当于一桶水 用了N个杯子装
2.分片有助于横向扩展,N个分片会被尽可能平均地(rebalance)分配在不同的节点上(例如你有2个节点,4个主分片(不考虑备份),那么每个节点会分到2个分片,后来你增加了2个节点,那么你这4个节点上都会有1个分片,这个过程叫relocation,ES感知后自动完成)
3.分片是独立的,对于一个Search Request的行为,每个分片都会执行这个Request
4.每个分片都是一个Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519个docs。
replica
1.副本,可以理解为备份分片,相应地有primary shard(主分片)
2.主分片和备分片不会出现在同一个节点上(防止单点故障),默认情况下一个索引创建5个分片一个备份(即5primary+5replica=10个分片)
3.如果你只有一个节点,那么5个replica都无法分配(unassigned),此时cluster status会变成Yellow。
4.为了提升访问压力过大是单机无法处理所有请求的问题,Elasticsearch集群引入了副本策略replica。副本策略对index中的每个分片创建冗余的副本,处理查询时可以把这些副本当做主分片来对待(primary shard),此外副本策略提供了高可用和数据安全的保障,当分片所在的机器宕机,Elasticsearch可以使用其副本进行恢复,从而避免数据丢失。
分片策略
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
水平扩容
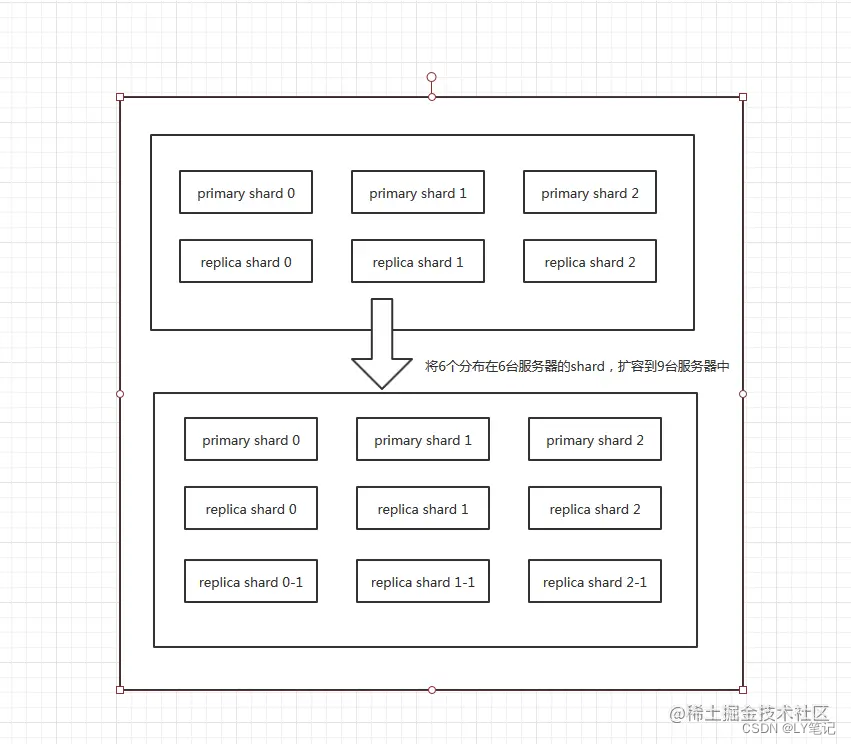
primary shard在索引创建后就无法进行修改,所以需要将6台服务器扩容到9台服务器只能对replica shard进行增加,可以修改索引配置,将replica shard的数量修改为2,此时replica shard的数量变为6个,加上3个primary shard 就是9个 shard
分页查询
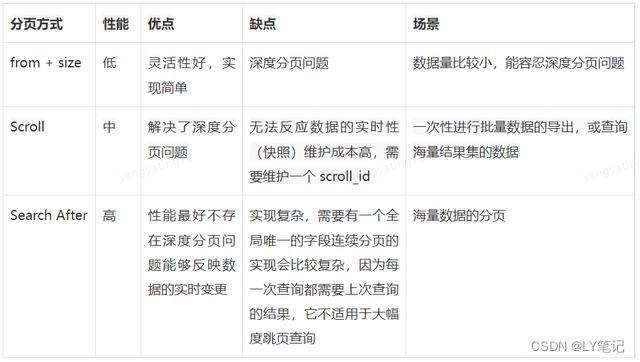
1.from + size 分页方式
第一步:Client 发送查询请求到 Server 端,Node1 接收到请求然后创建一个大小为 from + size 的优先级队列用来存放结果,此时 Node1 被称为 coordinating node(协调节点);
第二步:Node1 将请求广播到涉及的 shard 上,每个 shard 内部执行搜索请求,然后将执行结果存到自己内部的大小同样为 from+size 的优先级队列里;
第三步:每个 shard 将暂存的自身优先级队列里的结果返给 Node1,Node1 拿到所有 shard返回的结果后,对结果进行一次合并,产生一个全局的优先级队列,存在 Node1 的优先级队列中。(如上图中,Node1 会拿到 (from +size) * 6 条数据,这些数据只包含 doc 的唯一标识_id 和用于排序的_score,然后 Node1 会对这些数据合并排序,选择前 from + size 条数据存到优先级队列);
Scroll 分页方式
scroll 分页方式类似关系型数据库中的cursor(游标),首次查询时会生成并缓存快照,返回给客户端快照读取的位置参数(scroll_id),后续每次请求都会通过 scroll_id 访问快照实现快速查询需要的数据,有效降低查询和存储的性能损耗。
scroll 分页方式的优点就是减少了查询和排序的次数,避免性能损耗。缺点就是只能实现上一页、下一页的翻页功能,不兼容通过页码查询数据的跳页,同时由于其在搜索初始化阶段会生成快照,后续数据的变化无法及时体现在查询结果,因此更加适合一次性批量查询或非实时数据的分页查询。
Search After 分页方式
使用search_after 进行分页 相比 from & size 的方式要更加高效,而且在不断有新数据入库的时候仅仅使用 from 和 size 分页会有重复的情况,相比使用 scroll 分页,search_after 可以进行实时的查询,不过 search_after不适合跳跃式的分页。
使用 search_after 类比 SQL,相当于 SELECT * FROM shopping WHERE num > before_max_num ORDER BY num ASC LIMIT 10
对比