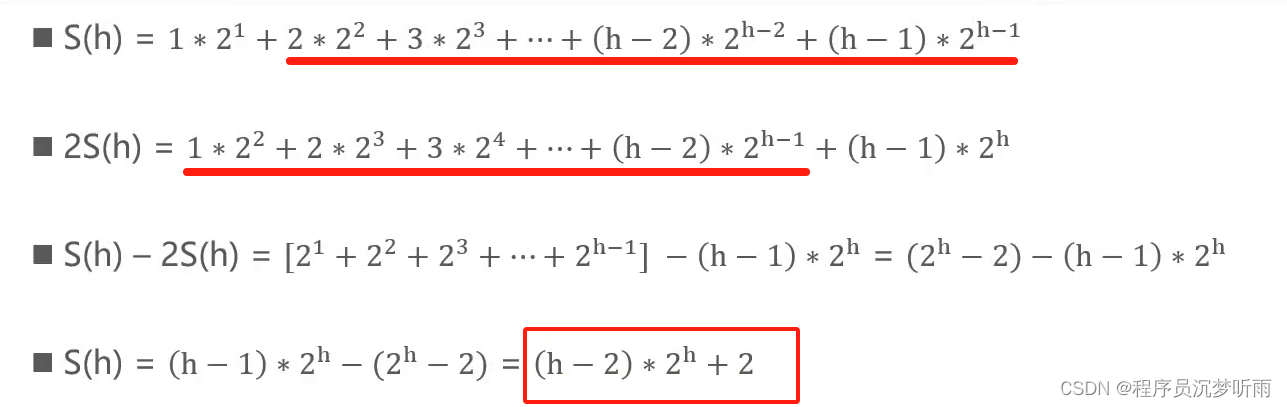一、JVM Optimization
1、G1
G1官网说明:Garbage First Garbage Collector Tuning
The Garbage First Garbage Collector (G1 GC) is the low-pause, server-style generational
garbage collector for Java HotSpot VM. The G1 GC uses concurrent and parallel phases
to achieve its target pause time and to maintain good throughput. When G1 GC determines
that a garbage collection is necessary, it collects the regions with the least live data
first (garbage first).
G1是Java HotSpot VM的低暂停、服务器端应用的垃圾收集器。G1 GC使用并行和并行阶段来实现其目标暂停
时间并保持良好的吞吐量。当G1GC确定有必要进行垃圾收集时,它首先收集具有最少活动数据的区域
(垃圾优先)。分而治之+分层模型
G1内存模型
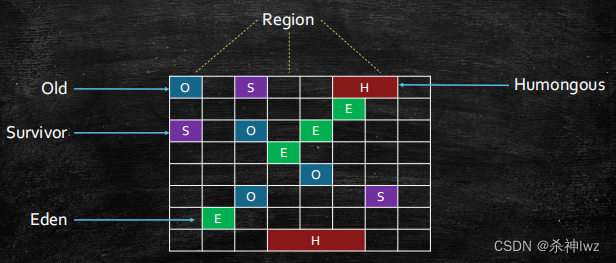
humongous:/hjuːˈmʌŋɡəs/ 巨大的、庞大的
it collects the regions with the least live data first (garbage first).垃圾优先
特点:
并发收集
压缩空闲空间不会延长GC的暂停时间
更易预测的GC暂停时间
适用不需要实现很高的吞吐量的场景
每个分区都可能是年轻代也可能是老年代,但是在同一时刻只能属于某个代。
年轻代、幸存区、老年代这些概念还存在,成为逻辑上的概念,这样方便复用之前分代框架的逻辑。在物理上不需要连续,则带来了额外的好处——有的分区内垃圾对象特别多,有的分区内垃圾对象很少,G1会优先回收垃圾对象特别多的分区,这样可以花费较少的时间来回收这些分区的垃圾,这也就是G1名字的由来,即首先收集垃圾最多的分区。
新生代其实并不是适用于这种算法的,依然是在新生代满了的时候,对整个新生代进行回收——整个新生代中的对象,要么被回收、要么晋升,至于新生代也采取分区机制的原因,则是因为这样跟老年代的策略统一,方便调整代的大小。
G1还是一种带压缩的收集器,在回收老年代的分区时,是将存活的对象从一个分区拷贝到另一个可用分区,这个拷贝的过程就实现了局部的压缩。每个分区的大小从1M到32M不等,但是都是2的幂次方。
JVM Optimization Learning(四)
不断学习才能不断提高!
生如蝼蚁,当立鸿鹄之志,命比纸薄,应有不屈之心。
乾坤未定,你我皆是黑马,若乾坤已定,谁敢说我不能逆转乾坤?
努力吧,机会永远是留给那些有准备的人,否则,机会来了,没有实力,只能眼睁睁地看着机会溜走。