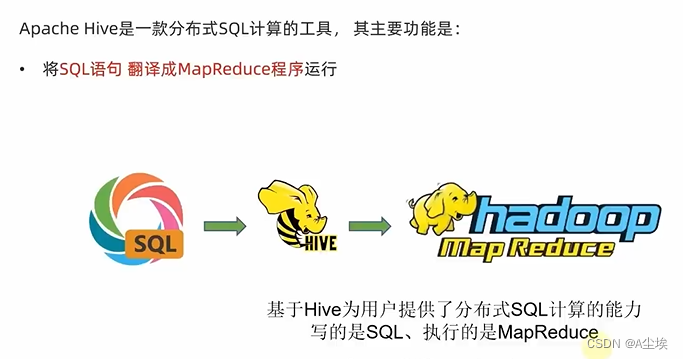
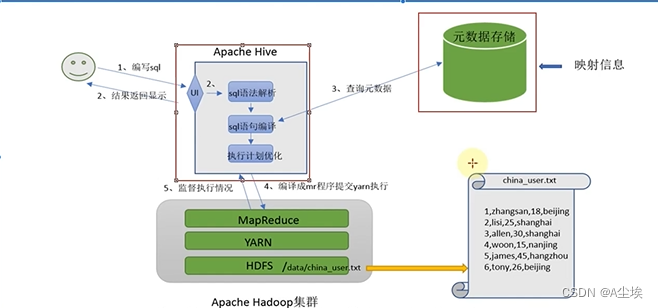
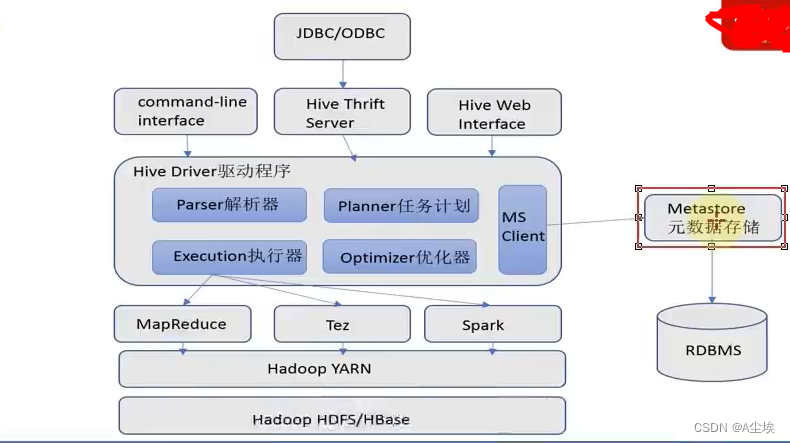
Hive架构
Hive部署


VMware虚拟机部署
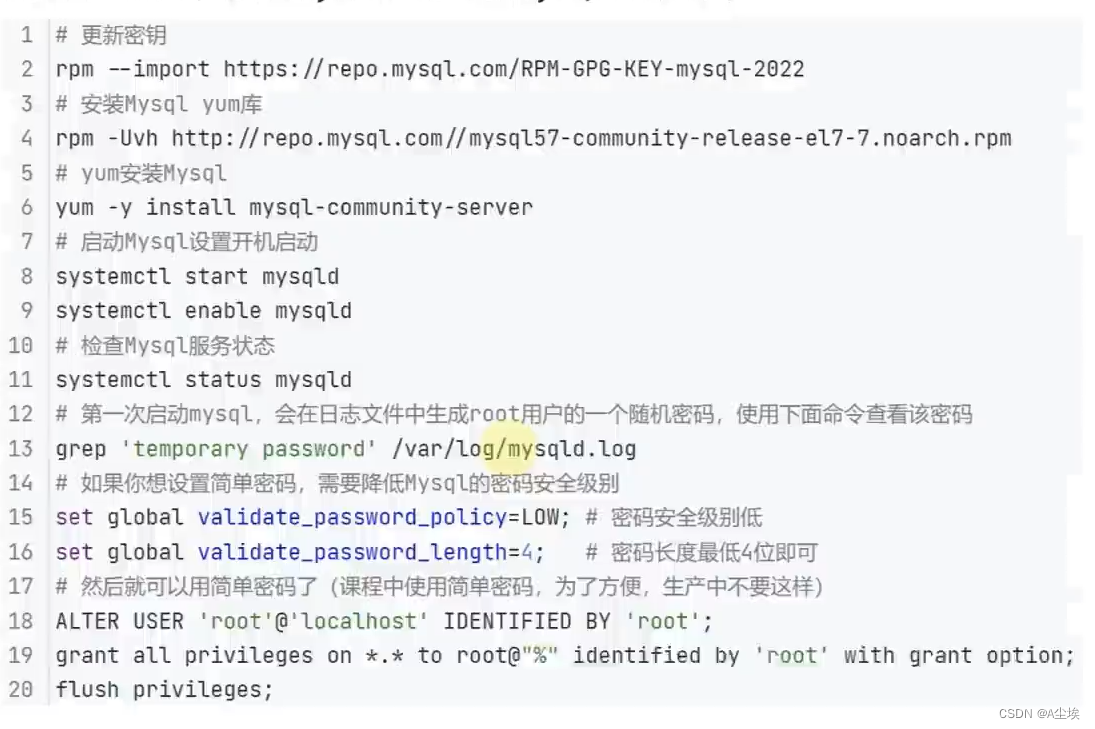
一、在node1节点安装mysql数据库
二、配置Hadoop

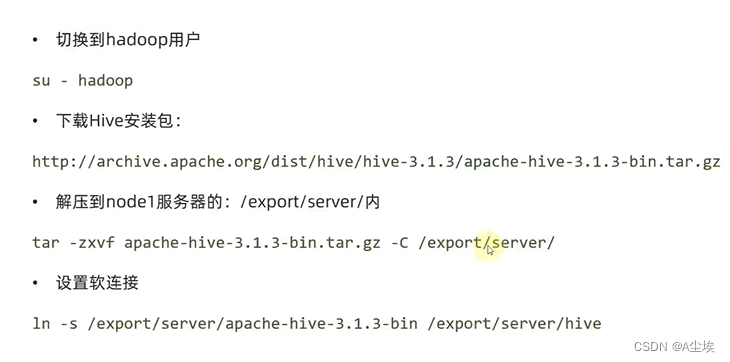
三、下载 解压Hive
四、提供mysql Driver驱动

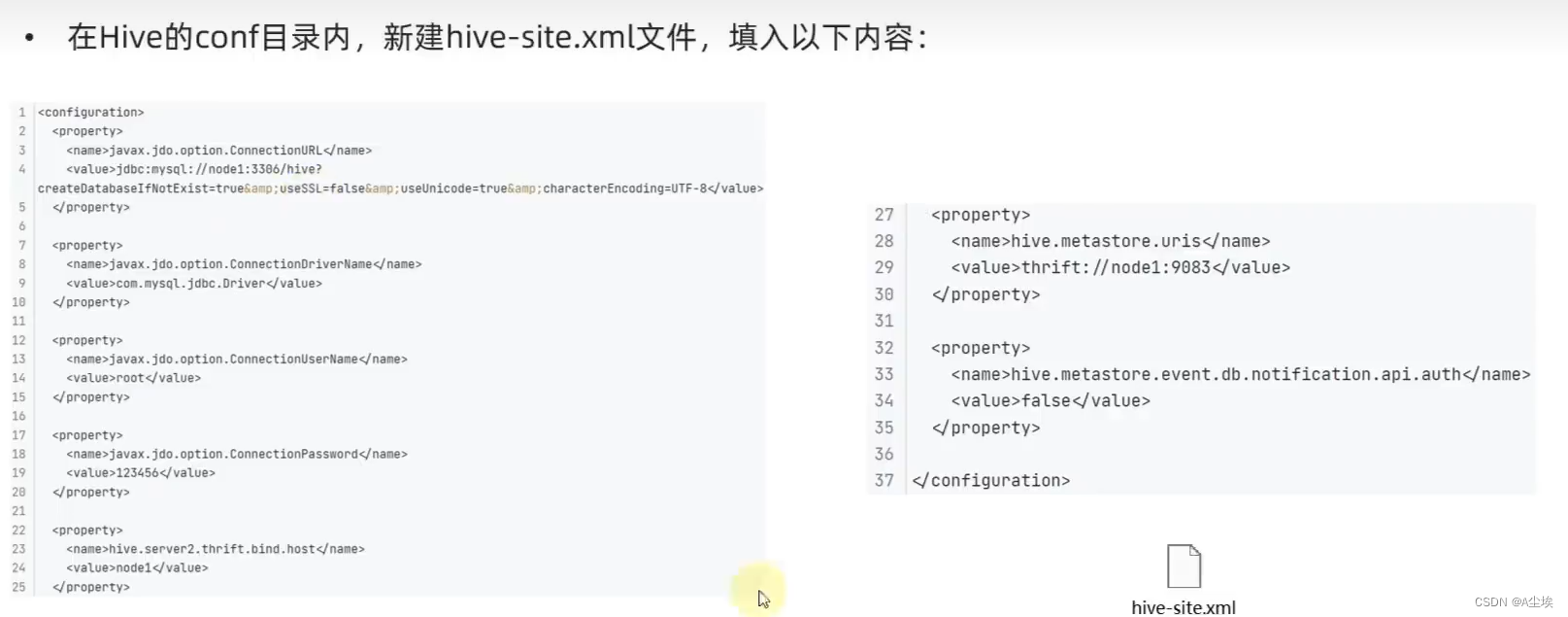
五、配置Hive

六、初始化元数据库

七、启动Hive(Hadoop用户)
chown -R hadoop:hadoop apache-hive-3.1.3-bin hive

阿里云部署

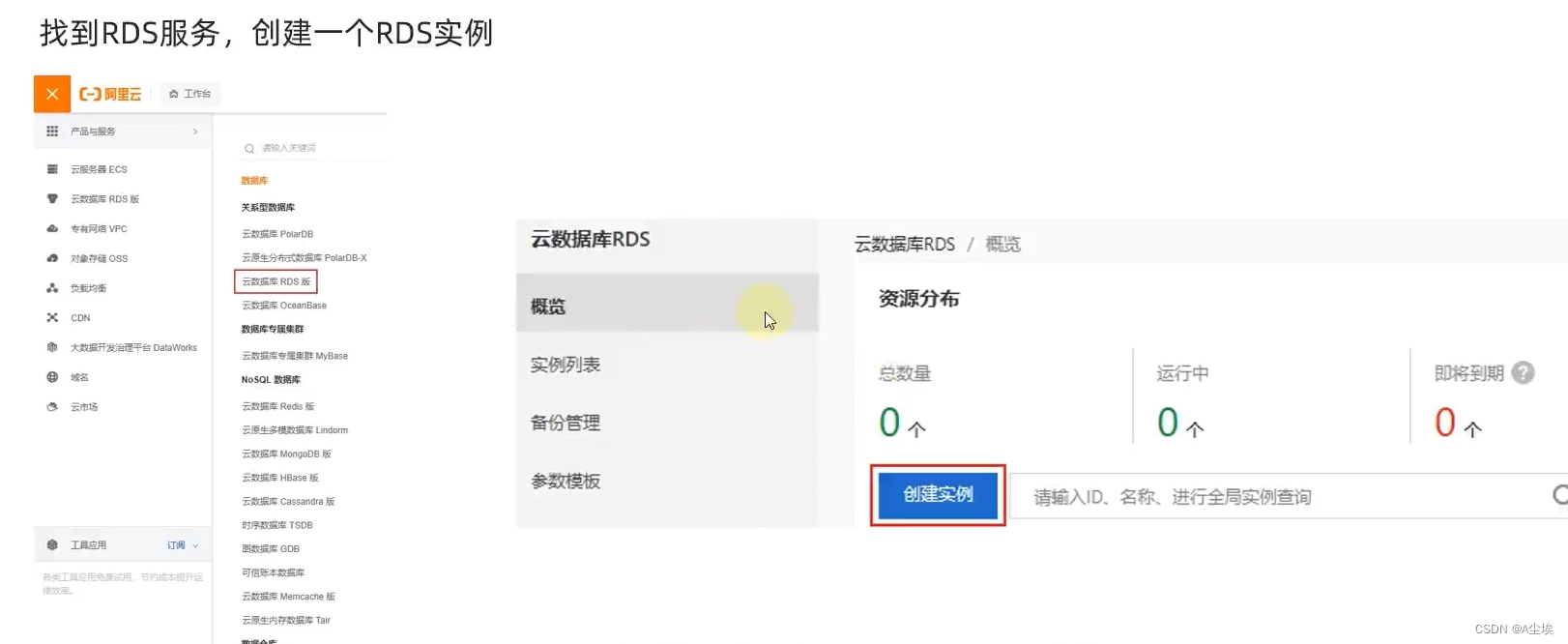
一、创建云数据库库
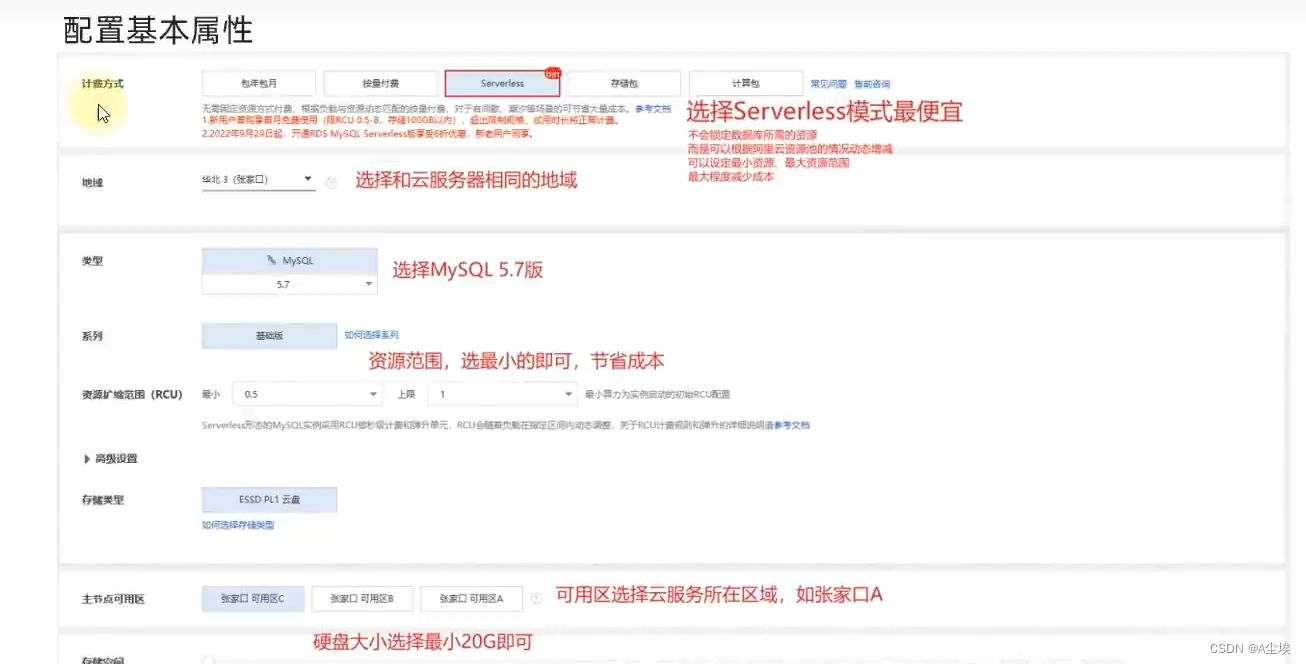
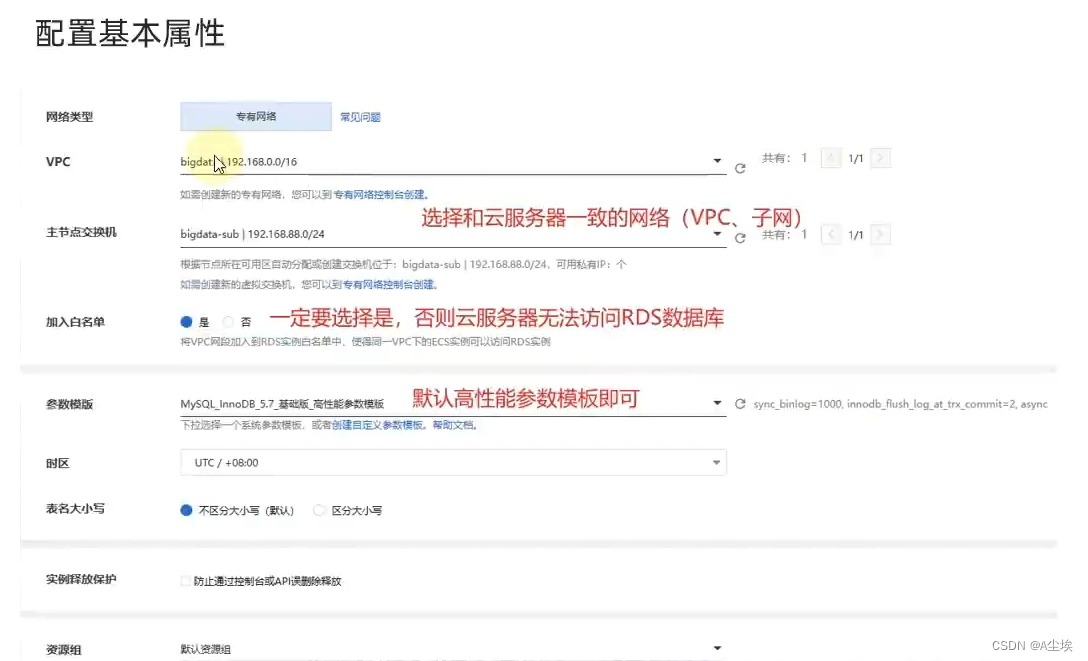
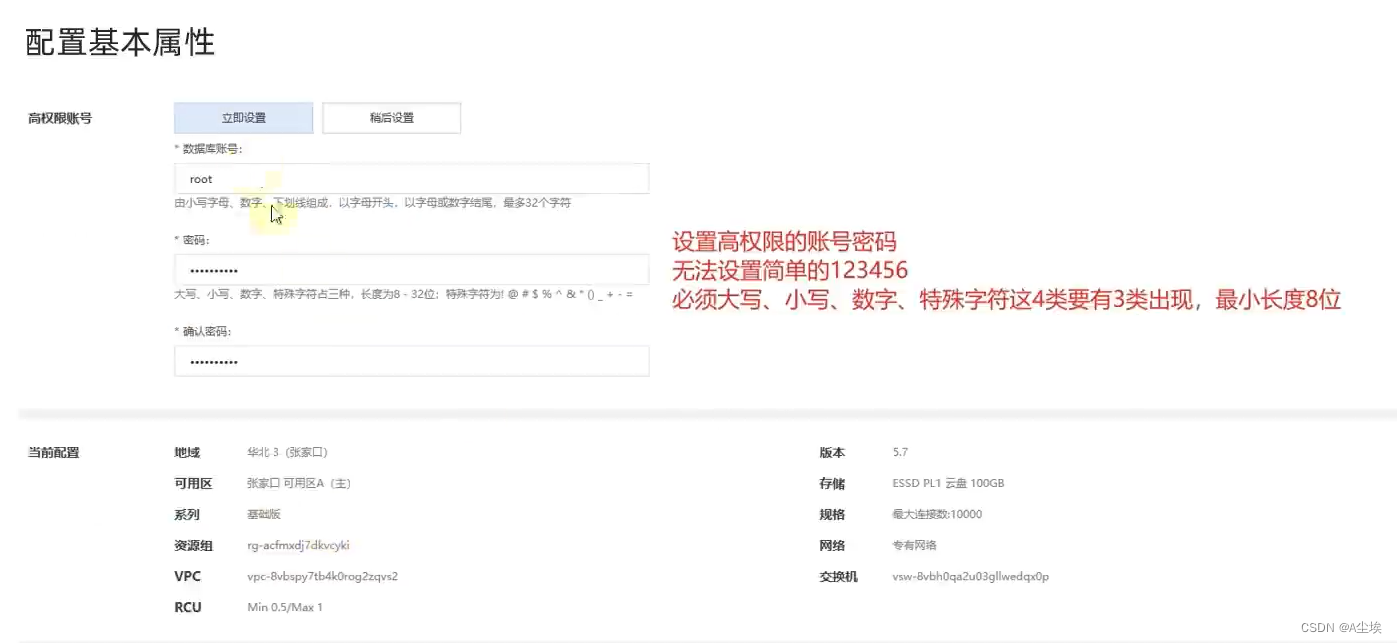
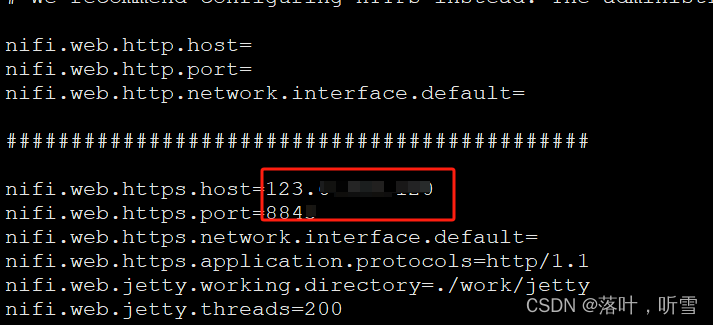
二、配置Hive

数据库连接地址粘贴到配置文件中

通过yum install -y mysql 安装mysql客户端,用于mysql命令的输入
UCloud云部署

一、创建UDB数据库
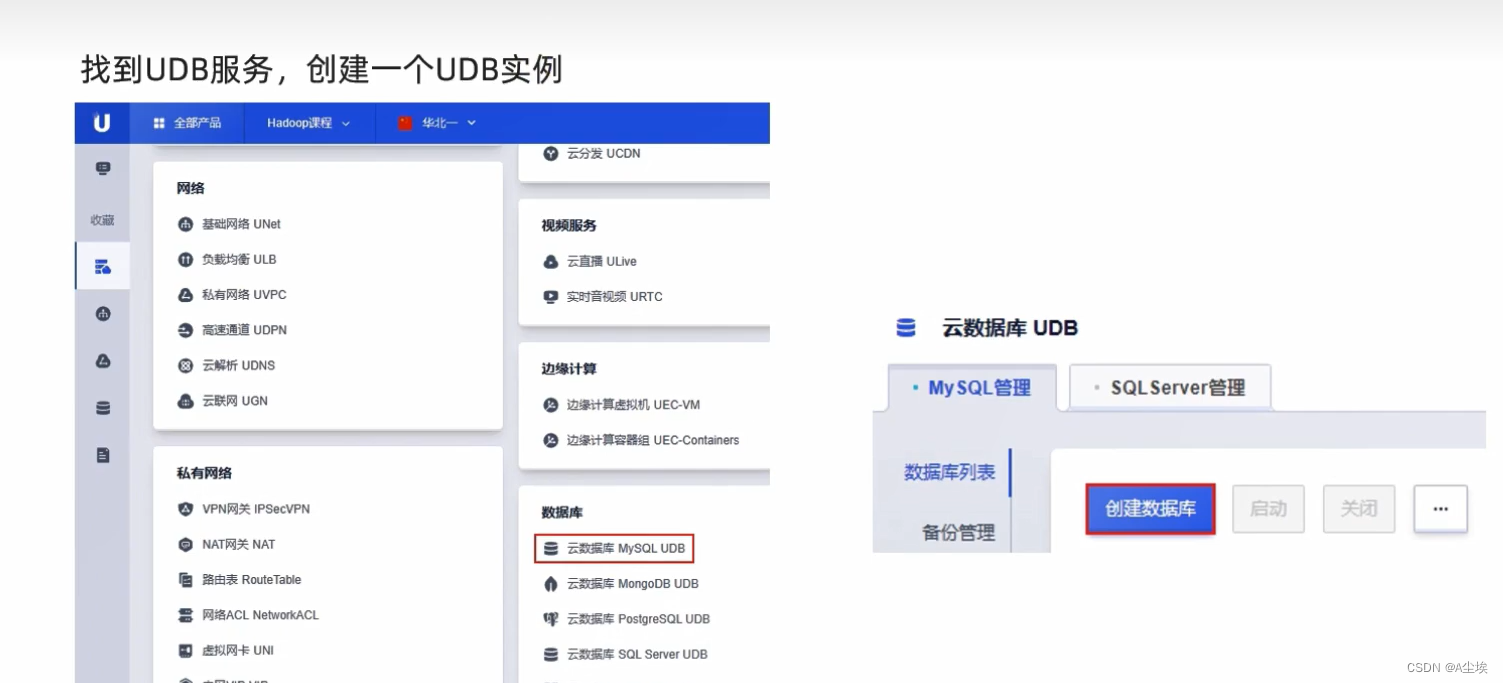
二、创建一个Hive数据库(需要通过yum install -y mysql提前安装命令)

三、初始化
============================================================
Hive操作
通过ps -ef | grep 40991更详细查看
或者通过jps查看

通过浏览器可以查看
Hive客户端
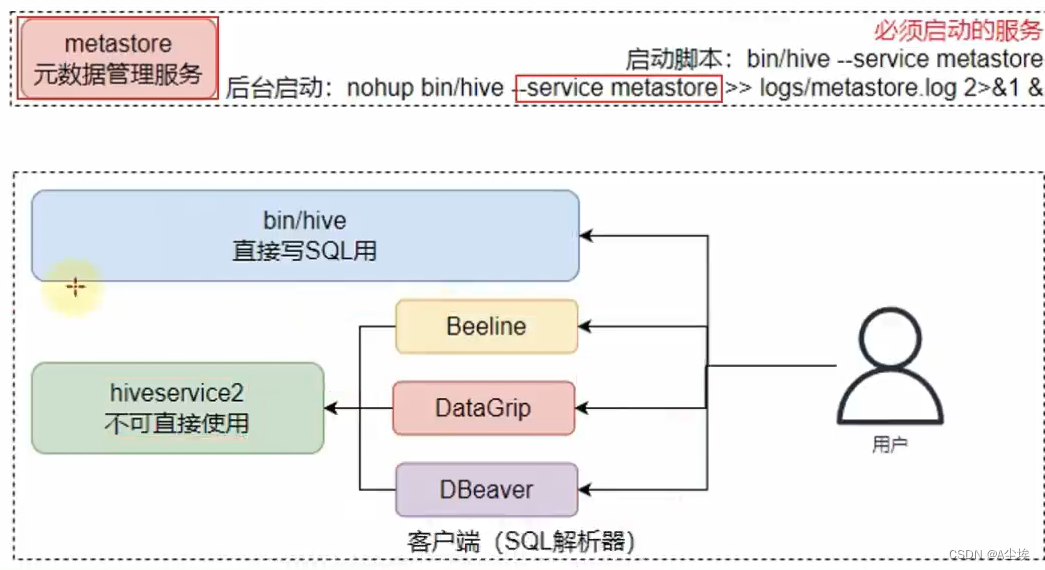
启动Hive客户端两种方式:
①、bin/hive即Hive的Shell客户端,直接写SQL
②、bin/hive --service hiveserver2 HiveServer2属于Hive内置的一个ThriftServer服务,提供Thrift端口供其他客户端链接:
可以链接ThriftServer的客户端有:
- Hive内置的beeline客户端工具(命令行工具)
- 第三方图形化SQL工具DataGrip 或DBeaver或者Navicat

HiveServer2 & Beeline(内置客户端)
①、启动beeline

②、连接hive2

DataGrip & DBeaver(第三方客户端)
①、DataGrip使用
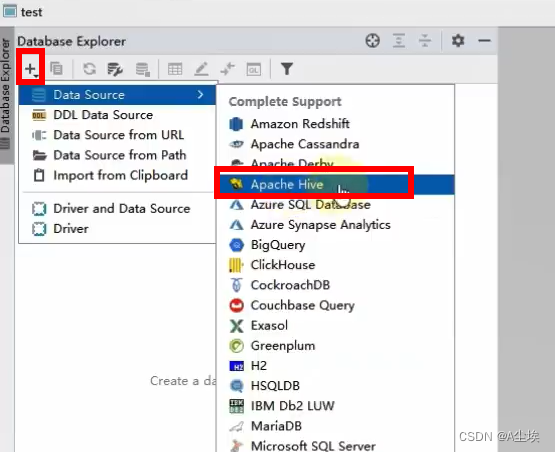
②、进行连接
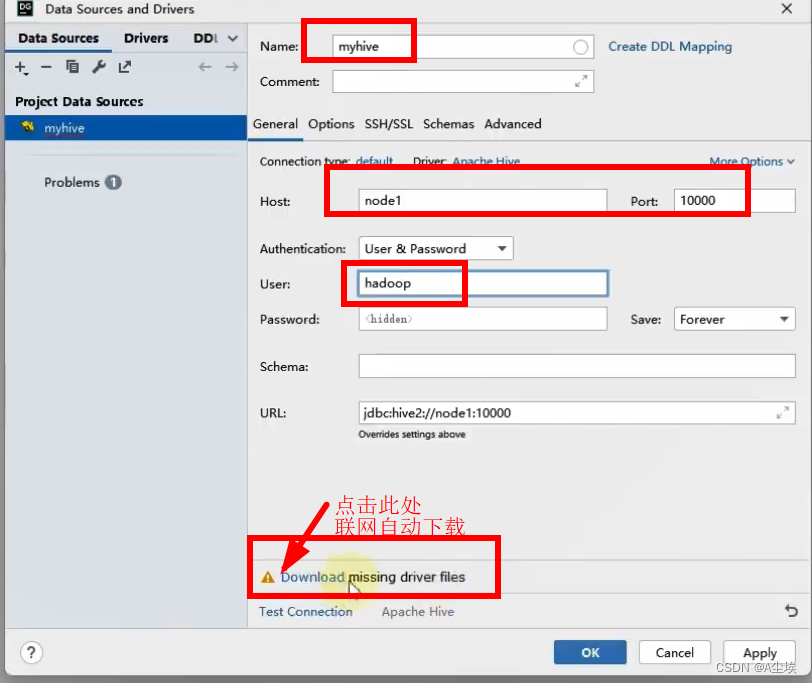
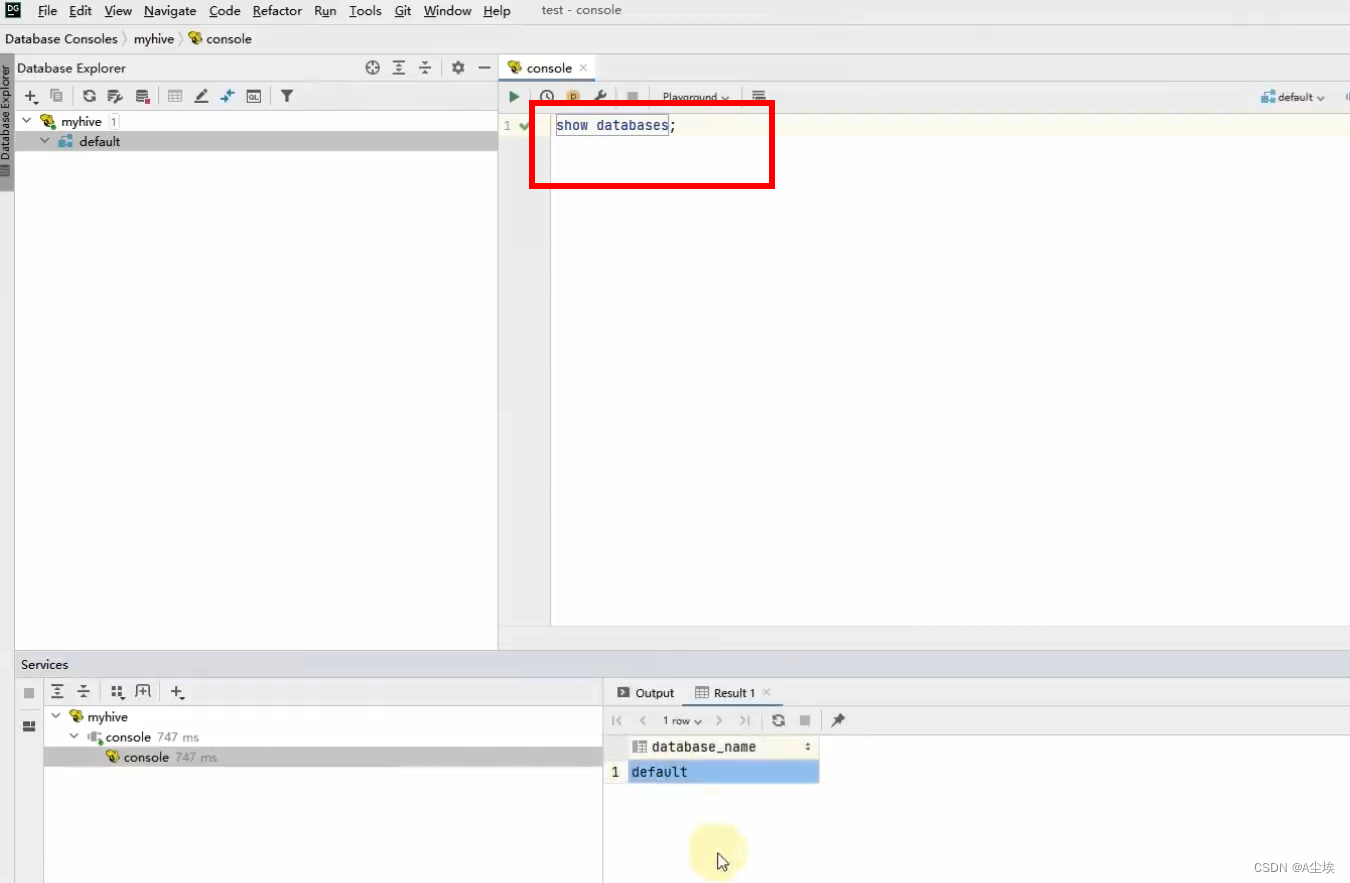
③、写SQL语句
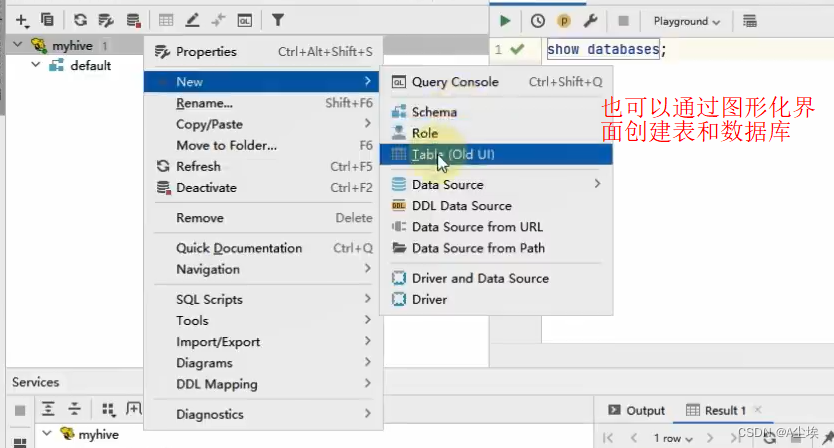
①、DBeaver使用
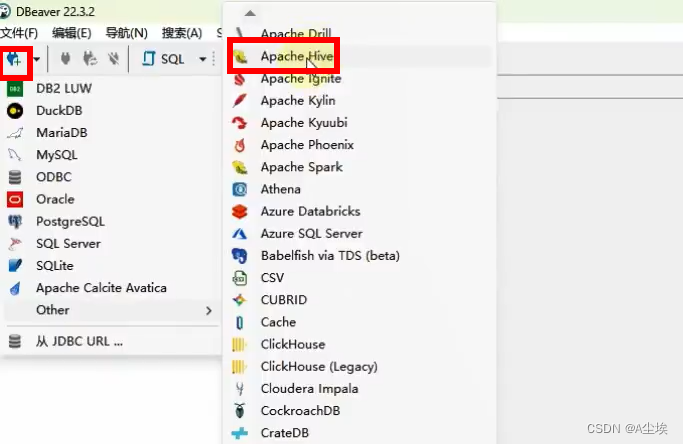
②、构建驱动
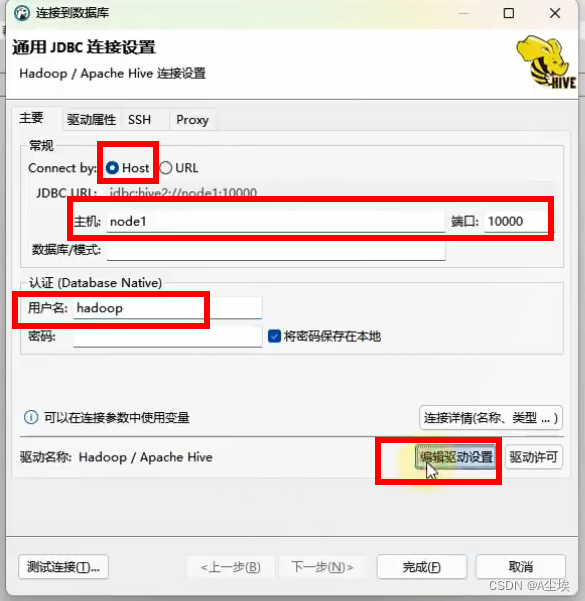
删除原来的驱动
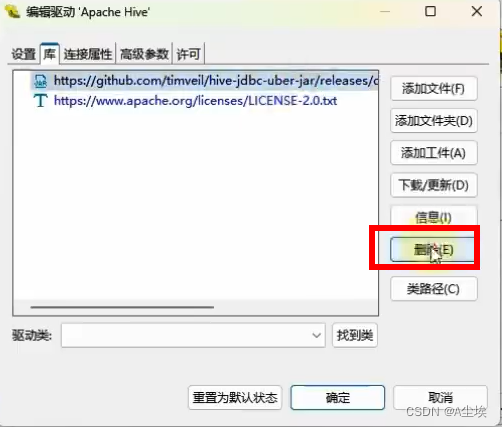
添加自己本地下载好的文件
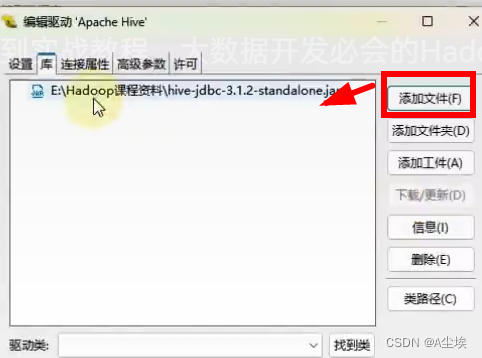
③、写好SQL,回车可以运行
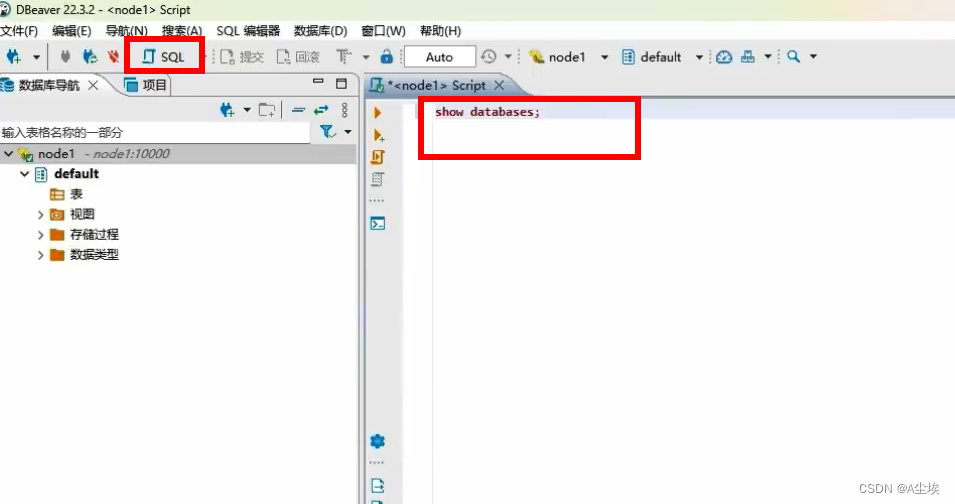
数据库操作


表分类:
内部表


create table myhive.stu(id int,name string); # 在myhive数据库中创建stu表# 指定分隔创建表 避免在下面查看表内容出现id和name不可见字符导致的紧凑
create table if not exists stu2(id int,name string) row format delimited fields terminated by '\t';insert into myhive.stu values(1,'jordan'),(2,"kobe");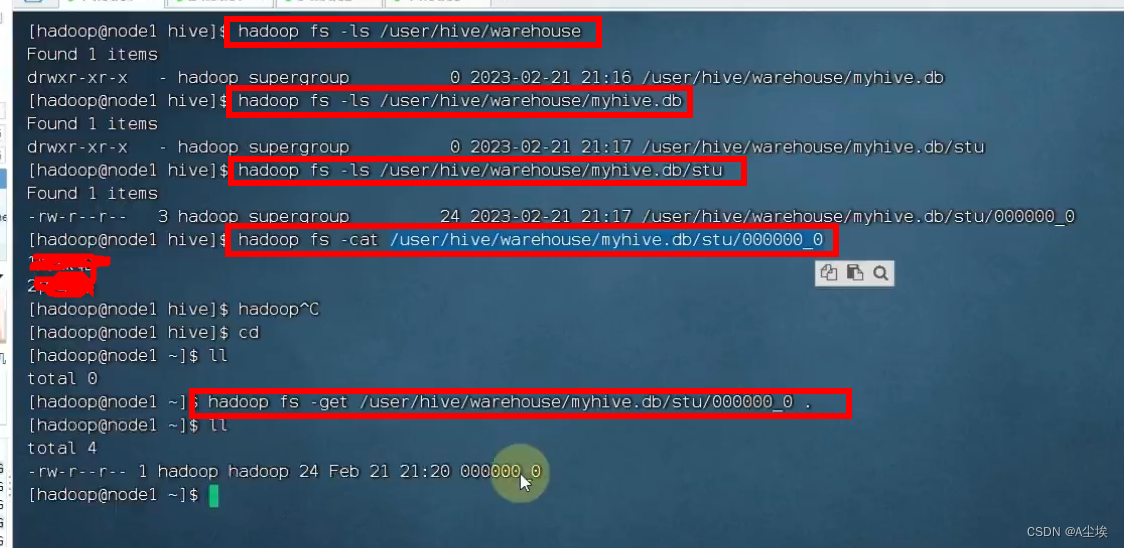
外部表

一、将数据上传到外部表所在的目录(先有表,再有数据)


二、先存在数据,后创建表

两者对比:

内外部表转换:
①、先查看表类型
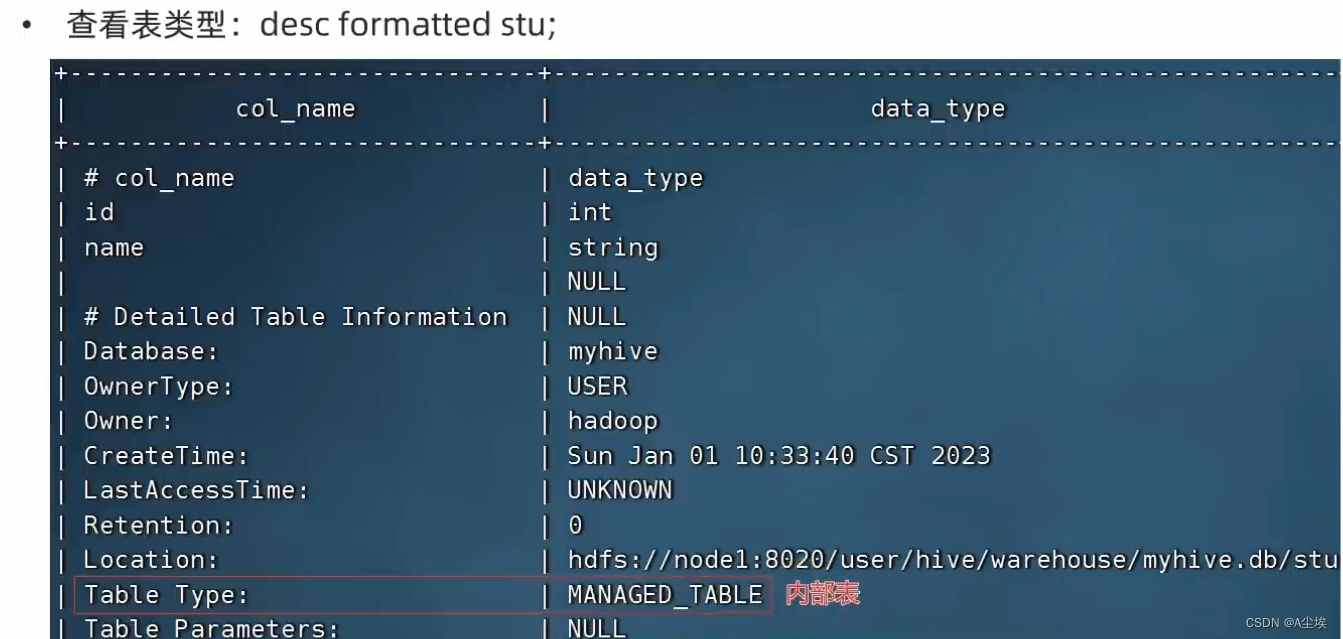
②、转换

数据的导入:
①、使用LOAD语法,从外部将数据加载到Hive内
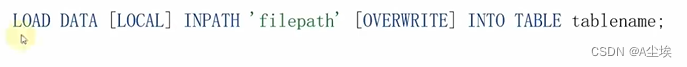
CREATE TABLE myhive.test_load(dt string comment '时间(时分秒)',user_id string comment '用户ID',word string comment '搜索词',url string comment '用户访问地址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
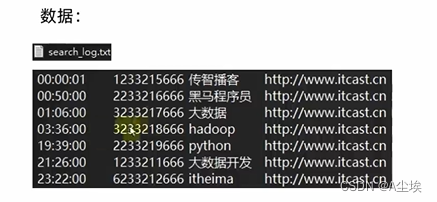
# 本地linux系统上传
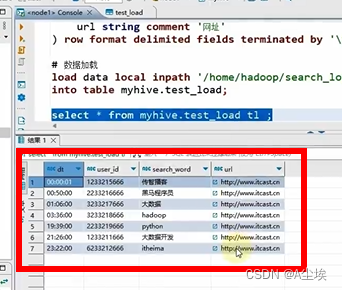
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;# 本质上是文件移动
load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load
【基于HDFS进行load加载数据,元数据文件会消失(本质是被移动到表所在的目录中)】
②、从其他表加载数据

数据的导出:
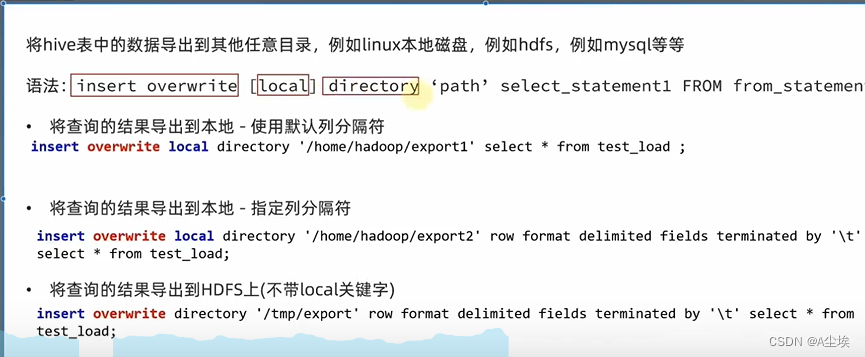
①、将hive表中的数据导出到其他任意目录,例如linux本地磁盘,hdfs,mysql等
②、通过hive shell方式导出

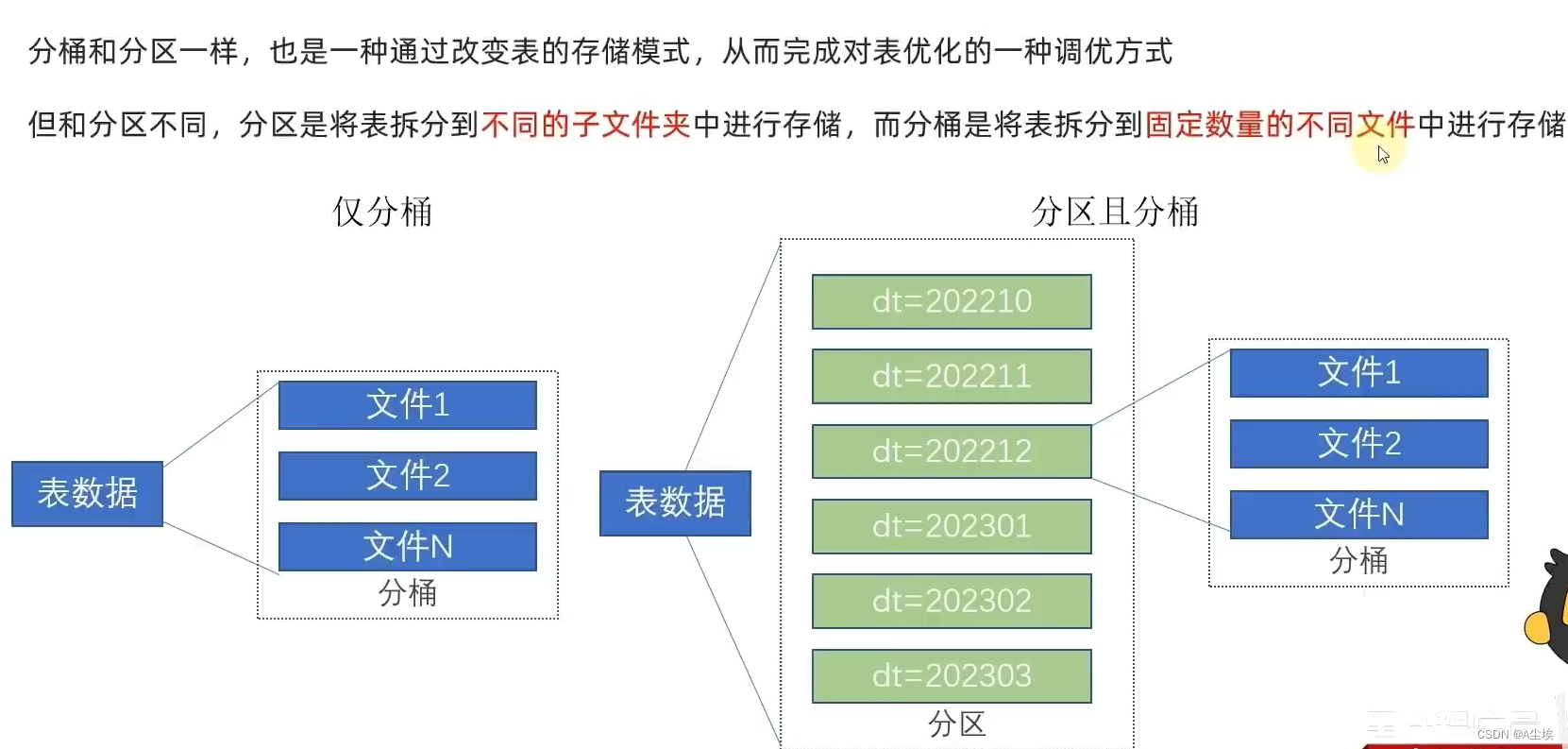
分区表

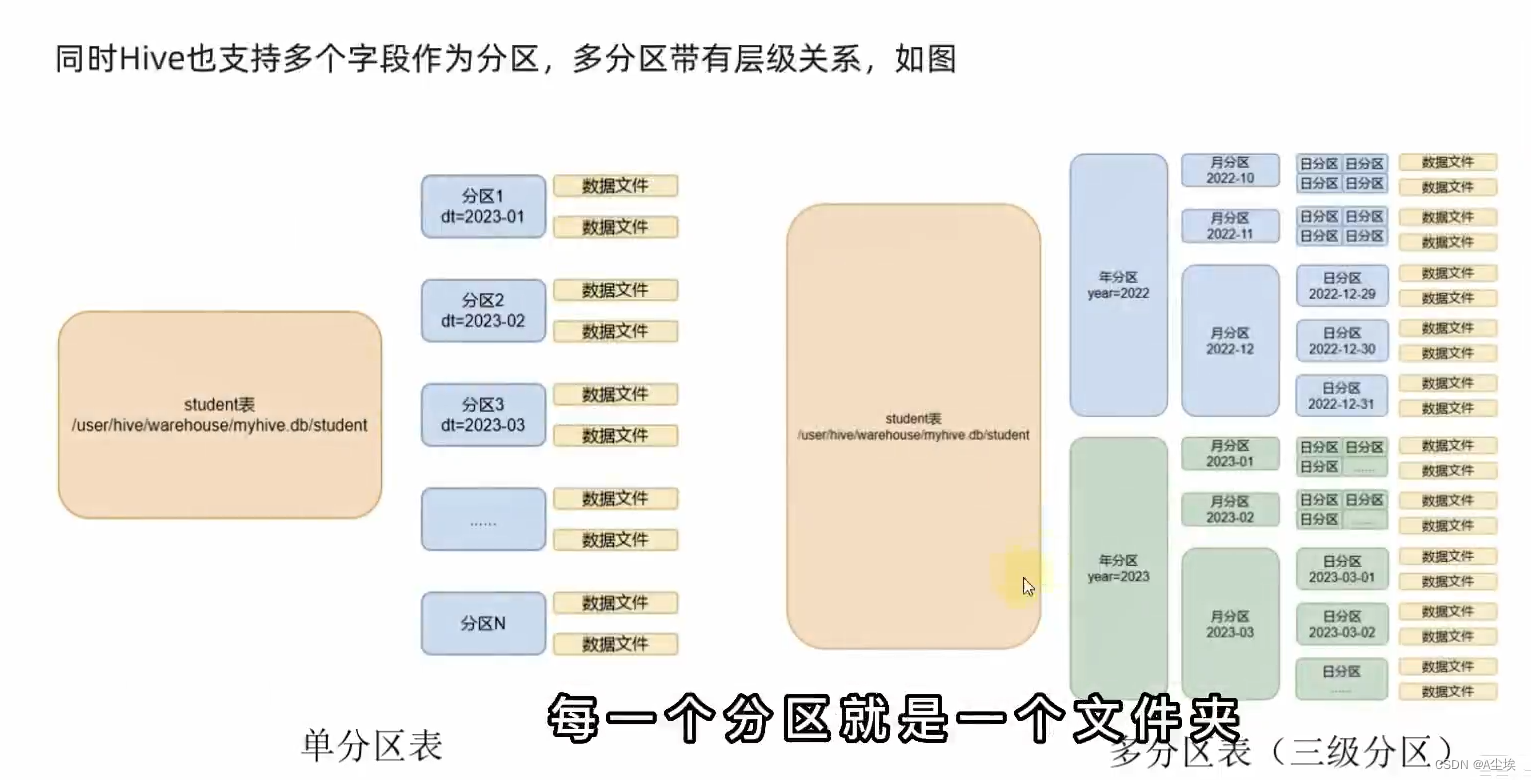
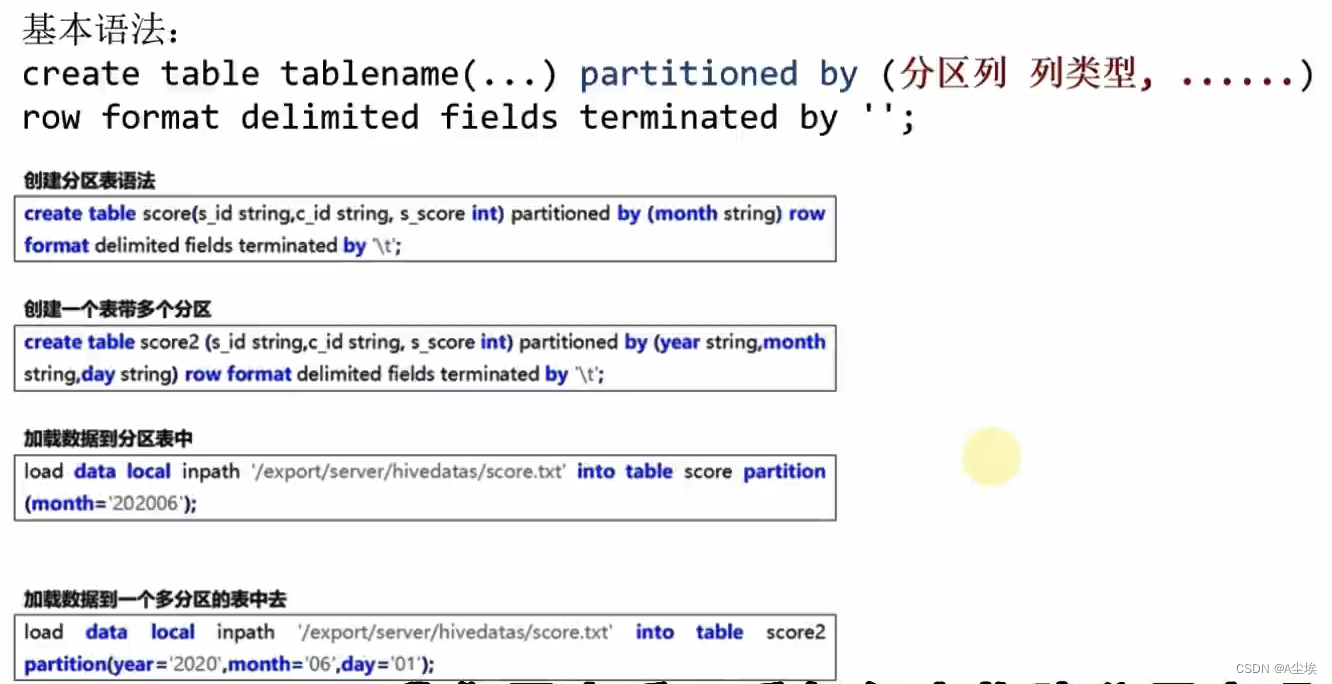
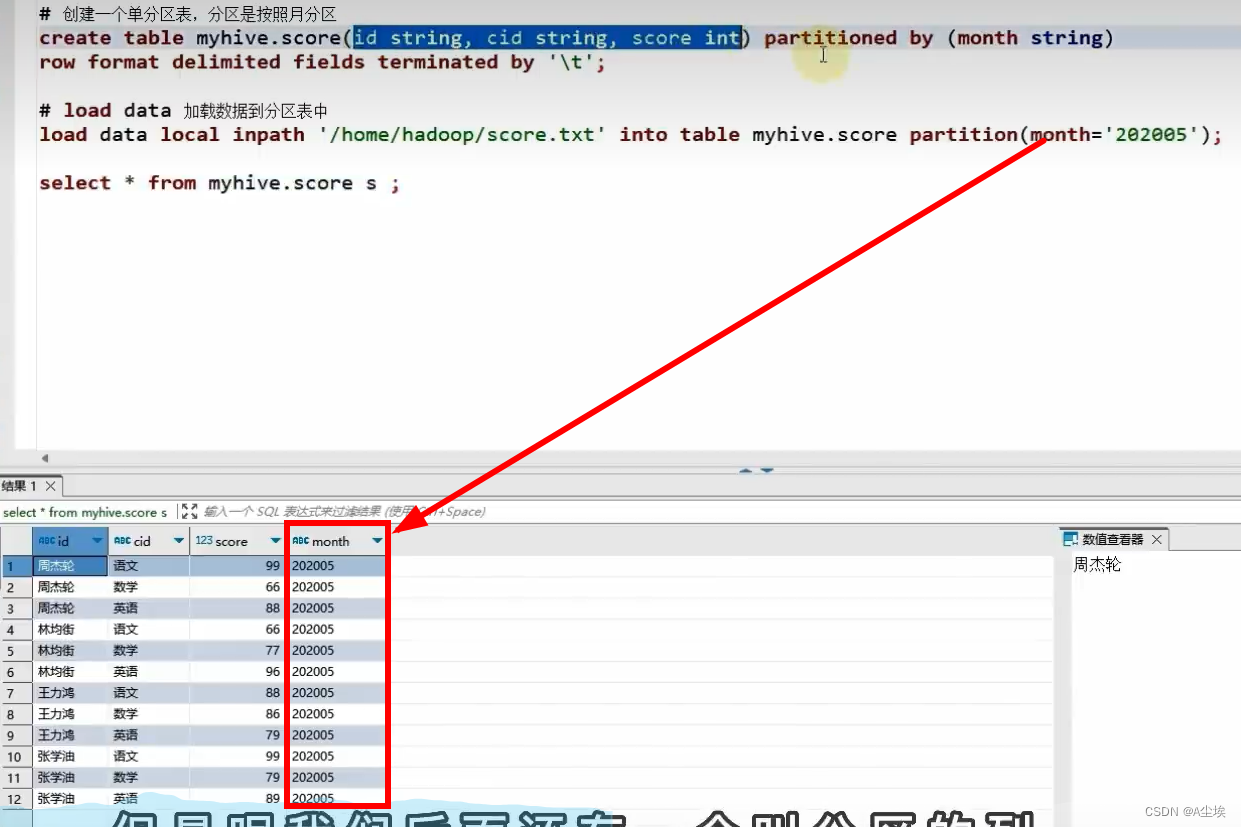
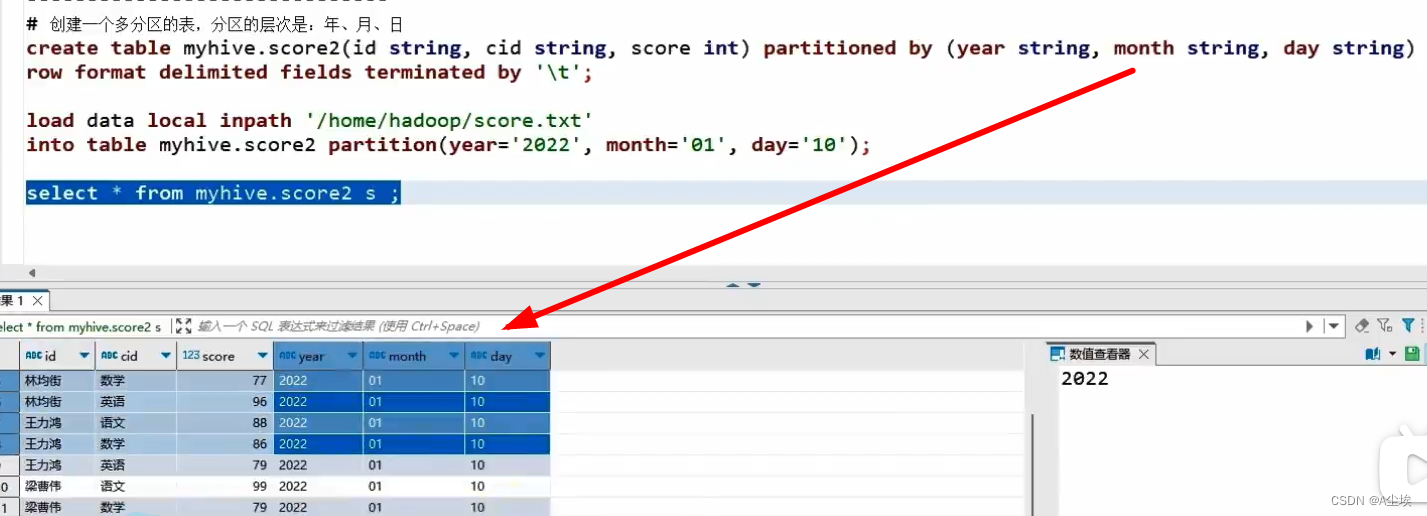
构建分区表
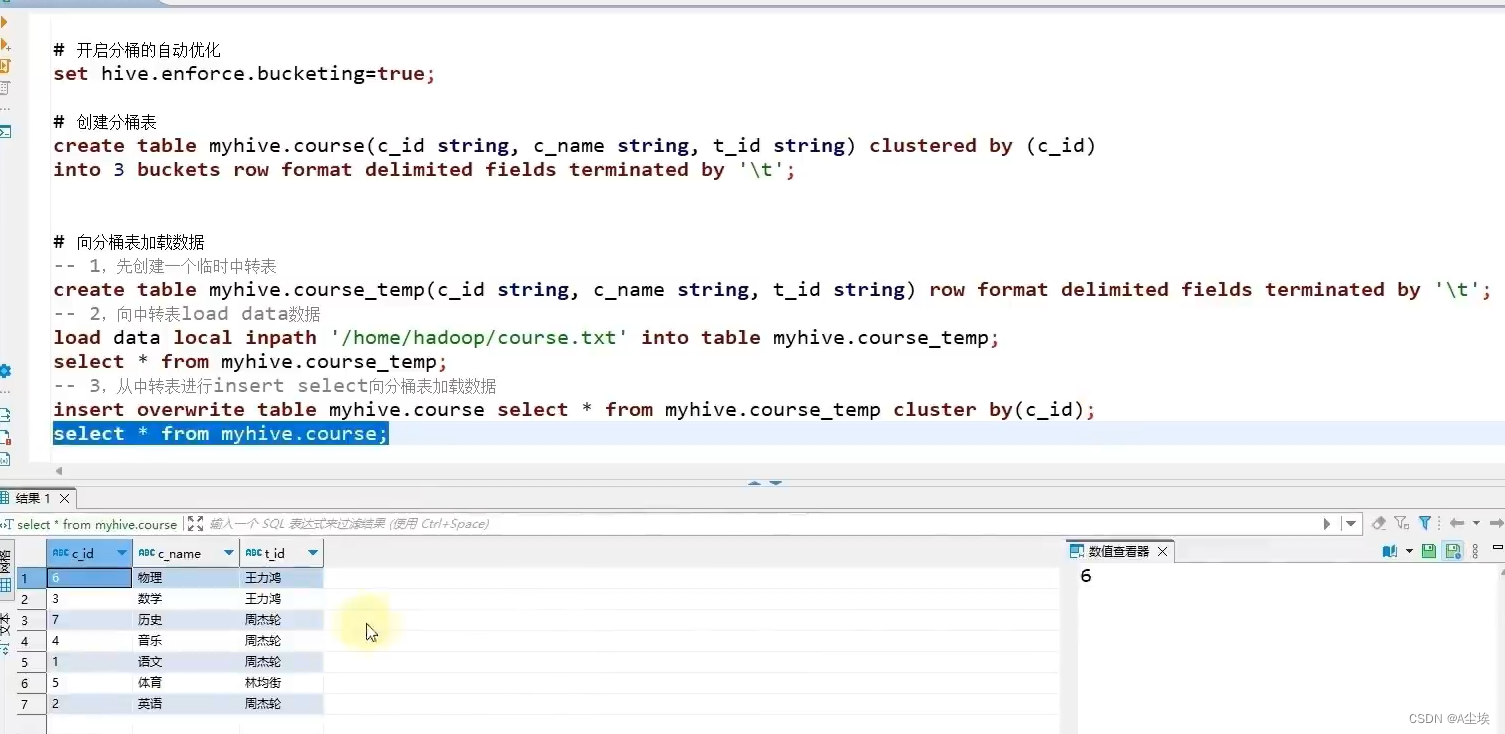
分桶表
分桶表创建


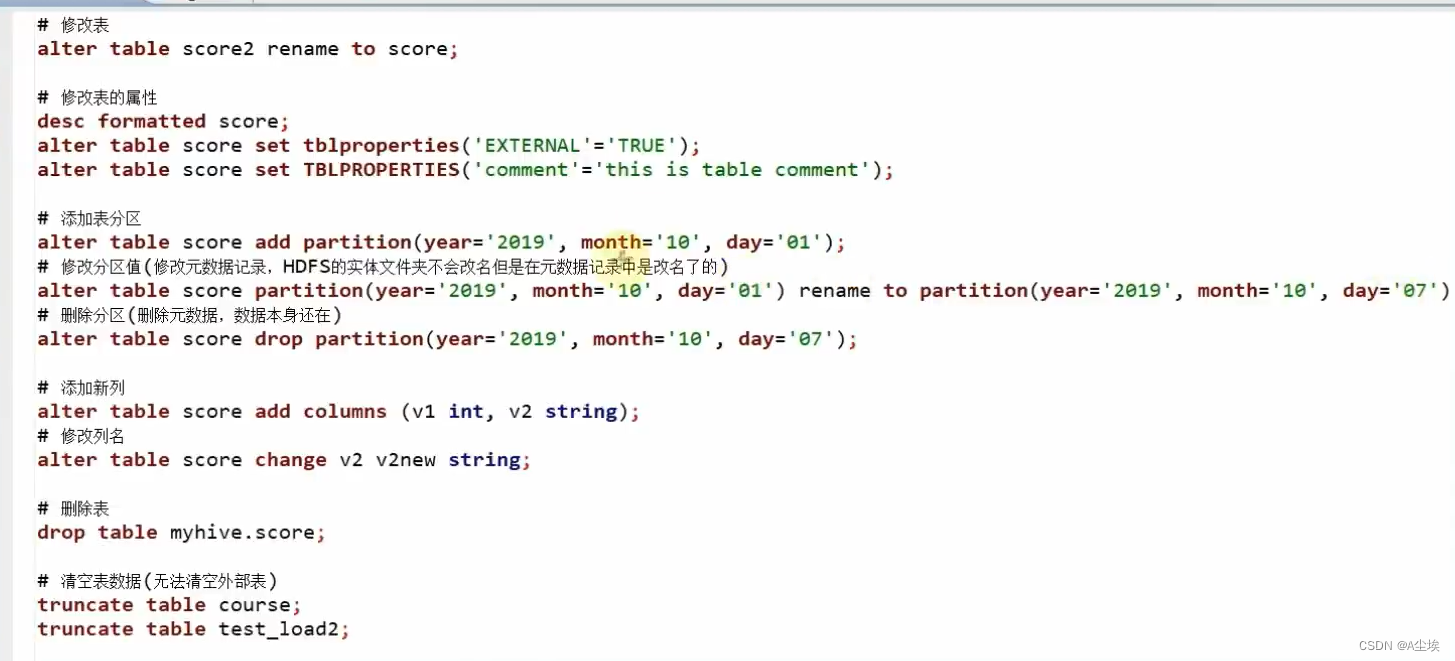
修改表操作
复杂类型
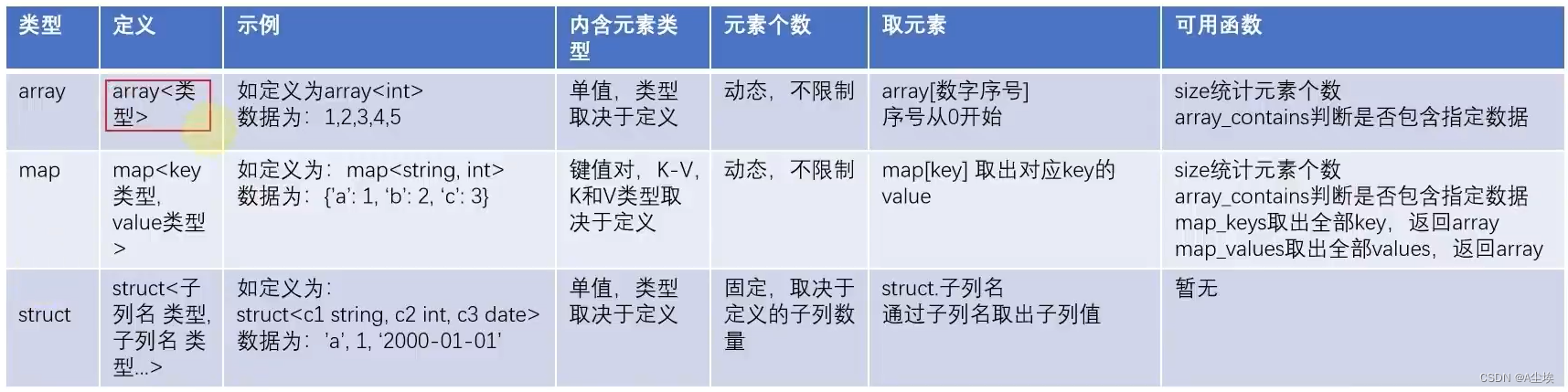
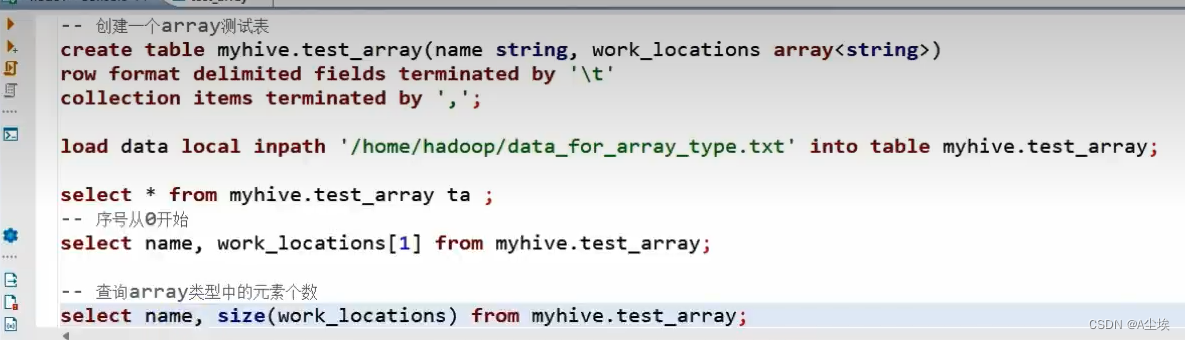
array数组

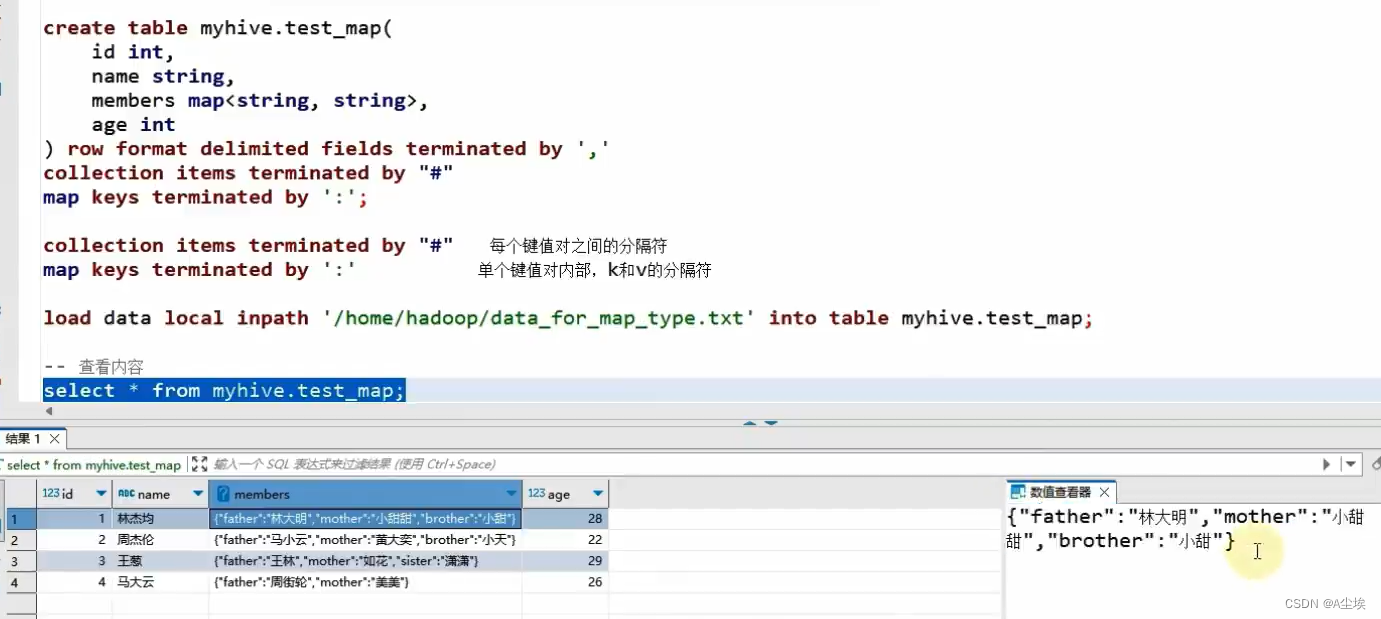
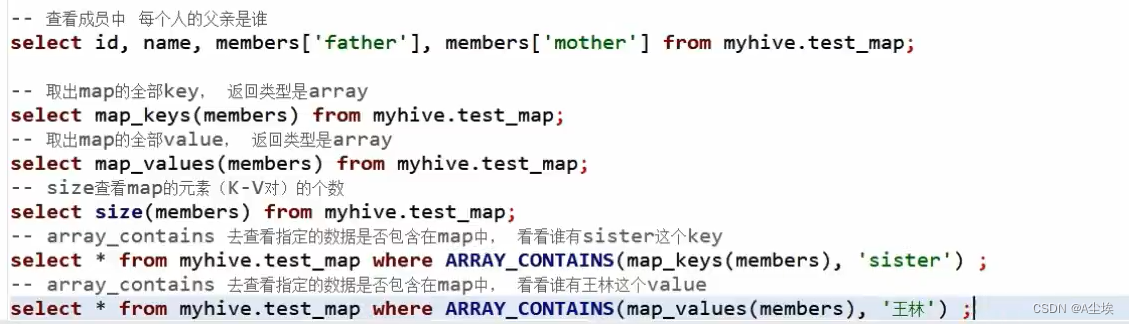
map映射
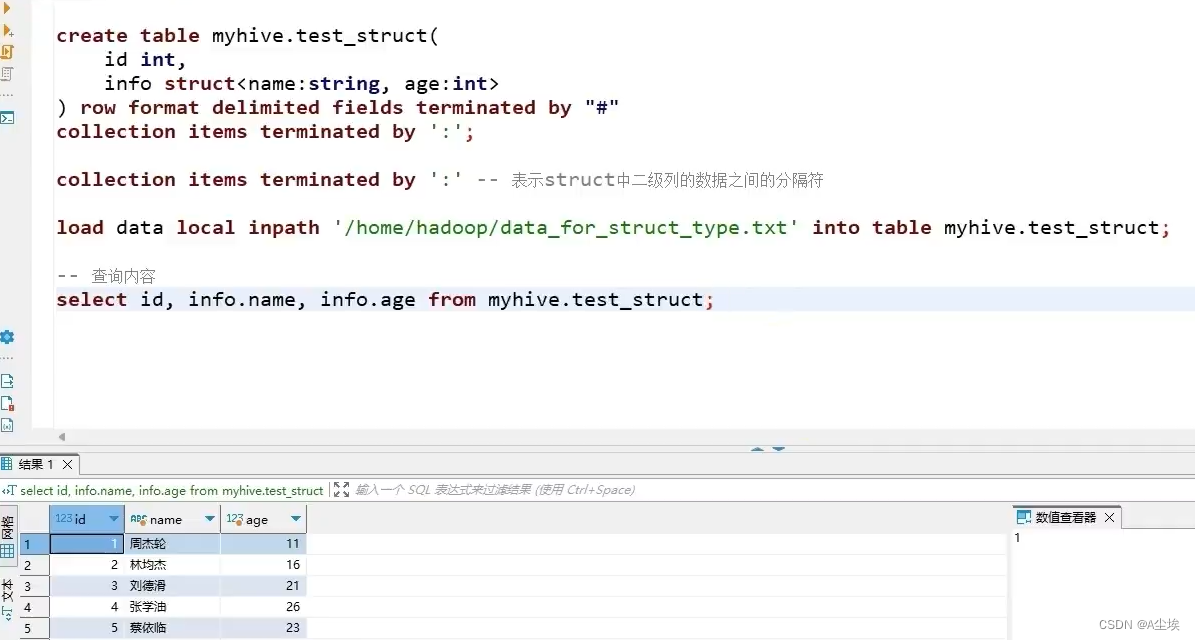
struct结构

常用的基本查询


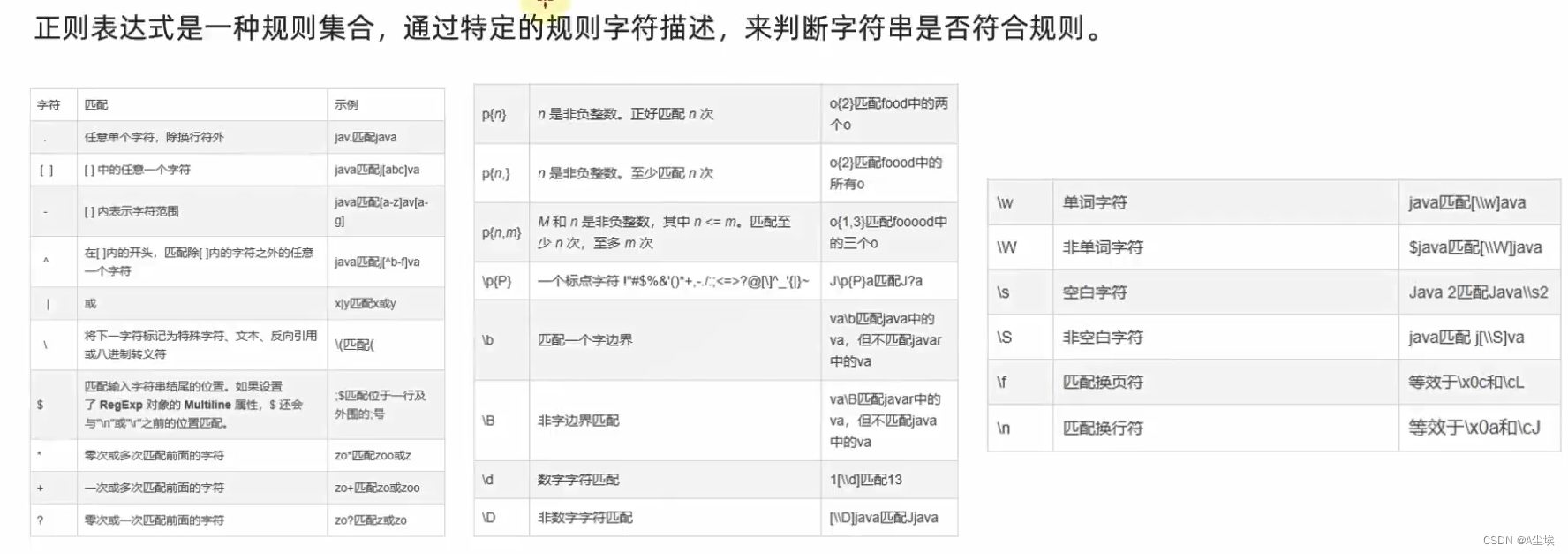
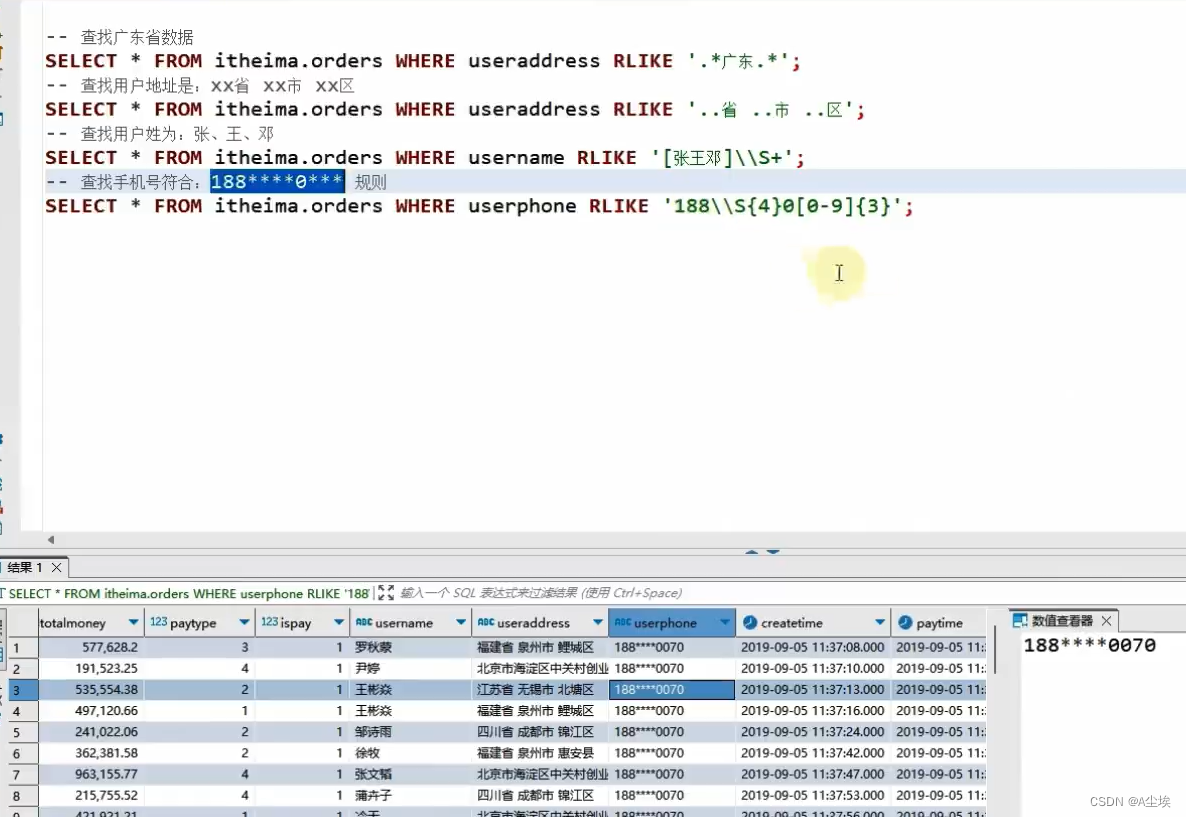
正则表达式