本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下:
神经网络和深度学习 - 网易云课堂
也欢迎对神经网络与深度学习感兴趣的网友一起交流 ~
在训练神经网络时,我们需要做出很多决策,例如神经网络分多少层、每层含有多少隐藏单元、学习率是多少、各层采用哪些激活函数。

当构建新的深度学习应用时,我们不可能从一开始就准确预测出这些信息,以及其他超参数。
实际上,应用深度学习是一个经验性、高度迭代的过程。人们通常从一个初始想法开始,然后编写代码,并尝试运行代码,通过运行和测试得到神经网络的运行结果,然后根据运行结果,调整策略,多次循环不断完善神经网络。创建高质量的训练集、验证集与测试集,有助于提高迭代效率。

对于数据集,人们通常会将这些数据划分成几部分,一部分作为训练集(Training set),一部分作为验证集(Development set),最后一部分则作为测试集(Test set)。
训练集用于执行训练算法,验证集用于检验算法,选择最好的模型。经过充分验证,选定了最终模型后,就可以在测试集上进行评估了。测试集的主要目的是评估模型的性能。
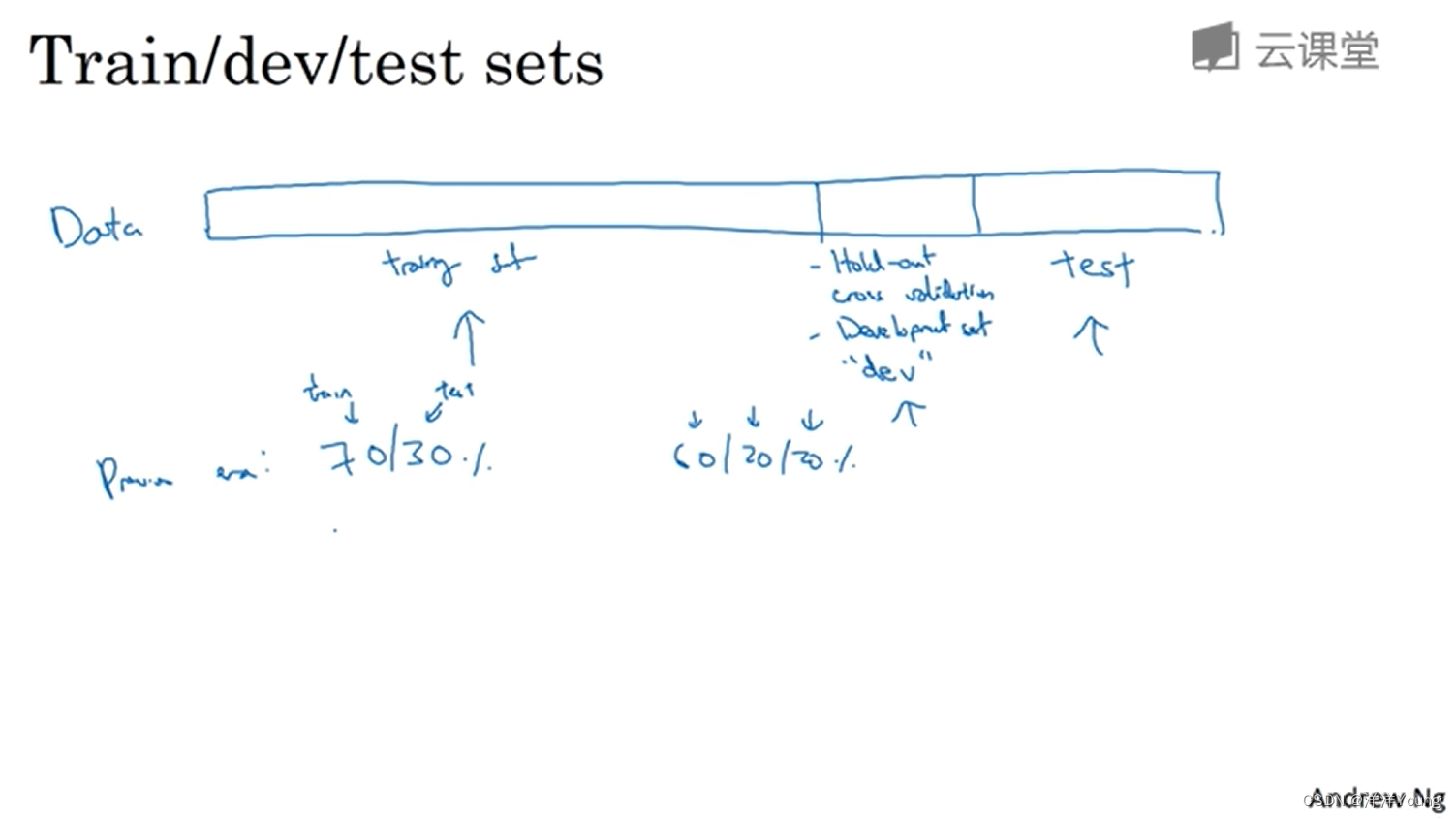
在”小数据“时代,数据集划分的常见做法是将所有数据七三分,即训练集与测试集的数据分别占 70%,30%(没有验证集);或者训练 / 验证 / 测试集数据分别占 60%,20%,20%。
当数据量小于 10000 时,上述的划分方法是合理的。但是在”大数据“时代,数据量可能是百万级别,那么验证集和测试集占数据总量的比例会趋向于变得更小。
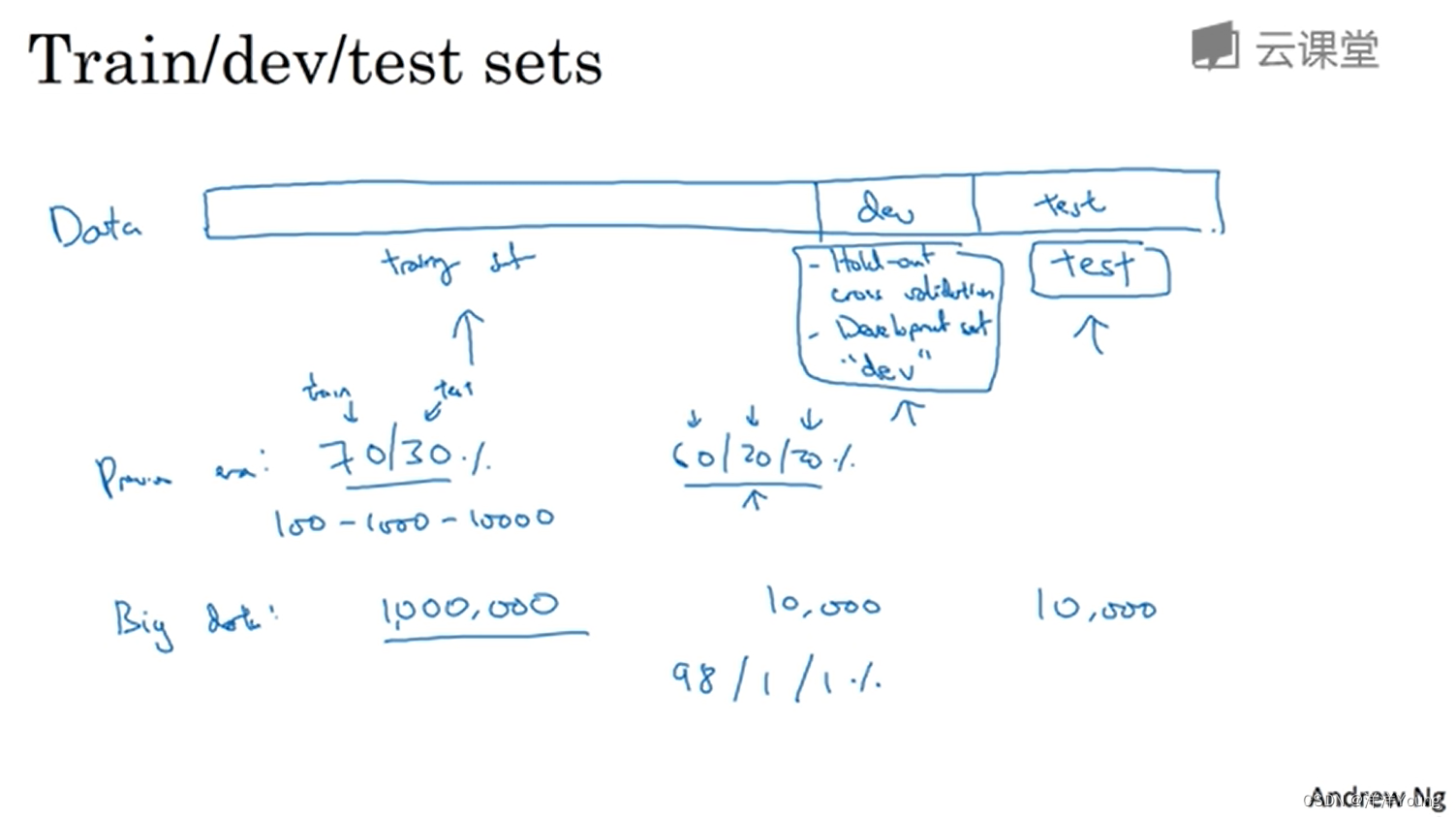
例如在 100 万个数据中,验证集和测试集各需要 10000 个,那么训练集训练集数据就有 98 万,训练 / 验证 / 测试集数据分别占 98%,1%,1%。

最后,要确保验证集和测试集来自同一分布。有时候没有测试集也是可以的, 这时验证集一部分作用是充当测试集,所以也叫验证测试集。