背景
系统设计之初,每次来新请求,业务层会先查询数据库,判断是否存在相同的id数据(id是唯一标识产品的),有则返回当前数据库查到的数据,根据数据决定下一步动作,没有则认为是初次请求,将数据存入数据库,执行另一个操作。结果最近出现了并发情况下数据库产生了多条重复的数据。这里记录一下相关的思考与解决。
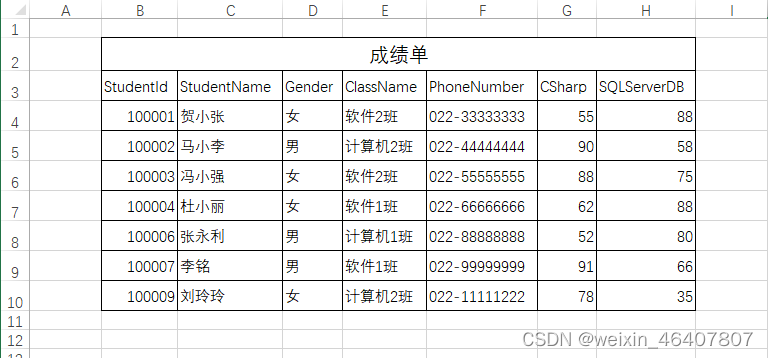
一. 查询数据库有哪些重复记录
方法1—使用group by 和 having子句
原理就是:将待查询列进行分组,并计算出每个分组中的行数,然后使用having子句筛选出大于1的分组返回结果。即为重复的数据列和重复次数。
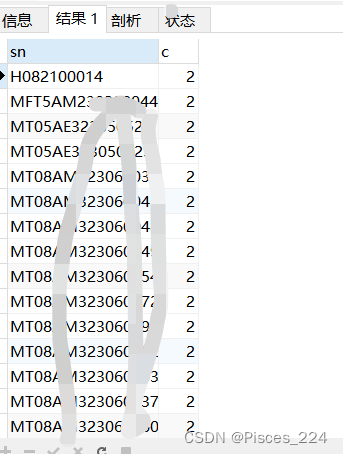
举例子:查询表中重复的 sn 号列数据
select sn, count(*) as c from device_active_info group by sn having c>1;
结果:
方法2:使用子查询和 join 查询
方法1我只查询出了重复列字段和重复次数,那么我想查询重复的列对应的整行数据呢?
语法如下:(子查询和join表连接)
select t1.* from device_active_info t1 join (select sn, count(*) as c from device_active_info group by sn having c>1) t2 on t1.sn = t2.sn
结果就可以得到重复列的所有详细数据。
2. 为什么会产生重复记录?
按照常理来说,事务的ACID特性会保证事务的一致性。但是这里是因为:执行事务A的过程中,先查询 sn,不存在再执行插入;因为时间相对较长,事务A执行完操作尚未提交时,事务B也进来执行操作,当查询数据库中是否存在数据sn时,此时同样未查询到,因此两个事务都提交完毕后,就出现了两条sn相同的重复记录。
那么为什么会这样?加@Transactional 注解还不够吗?
不够。
3. 解决方法
方案1 给字段设置唯一索引或联合主键
这样,当插入重复数据时会发生异常,也就不会产生这个问题了。
举例子:我使用navicat给s字段添加unique唯一性约束。

方案2 使用synchronized 关键字且其作用域包含 proxy事务
这里注意我说的字眼,因为spring事务是基于AOP的,
1. Synchronized在事务注解@Transactional 标注的方法内或方法上
这种情况下锁是失效的。
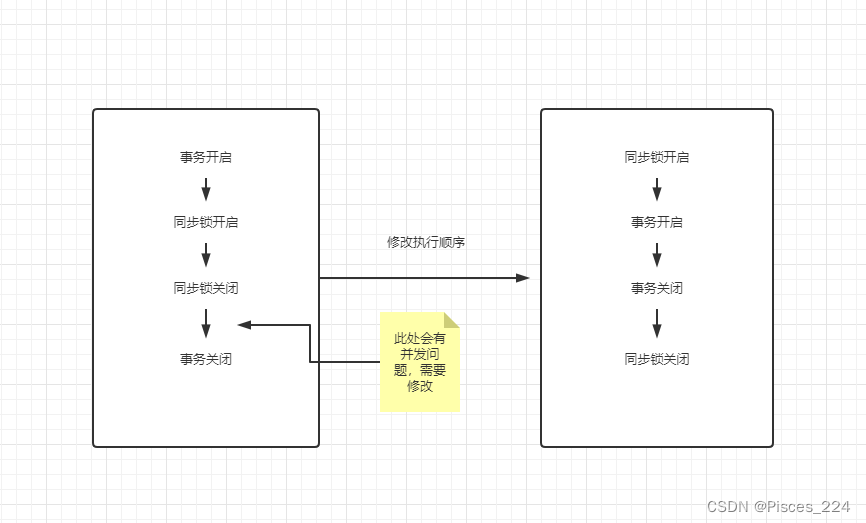
@Transactional注解实现事务的功能是通过aop的方式实现的,在Synchronized锁生效之前就开启了事务,然后锁关闭,最后再提交事务,在高并发的情况下,存在同步锁关闭,但是事务还未提交,新的线程已经重新获取了同步锁,
数据库数据此时还未更新,新线程读到的数据是旧数据。导致Synchronized同步不生效问题
解决方法:
需要在事务开启之前开启同步锁。可以将Synchronized放置在调用事务函数之前。
2. Synchronized关键字同步的方法、代码块包含@Transactional事务
这种情况下是可以实现数据唯一的。
我们可以新建一个类,写一个synchronized方法然后内部调用要执行的事务方法。
public Synchronized void doTransaction(sn) {testService.add(sn);
}
---@Override
@transactional
public void add(String sn) {
// 有则更新或不变;无则新增插入数据库
}MySQL 在写入数据时,可能会出现写入两条相同记录的情况,
原因如下:
重复插入:在插入数据时,如果使用的是 INSERT INTO 语句,但没有设置主键或唯一索引,那么可能会出现重复插入相同数据的情况。这时候,MySQL 不会报错,而是直接插入数据。
多线程写入:如果有多个线程同时写入相同的数据,那么就可能会出现写入两条相同的记录的情况。这种情况下,需要使用事务来保证数据的一致性。
主从同步:在主从复制的环境下,如果主库写入了一条数据,但是还没有同步到从库,而此时主库又写入了一条相同的数据,那么就会出现写入两条相同的记录的情况。
为了避免写入两条相同的记录,可以采取以下措施:
设置主键或唯一索引,避免重复插入相同的数据。
使用事务来保证数据的一致性,避免多线程同时写入相同的数据。
在主从复制的环境下,可以采用延迟复制或者增加从库的数量来提高同步速度,避免写入两条相同的记录。