作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
Stream API与接口默认方法、静态方法
之前学习函数式接口时,曾经提到过Java8新出的接口静态方法、默认方法:

为什么Java8要引入静态方法和默认方法呢?
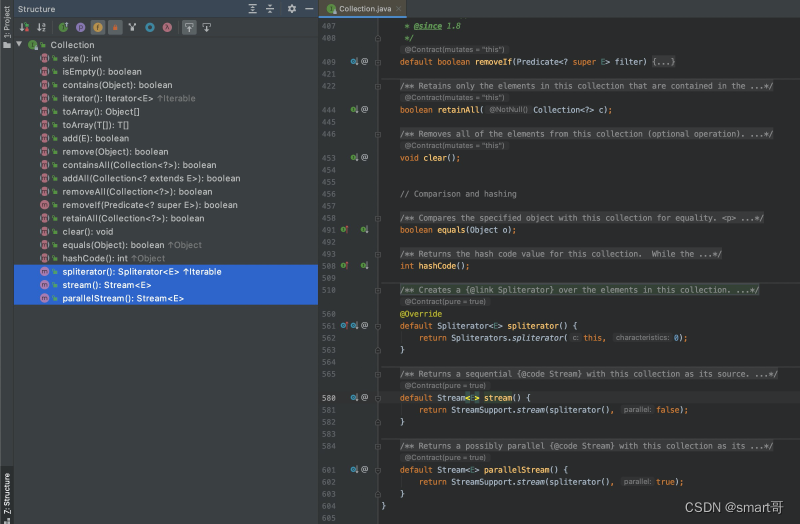
原因可能有多种,但其中一种肯定是为了“静默升级”(我自己造的一个词)。打开Collection接口:
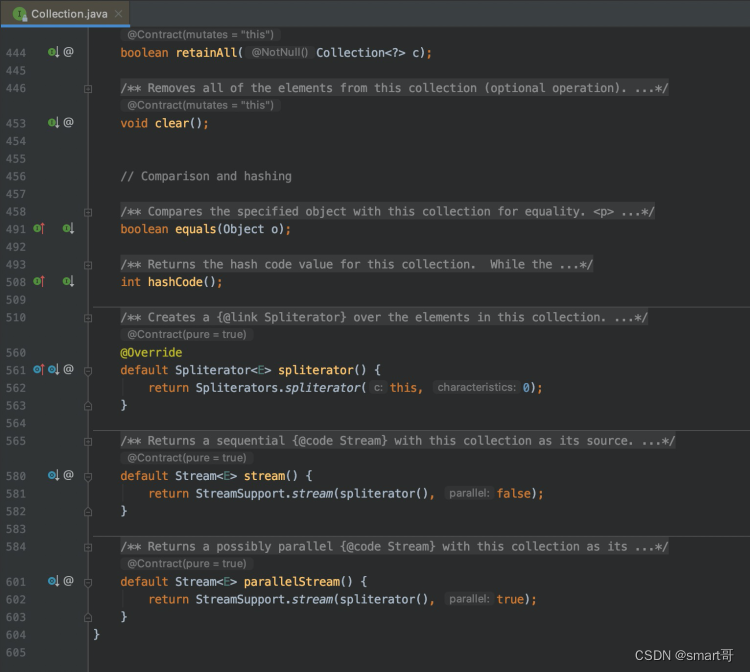
我们发现有3个default方法,而且都是JDK1.8新增的:
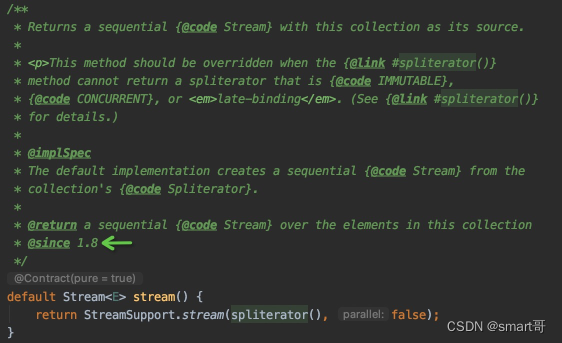
这下明白了吧,list.stream().filter()...用的这么爽,其实都直接继承自顶级父接口Collection。
这和引入default有啥关系呢?
试想一下,要想操作Stream必须先获取Stream,获取流的方法理应放在Collection及其子接口、实现类中。但如果作为抽象方法抽取到Collection中,那么原先的整个继承链都会产生较大的震动:
JDK官方要从Collection接口沿着继承链向下都实现一遍stream()方法。这还不是最大的问题,最致命的是全球各地保不齐就有人直接实现了Collection,比如MyArrayList啥的,此时如果贸然往Collection增加一个抽象方法,那么当他们升级到JDK1.8后就会立即编译错误,强制他们自己实现stream()...
到这,大家应该恍然大悟了:
害...什么静默升级,不就是向前兼容嘛!
所以JDK的做法是,把获取Stream的一部分方法封装到StreamSupport类,另一部分封装到Stream类,StreamSupport用来补足原先的集合体系,比如Collection,然后引入default方法包装一下,内部调用StreamSupport完成偷天换日。而得到Stream后的一系列filter、map操作是针对Stream的,已经封装在Stream类中,和原来的集合无关。
所以,StreamSupport+default就是原先集合体系和Stream之间的“中介”:
调用者-->Collection-->StreamSupport+default-->Stream
外部调用者还以为集合体系新增了Stream API呢。
接口静态方法也有很多使用场景,大家会在后续学习中看到:
总之,引入接口默认方法和静态方法后,接口越来越像一个类。从某个角度来说,这种做法破坏了Java的单继承原则。Java原本的特点是“单继承、多实现”,假设接口A和接口B都有methodTest(),那么class Test implements interfaceA, interfaceB时,就不得不考虑使用哪个父接口的methodTest()方法。JDK的做法是,编译时强制子类覆盖父接口同名的方法。
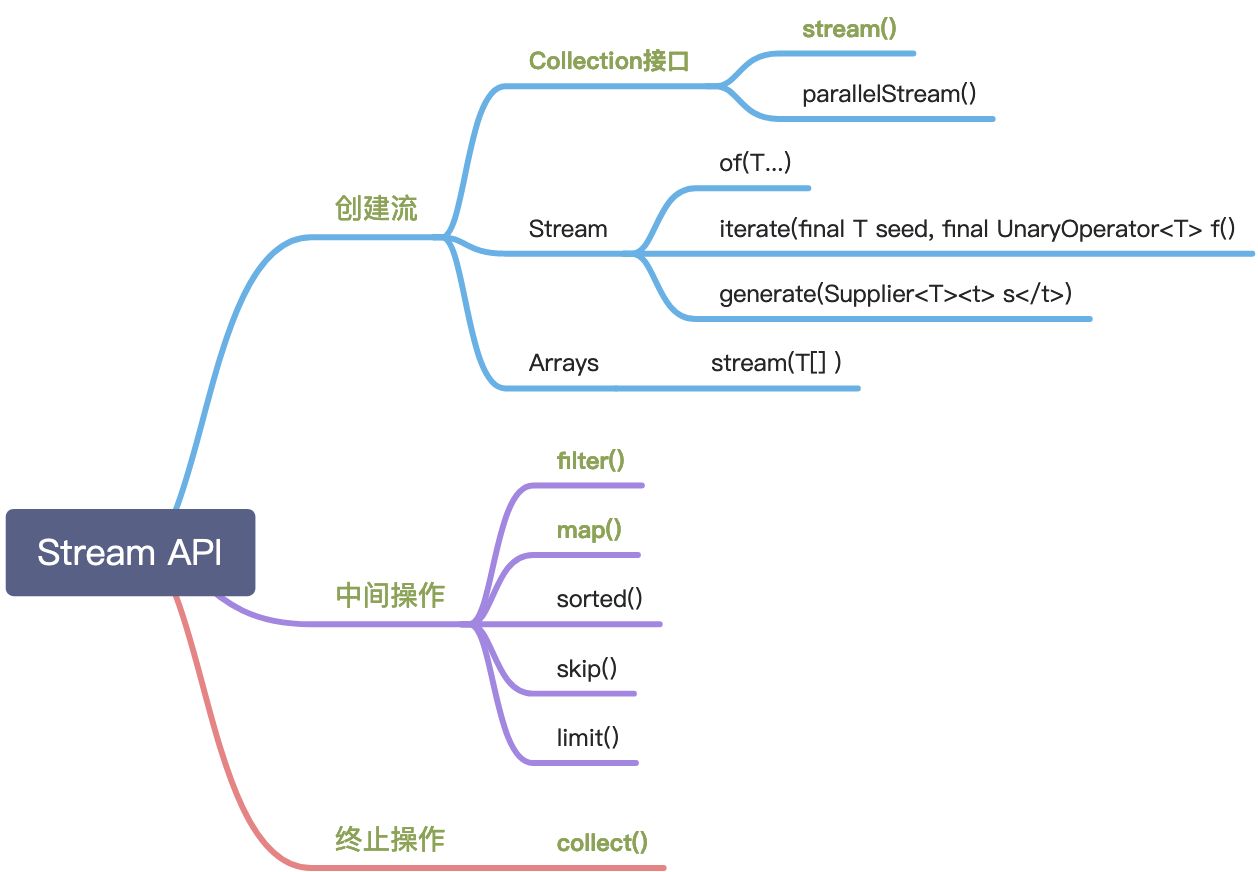
Steam API
我们最常用的集合其实来自两个派系:Collection和Map,实际开发时使用率大概是这样的:
- ArrayList:50%
- HashMap:40%
- 其他:10%
而用到Stream的地方,占比就更极端了:
- List:90%
- Set:5%
- Map:5%
对于一般人来说,只要学好List的Stream用法即可。
认识几个重要的接口与类
Stream的方法众多,不要期望能一次性融会贯通,一定要先了解整个API框架。有几个很重要的接口和类:
- Collection
- Stream
- StreamSupport
- Collector
- Collectors
Collection
之前介绍过了,为了不影响之前的实现,JDK引入了接口默认方法,并且在Collection中提供了一系列将集合转为Stream的方法:
要想使用Stream API,第一步就是获取Stream,而Collection提供了stream()和parallelStream()两个方法,后续Collection的子类比如ArrayList、HashSet等都可以直接使用顶级父接口定义好的默认方法将自身集合转为Stream。
Collection:定义stream()/parallelStream()|--List|--ArrayList:list.stream().filter().map().collect(...)|--LinkedList:list.stream().filter().map().collect(...)|--Vector|--Set|--HashSet|--TreeSetStream
Java的集合在设计之初就只是一种容器,用来存储元素,内部并没有提供处理元素的方法。更多时候,我们其实是使用集合提供的遍历方法,然后手动在外部进行判断并处理元素。
Stream是什么呢?简单来说,可以理解为更高级的Iterator,把集合转为Stream后,我们就可以使用Stream对元素进行一系列操作。
来,感受一下,平时使用的filter()、map()、sorted()、collect()都来自哪:
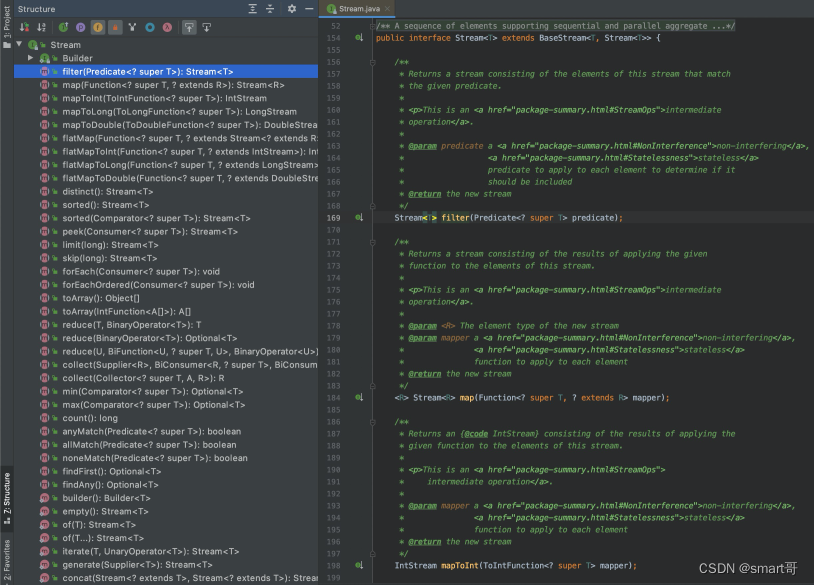
方法太多了,记忆时需要带点技巧,比如分类记忆。
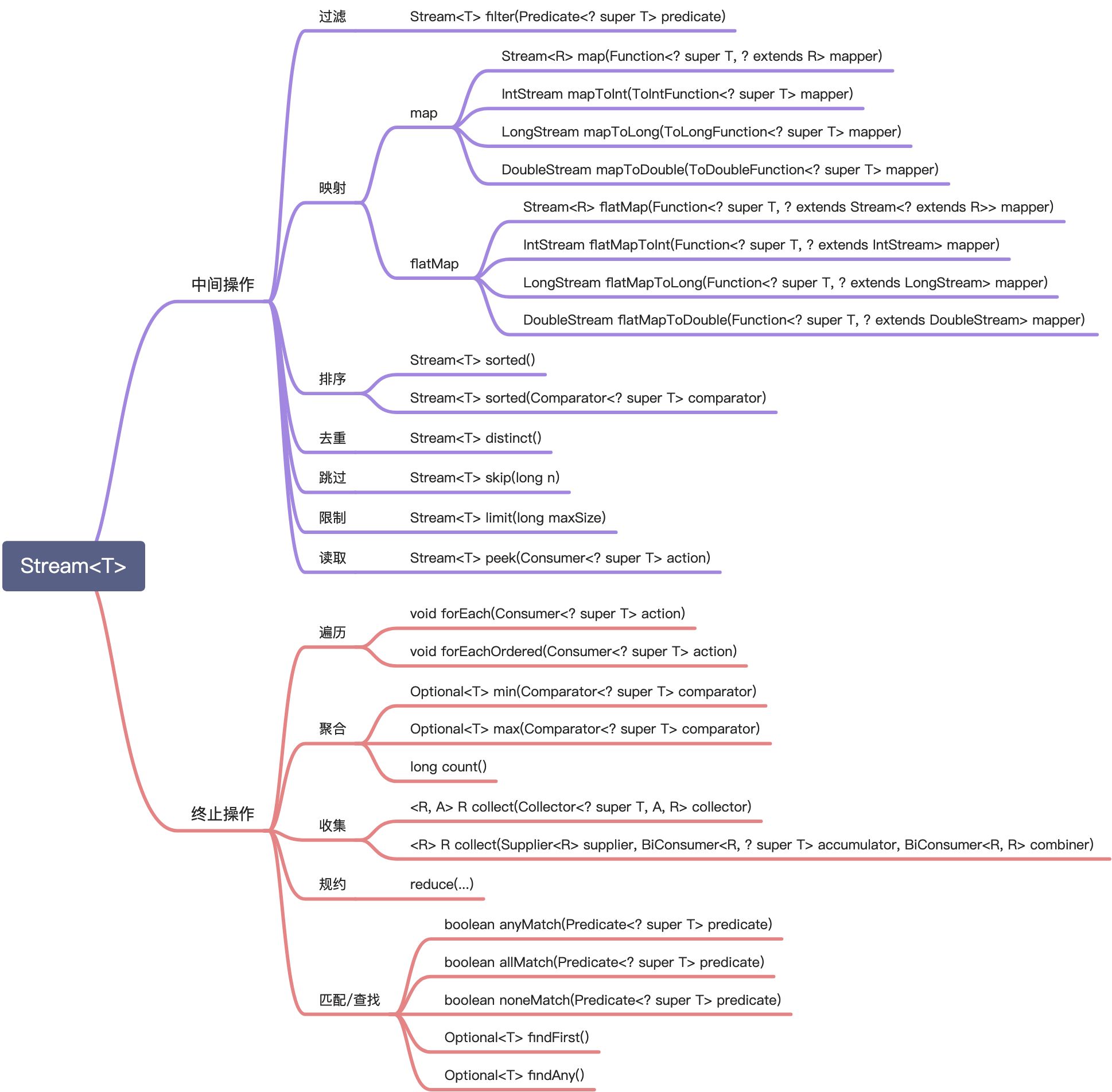
常用的有两种分类方法:
- 终止/中间操作
- 短路/非短路操作
前一种分类和我们关系大一些,所以我们按终止、中间操作分类记忆。
所谓中间操作和终止操作,可以粗略地理解为后面还能不能跟其他的方法。比如filter后面还可以跟map等操作,那么filter就是中间操作,而collect后返回的就是元素了,而不是流,无法继续使用。就好比一缕山泉,经过小草、小花、竹林,还是一缕水,但到了你的锅里煮成一碗粥,就没法继续使用了。
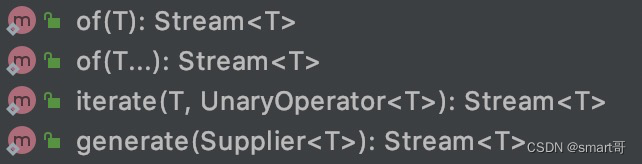
还有几个不是特别常用的操作就不放在思维导图里了,这里简要介绍一下。比如,除了Collection接口中定义的stream()和parallelStream(),Stream也定义了创建流的方法(不常用):
还有一个合并流的方法(知道即可):
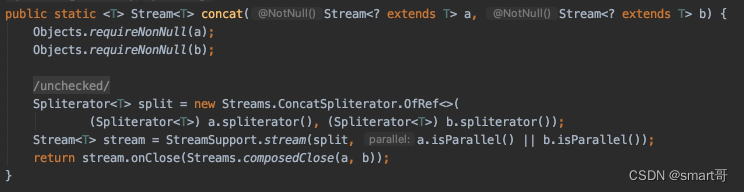
StreamSupport
没啥好介绍的,一般不会直接使用StreamSupport,Collection接口借助它实现了stream()和parallelStream()。
collect()、Collector、Collectors
我们先不说这几个是什么、有什么关系,直接通过代码演示哪里会用到:
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("甲", 18, "杭州", 999.9));list.add(new Person("乙", 19, "温州", 777.7));list.add(new Person("丙", 21, "杭州", 888.8));list.add(new Person("丁", 17, "宁波", 888.8));}public static void main(String[] args) {List<Person> result = list.stream().filter(person -> person.getAge() > 20).collect(Collectors.toList());}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}}collect()是用来收集处理后的元素的,它有两个重载的方法:
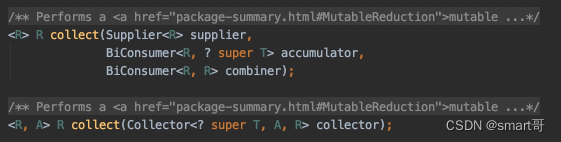
我们暂时只看下面那个,它接收一个Collector对象,而我们一般不会自己去new Collector对象,因为JDK给我提供了Collectors,可以调用Collectors提供的方法返回Collector对象:
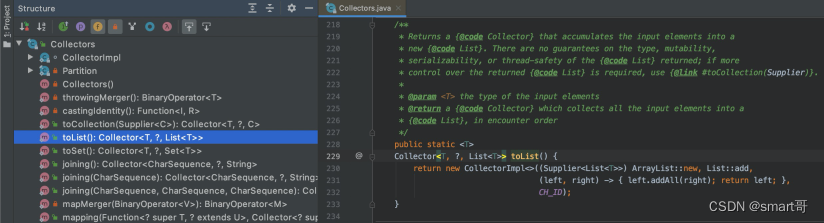
所以collect()、Collector、Collectors三者的关系是:
collect()通过传入不同的Collector对象来明确如何收集元素,比如收集成List还是Set还是拼接字符串?而通常我们不需要自己实现Collector接口,只需要通过Collectors获取。
这倒颇有点像Executor和Executors的关系,一个是线程池接口,一个是线程池工具类。
如何高效学习Stream API
和几个重要接口、类混个脸熟后,我们来谈谈如何高效学习Stream API。很多同学应该已经被上面的内容吓到了,不要怕,通过后面的实操,整个知识脉络很快就会清晰起来。但还是那句话,一开始不要扣细节,先抓主干:
初学者如果对stream的流式操作感到陌生,可以暂时理解为外部迭代(实际不是这样的,后面会大家一起观察):

特别注意reduce():

特别适合做累加、累乘啥的。
铺垫结束,接下来我们通过实战来正式学习Stream API。学习其他技术都可以追求理论深度,唯独Stream API就是一个字:干!
基础操作
map/filter
先来个最简单:
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {// 我们先学中间操作// 1.先获取流(不用管其他乱七八糟的创建方式,记住这一个就能应付95%的场景)Stream<Person> stream = list.stream();// 2.过滤得到年纪大于18岁的(filter表示过滤【得到】符合传入条件的元素,而不是过滤【去除】)Stream<Person> filteredByAgeStream = stream.filter(person -> person.getAge() > 18);// 3.只要名字,不需要整个Person对象(为什么在这个案例中,filter只能用Lambda,map却可以用方法引用?)Stream<String> nameStream = filteredByAgeStream.map(Person::getName);// 4.现在返回值是Stream<String>,没法直接使用,帮我收集成List<String>List<String> nameList = nameStream.collect(Collectors.toList());// 现在还对collect()为什么传递Collectors.toList()感到懵逼吗?}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}再来一个:
public static void main(String[] args) {// 直接链式操作List<String> nameList = list.stream().filter(person -> person.getAge() > 18).map(Person::getName).collect(Collectors.toList());
}sorted
试着加入sorted()玩一下。
在此之前,我们先来见见一位老朋友:Comparator。这个接口其实早在JDK1.2就有了,但当时只有两个方法:
- compare()
- equals()
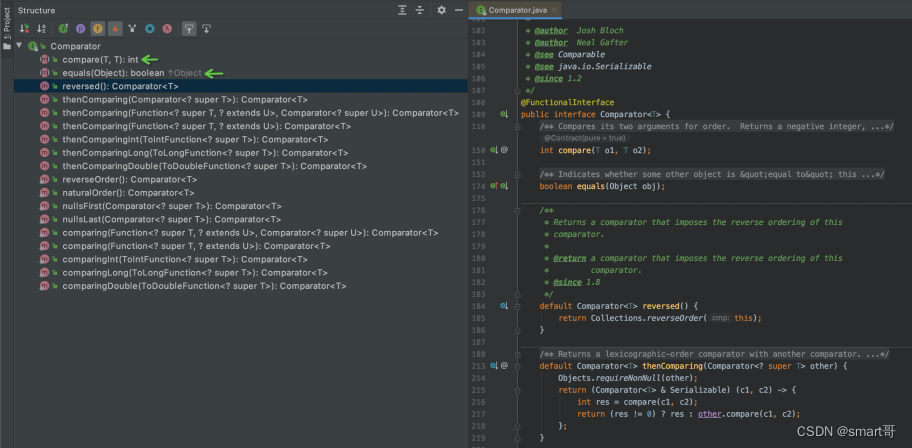
JDK1.8通过默认方法的形式引入了很多额外的方法,比如reversed()、Comparing()等。
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {// JDK8之前:Collections工具类+匿名内部类。Collections类似于Arrays工具类,我经常用Arrays.asList()Collections.sort(list, new Comparator<Person>() {@Overridepublic int compare(Person p1, Person p2) {return p1.getName().length()-p2.getName().length();}});// JDK8之前:List本身也实现了sort()list.sort(new Comparator<Person>() {@Overridepublic int compare(Person p1, Person p2) {return p1.getName().length()-p2.getName().length();}});// JDK8之后:Lambda传参给Comparator接口,其实就是实现Comparator#compare()。注意,equals()是Object的,不妨碍list.sort((p1,p2)->p1.getName().length()-p2.getName().length());// JDK8之后:使用JDK1.8为Comparator接口新增的comparing()方法list.sort(Comparator.comparingInt(p -> p.getName().length()));}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}大家不好奇吗?sort()需要的是Comparator接口的实现,调用Comparator.comparing()怎么也可以?
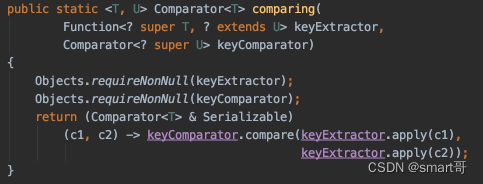
好家伙,Comparator.comparing()返回的也是Comparator...
OK,铺垫够了,来玩一下Stream#sorted(),看看和List#sort()有啥区别。
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {// 直接链式操作List<String> nameList = list.stream().filter(person -> person.getAge() > 18).map(Person::getName).collect(Collectors.toList());System.out.println(nameList);// 我想按姓名长度排序List<String> sortedNameList = list.stream().filter(person -> person.getAge() > 18).map(Person::getName).sorted().collect(Collectors.toList());System.out.println(sortedNameList);// 你:我擦,说好的排序呢?// Stream:别扯淡,你告诉我排序规则了吗?(默认自然排序)// 明白了,那就按照长度倒序吧(注意细节啊,str2-str1才是倒序)List<String> realSortedNameList = list.stream().filter(person -> person.getAge() > 18).map(Person::getName).sorted((str1, str2) -> str2.length() - str1.length()).collect(Collectors.toList());System.out.println(realSortedNameList);// 优化一下:我记得在之前那张很大的思维导图上看到过,sorted()有重载方法,是sorted(Comparator)// 上面Lambda其实就是调用sorted(Comparator),用Lambda给Comparator接口赋值// 但Comparator还供了一些方法,能返回Comparator实例List<String> optimizeNameList = list.stream().filter(person -> person.getAge() > 18).map(Person::getName).sorted(Comparator.reverseOrder()).collect(Collectors.toList());System.out.println(optimizeNameList);// 又是一样的套路,Comparator.reverseOrder()返回的其实是一个Comparator!!// 但上面的有点投机取巧,来个正常点的,使用Comparator.comparing()List<String> result1 = list.stream().filter(person -> person.getAge() > 18).map(Person::getName).sorted(Comparator.comparing(t -> t, (str1, str2) -> str2.length() - str1.length())).collect(Collectors.toList());System.out.println(result1);// 我去,更麻烦了!!// 不急,我们先来了解上面案例中Comparator的两个参数// 第一个是Function映射,就是指定要排序的字段,由于经过上一步map操作,已经是name了,就不需要映射了,所以是t->t// 第二个是比较规则// 我们把map和sorted调换一下顺序,看起来就不那么别扭了List<String> result2 = list.stream().filter(person -> person.getAge() > 18).sorted(Comparator.comparing(Person::getName, String::compareTo).reversed()).map(Person::getName).collect(Collectors.toList());System.out.println(result2);// 为什么Comparator.comparing().reversed()可以链式调用呢?// 上面说了哦,因为Comparator.comparing()返回的还是Comparator对象~}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}limit/skip
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {List<String> result = list.stream().filter(person -> person.getAge() > 17)// peek()先不用管,它不会影响整个流程,就是打印看看filter操作后还剩什么元素.peek(person -> System.out.println(person.getName())).skip(1).limit(2).map(Person::getName).collect(Collectors.toList());System.out.println(result);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}结果
==== 过滤后的元素有3个 ====
i
am
iron
==== skip(1)+limit(2)后的元素 ====
[am, iron]
所谓的skip(N)就是跳过前面N个元素,limit(N)就是只取N个元素。
collect
collect()是最重要、最难掌握、同时也是功能最丰富的方法。
最常用的4个方法:Collectors.toList()、Collectors.toSet()、Collectors.toMap()、Collectors.joining()
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {// 最常用的4个方法// 把结果收集为ListList<String> toList = list.stream().map(Person::getAddress).collect(Collectors.toList());System.out.println(toList);// 把结果收集为SetSet<String> toSet = list.stream().map(Person::getAddress).collect(Collectors.toSet());System.out.println(toSet);// 把结果收集为Map,前面的是key,后面的是value,如果你希望value是具体的某个字段,可以改为toMap(Person::getName, person -> person.getAge())Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person));System.out.println(nameToPersonMap);// 把结果收集起来,并用指定分隔符拼接String result = list.stream().map(Person::getAddress).collect(Collectors.joining("~"));System.out.println(result);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}关于collect收集成Map的操作,有一个小坑需要注意:
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("iron", 17, "宁波", 888.8));}public static void main(String[] args) {Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person));System.out.println(nameToPersonMap);}@Getter@Setter@AllArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +", address='" + address + '\'' +", salary=" + salary +'}';}}
}尝试运行上面的代码,会观察到如下异常:
Exception in thread "main" java.lang.IllegalStateException: Duplicate key Person{name='iron', age=21, address='杭州', salary=888.8}
这是因为toMap()不允许key重复,我们必须指定key冲突时的解决策略(比如,保留已存在的key):
public static void main(String[] args) {Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person, (preKey, nextKey) -> preKey));System.out.println(nameToPersonMap);
}如果你希望key覆盖,可以把(preKey, nextKey) -> preKey)换成(preKey, nextKey) -> nextKey)。
你可能会在同事的代码中发现另一种写法:
public static void main(String[] args) {Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, Function.identity());System.out.println(nameToPersonMap);
}Function.identity()其实就是v->v:

但它依然没有解决key冲突的问题,而且对于大部分人来说,相比person->person,Function.identity()的可读性不佳。
聚合:max/min/count
max/min
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {// 匿名内部类的方式,实现Comparator,明确按什么规则比较(所谓最大,必然是在某种规则下的最值)Optional<Integer> maxAge = list.stream().map(Person::getAge).max(new Comparator<Integer>() {@Overridepublic int compare(Integer age1, Integer age2) {return age1 - age2;}});System.out.println(maxAge.orElse(0));Optional<Integer> max = list.stream().map(Person::getAge).max(Integer::compareTo);System.out.println(max.orElse(0));}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}count
public static void main(String[] args) {long count = list.stream().filter(person -> person.getAge() > 18).count();System.out.println(count);
}去重:distinct
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {long count = list.stream().map(Person::getAddress).distinct().count();System.out.println(count);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}所谓“去重”,就要明确怎样才算“重复”。那么,distinct()是基于什么标准呢?
还是那两样:hashCode()和equals(),所以记得重写这两个方法(一般使用Lombok的话问题不大)。
distinct()提供的去重功能比较简单,就是判断对象重复。如果希望实现更细粒度的去重,比如根据对象的某个属性去重,可以怎么做呢?可以参考:分享几种 Java8 中通过 Stream 对列表进行去重的方法
一般来说,学到已经覆盖实际开发90%的场景了,后面的可以不用学了。
高阶操作
两部分内容:
- 深化一下collect()方法,它还有很多其他玩法
- 介绍flatMap、reduce、匹配查找、peek、forEach等边角料
collect高阶操作
聚合
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}/*** 演示用collect()方法实现聚合操作,对标max()、min()、count()* @param args*/public static void main(String[] args) {// 方式1:匿名对象Optional<Person> max1 = list.stream().collect(Collectors.maxBy(new Comparator<Person>() {@Overridepublic int compare(Person p1, Person p2) {return p1.getAge() - p2.getAge();}}));System.out.println(max1.orElse(null));// 方式2:LambdaOptional<Person> max2 = list.stream().collect(Collectors.maxBy((p1, p2) -> p1.getAge() - p2.getAge()));System.out.println(max2.orElse(null));// 方式3:方法引用Optional<Person> max3 = list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Person::getAge)));System.out.println(max3.orElse(null));// 方式4:IDEA建议直接使用 max(),不要用 collect(Collector)Optional<Person> max4 = list.stream().max(Comparator.comparingInt(Person::getAge));System.out.println(max4.orElse(null));// 特别是方式3和方式4,可以看做collect()聚合和max()聚合的对比// 剩下的minBy和countingOptional<Person> min1 = list.stream().collect(Collectors.minBy(Comparator.comparingInt(Person::getAge)));Optional<Person> min2 = list.stream().min(Comparator.comparingInt(Person::getAge));Long count1 = list.stream().collect(Collectors.counting());Long count2 = list.stream().count();}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}分组
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}/*** 按字段分组* 按条件分组** @param args*/public static void main(String[] args) {// GROUP BY addressMap<String, List<Person>> groupingByAddress = list.stream().collect(Collectors.groupingBy(Person::getAddress));System.out.println(groupingByAddress);// GROUP BY address, ageMap<String, Map<Integer, List<Person>>> doubleGroupingBy = list.stream().collect(Collectors.groupingBy(Person::getAddress, Collectors.groupingBy(Person::getAge)));System.out.println(doubleGroupingBy);// 简单来说,就是collect(groupingBy(xx)) 扩展为 collect(groupingBy(xx, groupingBy(yy))),嵌套分组// 解决了按字段分组、按多个字段分组,我们再考虑一个问题:有时我们分组的条件不是某个字段,而是某个字段是否满足xx条件// 比如 年龄大于等于18的是成年人,小于18的是未成年人Map<Boolean, List<Person>> adultsAndTeenagers = list.stream().collect(Collectors.partitioningBy(person -> person.getAge() >= 18));System.out.println(adultsAndTeenagers);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}提一句,collect()方法是最为丰富的,可以搭配Collector玩出很多花样,特别是经过各种嵌套组合。本文末尾留了几道思考题,大家到时可以试着做做。
统计
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}/*** 统计* @param args*/public static void main(String[] args) {// 平均年龄Double averageAge = list.stream().collect(Collectors.averagingInt(Person::getAge));System.out.println(averageAge);// 平均薪资Double averageSalary = list.stream().collect(Collectors.averagingDouble(Person::getSalary));System.out.println(averageSalary);// 其他的不演示了,大家自己看api提示。简而言之,就是返回某个字段在某个纬度的统计结果// 有个更绝的,针对某项数据,一次性返回多个纬度的统计结果:总和、平均数、最大值、最小值、总数,但一般用的很少IntSummaryStatistics allSummaryData = list.stream().collect(Collectors.summarizingInt(Person::getAge));long sum = allSummaryData.getSum();double average = allSummaryData.getAverage();int max = allSummaryData.getMax();int min = allSummaryData.getMin();long count = allSummaryData.getCount();}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}flatMap
总的来说,就是flatMap就是把多个流合并成一个流:
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9, new ArrayList<>(Arrays.asList("成年人", "学生", "男性"))));list.add(new Person("am", 19, "温州", 777.7, new ArrayList<>(Arrays.asList("成年人", "打工人", "宇宙最帅"))));list.add(new Person("iron", 21, "杭州", 888.8, new ArrayList<>(Arrays.asList("喜欢打篮球", "学生"))));list.add(new Person("man", 17, "宁波", 888.8, new ArrayList<>(Arrays.asList("未成年人", "家里有矿"))));}public static void main(String[] args) {Set<String> allTags = list.stream().flatMap(person -> person.getTags().stream()).collect(Collectors.toSet());System.out.println(allTags);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;// 个人标签private List<String> tags;}
}对于每个Person对象中的tags,如果没有flatMap,想要合并去重会比较麻烦。
对比map和flatMap:


flatMap传入的Function要求返回值是Stream<? extends R>而不是R,所以上面写的是:

Function返回的多个Stream<R>最终会被flatMap汇聚成同一个Stream<R>,而map的Function返回R,最终被收集成Stream<R>。

总之,当你遇到List中还有List,然后你又想把第二层的List都拎出来集中处理时,就可以考虑用flatMap(),先把层级打平,再统一处理。
forEach
这个,其实不算高阶操作,算了,就放这吧。简单来说就是遍历:
public class StreamTest {private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {// 遍历操作,接收Consumerlist.stream().forEach(System.out::println);// 简化,本质上不算同一个方法的简化list.forEach(System.out::println);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}peek()

它接受一个Consumer,一般有两种用法:
- 设置值
- 观察数据
设置值的用法:
public class StreamTest {public static void main(String[] args) {list.stream().peek(person -> person.setAge(18)).forEach(System.out::println);}
}也就是把所有人的年龄设置为18岁。
peek这个单词本身就带有“观察”的意思。

简单来说,就是查看数据,一般实际开发很少用,但可以用来观察数据的流转:
public class StreamTest {public static void main(String[] args) {Stream<Integer> stream = Stream.of(1, 2, 3);stream.peek(v-> System.out.print(v+",")).map(value -> value + 100).peek(v-> System.out.print(v+",")).forEach(System.out::println);}
}结果
1,101,101
2,102,102
3,103,103
有没有感到好奇?
用图表示的话,就是这样:

通过peek,我们观察到每一个元素都是逐个通过Stream流的。
为了看得更清楚些,重新写个demo:
public static void main(String[] args) {Stream.of(1, 2, 3, 4).peek(v -> System.out.print(v + ",")).filter(v -> v >= 2).peek(v -> System.out.print(v + ",")).filter(v -> v >= 3).forEach(System.out::println);
}结果
1,2,2,3,3,3
4,4,4
这打印,怎么这么诡异?
其实不诡异,元素确实是逐个通过的:

一个元素如果中途被过滤,就不会继续往下,换下一个元素。最终串起来,就会打印:
1,2,2,3,3,3
4,4,4
大家思考一下,真正的Stream和我们之前山寨的Stream,遍历时有何不同?能画图解释一下吗?
元素一个个通过关卡
元素一起通过一个个关卡
匹配/查找
findFirst
public static void main(String[] args) {Optional<Integer> first = Stream.of(1, 2, 3, 4).peek(v -> System.out.print(v + ",")).findFirst();
}结果:
1,
只要第一个,后续元素不会继续遍历。
findAny
public static void main(String[] args) {Optional<Integer> any = Stream.of(1, 2, 3, 4).peek(v -> System.out.print(v + ",")).findAny();
}结果:
1,
findFirst和findAny几乎一样,但如果是并行流,结果可能不一致:
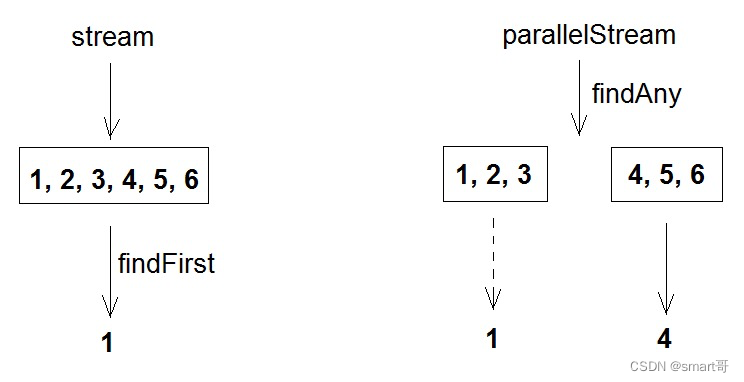
并行流颇有种“分而治之”的味道(底层forkjoin线程池),将流拆分并行处理,能较大限度利用计算资源,提高工作效率。但要注意,如果当前操作对顺序有要求,可能并不适合使用parallelStream。比如上图右边,使用并行流后返回的可能是4而不是1。
关于findFirst()和findAny()有没有人觉得这方法很傻逼?其实是我demo举的不对,通常来说应该是一堆filter操作任取一个等场景下使用。比如list.stream().filter(student->student.getAge()>18).findFirst(),即符合条件的任选一个。
allMatch
public static void main(String[] args) {boolean b = Stream.of(1, 2, 3, 4).peek(v -> System.out.print(v + ",")).allMatch(v -> v > 2);
}结果
1,
由于是要allMatch,第一个就不符合,那么其他元素也就没必要测试了。这是一个短路操作。
就好比:
if(0>1 && 2>1){// 2>1 不会被执行,因为0>1不成立,所以2>1被短路了
}noneMatch
public static void main(String[] args) {boolean b = Stream.of(1, 2, 3, 4).peek(v -> System.out.print(v + ",")).noneMatch(v -> v >= 2);
}结果
1,2,
和allMatch一样,它期望的是没有一个满足,而2>=2已经false,后面元素即使都大于2也不影响最终结果:noneMatch=false,所以也是个短路操作。
anyMatch
略
reduce
略,实际开发没用过,大家可以在熟悉上面的用法后再去了解,否则可能比较乱。
Stream API的效率问题
public class Test {public static void main(String[] args) {// 1. 简单数据类型:整数testSimpleType();// 2. 复杂数据类型:对象
// testObjectType();}private static void testSimpleType() {Random random = new Random();List<Integer> integerList = new ArrayList<>();for (int i = 0; i < 10000000; i++) {integerList.add(random.nextInt(Integer.MAX_VALUE));}// 1) streamtestStream(integerList);// 2) parallelStreamtestParallelStream(integerList);// 3) 普通fortestForLoop(integerList);// 4) 增强型fortestStrongForLoop(integerList);// 5) 迭代器testIterator(integerList);}private static void testObjectType() {Random random = new Random();List<Product> productList = new ArrayList<>();for (int i = 0; i < 10000000; i++) {productList.add(new Product("pro" + i, i, random.nextInt(Integer.MAX_VALUE)));}// 1) streamtestProductStream(productList);// 2) parallelStreamtestProductParallelStream(productList);// 3) 普通fortestProductForLoop(productList);// 4) 增强型fortestProductStrongForLoop(productList);// 5) 迭代器testProductIterator(productList);}// -------- 测试简单类型 --------public static void testStream(List<Integer> list) {long start = System.currentTimeMillis();Optional<Integer> optional = list.stream().max(Integer::compare);System.out.println("result=" + optional.orElse(0));long end = System.currentTimeMillis();System.out.println("testStream耗时:" + (end - start) + "ms");}public static void testParallelStream(List<Integer> list) {long start = System.currentTimeMillis();Optional<Integer> optional = list.parallelStream().max(Integer::compare);System.out.println("result=" + optional.orElse(0));long end = System.currentTimeMillis();System.out.println("testParallelStream耗时:" + (end - start) + "ms");}public static void testForLoop(List<Integer> list) {long start = System.currentTimeMillis();int max = Integer.MIN_VALUE;for (int i = 0; i < list.size(); i++) {int current = list.get(i);if (current > max) {max = current;}}System.out.println("result=" + max);long end = System.currentTimeMillis();System.out.println("testForLoop耗时:" + (end - start) + "ms");}public static void testStrongForLoop(List<Integer> list) {long start = System.currentTimeMillis();int max = Integer.MIN_VALUE;for (Integer integer : list) {if (integer > max) {max = integer;}}System.out.println("result=" + max);long end = System.currentTimeMillis();System.out.println("testStrongForLoop耗时:" + (end - start) + "ms");}public static void testIterator(List<Integer> list) {long start = System.currentTimeMillis();Iterator<Integer> it = list.iterator();int max = it.next();while (it.hasNext()) {int current = it.next();if (current > max) {max = current;}}System.out.println("result=" + max);long end = System.currentTimeMillis();System.out.println("testIterator耗时:" + (end - start) + "ms");}// -------- 测试对象类型 --------public static void testProductStream(List<Product> list) {long start = System.currentTimeMillis();Optional<Product> optional = list.stream().max((p1, p2) -> p1.hot - p2.hot);System.out.println(optional.orElseThrow(() -> new RuntimeException("对象不存在")));long end = System.currentTimeMillis();System.out.println("testProductStream耗时:" + (end - start) + "ms");}public static void testProductParallelStream(List<Product> list) {long start = System.currentTimeMillis();Optional<Product> optional = list.parallelStream().max((p1, p2) -> p1.hot - p2.hot);System.out.println(optional.orElseThrow(() -> new RuntimeException("对象不存在")));long end = System.currentTimeMillis();System.out.println("testProductParallelStream耗时:" + (end - start) + "ms");}public static void testProductForLoop(List<Product> list) {long start = System.currentTimeMillis();Product maxHot = list.get(0);for (int i = 0; i < list.size(); i++) {Product current = list.get(i);if (current.hot > maxHot.hot) {maxHot = current;}}System.out.println(maxHot);long end = System.currentTimeMillis();System.out.println("testProductForLoop耗时:" + (end - start) + "ms");}public static void testProductStrongForLoop(List<Product> list) {long start = System.currentTimeMillis();Product maxHot = list.get(0);for (Product product : list) {if (product.hot > maxHot.hot) {maxHot = product;}}System.out.println(maxHot);long end = System.currentTimeMillis();System.out.println("testProductStrongForLoop耗时:" + (end - start) + "ms");}public static void testProductIterator(List<Product> list) {long start = System.currentTimeMillis();Iterator<Product> it = list.iterator();Product maxHot = it.next();while (it.hasNext()) {Product current = it.next();if (current.hot > maxHot.hot) {maxHot = current;}}System.out.println(maxHot);long end = System.currentTimeMillis();System.out.println("testProductIterator耗时:" + (end - start) + "ms");}}@Data
@AllArgsConstructor
class Product {// 名称String name;// 库存Integer stock;// 热度Integer hot;
}大家把测试案例拷贝到本地test包下运行看看,相信心中有判断。虽然上面的案例中没有测试list.stream.filter().map.dictinc()等连环操作,但结果应该差不多。
但我想说的是,绝大部分时候代码的可读性应该优先于性能,况且Stream API性能并不差。和传统代码相比,Stream API让程序员专注于实现的步骤而不是细节,大大提高了代码的可读性。
Integer minPrice = itemSkuPriceTOS.stream().sorted(Comparator.comparingLong(ItemSkuPriceTO::getPrice)) // 先正序排列.findFirst() // 找到第一个,也就是价格最低的item.map(ItemSkuPriceTO::getPrice) // 得到item的价格.orElse(0); // 兜底处理如果你习惯了Stream API,上面的代码在可读性上会比用for循环实现好得多,所以能用Stream API的尽量用Stream API吧。毕竟上面测试用了1000w数据差距也就几十毫秒,更别说实际项目中可能就几十条了。
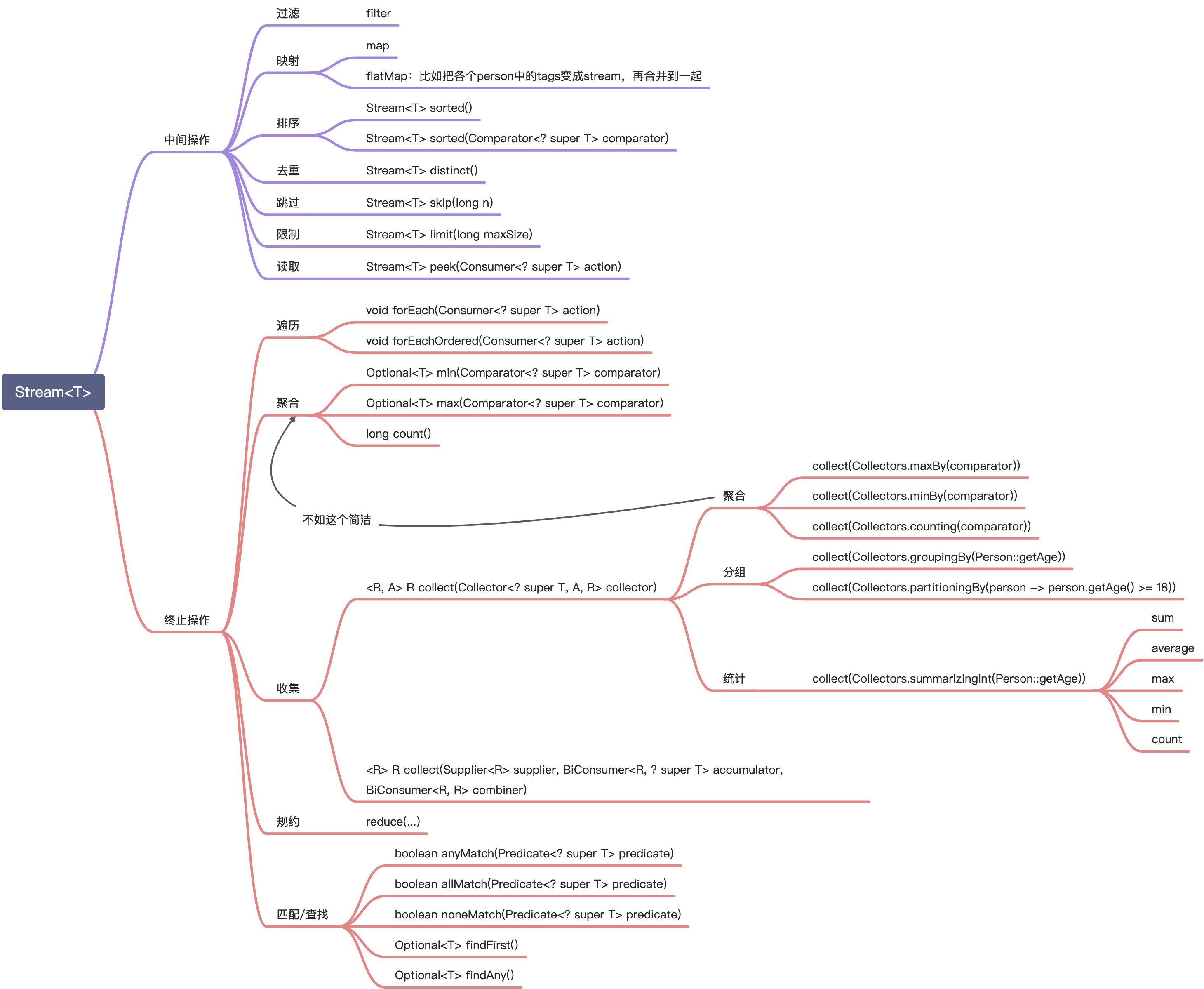
最后再来看思维导图复习一下吧(有些使用频率很低,本文就略过了):
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬