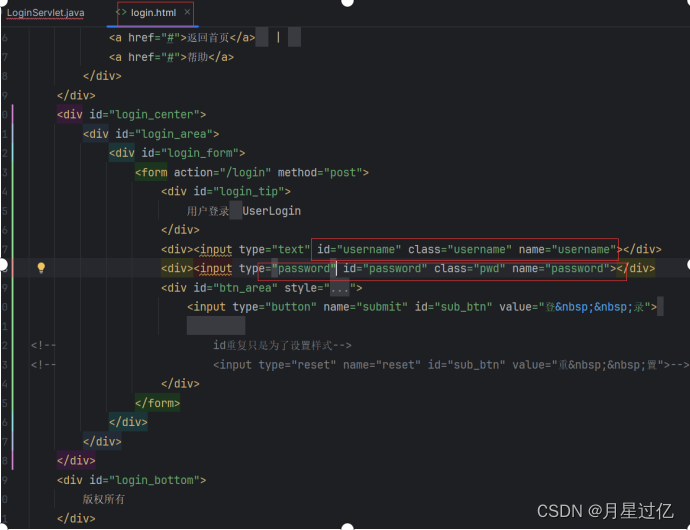
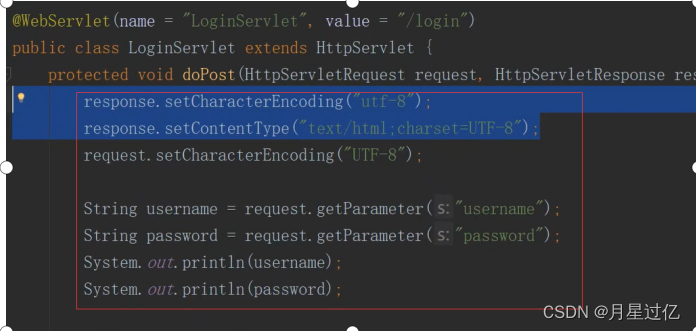
选择20道
填空10道
判断10道
简答4-5道
编程题2道
一、选择题
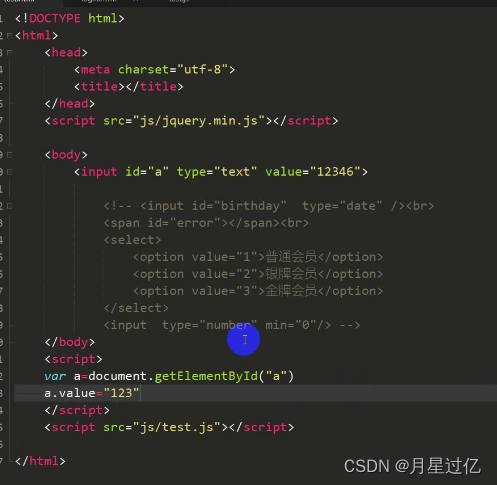
1.js中更改一个input框的值:
<input id='a' type="text" value="123456">
通过a.value改变他的值
方法:
- 在script标签中通过id获得该输入框对象,然后通过value属性修改
- <script>var a=document.getelementById("a")
- a.value="123"
- </script>
2.CSS更改文字颜色
css中通过标签选择器,来改变标签内字体的颜色
<style>
p{ color :red;
}
</style>

3.CSS样式的内外边距(上下左右四个值)
看padding属性值的个数
<head>
<style>
.b{ width:100px
height:100px
background-color:green;
Padding:10px 20px; //边距的大小
//padding的值的个数: 1个 上下左右
2个 上下、左右
3个 上、左右、下
4个 上 、右、下、左
}
</style>
<div class="b">
</head>
4.超链接 下划线 鼠标移到超链接使超链接的下划线消失
<html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><style>a:hover{text-decoration: none;}</style></head><body><a href="http:www.baidu.com">a</a> </body>
</html>
<style>
a:hover{
text-decoration: none;//鼠标选中超链接下划线小时
}
</style>
5.js中的函数function 可不可以有返回值,可不可以有参数
js 中的函数可以有返回值,也可以有参数 通过 return 返回。
<script>
function a (b=10){
return b;
}
</script>
6.hadoop中用递归方式查询子目录命令
hdfs dfs -ls 文件夹名

7.在数据库中查询名称不为空或者为空的用什么样的查询语句。
select * from 表名 where name is not null;
8. 有条件(where)的分组查询
select count(uid),uid from 表名 where level=0 groupby uid;
- 分组条件要与前面统计函数的条件相同
- where要在group之前
9.启动/停止Hadoop的所有服务
启动:start-all.sh
停止:stop-all.sh

10.在linux中创建/查看文件有哪些方式
创建文件
- vi a.txt //编辑器创建文件
- echo "aa" >b //重定向创建文件
- touch abc
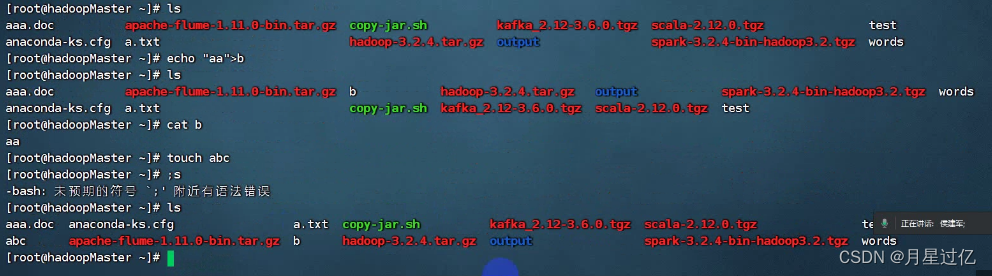
查看文件
- ls 查看文件夹
- cat 查看文件
11.数据库中的模糊查询(查询所有带2的数据)
select uid from 表名 where uid like '%2%'
使用like函数进行模糊查询 并且 % 作为替位符用于匹配多个值
12.mysql数据库中主键和唯一约束的区别
主键和唯一约束都是用于保证表中数据的唯一性,但它们之间还是有一些区别的。
主键是一种特殊的唯一约束,它要求表中的每一条记录都必须有一个唯一标识,这个标识就是主键。主键可以由一个或多个列组成,但是主键列上的值必须是唯一的,而且不能为空。主键还可以作为外键,用于建立表与表之间的关系。
唯一约束也要求表中的每一行都有唯一标识,但是它与主键的区别在于,唯一约束允许空值(NULL),而主键不允许空值。此外,一个表可以有多个唯一约束,但只能有一个主键。
- 主键不能为空 可以使任意类型的数据
- 唯一约束约束的字段可以为空
- 一个表可以有多个唯一约束,但是只能有一个主键
13.hdfs配置副本的数量
<configuration>
<property>
<name>dfs.replication</name> //副本
<value>1</value> //配置副本的数量 默认情况为3
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
14.java中如何抛出异常
Public void a() throws Exception{ //抛出异常
throw New Exception(); //产生异常并抛给上级(方法)
}
15.=&==的区别
boolean a = false;
If(a=true){ //注意“=”还是“==”
System.out.println(“aaa”);
}
a=true 只是个赋值语句 而非== 判断是否相等 a永远是true 所以会打印
16.Session
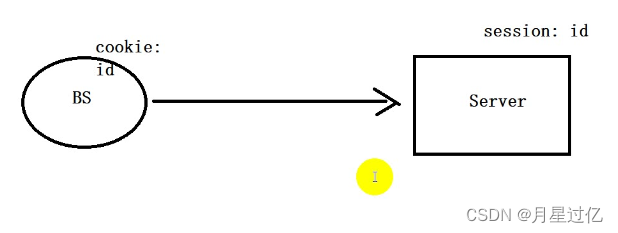
- session 主要保存id 用于浏览器和服务器的交互
- 第一次访问后服务端会向浏览器发送一个id 由Session携带(与cookie组成会话跟踪技术)
- 下一次访问仍携带该id证明已经登陆过。
- session是服务端机制 不是客户端机制
-
17.servlet的生命周期中,容器只调用一次的方法
- servlet的初始化方法 init()
-
18.servlet实现请求转发的方法
-
forward 通过RequestDispatcher.forward()方法转发
-
19.hdfs-site.xml中配置的属性
-
<configuration>
<property>
<name>dfs.replication</name> //副本
<value>1</value> //配置副本的数量 默认情况为3
</property>
<property>
<name>dfs.permissions</name>//配置hdfs权限
<value>false</value>
</property>
</configuration>
- 1.dfs.replication
- 2.dfs.permissions
-
二、填空题
-
1.java的数据类型有 基本类型 和引用类型
-
2.通过display属性进行弹性盒子布局的属性有 flex
- 1.其默认值为inline,这意味着此元素会被显示为一个内联元素,在元素前后没有换行符;
- 2.设置display的值为flex,则表示用于指定弹性盒的容器;
- 3.如果设置display的值为none,则表示此元素不会被显示。
-
3.html中根据标签的特点分成哪几类,三大类 行内元素、块级元素、行内块级元素
-
4.在hadoop中查看进程,看进程命令 jps
-
5.Java中集合分两大类,有序和无序两大类 list 和set
-
6.hdfs中进行数据存储的节点 namenode
-
三、判断题
-
1.在vi中删除一行用什么命令 ?dd
-
2.主键的创建 即可以在创建表时创建 也可以在创建表后 使用alter命令更新主键 正确
-
3.SQL语句大小写是敏感的 错误
-
sql语句的大小写是不敏感的,mysql不会区分大小写
-
4.在Java中可以用来声明方法和类,如果方法抽象必须使用关键词abstract 正确
-
5.在Java中多态将一个父类的引用指向一个子类,需要进行强制转换 错误
-
不需要强制转换 直接可以用 子类转父类需要转换 父类转子类不需要转换
-
6.在css里如果是弹性布局是css3
- CSS3中有弹性布局新样式 CSS2中没有
-
7.JavaEE中两个对象HttpServletResponse的接口继承于HttpServlet调用HttpResponse的请求 错误
- response 是响应信息 request是请求信息
-
8.htfs有多个副本,所以NameNode不存在单节点问题 错误
- 名称节点只有一个 所以存在单节点问题
-
9.hadoop中block size 块大小128MB不能改变 错误
- 可以改变
-
三、简答题
-
1.简单,简要描述如何安装配置一个阿帕奇开源版的hadoop描述即可
-
下载解压、关闭防火墙,安装jdk、配置环境变量、修改主机名、修改配置文件、格式化hdfs、启动进程start-all
-
2.statement,preparedstatement关系和区别
-
关系:Statement和PreparedStatement都是Java中用于执行SQL语句的接口,其中PreparedStatement继承自Statement。
-
区别:
-
1.PreparedStatement可以使用占位符,是预编译的,批处理比Statement效率高。
-
2.Statement在执行一次性存储的时候使用,因为PreparedStatement的开销比较大。
3.PreparedStatement可以在执行SQL语句之前进行预编译,这样可以提高执行效率。而Statement则是每次执行SQL语句时都需要进行编译,效率相对较低。
-
4.PreparedStatement可以使用占位符,这样可以避免SQL注入攻击。而Statement则需要将参数直接拼接到SQL语句中,容易受到SQL注入攻击。
-
3.抽象类和接口的区别:
1.接口和抽象类都不能被实例化,如果实例化抽象类必须指向实现所有抽象的方法的实例对象,接口变量必须指向所有接口方法类的对象。
2.抽象类被子类继承,接口就要被实现,抽象类被子类继承,接口被子类实现
3.接口只能做方法声明,抽象类可以做方法声明,也可以做方法实现
4.接口里定义的变量只能是公共的、静态的常量,不能定义变量。抽象类中定义的变量就是常量
5.抽象类的抽象方法必须被子类所实现,如果子类不能完全实现父类的抽象方法,那么该子类也应该被设为抽象类。同样实现接口的时候,如果不实现接口的方法,那么该类也必须成为抽象类
6.抽象方法只能声明不能实现,接口是设计的结果,抽象类是重构的结果,抽象方法只能声明不能实现
7.抽象类里可以没有抽象方法,接口里的方法必须都是抽象方法
8.如果一个类里有抽象方法,那么这个类只能是抽象类。
9.抽象方法要被实现,所以不能是静态的,也不能是私有的必须是public或者是protect
-
10.接口可以继承接口,并可以多继承接口,但类只能单继承
-
4、事务的四大特性
-
事务的四大特性是ACID,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
-
-
原子性:指一个事务中的所有操作要么全部完成,要么全部不完成,不可能停滞在中间某个环节。如果在事务执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性:指事务执行前后,数据库从一个一致性状态变为另一个一致性状态。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。比如,转账事务中,无论事务是否成功,转账前后两个账户的总金额应该保持不变。
-
隔离性:指并发执行的事务之间是相互隔离的,一个事务的执行不能被其他事务干扰。每个事务都有完整的数据空间,事务内部的操作及使用的数据对其它并发事务是隔离的,各个事务之间是不能互相干扰的。
-
持久性:指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其执行结果有任何影响。数据库应该能够保证即使发生了系统故障,也不会丢失提交事务的操作。
-
5.hdfs体系结构
主从结构模型,可以一主多从,hadoop3也可以多主多从,一个hdfs集群主要时由一个NameNode和若干个DataNode组成的,其中NameNode为主服务器,也就是主从结构,管理文件,系统的命名空间,和客户端对文件的访问操作。集群中的DataNode管理存储的数据
四、代码题
1.在hadoop中wordCount
public class WordCount {/*** 创建一个Map类* 存储数据*/public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {// 定义一个常量:1private final static IntWritable one = new IntWritable(1);// 定义一个key对象 Textprivate Text word = new Text();protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {// Spark HBaseStringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreElements()) {word.set(itr.nextToken());// 输出给reducecontext.write(word, one);}}}/*** 创建一个Reduce类* 计算*/public static class SumReduce extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {Iterator var4 = values.iterator();int sum = 0;while (var4.hasNext()) {IntWritable data = (IntWritable) var4.next();sum += data.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {String inputPath = "hdfs://hadoopMaster:9000/data/words";String outPath = "hdfs://hadoopMaster:9000/data/result";// 1.创建配置Configuration conf = new Configuration();// 2.创建一个任务Job job = Job.getInstance(conf, "word count");// clientjob.setJarByClass(WordCount.class);// 设置Mapper类job.setMapperClass(TokenizerMapper.class);// 合并job.setCombinerClass(SumReduce.class);// 计算job.setReducerClass(SumReduce.class);// Text 要与reduce指定输出类型对应job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 指定输入数据FileInputFormat.addInputPath(job, new Path(inputPath));// 指定输出结果FileOutputFormat.setOutputPath(job, new Path(outPath));// 等待任务结果System.exit(job.waitForCompletion(true) ? 0 : 1);}2.Web开发servlet写一个登录,使用jsp写一个表单提交,用户名和密码,用servlet里面获取数据