论文地址:https://arxiv.org/abs/1412.7062
代码地址:GitHub - TheLegendAli/DeepLab-Context
1.是什么?
DeepLab V1是一种基于VGG模型的语义分割模型,它使用了空洞卷积和全连接条件随机(CRF)来提高分割的准确性。其总体架构包括一个卷积神经网络和一个CRF后处理模块。在卷积神经网络中,使用了空洞卷积来扩大感受野,从而提高了分割的准确性。在CRF后处理模块中,使用了全连接CRF来进一步优化分割结果。
以下是DeepLab V1模型的主要特点和:
- 使用了VGG模型作为卷积神经网络的基础模型。
- 使用了空洞卷积来扩大感受野,从而提高了分割的准确性。
- 使用了全连接CRF来进一步优化分割结果。
2.为什么?
在论文的引言部分(INTRODUCTION)首先抛出了两个问题(针对语义分割任务):
信号下采样导致分辨率降低:
在DCNN中重复最大池化和下采样带来的分辨率下降问题,分辨率的下降会丢失细节。max-pooling会降低特征图的分辨率,而利用反卷积等上采样方法会增加时空复杂度,也比较粗糙,因此利用空洞卷积来扩大感受野,相当于下采样-卷积-上采样的过程被一次空洞卷积所取代。空洞卷积可以扩展感受野,获取更多的上下文信息。
作者说主要是采用Maxpooling导致的,为了解决这个问题作者引入了'atrous'(with holes) algorithm(空洞卷积 / 膨胀卷积 / 扩张卷积)
空间“不敏感” 问题。
以获取图像中物体为核心的决策,必然需要空间不变性/不敏感。换句话说,对于同一张图片进行空间变换(如平移、旋转),其图片分类结果是不变的。但对于图像分割等,对于一张图片进行空间变换后,其结果是改变的。
作者说分类器自身的问题(分类器本来就具备一定空间不变性),我个人认为其实还是Maxpooling导致的。为了解决这个问题作者采用了fully-connected CRF(Conditional Random Field)方法。
Q:为什么说“CNNs 的不变性特性可能导致在特征提取过程中丢失一些空间信息”?
A:这主要是由于以下几个原因:池化操作:CNN 中常用的池化层(如最大池化或平均池化)会减小特征图的空间尺寸,以减少计算量并增强空间不变性。然而,这种下采样的操作也导致了部分空间信息的丢失。当特征图被缩减时,原始图像中细微的空间结构和位置信息可能被模糊化或忽略,因此在一定程度上丢失了细粒度的空间信息。
卷积核尺寸:在卷积操作中,使用的卷积核尺寸通常较小,只关注局部感受野内的特征。这意味着较大的空间结构可能在特征提取过程中被忽略。虽然通过堆叠多个卷积层可以逐渐扩大感受野,但仍然存在一定程度的局部性。
权值共享:虽然权值共享增强了模型的平移不变性,但这也导致了一些空间信息的丢失。由于卷积核在整个图像上是共享的,网络学习到的特征对于不同位置的相同特征可能具有相同的响应,但对于不同特征的位置信息的差异性较小。
解决方案
为了克服这些技术障碍,在像素级标注任务中,可以采取一些策略,如:避免过度的信号下采样:可以适当减少池化层的使用,或者使用更少的步长来进行池化,以保留更多的空间信息。
结合上采样技术:可以使用转置卷积或其他上采样技术来恢复特征图的空间分辨率,从而更好地处理像素级标注任务。
结合多尺度特征:可以在网络中引入多尺度的特征表示,以捕获不同尺度的信息,并提高对不同大小目标的感知能力。
使用适当的损失函数:对于像素级标注任务,可以使用适当的损失函数,如交叉熵损失或Dice损失,来优化网络并鼓励更准确的像素级标注结果。
3.怎么样?
3.1 模型示意图
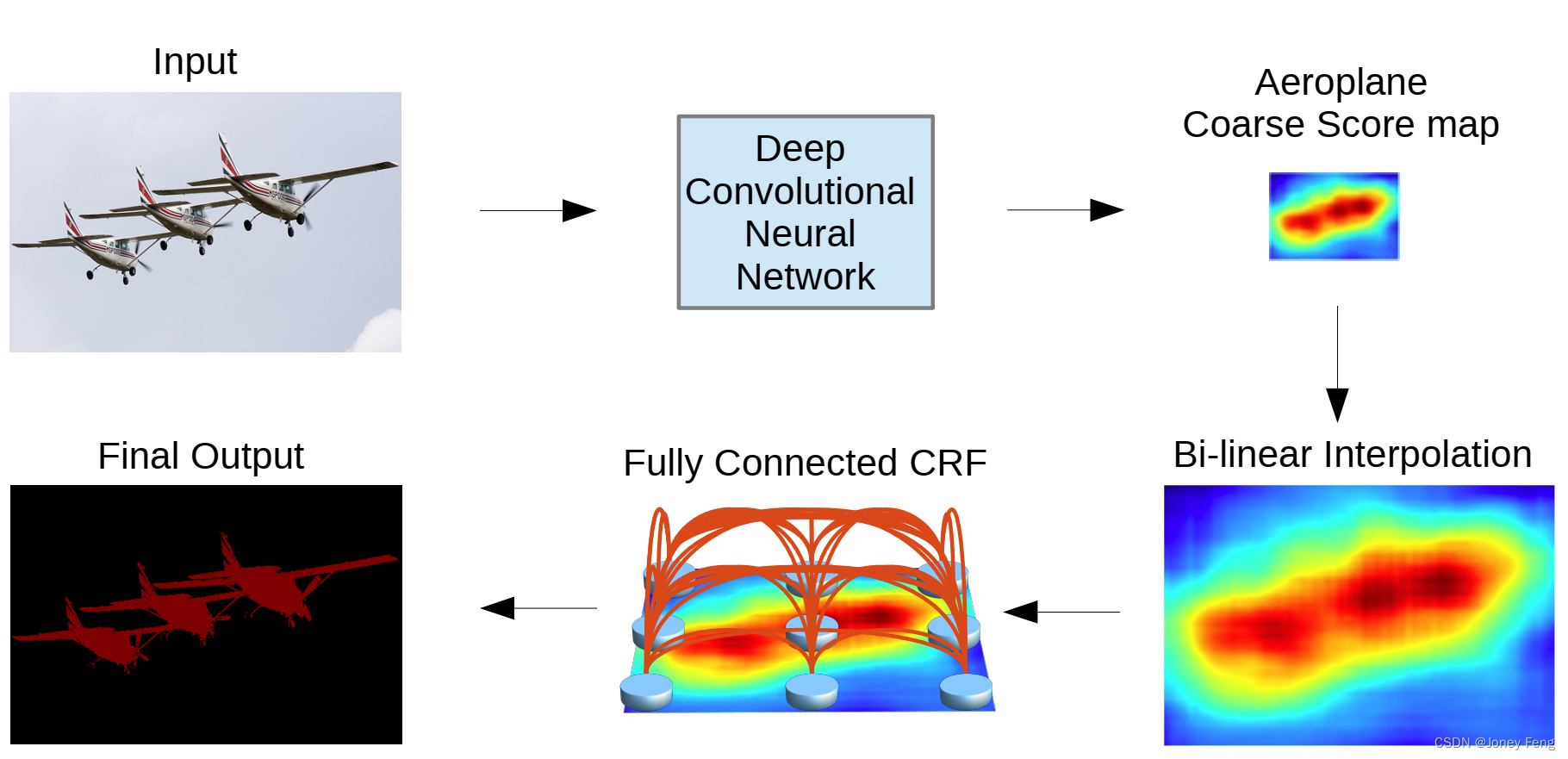
深度卷积神经网络(具有完全卷积层)生成的粗糙分数图通过双线性插值进行上采样。然后,应用全连接CRF来优化分割结果。最佳观看方式为彩色显示。
3.2 LargeFOV

经过上采样得到 224 × 224 × n u m c l a s s e s 224 \times 224 \times \mathrm{num \ classes}224×224×num classes 的特征图并非模型最终输出结果,还要经过一个 Softmax 层后才是模型最终的输出结果。Softmax 层的作用是将每个像素的类别预测转换为对应类别的概率。它会对每个像素的 num_classes 个类别预测进行归一化,使得每个预测值都落在 0 到 1 之间,并且所有类别的预测概率之和为 1。这样,对于每个像素点,我们可以得到每个类别的概率,从而确定该像素属于哪个类别的概率最大。最终的输出结果通常是经过 Softmax 处理后的特征图,其中每个像素点都包含了 num_classes 个类别的概率信息。
LargeFOV 本质上就是使用了膨胀卷积。
通过分析发现虽然 Backbone 是 VGG-16 但所使用 Maxpool 略有不同,VGG 论文中是 kernel=2,stride=2,但在 DeepLab v1 中是 kernel=3,stride=2,padding=1。接着就是最后两个 Maxpool 层的 stride 全部设置成了 1(这样下采样的倍率就从原来的 32 变成了 8)。最后三个 3 × 3 的卷积层采用了膨胀卷积,膨胀系数 r = 2
然后关于将全连接层卷积化过程中,对于第一个全连接层(FC1)在 FCN 网络中是直接转换成卷积核大小为 7 × 7 ,卷积核个数为 4096 40964096 的卷积层(普通卷积),但在 DeepLab v1 中作者说是对参数进行了下采样最终得到的是卷积核大小 3 × 3 ,卷积核个数为 1024 10241024 的卷积层(膨胀卷积),对于第二个全连接层(FC2)卷积核个数也由 4096 40964096 采样成 1024 10241024(普通卷积)。
将 FC1 卷积化后,还设置了膨胀系数(膨胀卷积),论文 3.1 中说的是 r = 4 但在 Experimental Evaluation 中 Large of View 章节里设置的是 r = 12 对应 LargeFOV。对于 FC2 卷积化后就是卷积核 1 × 1 ,卷积核个数为 1024 的普通卷积层。接着再通过一个卷积核 1 × 1 ,卷积核个数为 num_classes(包含背景)的普通卷积层。最后通过 8 倍上采样还原回原图大小。
3.3 CRF
对于每个像素位置 i 具有隐变量 xi (这里隐变量就是像素的真实类别标签,如果预测结果有21类,则 i ∈ ( 1 , 2...21 ) ,还有对应的随机场观测值 yi (即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构建了一个条件随机场(CRF)。通过观测变量 yi 来预测像素位置 i 对应的类别标签 xi。条件随机场示意图如下:

整个模型的能量函数
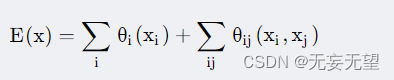
3.4 MSc(Multi-Scale)
作者将两层的 MLP(第一层:具有 128 个 卷积核且大小为 3 × 3 3\times 33×3 的卷积,第二层:具有 128 个卷积核且大小为 1 × 1 1\times 11×1 的卷积)分别附加到输入图像和前四个最大池化层的输出上,然后将它们的特征图与主网络的最后一层特征图进行连接。因此,送入 Softmax 层的聚合特征图将增加 5 × 128 = 640 5 \times 128 = 6405×128=640 个通道。
即 DeepLab v1 除了使用之前主分支上输出外,还融合了来自原图尺度以及前四个 Maxpool 层的输出,更详细的结构参考下图。

3.5 代码实现
VGG16
import torch
import torch.nn as nn
class VGG13(nn.Module):def __init__(self):super(VGG13, self).__init__()self.stage_1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2,2),)self.stage_2 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2,2),)self.stage_3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2,2),) self.stage_4 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2,stride=1, padding=1),)self.stage_5 = nn.Sequential(#空洞卷积nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=2, dilation=2),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=2, dilation=2),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=2, dilation=2),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2, stride=1),) def forward(self, x):x = x.float()x1 = self.stage_1(x)x2 = self.stage_2(x1)x3 = self.stage_3(x2)x4 = self.stage_4(x3)x5 = self.stage_5(x4)return [x1, x2, x3, x4, x5]DeepLabV1
class DeepLabV1(nn.Module):def __init__(self, num_classes):super(DeepLabV1, self).__init__()#前13层是VGG16的前13层,分为5个stageself.num_classes = num_classesself.backbone = VGG13()self.stage_1 = nn.Sequential(#空洞卷积nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=4, dilation=4),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(512),nn.ReLU(),)self.final = nn.Sequential(nn.Conv2d(512, self.num_classes, kernel_size=3, padding=1))def forward(self, x):#调用VGG16的前13层 VGG13x = self.backbone(x)[-1]x = self.stage_1(x)x = nn.functional.interpolate(input=x,scale_factor=8,mode='bilinear')x = self.final(x)return x参考:
DeepLabV1网络简析
论文阅读 || 语义分割系列 —— deeplabv1 详解
[语义分割] DeepLab v
1网络(语义分割、信号下采样、空间上的不敏感性、LargeFOV、膨胀卷积、空洞卷积、MSc、Multi-Scale)
第五章:DeepLabV1——深度卷积神经网络和全连接条件随机场的语义图像分割
语义分割系列-4 DeepLabV1-V3+(pytorch实现)