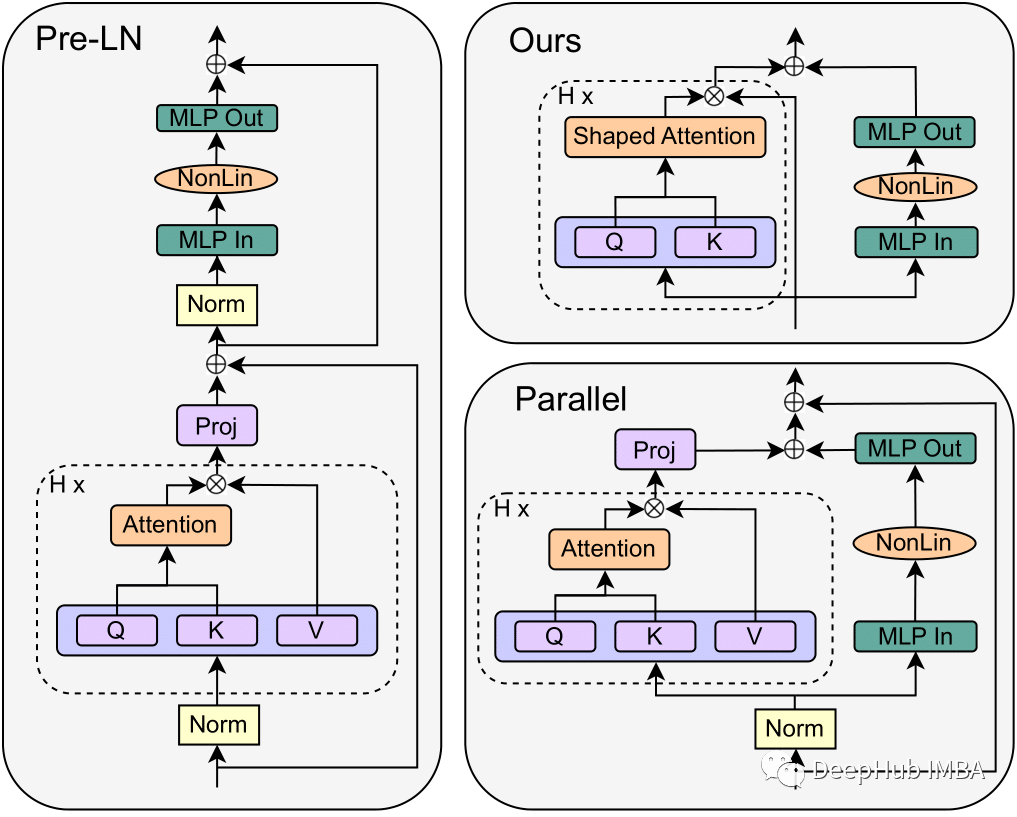
在这篇文章中我将深入探讨来自苏黎世联邦理工学院计算机科学系的Bobby He和Thomas Hofmann在他们的论文“Simplifying Transformer Blocks”中介绍的Transformer技术的进化步骤。这是自Transformer 开始以来,我看到的最好的改进。
大型语言模型(llm)可以通过各种扩展策略扩展其功能。更直接的方法包括放大计算资源——这是一个应用人工智能工程的问题,通常更容易获得。而另一种更微妙、更有效的方法涉及改进底层的数学框架。这种方法代表了人工智能研究的前沿,是一项很少有人能熟练驾驭的努力。
论文摘要
在设计深层Transformer 时,一种常见的方法是使用复杂的组件组成,这些组件块由交织在一起的注意力和MLP子块、跳过连接和规一化层组成。这种复杂性会使这些体系结构变得脆弱,即使是很小的更改也会显著影响训练速度或使模型无法训练。
论文研究以信号传播理论及实证研究结果为基础,探讨标准Transformer 块的简化方法。证明了许多组件,如跳过连接、投影或值参数、顺序子块和归一化层,可以在不牺牲训练速度的情况下被删除。
在纯自回归解码器和纯BERT编码器模型上的实验表明,论文的简化Transformer 实现了与标准Transformer 相当的训练速度和性能,同时训练吞吐量提高了15%,使用的参数减少了15%。
缩放定律
如前所述扩展LLM相对简单的方法之一是不断增加参数大小和训练语料库。正如LLM缩放定律所描述的那样,从中获得的收益实际上是免费的。有一整篇论文都在讨论这个问题。
(DEEP)Scaling Laws(HUB) for Neural Language Models
https://arxiv.org/abs/2001.08361
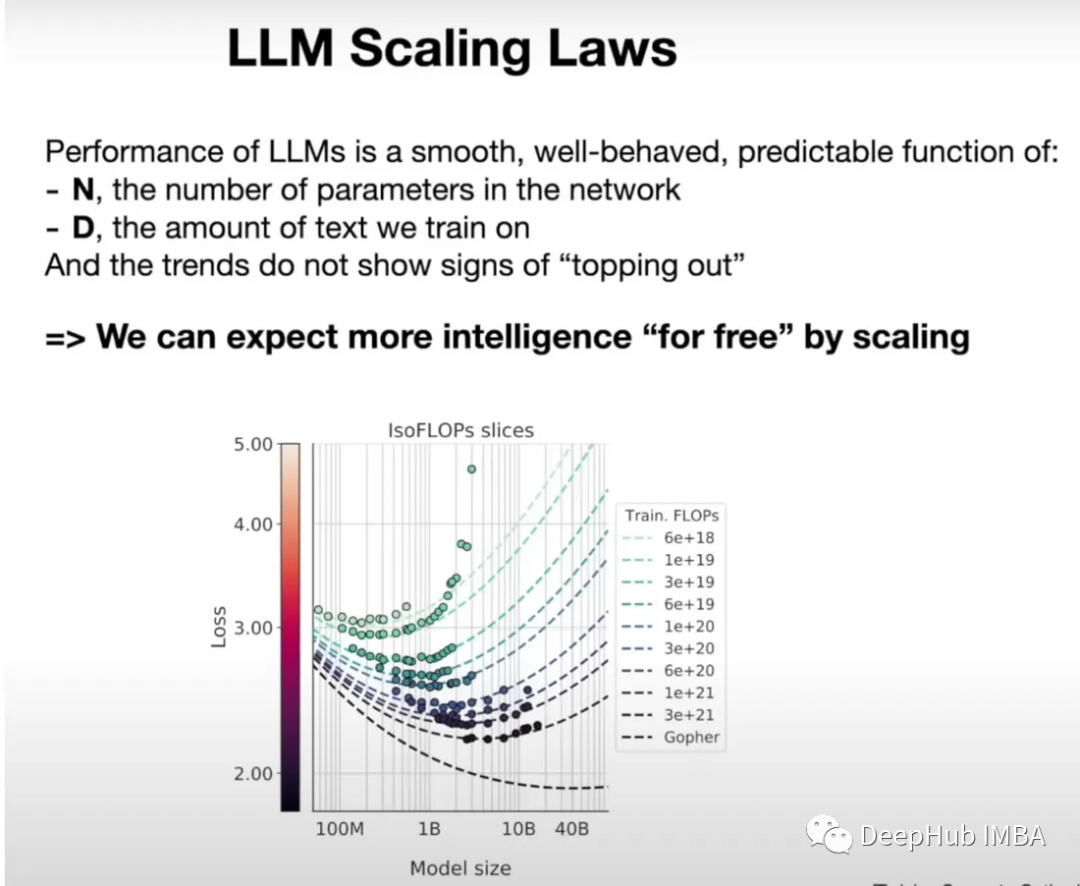
从理论上讲,Transformer 可以继续扩展更多的参数,更大的数据集,并增加计算资源。但是在实践中,有几个约束限制了可以缩放的程度。
为了加深我们对缩放限制的理解,首先要考虑一个数学框架,它涵盖了了LLM性能的多个方面。这样的框架必须考虑到随着数据规模的增加参数收益的递减,以及模型架构效率和计算约束之间复杂的相互作用。
我们将P(n,d,θ)定义为LLM的潜力,其中n是参数的数量,d是训练数据的大小,θ封装了模型架构的效率。P可以用递归函数来描述:
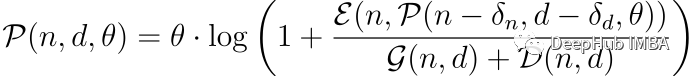
E表示参数利用效率,这是一个非线性函数,可能随着参数数量的增加而减小。
δn和δd分别表示参数数量和数据集大小的减少,使我们能够检查额外资源的边际效用。
G体现了计算约束,一个随n和d超线性增长的函数,代表了与更大的模型和数据集相关的不断增长的计算成本。
D反映了数据集的复杂性或难度,它也随着数据集大小的增加而增长,并引入了更多具有挑战性的学习问题。
E、G和D之间错综复杂的相互作用就是Transformer 缩放的最终结果:
参数利用效率(E):随着模型的扩展,由于信息的冗余,每个附加参数对模型性能的贡献较小,这些信息由n的双曲函数或其他次线性函数表示。
计算约束(G):计算成本随模型规模和数据集规模的增长均大于线性,反映了训练的超线性时间复杂度。
数据集复杂性(D):随着添加的数据越来越多,增量数据复杂性也会增加,需要更细致的模型能力来有效地捕获这种复杂性。
递减收益:对数项确保P的增长率是次线性的,与经验观察的收益随着模型大小的增加而减少相一致。
在实践中,随着n和d的增加,P趋于渐近线,这些因素共同对llm的有效缩放施加了实际限制。从环境和经济方面的考虑进一步加剧了这一饱和点,这些因素没有明确包括在模型中,但在实际应用中至关重要。
因此当n和d接近无穷大时,函数P在数学上可以无限增长,但现实世界的情况会限制LLM缩放,因为复杂的非线性生长函数P强调了经验现实,即Transformer 架构的缩放确实存在实际限制。
所以我们就需要提升数学公式的计算效率来解决这个问题,这也就是我们上面说的改进底层的数学框架。
Transformer模块的改进
Transformer 模型中的注意力机制可以被分解成一个多层次的过程,它包好了线性代数和概率论的概念。注意力函数是查询和一组键值对到输出的映射,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性函数计算的。
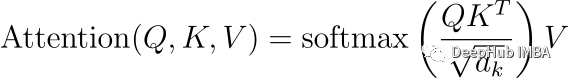
这个公式大家肯定都很熟悉,它包含几个复杂的运算:
点积QK^T:每个查询通过点积与所有键匹配,创建一个分数矩阵,表示每个查询与每个键对齐的程度。
缩放因子dk:分数然后按键的维度的平方根的反比按比例缩小,减少有过大的点积值可能导致梯度不稳定的风险。
Softmax:将Softmax函数应用于缩放后的分数,将其转换为一组权重之和为1的概率分布。
带有V的加权和:使用注意力权重来取值向量的加权和,这是注意力机制的输出。
有了注意力机制,Transformer 块如下图所示:
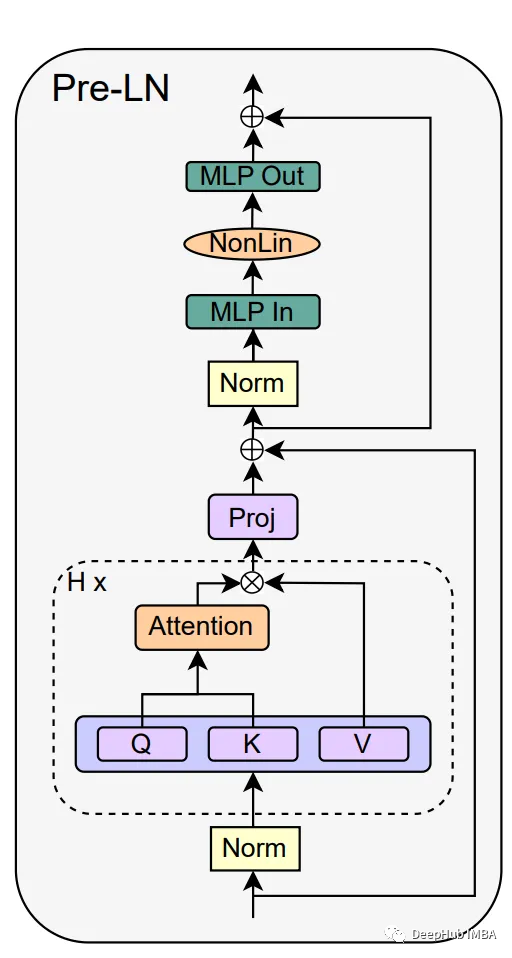
这也是我们常见的图,下面我们逐一介绍论文的改进过程
1、移除注意力子块跳过连接
为了加深对论文中提出的修改的数学理解,就需要深入研究注意力机制和所引入的修改的复杂性。
Transformer 的崩溃问题:
注意矩阵的秩是至关重要的,因为它反映了流经网络的信号的维数。当这个秩被降低时,秩崩溃就会发生,这会限制模型学习复杂模式的能力。在数学上如果注意力矩阵A的秩显著降低,则意味着该矩阵变得更接近于低维子空间,从而失去了捕捉数据中各种关系的能力。
为了防止秩崩溃,引入了Value-SkipInit修改。Transformer原有的注意力机制可以使用下面的矩阵形式表现:
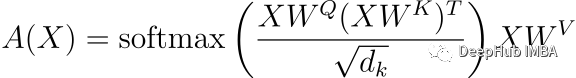
其中,WQ、WK、WV分别为查询、键和值的权值矩阵,dk为键的维数。Value-SkipInit论文:
Deep (HUB)Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation
https://arxiv.org/abs/2302.10322
将其修改为:
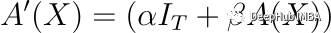
A ’ (X)为修正后的自注意力矩阵,α和β为可训练标量,I_T为大小为T×T的单位矩阵。这种修改保证了即使自注意机制倾向于较低的级别,αIT的加入也抵消了崩溃的影响。
通过维度扩展通过引入定心矩阵C扩展了这一概念
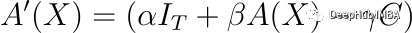
将定心矩阵(Centering Matrix)C设置为查询键乘积为零时的自注意力值,确保注意机制的初始状态偏向于同一性映射。这有助于稳定早期训练阶段,在那里A(X)的秩可能不够多样化。
信号流的稳定性:通过引入αIT,该修改确保了跨层的信息流的最小程度的多样性,这对于学习复杂模式至关重要。
对注意动力的控制:参数α、β和γ提供了一种控制注意机制的学习的机制,允许在保持同一性和从数据中学习之间取得平衡。
对同一性的初始偏差:C的包含使注意力机制最初偏向于同一性映射,在早期训练阶段提供稳定性,并随着训练的进行逐渐允许模型学习更复杂的依赖关系。
2、没有跳过链接的训练速度
下面要研究同一性注意力矩阵在Transformer 中的作用及其对训练动态的影响。这种方法用单位矩阵初始化注意机制,可以通过一系列复杂的方程来概念化。
当用单位矩阵初始化注意机制时,初始阶段的注意计算简化为:

A_init (X)表示初始化时的自关注输出。
I表示单位矩阵。
X是输入矩阵。
Softmax是应用于缩放后的点积的Softmax函数。
Dk是键的维数,用于缩放点积。
表达式IXIT化简为X,假设I是单位矩阵匹配X的维数。
IV项化简成V如果V与I的维数相同。
由于IXIT化简为X,假设IV化简为V,则方程为:
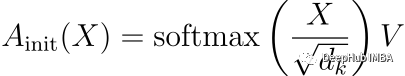
在修正后的方程中:
A_init (X)表示初始化时的注意力输出。
X是输入矩阵。
Softmax是应用于缩放后的输入矩阵的Softmax函数。
Dk是键的维度,用于缩放。
V是值矩阵。
考虑到初始化时上述公式的简单性,Transformer 的行为类似于线性模型。这可以进一步表示为:
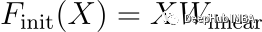
其中W_linear表示由简化的注意力机制和Transformer 块的其余部分(如前馈网络)引起的有效线性变换。
随着训练的进展,注意力矩阵进行了更新学习,允许模型捕获更复杂的依赖关系。这种演变可以建模为:
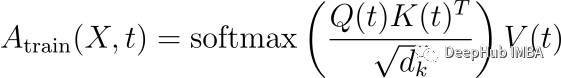
t为训练步长,Q(t)、K(t)、V(t)随训练而进行了更新。
从A_init到A_train的过渡可以使用参数λ(t)来建模,该参数在初始线性行为和复杂注意力机制之间进行插值:
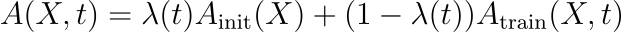
A(X,t)表示时刻t的自注意力输出。
λ(t)是一个与时间相关的参数,它在注意机制的初始状态和训练状态之间进行插值。
A_init (X)是初始的自注意力输出。
A_train (X,t)为时刻t训练时的自注意力输出。
该方程结合了这两种状态,随着λ(t)随时间的变化逐渐从初始状态过渡到训练状态。
随着训练的进行,λ(t)从1减小到0。
这个数学过程揭示了用恒等注意矩阵初始化Transformer 如何影响其早期训练行为,从而获得可预测和稳定的学习阶段,逐渐过渡到捕获更复杂的模式。这种方法平衡了早期训练对稳定性的需求和Transformer 在学习过程中发展复杂表征的能力。
3、删除“值”和投影参数
如果去掉数值和投影参数,会简化了Transformer 的内部结构。将这些矩阵设置为恒等式本质上将Transformer 的相关组件转换为线性层,从而降低了它们需要执行的操作的复杂性。
让我们看一下数学公式,这将有助于阐明如何设置值和投影矩阵来简化Transformer 的内部结构。
通过将值矩阵(WV)和投影矩阵§设置为单位矩阵,大大简化了自注意力机制。新的公式变成:
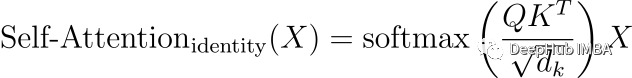
Self-Attention_identity (X)表示设置值矩阵和投影矩阵为恒等时,自注意层的输出。
Q和K是查询矩阵和键矩阵,通常计算为Q=XW^Q 和K=XW^K ,其中W^Q 和W^K 是相应的权重矩阵。
在这种情况下,不使用值矩阵V,而是使用输入矩阵X本身。将softmax函数应用于Q和K的标量点积,并将结果乘以X。
Dk表示关键向量的维数,用于缩放softmax函数中的点积。
简化的数学含义:
线性变换:用X代替V,使值变换变成线性操作,降低了注意力机制的复杂性。
减少参数空间:从方程中消除WV减少了可训练参数的数量,从而导致更有效的训练过程和更快的收敛速度。
对模型能力的影响:虽然这种简化降低了复杂性,但它也影响了模型学习复杂数据表示的能力。所以需要更多地依赖于其他的组件(如前馈网络)来捕获数据中的复杂模式。
改变的数据流:使用单位矩阵,通过网络的数据流发生了变化。注意力机制现在直接传播按注意权重缩放的输入数据X,改变了网络内信息处理的动态。
4、移除MLP子块跳过连接
为了加深对MLP子块跳过连接和在Transformer 中引入并行子块的数学理解,我们要对涉及多头注意(MHA)和多层感知器(MLP)块的新架构进行剖析和详细说明。该方法通过并发处理提高了模型的效率。
在传统的Transformer 中,每一层的输出是顺序计算的,首先通过MHA子块,然后通过MLP子块。数学上这可以表示为:
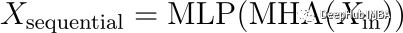
其中X_in是层的输入,函数MHA和MLP分别表示多头注意和多层感知器块的操作。
并行子块修改涉及到MHA和MLP子块的并行处理,输出方程为:
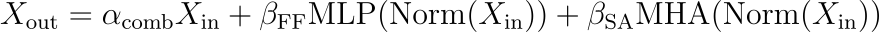
X_out表示Transformer 层的输出。
α_comb是输入贡献的比例因子。
αcomb、βFF和βSA是可训练的参数,分别控制输入、MLP和MHA块对输出的贡献。
Norm表示在MLP和MHA块处理之前应用于输入的规一化函数(如Layer normalization)。
MLP和MHA块并行处理相同的归一化输入,它们的输出与缩放后的输入求和。
并行处理的数学含义:
提高效率:通过并行处理MHA和MLP块,该模型可以潜在地减少每层的计算时间。
平衡贡献:参数α_comb, βFF和βSA允许MLP和MHA块对最终输出的灵活和平衡贡献,可以在训练期间进行优化。
简化的跳过连接:该方程引入了一个简化的跳过连接,它聚合了MHA和MLP块的贡献。这与传统的Transformer 不同,传统的Transformer 通常与每个子块相关联。
对学习动态的影响:改变了转换器的学习动态,可能使模型能够更有效地捕获数据中不同类型的依赖关系。
5、删除归一化层
归一化层的去除和残差分支的调整是为了保持不同层输出尺度的平衡,这可以通过精确的初始化和动态训练来实现。
在典型的Transformer 中,使用归一化层来稳定训练和管理层输出的规模。归一化后的图层输出可以表示为:
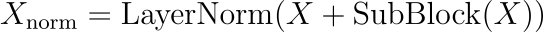
LayerNorm为层归一化操作,X为层的输入,SubBlock(X)表示子块(MHA或MLP)内的操作。
随着归一化层的去除,重点转移到调整残差分支。这种调整可以用数学模型表示为:
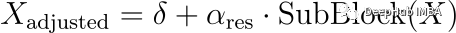
其中α_res是一个可训练的比例因子,应用于子块的输出来管理输出规模。
为了在不归一化的情况下平衡不同层输出的规模,可以采用以下策略:
使用谨慎初始化,可以初始化模型参数,特别是子块中的参数,以防止输出规模出现较大波动。这可以表示为:
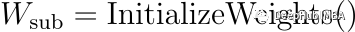
W_sub是子块的权重,InitializeWeights()是一个以确保控制输出缩放的方式初始化权重的函数。
在训练过程中进行动态调整,可以根据学习过程的反馈对比例因子α_res进行动态调整。这种调整可以表述为:
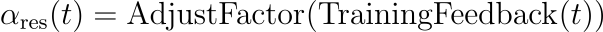
α_res (t)是训练步骤t的比例因子,AdjustFactor是根据训练过程中收到的反馈调整α_res的函数。
去除归一化层的数学含义:
消除归一化层需要对跨不同层的输出的比例进行微调控制。
可调节的比例因子α_res对于确保不同层的输出保持平衡而不受归一化的稳定作用至关重要。
在训练期间仔细的初始化和动态调整有助于管理由于缺乏归一化而可能产生的潜在比例差异。
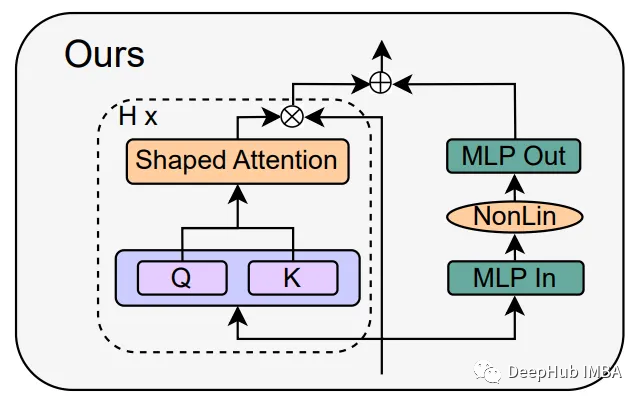
6、最终获得的架构
通过以上的修改,最终架构如下所示:
实验分析
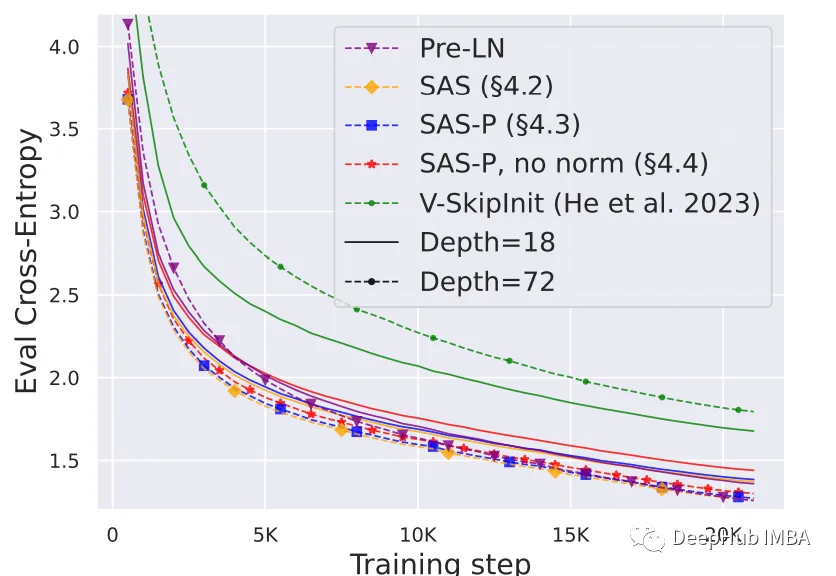
如下图所示,简化的Transformer 块在更大深度下显示出更高的训练速度。他们不仅训练得更快,而且有效地利用了额外的能力。与论文的模型相比,Value-SkipInit尽管增加了容量,但在更深的深度上训练速度较慢,并且表现出较差的可扩展性。
在论文中,他们评估了简化模型块在各种数据集和体系结构中的有效性,包括用于屏蔽语言建模的双向编码器BERT和GLUE基准测试。他们采用了“Crammed”BERT设置,在消费级的GPU上进行资源受限(24小时)的训练。
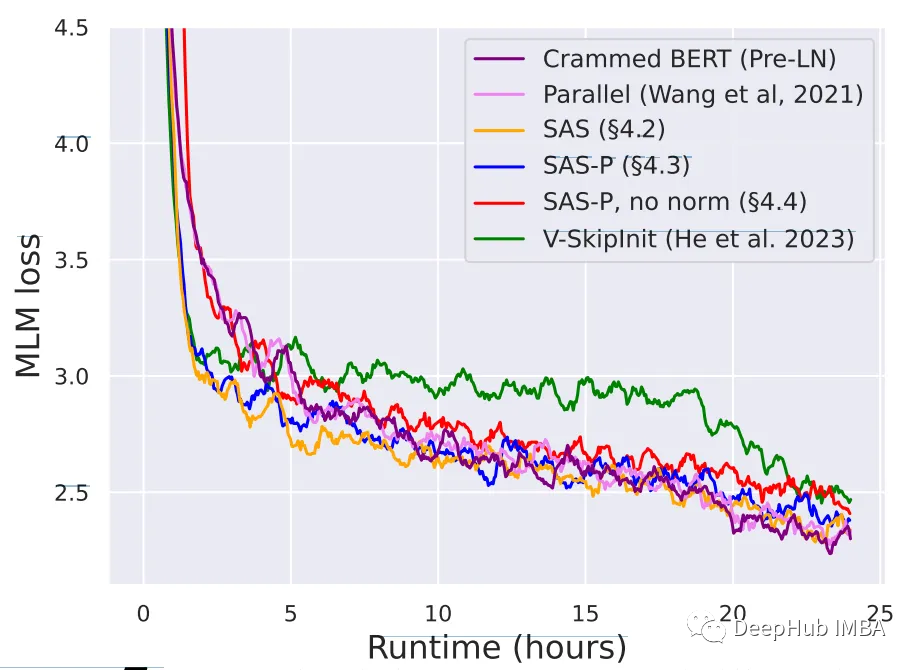
论文的简化块,特别是当与归一化相结合时,在24小时的训练限制内匹配了Pre-LN基线的预训练速度,如下图所示。但在不修改值和投影的情况下删除跳过连接,会显著降低训练速度。
下表显示了在GLUE基准上进行微调后,简化的方法与BERT基线的性能相匹配。论文还观察到Value-SkipInit可以在微调期间恢复,这表明除了预训练速度之外的因素也会影响性能。在一些下游数据集的微调过程中,删除归一化会导致不稳定。
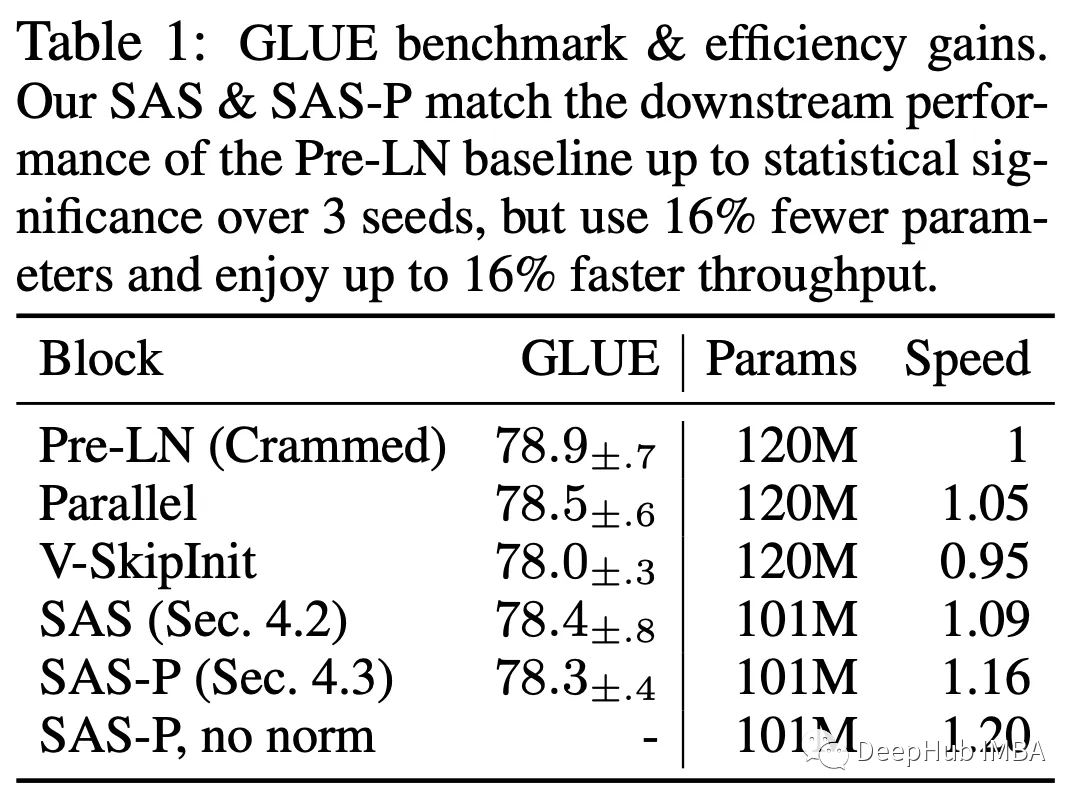
该研究强调了简化模型块的有效性,特别是在资源受限的情况下,同时承认各种因素在微调性能中的重要性。
为了适应在更多数据上训练更长时间的小模型的趋势,论文使用简化块进行了实验。当使用3×令牌(约2B个令牌)训练时,简化的SAS和SAS- p块保持或超过Pre-LN块的训练速度,如下图所示。
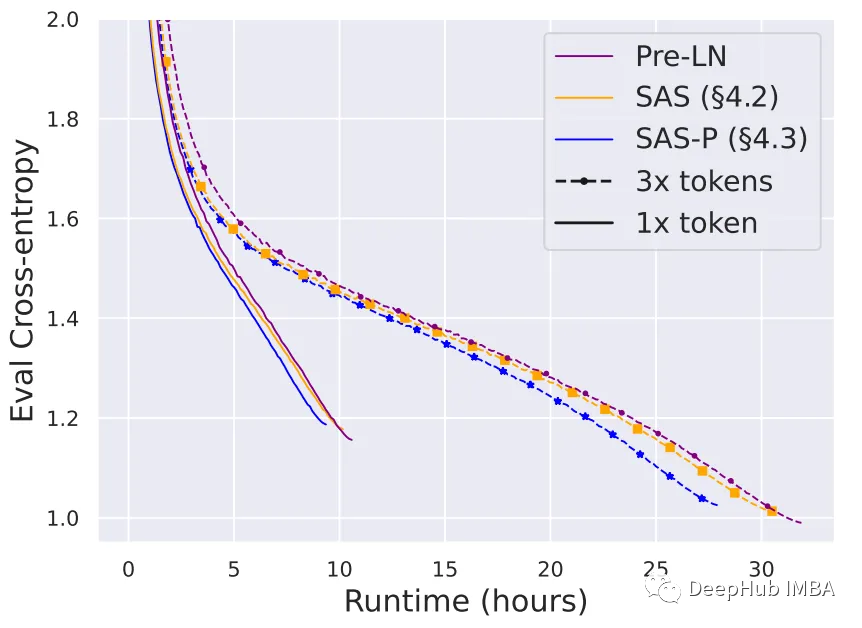
总结
论文“Simplifying Transformer Blocks”中提出的简化反映了对Transformer 体系结构细微差别的理解的深刻转变。他们强调了在大幅减少计算占用的情况下实现相当甚至改进的模型性能是非常有可能的。
本文只做了一些简单的数学描述,详细的数学阐述可能包括对修改后的注意力矩阵的特征值分析,光谱分解以了解定心矩阵C的影响,以及广泛的消融研究以量化每个简化步骤的影响。
从本质上讲,这种简化不仅使Transformer 更易于使用和高效,而且为从根本上理解深度学习架构开辟了新的途径。它为更可持续的人工智能和机器学习解决方案铺平了道路,这些解决方案在现实世界的应用中既强大又实用。
论文地址:Simplifying Transformer Blocks
https://avoid.overfit.cn/post/55636b1affd6459fa0f5c1de0d512d4e
作者:Freedom Preetham