前言
Amazon Aurora是亚马逊云科技自研的云原生关系数据库,它在提供和开源数据库MySQL、PostgreSQL的完好兼容性同时,也能够提供和商业数据库媲美的性能和可用性。
Aurora的性能提升不仅包含应用读写吞吐量的提升,也包含复制延迟的降低。一个Aurora集群包含1个写节点和多达15个读节点。在写节点和读节点之间的数据传输机制上,Aurora创新性地使用Redo Log传输来实现。Aurora的架构是计算存储分离,写和读节点共享存储,在写节点处理写请求时,会将Redo Log传送给存储系统,同时也会传送给读节点。读节点在收到Redo Log后,会判断Redo Log所修改的数据页是否在自己当前的缓冲区中:如果存在,可以按照一定逻辑将Redo Log应用到对应数据页上;如果不存在,可以直接忽略掉这部分Redo Log,后续需要时可以直接去共享存储中读取数据页。Redo Log的传输使得数据传输量相比传统的Binlog大幅降低,再加上读节点应用Redo Log的简洁处理逻辑,使得Aurora的复制延迟很低,通常在20毫秒以内。相应处理逻辑如下图所示。
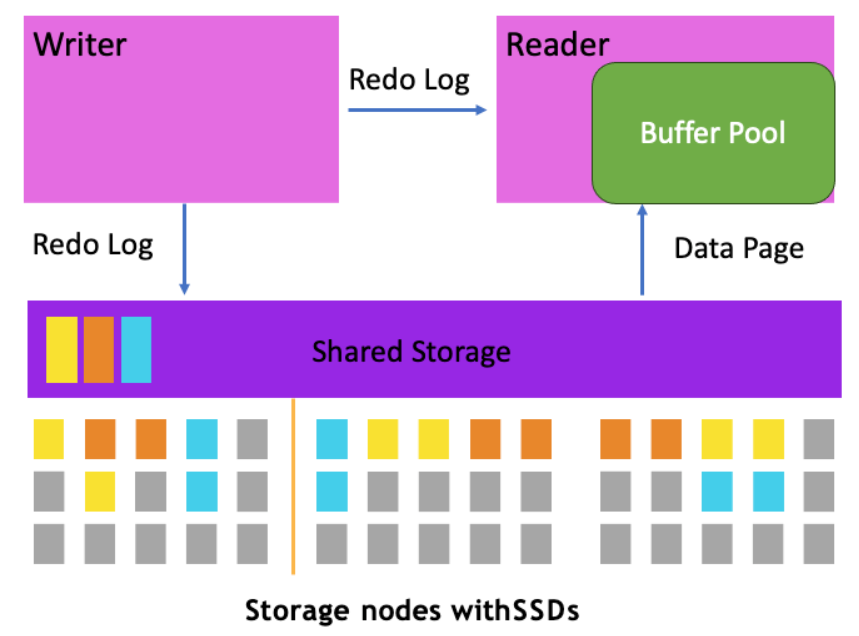
由于低复制延迟和读节点自动伸缩的能力,用户可以将非必须要求强一致的应用分散部署到Aurora不同节点上。高性能、高可用以及良好的扩展性使得Aurora得到用户的喜爱,也一度成为亚马逊云科技用户使用量增幅最快的服务。
因为Aurora本身读写节点是通过Redo Log复制的,如果单纯使用Aurora,是不需要开启Binlog的。但是,用户有时也需要把数据从OLTP数据库中导出,比如去做后续的复杂数据分析等。对于MySQL而言,数据导出最通用的方式便是Binlog。Aurora MySQL与社区MySQL是完好兼容的,所以也支持消费端以Binlog Consumer的方式来将数据持续导出。打开Binlog以及有Binlog Consumer连接都会对MySQL带来性能上的影响,所以Aurora MySQL在Binlog方面不停进行优化,力争减少开启Binlog带来的影响。
本篇聚焦Aurora MySQL在Binlog方面的优化历程,首先会介绍下Binlog的机制,然后会分享下Aurora MySQL的Yield机制和Binlog I/O Cache,最后会重点介绍下Aurora MySQL 3推出的Enhanced Binlog这一新功能以及对应的性能测试情况。
Binlog机制
Binlog是MySQL主从节点同步数据的最常见方式。在主节点开启Binlog后,MySQL会在事务执行过程中记录数据页变更Redo Log的同时,也会记录Binlog,来描述数据在逻辑意义上的修改。Binlog最小的单位为Binlog Event,多个Binlog Event构成一个Binlog文件,一个Binlog文件的大小通常是128MB。对于大事务,Binlog文件大小也可能会超过128MB。Binlog有Row、Statement和Mixed三种不同的格式,可以决定Binlog Event中数据存放的内容,Row表示真实的数据,Statement表示SQL语句,而Mixed是两者的混合,会尽可能采用Statement格式来记录Binlog,在Statement方式在某些场景下可能导致主从不一致的情况下(比如获取当前系统时间),会采用ROW格式来记录Binlog。开启Binlog本身会需要额外的数据处理和刷盘逻辑,会带来一定的性能损。
当有另一个模块需要消费Binlog时,它会以Binlog Consumer的身份连接到主节点。下图展示了另一个MySQL数据库作为Binlog Consumer的情况下主从同步机制的示意图。实际应用中也有可能会是其他流数据处理工具比如Kafka、DMS连接到MySQL主库,MySQL主库的处理逻辑都是相同的。
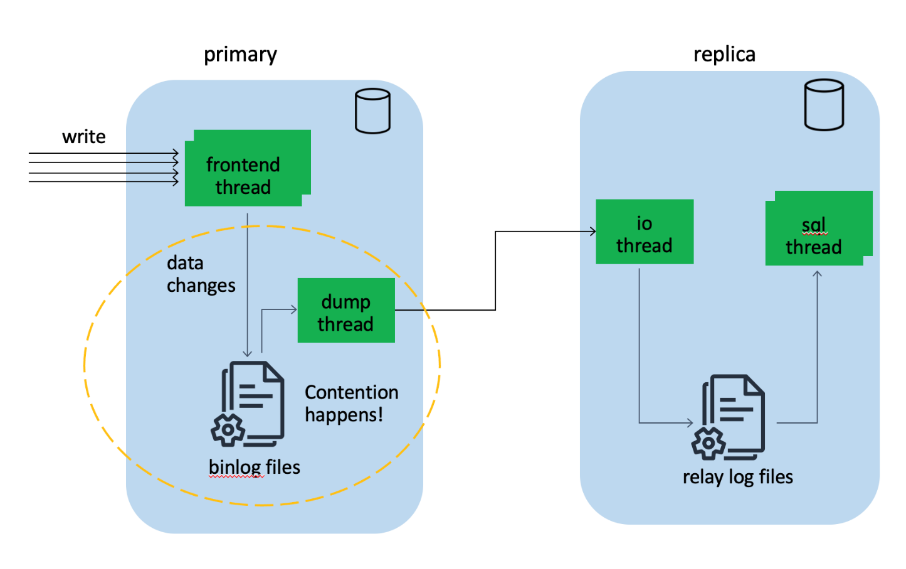
每当有一个副本连接到MySQL主库时,MySQL主库中都会有一个Dump线程专门用来读取Binlog Event,并将Binlog Event通过网络发送给Consumer。如果Binlog Consumer也是MySQL数据库,会有一个专门的IO线程来接收主库传输的数据,并将接收到的Binlog Event存放在Relay Log中。从库MySQL上还会有一个或者多个SQL线程,来读取Relay Log,并将读取到的Binlog Event进行重放,从而使从库得到与主库一致的数据。
主库上因为前端线程在处理用户写入请求时需要将Binlog Event写入到Binlog文件,而Dump线程需要读取Binlog文件,尽管Binlog文件通常以128MB为单位进行存储,当两者操作同一个Binlog文件时,仍然会带来加锁竞争等,所以有Binlog Consumer连接到MySQL主库时会进一步由于锁冲突额外消耗MySQL主库的资源,影响到前端应用程序的返回时延。MySQL支持多个Binlog Consumer同时连接,但每个连接都会有对应的Dump线程来读取Binlog,连接数越多,对主库的性能影响也就越大。
Aurora MySQL的Yield和I/O Cache机制
Aurora MySQL兼容社区版MySQL,在Binlog处理逻辑上尤其是前端线程、Dump线程、IO线程和SQL线程等处理上与社区保持一致,只是将Binlog文件的存储由本地磁盘转到了远程的共享存储上。所以开启Binlog以及有Binlog Consumer连接到Aurora MySQL同样会带来性能的损耗。
Aurora MySQL一直致力于减少由于开启Binlog对Aurora带来的性能影响。在Aurora MySQL 1.17.6和2.04.5版本中提出了Binlog Yield的机制,Aurora MySQL 2.10版本中进一步提出了I/O Cache的机制来减少Binlog竞争冲突。
Binlog Yield的含义是在Dump线程与前端应用对应的线程在操作同一个Binlog文件引发冲突时,让Dump线程Yield等待一段时间,等到等待时间期满或者前端应用线程操作完毕当前Binlog文件,再让Dump线程继续工作。等待时间由变量aurora_binlog_replication_max_yield_seconds控制。Yield的机制能够在发生冲突时优先执行前端应用线程,能够降低对用户应用的响应延迟,但会一定程度上会带来复制延迟的增加。
Binlog I/O Cache顾名思义是单独开辟一块内存缓冲区,用来存放Binlog。前端线程可以将Binlog Event写入到内存缓冲区中,Dump线程可以从内存缓冲区中读取Binlog。在Binlog复制延迟比较低的时候,Dump线程和前端线程的交互可以在内存中完成,而不再需要去远程存储系统中读取并加锁处理,因此提升了Binlog复制传输的性能。
Aurora MySQL 3的Enhanced Binlog
Aurora MySQL 3.03支持的Enhanced Binlog从另一个角度降低了开启Binlog带来的性能损耗。它能将打开binlog对应用程序的影响降低到13%(之前可能最高达到50%),也能提升计算节点的吞吐。此外,Binlog开启时,数据库故障恢复效率与社区版binlog相比提升了99%。
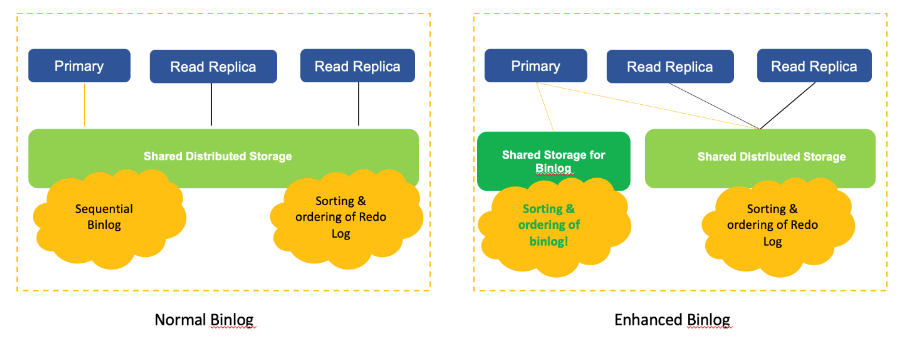
上面示意图对比展示了Enhanced Binlog和普通Binlog在Aurora MySQL架构中的不同。Enhanced Binlog提出以前,如果用户把Aurora MySQL引擎开启了Binlog,Aurora MySQL写节点在写Redo Log的同时,也会把Binlog写出到存储中去,这样,在发生写节点failover时,新的写节点就能依据共享存储中的信息做好failover以及后续持续写入。另外,Binlog文件的写入是串行完成的。在Enhanced Binlog架构图中,Aurora MySQL将Binlog存储在单独的存储引擎中,并更改了计算层和Binlog引擎中交互Binlog的方式,从串行写封装文件接口的形式改成打散并行写Binlog Event的形式,Binlog引擎可以完成Binlog Event的排序和归集。
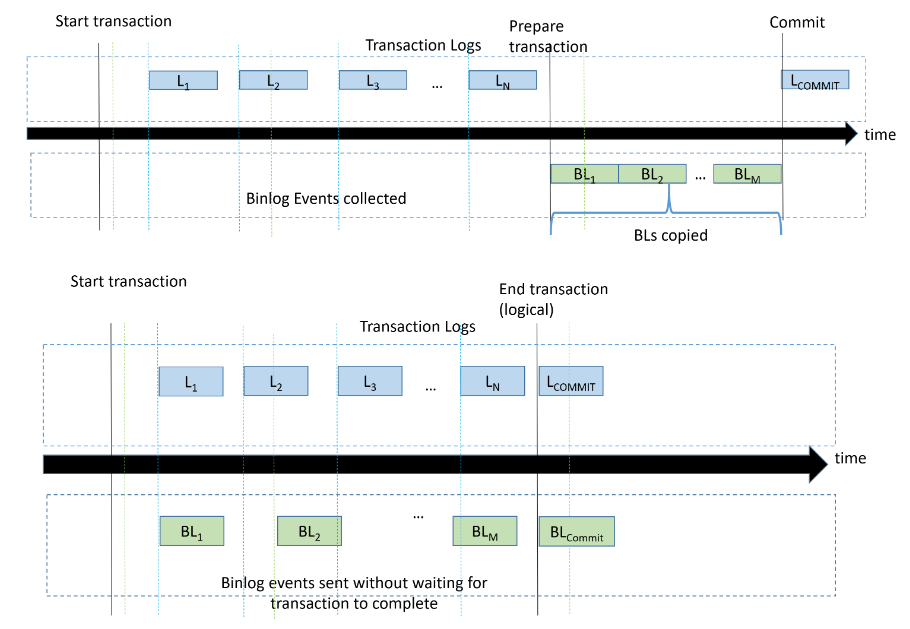
上图进一步展示了Aurora MySQL开启Enhanced Binlog之前和之后对应的处理逻辑的对比。传统Binlog处理流程是两阶段提交的方式,即Redo Log Prepare->Binlog Commit->Redo Log Commit。Binlog刷盘的动作是在Redo Log Prepare完毕顺序刷到存储层,128MB的Binlog文件刷出是需要经历一段时间的,对于较大的事务,Binlog文件也可能超过128MB。当然,Aurora MySQL 2也对超过512MB的大Binlog文件做了提前拷贝到存储层的优化,但对于512MB以下的Binlog文件,传输时需要耗费一定时间的。而Enhanced Binlog单独的存储引擎存放Binlog,可以使得刷Redo Log和Binlog的操作可以同步进行,在事务提交时,直接就通知两个存储引擎进行单独的Commit操作,节省了等待Binlog刷盘的时间。
Enhanced Binlog测评
针对Aurora MySQL Enhanced Binlog,也做了一些测试。现有两套Aurora MySQL集群:
-
Aurora MySQL 3.03.1版本。R6g.8xlarge集群,一写一读,打开Binlog。
-
Aurora MySQL 3.03.1版本。R6g.8xlarge集群,一写一读,打开Binlog,并打开Enhanced Binlog。
为打开Binlog,设置参数binlog_format为ROW。为了使用Sysbench测试较高并发,将max_prepared_stmt_count设置成了最大值1048576。
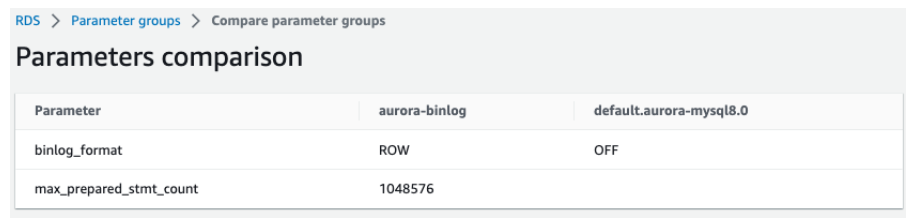
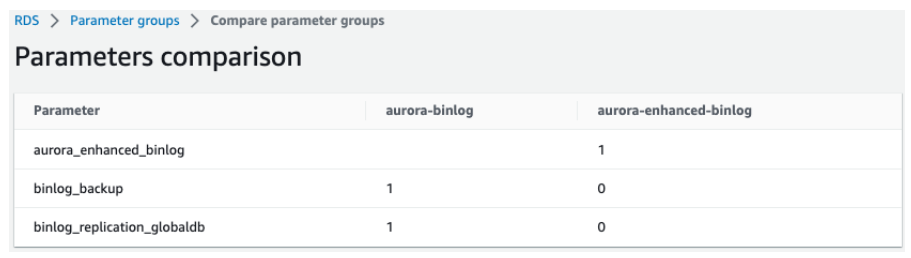
为打开Enhanced Binlog,设置了三个参数aurora_enhanced_binlog,binlog_backup,binlog_replication_globaldb,参数取值如下图所示。
运行的负载是采用Sysbench进行压测,Sysbench运行在EC2上,EC2机型是c5.18xlarge。测试过程中EC2没有成为瓶颈。
测试了两组不同的数据:1)16张表,每张表1千万条记录;2)250张表,每张表25000条记录。测试的Sysbench并发请求从2,4,8,一直增加到4096。
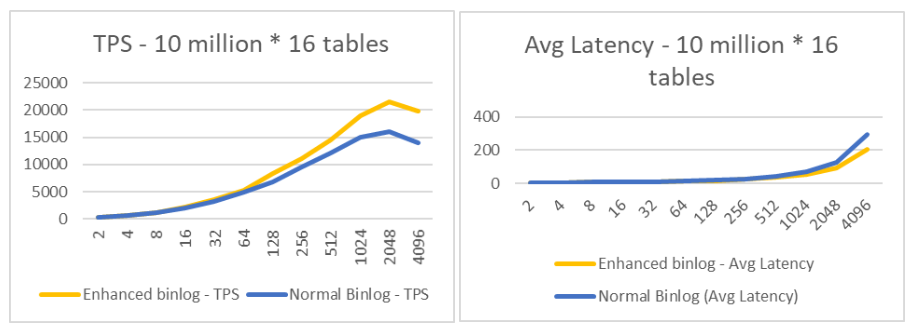
下面展示了16张表每表1千万条记录的测试结果。可以看到随着并发线程的增多,Enhanced Binlog的优势愈发明显,在4096个并发线程时,Enhanced Binlog能达到41%的性能提升。
下面展示了250张表每表25000条记录的测试结果。可以看到和前面类似的结论。随着并发线程的增多,Enhanced Binlog的优势愈发明显,在4096个并发线程时,Enhanced Binlog能达到23%的性能提升。

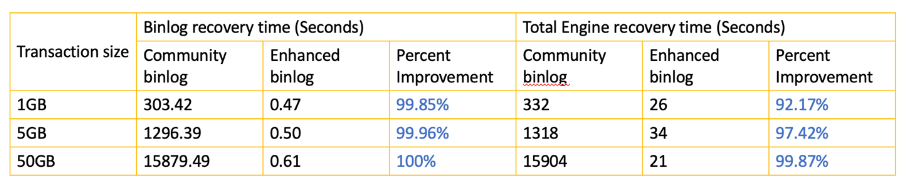
下面表格展示了Enhanced Binlog故障恢复的速度。可以看到Enhanced Binlog能够将故障恢复的速度提升92%以上。
此外,还针对ZeroETL进行了测试,因为ZeroETL是依赖于Aurora Enhanced Binlog的,测试结果表明,即便开启了ZeroETL,即有Binlog Consumer从Aurora MySQL中读取数据,Aurora MySQL对OLTP的性能保持不变。原因在于ZeroETL能够从Binlog存储引擎中直接读取数据,无需再联系Aurora MySQL计算节点。
总体而言,单独的Binlog存储引擎有几个优势:
-
提升性能:存储层进行Binlog排序逻辑,可以增加计算层的并行度,减少加锁,加速事务两阶段提交的速度。
-
加速故障恢复:避免传统Binlog故障恢复时必须顺序读取Binlog到计算层的操作。可以在保证一致性前提下按需恢复事务。可以将故障恢复时间从几分钟降低到几秒。
-
是实现直接从Aurora MySQL存储层取Binlog的基础。比如Aurora MySQL和Redshift之间的ZeroETL功能就是基于Enhanced Binlog来执行实现的,避免了有Binlog Consumer连接到Aurora MySQL计算实例对于计算节点资源的进一步竞争和消耗。
总结
综上所述,亚马逊云科技Aurora MySQL在复制性能提升上不断优化和尝试。Aurora MySQL首发版本中基于Redo Log的物理复制机制带来通常在20毫秒以下的复制延迟,使很多客户能够将更多的读应用发送到读节点进而达到更好扩展性。
基于用户对Binlog的诉求和MySQL原生Binlog机制带来对性能影响,Aurora MySQL 1.17.6和2.04.5中首先提出了Binlog Yield机制通过Dump线程让路,给前端线程更高优先级,降低了有Binlog Consumer连接时对应用延迟的影响;Aurora MySQL 2.10中进一步改进,提出了Binlog I/O Cache,既能在有Binlog Consumer连接时降低对前端应用延迟的影响,又不过度拖累复制延迟;Aurora MySQL 3.03中更是重塑了架构,将Binlog放在了单独的存储引擎上,不仅降低了Binlog在写节点落盘的时延,更是创造性地使Binlog Consumer能从存储引擎上读取Binlog信息,无需再从Aurora MySQL主节点上进行将Binlog文件从存储层读出再发送,彻底避免了Binlog Consumer和前端应用线程的竞争。所以不论是否有Binlog Consumer的连接,Aurora MySQL的性能不受影响。