背景
收到一批数据,数据形式。采集数据的间隔时间是10分钟,全天采集数据,每天的数据量是144条
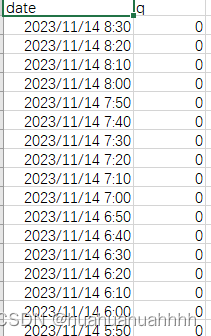
处理后的数据形式
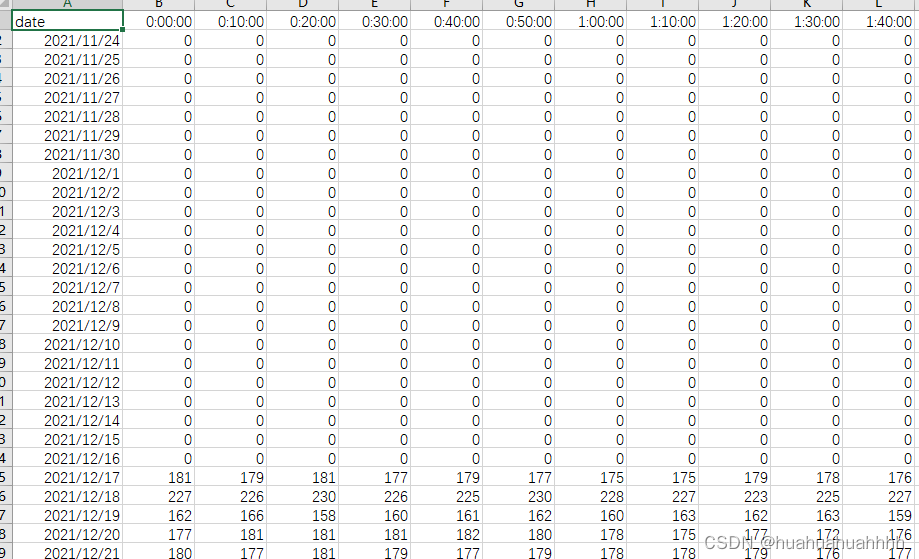
分析
- 去除表格中的
q的异常值,置为0 - 去除重复行
- 将原始表格中的date分裂成日期和时间
- 缺失的时间点数据补0,否则无法将单列数据reshape成二维表的形式
- reshape
df_empty.pivot
代码实现
# coding:utf-8
from tqdm import tqdm
import numpy as np
import pandas as pddef compute_uniq_dates(df):uniq_dates = df['date'].unique()## 取出一天的时间间隔 -- 时间点for uniq_date in uniq_dates:single_info = df[df['date'] == uniq_date]num_data = len(single_info)if num_data == 144:time_sep = single_info['time']breakprint('time_sep \n', time_sep)return uniq_dates,time_sepdef concate_dates(df,uniq_dates,time_sep):count = 0miss_date = [] ## 缺数据的日期## 建立空表,拼接每天的结果df_empty = pd.DataFrame(columns=['date', 'time', 'q']) ## 保存最后的结果## 有哪些天有缺失数据,分别缺了过少条for uniq_date in tqdm(uniq_dates):single_info = df[df['date'] == uniq_date]num_data = len(single_info)## 判断原始表格中这天的数据是否完整,不完整补齐,多了去掉## 完整直接使用原始表格中的数据if num_data != 144:if num_data < 144:miss_date.append(uniq_date)else: ## > 144条的print('duplicate uniq_date', uniq_date)count += 1## temp_df 保存当天的数据。如果原始表格中有数据,用原始表格中数据;# 如果原始表格中没有数据,用0代替temp_df = {'date': pd.Series(np.array([uniq_date for i in range(len(time_sep))])),'time': pd.Series(np.array(time_sep.tolist())),'q': pd.Series(np.array([0. for i in range(len(time_sep))]))} # 没有设置index的Seriestemp_df = pd.DataFrame(temp_df, columns=['date', 'time', 'q'])## 不够的补齐数据for sample_time in time_sep: ## 时间点 8:00try:## 取出原始表格中 当前日期和时间的q值,并赋值给新表格中相同日期和时间点## 如果原始表格中无法取出这个数据,说明这个数据丢失,使用temp_df在定义时的0代替actual_val = single_info.loc[(single_info['date'] == uniq_date) & (single_info['time'] == sample_time), 'q'].values.tolist()[0]temp_df.loc[(temp_df['date'] == uniq_date) & (temp_df['time'] == sample_time), 'q'] = float(actual_val)except: ## 表示时间点不存在,维持0continue## 当原始数据中同一个时间点有两个数据,且数据不相等时,新表和旧表的同一天的q值的和不同## 此部分用于找出原始数据中的问题数据if True:if int(single_info['q'].sum()) != int(temp_df['q'].sum()):print(single_info['q'].sum())print(temp_df['q'].sum())print('uniq_date,sample_time unequal sum', uniq_date, sample_time)# exit()## 一天天地去拼接数据df_empty = pd.concat([df_empty, temp_df], axis=0)else:df_empty = pd.concat([df_empty, single_info], axis=0)return df_empty,miss_datedef parse_df(df,save_path):print('processing ......')df['time'] = pd.to_datetime(df['date']).dt.timedf['date'] = pd.to_datetime(df['date']).dt.date# 去除重复行df = df.drop_duplicates()## 去掉异常值df_new = df[df['q'] > 10]df = df_new[df_new['q'] < 600]# # 使用duplicated()函数找出重复行# duplicate_rows = df[df.duplicated()]## 采的数据日期和时间点uniq_dates, time_sep = compute_uniq_dates(df)df_empty,miss_date = concate_dates(df,uniq_dates,time_sep)print('df_empty\n', df_empty)# 重新排列表格成目标形式# df = df_empty.pivot(index='time', columns='date', values='q').fillna(0)df = df_empty.pivot(index='date', columns='time', values='q').fillna(0)# 重置索引df = df.reset_index()## 保存结果df.to_csv(save_path, index=False)fw = open('miss_date.txt', 'w')for da in miss_date:line = da.strftime('%Y-%m-%d') + '\n'fw.write(line)print('miss date', miss_date)exit()
if __name__ =='__main__':csv_path = 'temp.csv'save_path = 'output.csv'df = pd.read_csv(csv_path, encoding='utf-8')parse_df(df,save_path)
遇到的问题
- 无法打开文件
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
解决办法:用记事本打开csv文件,更改编码方式是TUTF-8 - 如何取出原始表格中的日期和时间
df['time'] = pd.to_datetime(df['date']).dt.time
df['date'] = pd.to_datetime(df['date']).dt.date ## 覆盖原始的date
- 如何取出原始表格中指定日期和时间的q值,并更新到新表格中
使用loc取出数据,原始数据中存在一个时间点多个数据,且数据不相同,无法用duplicate去掉,这里取的第一个值
# 取出原始表格中 当前日期和时间的q值,并赋值给新表格中相同日期和时间点
## 如果原始表格中无法取出这个数据,说明这个数据丢失,使用temp_df在定义时的0代替
actual_val = single_info.loc[(single_info['date'] == uniq_date) & (single_info['time'] == sample_time), 'q'].values.tolist()[0]
temp_df.loc[(temp_df['date'] == uniq_date) & (temp_df['time'] == sample_time), 'q'] = float(actual_val)
- 上述处理后,表格的形式为下面的这种形式,如何转成目标形式呢?
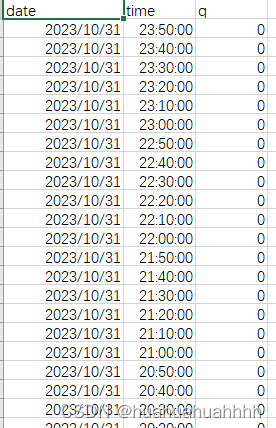
# 重新排列表格成目标形式
## 时间-日期形式
# df = df_empty.pivot(index='time', columns='date', values='q').fillna(0)
## 日期-时间形式
df = df_empty.pivot(index='date', columns='time', values='q').fillna(0)
# 重置索引
df = df.reset_index()



![14.Tomcat和HTTP协议-[一篇通]](img/doge.jpg)