引导
在上一节中,我们学习到二分查找,惊叹于它超高的效率(时间复杂度为O(logn))。但是二分查找有一个局限性就是依赖于数组,这就导致它应用并不广泛。
那么适用链表是否可以做到呢?答案是可以的。只不过要复杂一点,算法中称为跳表。应用很广泛。
跳表
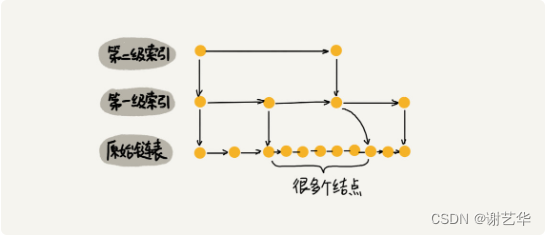
跳表的实质就是通过多级索引结构加快查找速度。这么说可能不理解,我们通过下面一系列图来进行理解。
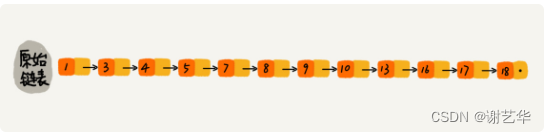
我们在链表中查找一个元素的时间复杂度时O(n),这个我们在链表章节已经说明了。但是如何能够提高查找的效率呢?如果加上索引是否会快一些。
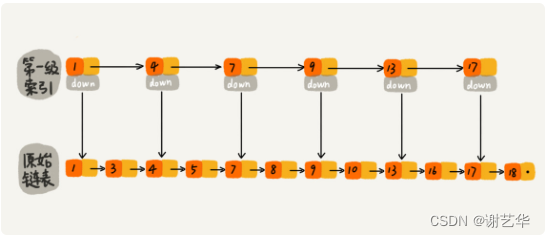
如上图所示,我们每两个节点添加一个索引。通过这样的结构,查找13这个元素。原先需要9次比较操作,现在只需要5次。是不是减少了很多?但是当数据量n很大时,每两个节点引出一个索引,那么第一级索引就有n/2个节点。这样在第一级索引中也会消耗很多时间。
有什么好的解决方式吗?--多级索引

通过添加多级索引,能够加快我们的查找速度,这就是跳表。
跳表的效率
我们通过上面的图,了解到跳表的确能够提高我们的查找速度,但是它的时间复杂度时多少呢?我们继续上面的例子来分析。
假设我们原始链表的长度为n,那么第一即的索引个数就是n/2,第二级索引个数就是n/4,...第k级索引个数就是n/2^k。

每层索引最多查找3次。故该跳表的最差情况的时间复杂度是O(3*logn)=O(logn)。
其实我们知道这也是典型的空间换时间的方式。这么多的索引岂不是很浪费内存?
跳表浪费内存吗?
答案是肯定的,这么多的索引节点,当然会浪费内存。根据上面的跳表,我们也可以计算出空间复杂度为O(n-2)。但是这种空间的浪费重要吗?或者说有什么方式可以缩减这个空间消耗呢?
- 通过跳表原理的介绍,我们知道索引节点只需要存储几个指针和关键值。相对于原始数据中可能是很大的对象,这个就可以忽略了。
- 我们也可以增加节点间隔来产生索引,比如10个节点产生一个索引。你可以尝试计算一下空间复杂度
插入删除
我们知道链表的插入删除操作的时间复杂度是O(1),但无奈于插入删除之前有查找操作,这就导致实际中我们想要删除或插入一个节点的时间复杂度是O(n)。现在跳表查找的时间复杂度是O(logn),那么我们插入删除的炒作也就是O(logn)。
插入操作:
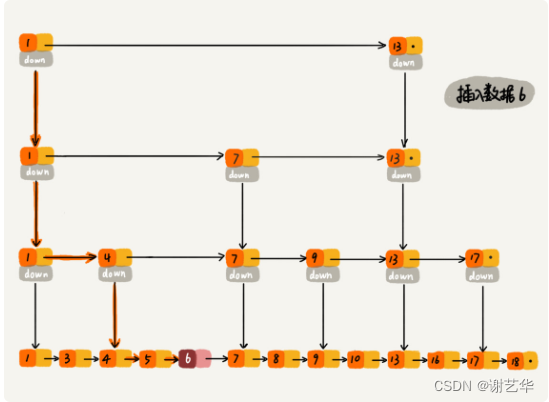
插入一个数据变得更加高效了。如果只在原始链表中进行数据的插入,不对索引进行更新,就会出现下面的问题:
这样复杂度容易退化O(n)。因此跳表的删除,插入操作一定要更新索引表,用来保持这种平衡:当原始数据多了,就适当增加索引的节点。避免复杂度退化。
跳表平衡的维护
一般这种平衡性是通过随机函数来维持的。一般常用的方式是抛硬币法。我将会在代码中进行解析。
| #include<stdlib.h>
#include<stdio.h>
#include<string.h>
#define MAXLEVEL 15
typedef struct node{
int val;
struct node * level[MAXLEVEL];
}Node;
int initslist(Node* head)
{
head->val = -1;
memset(head->level,0,sizeof(Node*)*MAXLEVEL);
return 0;
}
int random_level(void)
{
int i, level = 1;
for (i = 1; i < MAXLEVEL; i++)
if (random() % 2 == 1)
level++;
return level;
}
insertslist(Node* head,int val)
{
int level = random_level();
Node* new = (Node*)malloc(sizeof(Node));
new->val = val;
memset(new->level,0,sizeof(Node*)*MAXLEVEL);
Node* p = head;
Node* update[MAXLEVEL] = {0};
int i = 0;
for(i = level - 1 ; i >= 0 ; i--)
{
while(p->level[i] && p->level[i]->val < val)
p = p->level[i];
update[i] = p;
}
for(i = 0 ; i < level ; i++)
{
new->level[i] = update[i]->level[i];
update[i]->level[i] = new;
}
}
Node * findslist(Node* head,int target)
{
Node * p = head;
int i = MAXLEVEL - 1;
for( ; i >= 0 ; i--)
{
while(p->level[i] && p->level[i]->val < target)
{
p = p->level[i];
}
}
if(p->level[0] && p->level[0]->val == target)
return p->level[0];
else
return NULL;
}
int deleteslist(Node* head, int target)
{
Node * p = head;
int i = MAXLEVEL - 1;
Node* update[MAXLEVEL] = {0};
for(; i >= 0 ; i--)
{
while(p->level[i] && p->level[i]->val < target)
p = p->level[i];
update[i] = p;
}
if(update[0]->level[0] == NULL || update[0]->level[0]->val != target)
return -1;
for(i = MAXLEVEL -1 ; i >= 0 ; i--)
{
if(update[i]->level[i] && update[i]->level[i]->val == target)
{
update[i]->level[i] = update[i]->level[i]->level[i];
}
}
return 0;
}
int printslist(Node* head)
{
Node * p = head;
int i = MAXLEVEL - 1;
for(; i >= 0 ; i -- )
{
p = head;
printf("Level[%02d]",i);
while(p->level[i])
{
printf(" %4d (%p)",p->level[i]->val,p->level[i]);
p = p->level[i];
}
printf("\n");
}
printf("\n");
}
int main()
{
Node head;
initslist(&head);
srandom(time(NULL));
int i =0;
for(i = 20 ; i < 30 ; i++)
insertslist(&head,i);
printslist(&head);
Node* temp = findslist(&head,25);
printf("temp = %p\n",temp);
deleteslist(&head,25);
printslist(&head);
return 0;
} |
总结
本节我们接触到了跳表这种数据结构。它的查找,删除,插入操作时间复杂度都是O(logn),并且不依赖于数组,因而它的应用场景更加广泛。
跳表是利用空间换时间的方式得到更高的效率。
跳表在插入删除操作的时候不仅仅要对原始链表进行处理,也要更新索引结构,以保持两者的平衡,避免复杂度退化。保持平衡的方法一般用“抛硬币”方式。
跳表的实现并不简单,需要好好琢磨并练习。