一、langChain
LangChain 是一个由语言模型LLMs驱动的应用程序框架,它允许用户围绕大型语言模型快速构建应用程序和管道。 可以直接与 OpenAI 的 ChatGPT 模型以及 Hugging Face 集成。通过 langChain 可快速构建聊天机器人、生成式问答(GQA)、本文摘要等应用场景。
LangChain本身并不开发LLMs,它的核心理念是为各种LLMs提供通用的接口,降低开发者的学习成本,方便开发者快速地开发复杂的LLMs应用。LangChain目前有python 和 nodejs 两种版本实现,python 支持的能力较多,下面的功能演示都是基于 Python 进行的。
LangChain 中主要支持的组件如下所述:
Models:各种类型的模型和模型集成,比如OpenAI的ChatGPT。Prompts:提示管理、提示优化和提示序列化,通过提示微调模型的语义理解。Memory:用来保存和模型交互时的上下文状态。Indexes:用来结构化文档,以便和模型交互。Chains:一系列对各种组件的调用。Agents:决定模型采取哪些行动,执行并且观察流程,直到完成为止。
例如:使用原生的方式调用 OpenAI 如下:
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
import openai
import osopenai.api_key = os.environ["OPENAI_API_KEY"]
messages = [{"role": "user", "content": "介绍下 ChatGPT "}]
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=messages,temperature=0,
)print("LLM 返回:", response.choices[0].message["content"])

现在使用 LangChain 的话就可以使用下面方式:
pip install langchain[all] -i https://pypi.tuna.tsinghua.edu.cn/simple
from langchain.llms import OpenAI
import osopenai_api_key=os.environ["OPENAI_API_KEY"]
llm = OpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key)
my_text = "介绍下 ChatGPT "
print(llm(my_text))

下面是基于 LangChain 构建聊天功能:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
import osopenai_api_key=os.environ["OPENAI_API_KEY"]
chat = ChatOpenAI(temperature=1, openai_api_key=openai_api_key)
res = chat([# 系统语言SystemMessage(content="你是一个智能导游,根据用户描述的地方,回答该地放的特色"),# 人类语言HumanMessage(content="江苏南京")]
)
print(res)

从上面的案例可以感受出 LangChain 的简易性,更详细的介绍可以参考下面官方文档:
https://python.langchain.com/docs/get_started/quickstart
中文文档地址:
https://www.langchain.com.cn/
下面对常用的 LangChain 组件进行使用介绍:
二、Prompts 提示管理
使用文本提示的方式,微调模型的语义理解,给出更加准确的信息。
2.1 PromptTemplate 提示模板
PromptTemplate 可以生成文本模版,通过变量参数的形式拼接成完整的语句。
from langchain.llms import OpenAI
from langchain import PromptTemplate
import osopenai_api_key = os.environ["OPENAI_API_KEY"]# 使用 openAi 模型
llm = OpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key)# 模版格式
template = "我像吃{value}。我应该怎么做出来?"
# 构建模版
prompt = PromptTemplate(input_variables=["value"],template=template,
)
# 模版生成内容
final_prompt = prompt.format(value='鱼香肉丝')print("输入内容::", final_prompt)
print("LLM输出:", llm(final_prompt))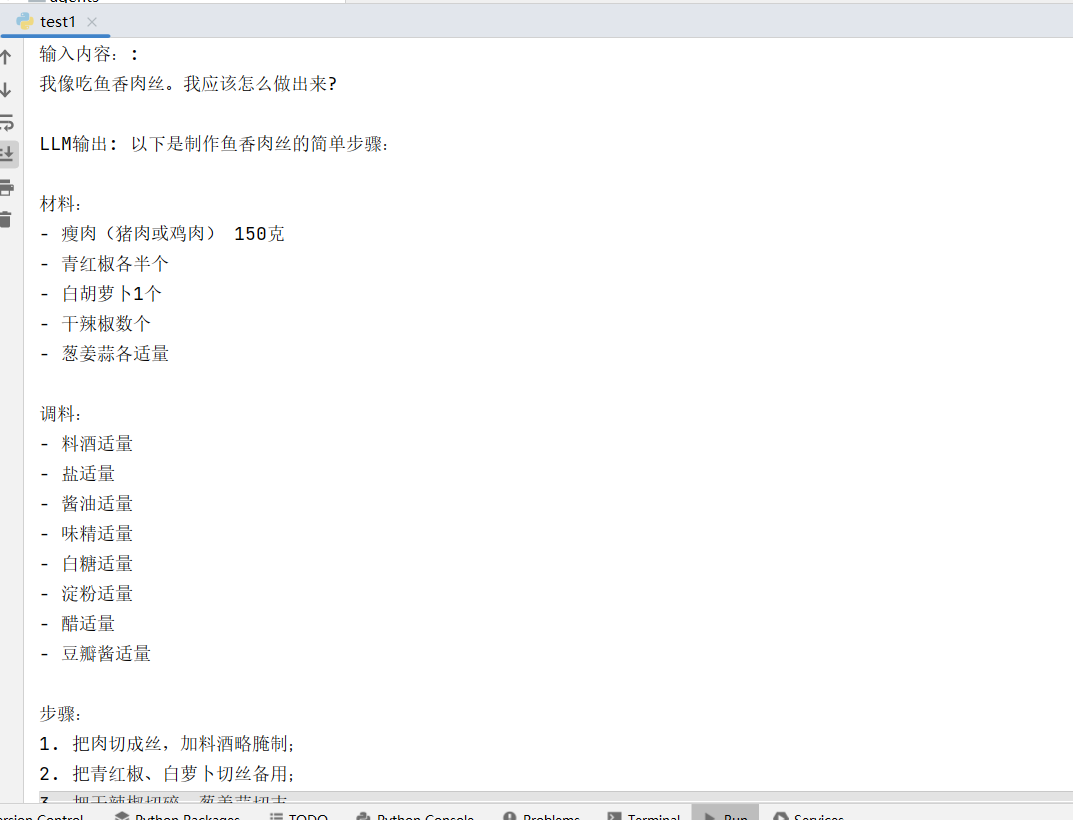
2.2 FewShotPromptTemplate 选择器示例
将提示的示例内容同样拼接到语句中,让模型去理解语义含义进而给出结果。
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langchain.llms import OpenAI
import os## prompt 选择器示例
openai_api_key = os.environ["OPENAI_API_KEY"]llm = OpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key)example_prompt = PromptTemplate(input_variables=["input", "output"],template="示例输入:{input}, 示例输出:{output}",
)# 这是可供选择的示例列表
examples = [{"input": "飞行员", "output": "飞机"},{"input": "驾驶员", "output": "汽车"},{"input": "厨师", "output": "厨房"},{"input": "空姐", "output": "飞机"},
]# 根据语义选择与您的输入相似的示例
example_selector = SemanticSimilarityExampleSelector.from_examples(examples,# 生成用于测量语义相似性的嵌入的嵌入类。OpenAIEmbeddings(openai_api_key=openai_api_key),# 存储词向量FAISS,# 生成的示例数k=4
)
# 选择器示例 prompt
similar_prompt = FewShotPromptTemplate(example_selector=example_selector,example_prompt=example_prompt,# 加到提示顶部和底部的提示项prefix="根据下面示例,写出输出",suffix="输入:{value},输出:",# 输入变量input_variables=["value"],
)value = "学生"
# 模版生成内容
final_prompt = similar_prompt.format(value=value)print("输入内容::", final_prompt)
print("LLM输出:", llm(final_prompt))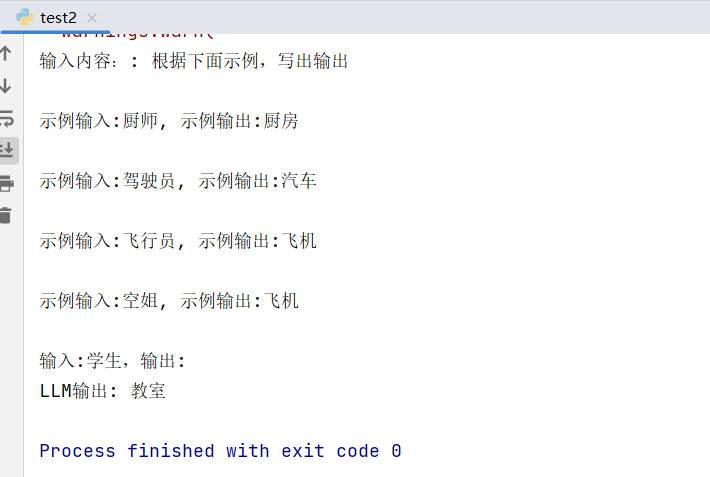
2.3 ChatPromptTemplate 聊天提示模版
以聊天消息作为输入生成完整提示模版。
from langchain.schema import HumanMessage
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
# 我们将使用聊天模型,默认为 gpt-3.5-turbo
from langchain.chat_models import ChatOpenAI
# 解析输出并取回结构化数据
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
import osopenai_api_key = os.environ["OPENAI_API_KEY"]
chat_model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key)prompt = ChatPromptTemplate(messages=[HumanMessagePromptTemplate.from_template("根据用户内容,提取出公司名称和地域名, 用用户内容: {user_prompt}")],input_variables=["user_prompt"]
)user_prompt = "阿里巴巴公司在江苏南京有分公司吗"
fruit_query = prompt.format_prompt(user_prompt=user_prompt)
print('输入内容:', fruit_query.messages[0].content)fruit_output = chat_model(fruit_query.to_messages())
print('LLM 输出:', fruit_output)
2.4 StructuredOutputParser 输出解析器
要使 LLM 模型返回我们需要的格式,可以直接告诉 LLM 你想要的结果格式,也可以通过 解析器来制定:
PromptTemplate + StructuredOutputParser
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, PromptTemplate
from langchain.llms import OpenAI
import osopenai_api_key = os.environ["OPENAI_API_KEY"]llm = OpenAI(model_name="text-davinci-003", openai_api_key=openai_api_key)
# 定义结构
response_schemas = [ResponseSchema(name="company", description="提取的公司名"),ResponseSchema(name="area", description="提取的地域名")
]
# 解析输出结构
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print('格式化的提示模板', format_instructions)template = """
根据用户内容,提取出公司名称和地域名
{format_instructions}
% 用户输入:
{value}
"""
prompt = PromptTemplate(input_variables=["value"],partial_variables={"format_instructions": format_instructions},template=template
)
final_prompt = prompt.format(value="阿里巴巴公司在江苏南京有分公司吗")print("输入内容::", final_prompt)
print("LLM输出:", llm(final_prompt))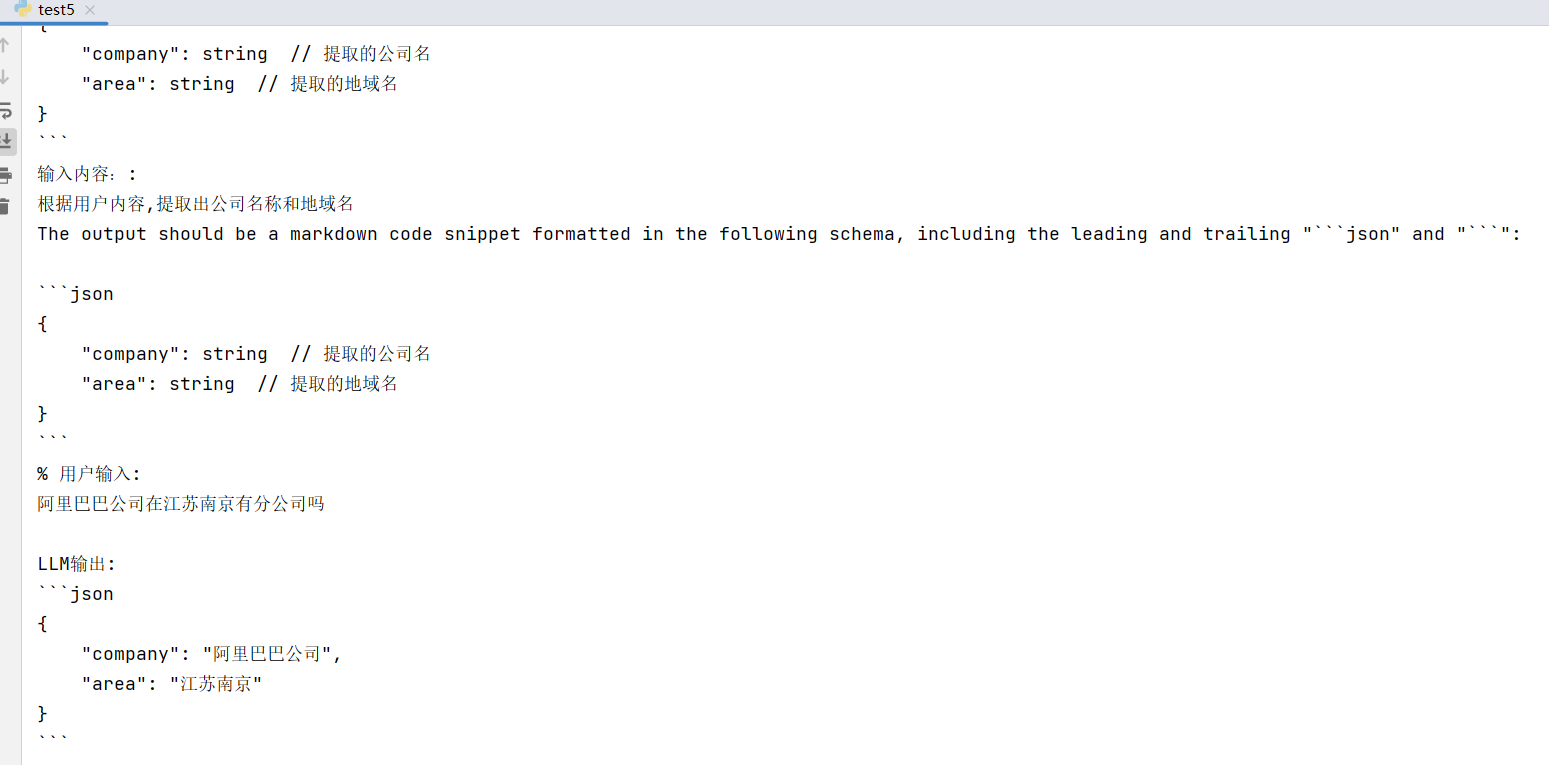
PromptTemplate + ChatPromptTemplate
from langchain.schema import HumanMessage
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
# 我们将使用聊天模型,默认为 gpt-3.5-turbo
from langchain.chat_models import ChatOpenAI
# 解析输出并取回结构化数据
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
import osopenai_api_key = os.environ["OPENAI_API_KEY"]
chat_model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key)response_schemas = [ResponseSchema(name="company", description="提取的公司名"),ResponseSchema(name="area", description="提取的地域名")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print(format_instructions)prompt = ChatPromptTemplate(messages=[HumanMessagePromptTemplate.from_template("根据用户内容,提取出公司名称和地域名 {format_instructions}, 用户输入: {value}")],input_variables=["value"],partial_variables={"format_instructions": format_instructions}
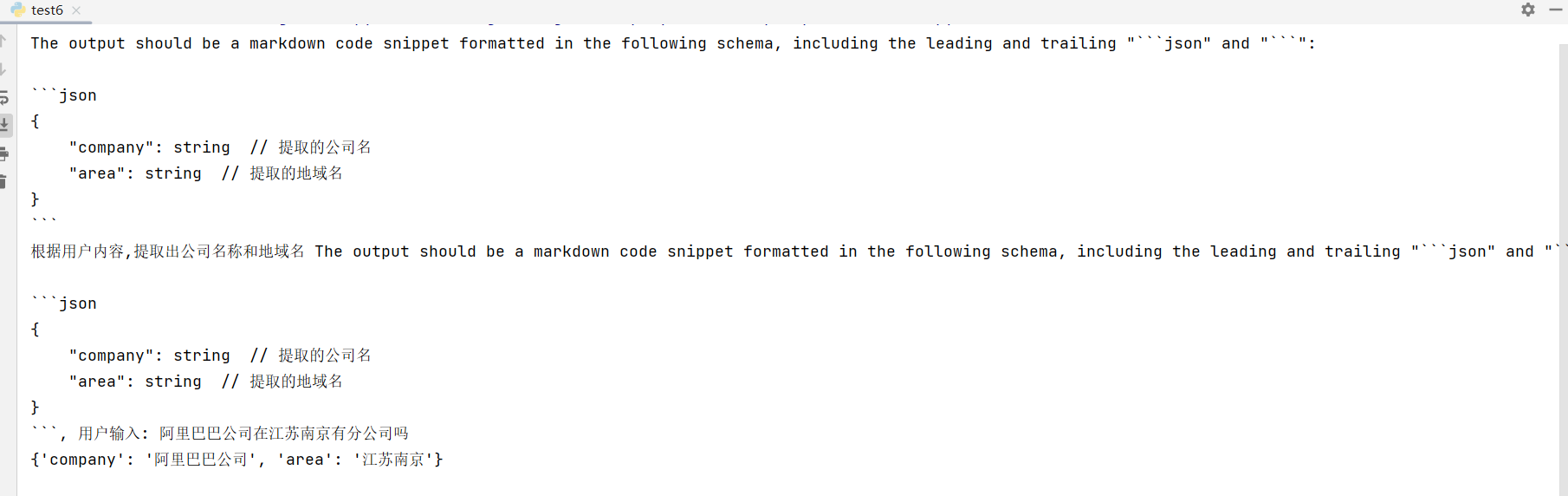
)fruit_query = prompt.format_prompt(value="阿里巴巴公司在江苏南京有分公司吗")
print (fruit_query.messages[0].content)fruit_output = chat_model(fruit_query.to_messages())
output = output_parser.parse(fruit_output.content)
print (output)
三、文件载入 和 Embeddings 文本向量化
例如有如下文本文件:
`LangChain` 是一个开发由语言模型`LLMs`驱动的应用程序的框架,它允许用户围绕大型语言模型快速构建应用程序和管道。 可以直接与 `OpenAI` 的 `GPT` 模型以及 `Hugging Face` 集成。通过 `langChain` 可快速构建聊天机器人、生成式问答(`GQA`)、本文摘要等应用场景。`LangChain`本身并不开发`LLMs`,它的核心理念是为各种`LLMs`提供通用的接口,降低开发者的学习成本,方便开发者快速地开发复杂的`LLMs`应用。`LangChain`目前有两个`python` 和 `nodejs` 两种版本实现,`python` 支持的能力较多,下面都基于 `Python` 演示其部分功能。`LangChain` 中主要支持的组件有如下:- `Models`:各种类型的模型和模型集成,比如`OpenAI` 的 `ChatGPT`。
- `Prompts`:提示管理、提示优化和提示序列化,通过提示微调模型的语义理解。
- `Memory`:用来保存和模型交互时的上下文状态。
- `Indexes`:用来结构化文档,以便和模型交互。
- `Chains`:一系列对各种组件的调用。
- `Agents`:决定模型采取哪些行动,执行并且观察流程,直到完成为止。
3.1 文件加载与分割
自己进行文件的加载,然后对字符串进行分割:
from langchain.text_splitter import RecursiveCharacterTextSplitterwith open('data/test.txt', 'r', encoding="utf-8") as f:value = f.read()# 文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=100,
)
# 创建文档
texts = text_splitter.create_documents([value])
print("文档数:", len(texts))# 拆分后的文档
for doc in texts:print(doc)
使用文本加载器,加载文本:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader# 使用文本加载器
loader = TextLoader('data/test.txt', encoding="utf-8")
documents = loader.load()# 文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=100,
)
# 分割文档
texts = text_splitter.split_documents(documents)
print("文档数:", len(texts))# 拆分后的文档
for doc in texts:print(doc)
3.2 Embeddings 文本向量化
文本向量化,可以计算出文本的相似性:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
import osopenai_api_key=os.environ["OPENAI_API_KEY"]
# 使用文本加载器
loader = TextLoader('data/test.txt', encoding="utf-8")
documents = loader.load()# 文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=100,
)
# 分割文档
texts = text_splitter.split_documents(documents)
print("文档数:", len(texts))
# 拆分后的文档
for doc in texts:print(doc)
# 准备嵌入引擎
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# 向量化
# 会对 OpenAI 进行 API 调用
db = FAISS.from_documents(texts, embeddings)
# 初始化检索器
retriever = db.as_retriever()
# 根据语义获取最相近的文档
docs = retriever.get_relevant_documents("介绍下什么是 langchain ?")
print('结果:', docs)
四、memory 多轮对话
对于聊天应用中,记录聊天的记录给到模型可以回答出更加准确的回答,最前面第一点介绍的案例只有一个简单的问答,如果是多轮对话就可以修改为如下格式:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
import osopenai_api_key=os.environ["OPENAI_API_KEY"]
chat = ChatOpenAI(temperature=0.7, openai_api_key=openai_api_key)
## 多轮对话
res = chat([SystemMessage(content="你是一个很好的 AI 机器人,可以帮助用户在一个简短的句子中找出去哪里旅行"),HumanMessage(content="我喜欢海滩,我应该去哪里?"),AIMessage(content="你应该去广东深圳"),HumanMessage(content="当我在那里时我还应该做什么?")]
)
print('多轮对话', res)
还可以基于 Memory 组件中的 ChatMessageHistory :
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAI
import osopenai_api_key=os.environ["OPENAI_API_KEY"]
chat = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)# 声明历史
history = ChatMessageHistory()
history.add_user_message("你是一个很好的 AI 机器人,可以帮助用户在一个简短的句子中找出去哪里旅行")
history.add_user_message("我喜欢海滩,我应该去哪里?")
# 添加AI语言
history.add_ai_message("你应该去广东深圳")
# 添加人类语言
history.add_user_message("当我在那里时我还应该做什么?")print('history信息:', history.messages)
# 调用模型
ai_response = chat(history.messages)
print('结果', ai_response)# 继续添加 AI 语言
history.add_ai_message(ai_response.content)
print('history信息:', history.messages)# 继续添加人类语言
history.add_user_message("推荐下美食和购物场所")
ai_response = chat(history.messages)
print('结果', ai_response)
五、chain 顺序链
5.1 简单顺序链
可以使用 LLM 的输出作为另一个 LLM 的输入。有利于任务的分解:
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
import osopenai_api_key = os.environ["OPENAI_API_KEY"]
llm = OpenAI(temperature=1, openai_api_key=openai_api_key)# 第一个链模版内容
template1 = "根据用户的输入的描述推荐一个适合的地区,用户输入: {value}"
prompt_template1 = PromptTemplate(input_variables=["value"], template=template1)
# 构建第一个链
chain1 = LLMChain(llm=llm, prompt=prompt_template1)# 第二个链模版内容
template2 = "根据用户的输入的地区推荐该地区的美食,用户输入: {value}"
prompt_template2 = PromptTemplate(input_variables=["value"], template=template2)
# 构建第二个链
chain2 = LLMChain(llm=llm, prompt=prompt_template2)# 将链组装起来
overall_chain = SimpleSequentialChain(chains=[chain1, chain2], verbose=True)# 运行链
review = overall_chain.run("我想在中国看大海")
print('结果:', review)
5.2 总结链
有时候对于大量的文本内容进行摘要总结,可能无法一次性加载进来,此时可借助总结链进行总结:
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
import osopenai_api_key = os.environ["OPENAI_API_KEY"]loader = TextLoader('data/test.txt',encoding="utf-8")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=50)
texts = text_splitter.split_documents(documents)llm = OpenAI(temperature=1, openai_api_key=openai_api_key)
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
review = chain.run(texts)
print('结果:',review)
六、问答
通过本地知识库微调模型,回答出更加准确的信息。
from langchain import OpenAI
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
import osopenai_api_key = os.environ["OPENAI_API_KEY"]
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)loader = TextLoader('./data/test.txt',encoding="utf-8")
doc = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
# 嵌入引擎
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# 词向量
docsearch = FAISS.from_documents(docs, embeddings)
# 创建检索引擎
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())res = qa.run("介绍下什么是 langchain ")print(res)