Mutual consistency learning for semi-supervised medical image segmentation
- 基于互一致性学习的半监督医学图像分割
- 背景
- 贡献
- 半监督学习
- 其它缓解过拟合的方法
- 实验
- 方法
- 损失函数
- Thinking
基于互一致性学习的半监督医学图像分割
Medical Image Analysis 81 (2022) 102530
背景
医学影像数据标注困难、昂贵,小规模的数据容易导致深度学习过拟合,性能欠佳,半监督方法使用未标注的数据提高分割性能非常重要。
观察到,使用有限注释训练的深度模型在模糊区域(例如,粘性边缘或细分支)精度不高,用于医学图像分割。利用这些具有挑战性的样本可以使半监督分割模型训练更加有效
贡献
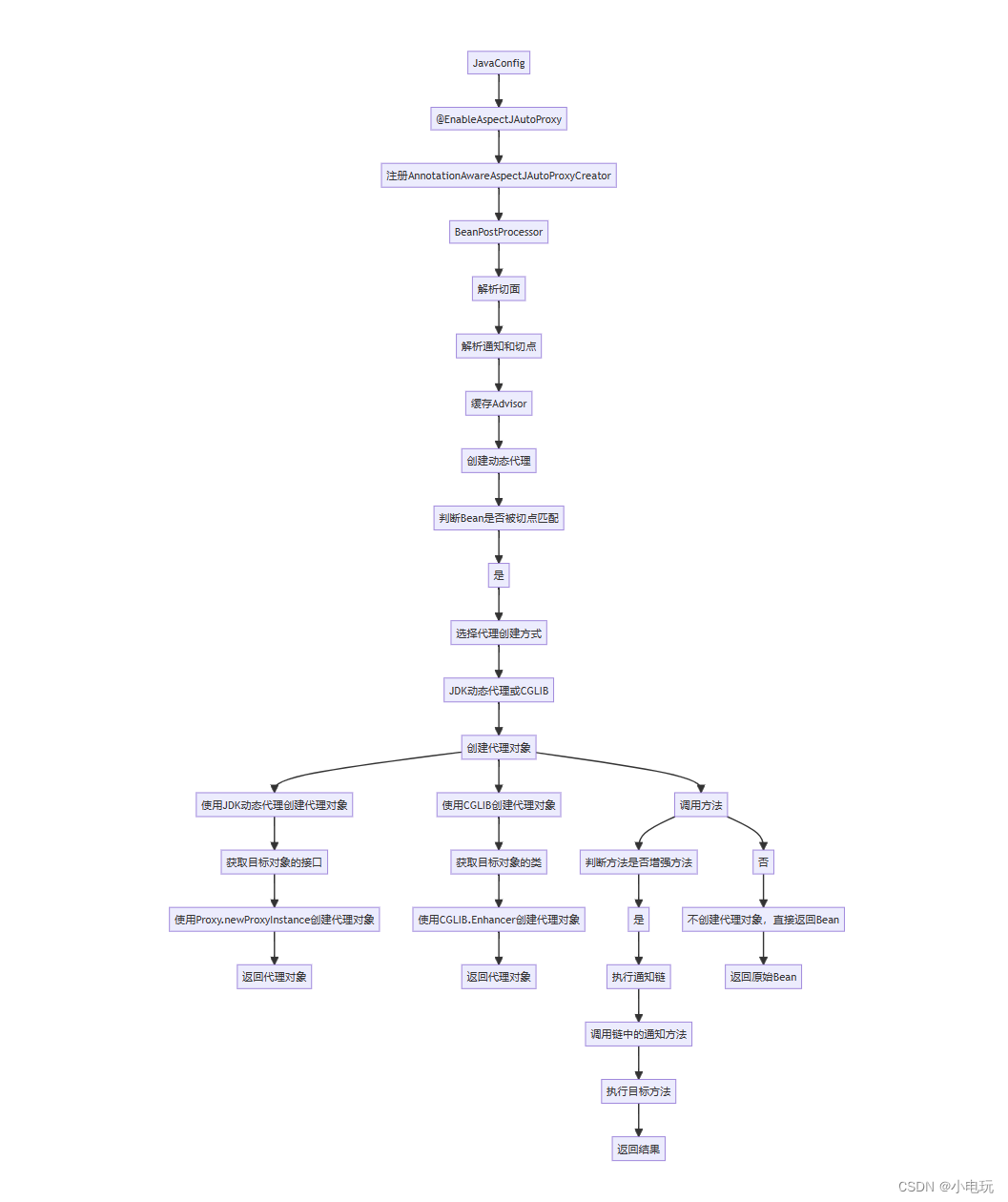
因此,我们提出的MC-Net+模型由两个新的设计组成。
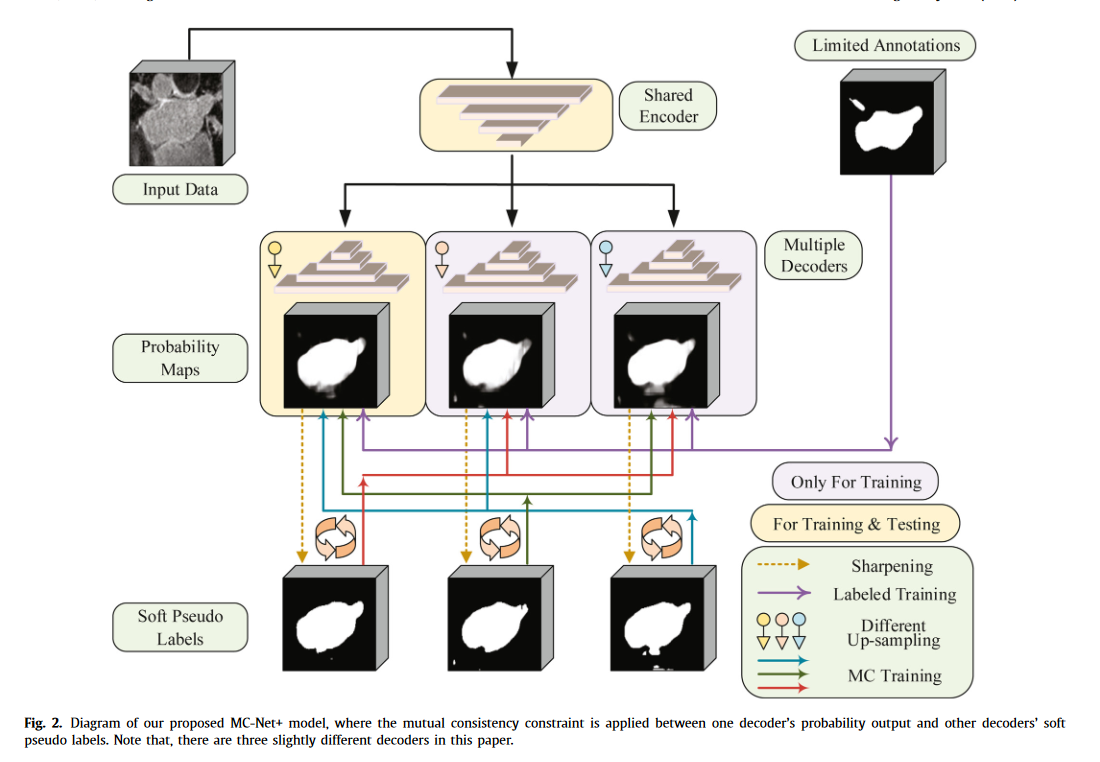
- 首先,该模型包含一个共享编码器和多个略有不同的解码器(即,使用不同的上采样策略)。计算多个解码器输出的统计差异来表示模型的不确定性,这表明了未标记的区域。
- 其次,我们在一个解码器的概率输出和其他解码器的软伪标签之间应用了一种新的相互一致性约束。通过这种方式,我们最小化了训练过程中多个输出的差异(即模型的不确定性),并迫使模型在这种具有挑战性的区域中生成不变的结果,旨在使模型训练正规化。
- 我们在三个公共医疗数据集上比较了我们的MC-Net+模型与五种最先进的半监督方法的分割结果。使用两种标准半监督设置的扩展实验证明了我们的模型优于其他方法的性能,这为半监督医学图像分割开创了新的技术状态。
•我们提出了用于半监督分割的MC-Net+模型,其关键思想是强制该模型在硬区域生成一致的低熵预测,可以有效地利用未标记的数据,提高半监督图像分割性能。
•我们设计了一种新的互一致性方案,以利用模型训练的一致性和熵最小化约束,使模型能够学习广义特征表示。
•大量实验表明,所提出的MC-Net+模型优于最近的五种方法,并为半监督医学图像分割提供了新的技术水平(SOTA)。
半监督学习
现有的半监督学习分为两类:
第一种方法是基于一致性的模型,输入的小扰动不应产生相应输出的明显偏差;第二类由几种熵最小化方法组成,这些方法基于聚类假设,即每个类的聚类应该是紧凑的,因此具有低熵。
深度模型的泛化能力应该与模型的不确定性高度相关。这些观察结果促使我们探索模型的不确定性,以帮助模型推广到这些硬区域,这也与Qiao和Peng(2021)的同时工作一致。
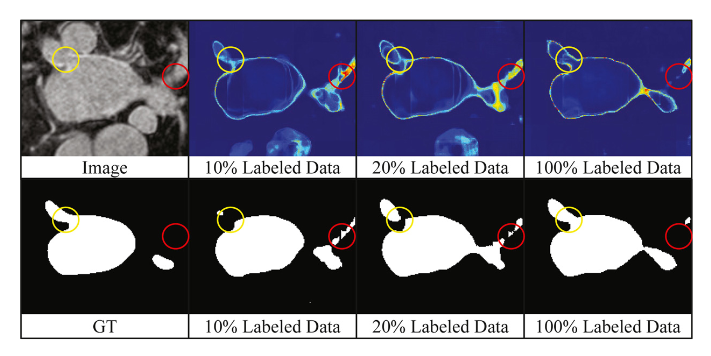
VNet全监督训练的,10%、20%、100%不同数据量,可见,数据量增加,V-Net模型只细化了少数硬区域的预测;(2) 随着用于训练的标记数据的增加,该模型易于输出较少的模糊结果。因此,我们假设深度学习模型的泛化能力应该与模型的不确定性高度相关。这些观察结果促使我们探索模型的不确定性,以帮助模型推广到这些硬区域,这也与Qiao和Peng(2021)的同时工作一致。通过估计的模型不确定性来更多地关注未标记的具有挑战性的区域
目前人们普遍认为,一致性约束和熵最小化约束都可以提高半监督模型的特征判别能力。因此,在本文中,我们在MC-Net+模型中使用这两种技术来进行精确的半监督医学图像分割。
其它缓解过拟合的方法
- 提高深度模型泛化能力的另一个研究方向是通过学习跨任务特征表示或进行无监督的预训练(You et al.,2021)。
- 基于对比学习的模型(Chaitanya et al.,2020)可以进行自我监督训练,以缓解深度模型的过度拟合。
- 例如,You等人,2022a采用全局/局部对比学习从未标记的数据中提取更广义的特征,并为半监督医学图像分割带来了显著的性能提升。
- 此外,可以构建一些代理或辅助任务来显式正则化模型训练(Zhu et al.,2020;You等人,2020)。
- 具体而言,形状或边界约束可用于形状细化,以促进医学图像分割(Ma等人,2020;Murugesan等人,2019)。
- 一些辅助损失(例如,用于图像重建)也可以帮助模型提取更广义和有用的特征(Wang等人,2021;Castillo-Navarro等人,2020)。
- 例如,You等人(2022c)将知识提取和多任务学习相结合,有效地利用了未标记的数据,实现了令人满意的半监督分割性能。
实验
数据集:LA、胰腺CT和ACDC数据集
进行了两种典型的半监督实验设置,即使用10%或20%的标记数据和其余的未标记数据进行训练
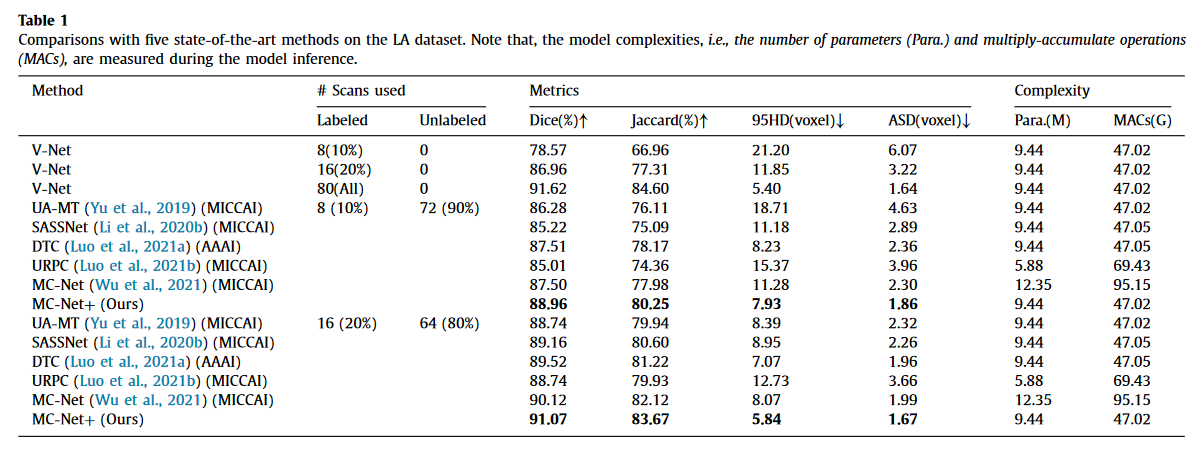
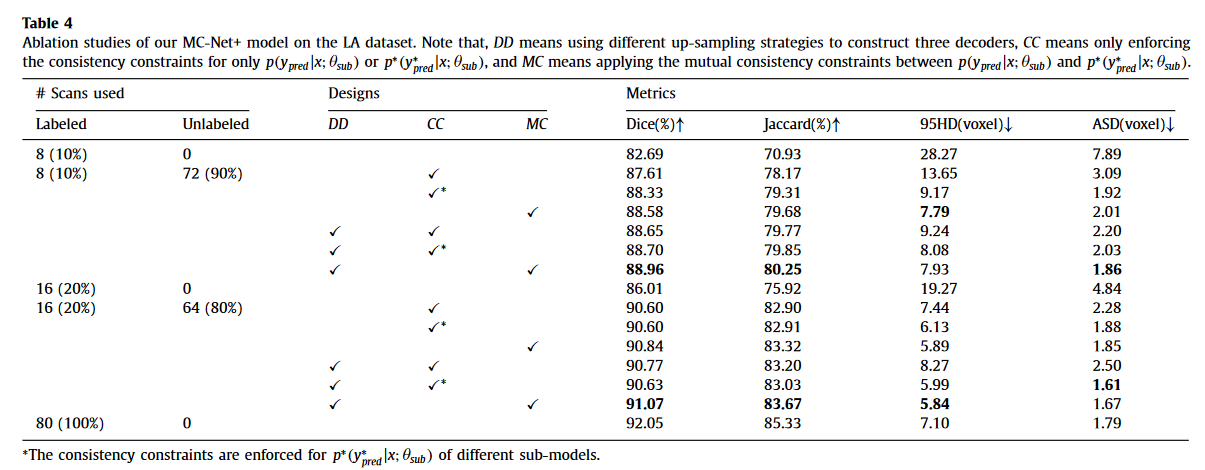
1)通过强迫三个解码器产生相似的结果(即降低模型的不确定性),获得了最显著的性能增益(平均骰子增益分别为5.28%和4.59%);
2) 使用多个略有不同的解码器,用DD标记,导致平均骰子增益分别为0.63%和0.13%。请注意,一项并行工作(Chen et al.,2021)使用了具有不同初始化参数的相同模型架构,而我们使用了不同的上采样策略来进一步增加模型内的多样性,从而获得更好的性能;
3) 鼓励MC标记的训练的相互一致性,经过锐化再计算损失总是比对CC或CC*标记的概率输出或软伪标签应用一致性约束要好
方法
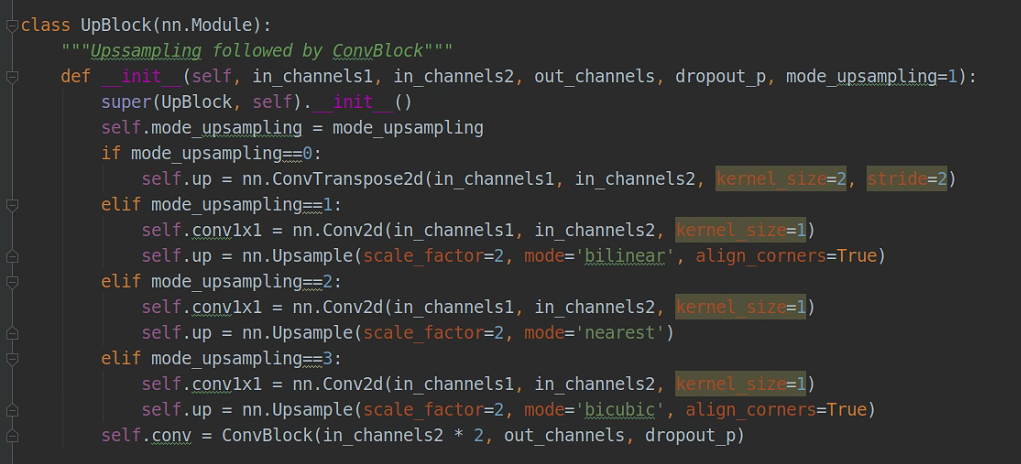
四种不同的上采样方式,转置卷积,bilinear,nearest,bicubic
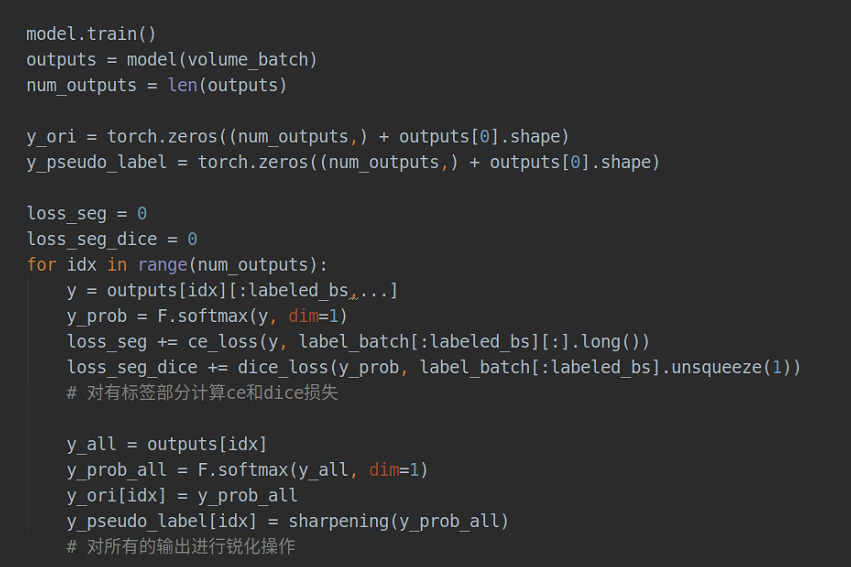
具体训练过程代码:
利用batch_sampler生成数据集,前面labeled_idxs是有标签的,后面unlabeled_idxs是无标签的

三个解码器,outputs是个列表,outputs[0]是主解码器的输出,outputs[1]、outputs[2]是另外两个解码器,最终测试的时候只用outputs[0];
前面labeled_bs个有标签的直接计算CELoss和DiceLoss,CEDice(YlabeledD1, label),CEDice(YlabeledD2, label),CEDice(YlabeledD3, label)
再对所有的outputs经过softmax和锐化处理得到y_pseudo_label,y_ori就是整体的outputs经过softmax
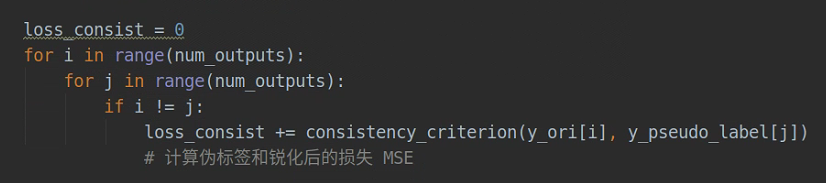
对所有的数据(有标签和无标签一起),计算三个解码器交叉的MSELoss,MSE(Yd1, Yd2锐化),MSE(Yd1, Yd3锐化),MSE(Yd2,Yd1锐化),MSE(Yd2, Yd3锐化),MSE(Yd3, Yd1锐化),MSE(Yd3, Yd2锐化)
损失函数
MSE(Yd1, Yd2锐化),MSE(Yd1, Yd3锐化),MSE(Yd2,Yd1锐化),MSE(Yd2, Yd3锐化),MSE(Yd3, Yd1锐化),MSE(Yd3, Yd2锐化)用于最小化不确定性
锐化公式:
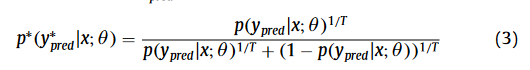
MC损失,就是用锐化前的和锐化后的一致性损失,来自不同解码器
分割损失Lseg是有标签的部分计算的损失
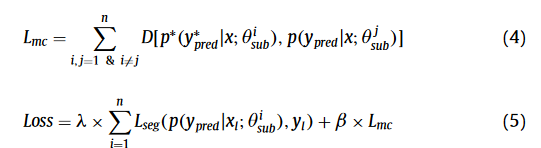
Thinking
多个不同上采样的解码器,对所有数据进行训练,对每个解码器得到的有标签的数据进行有监督分割训练,对所有的数据进行锐化操作,进行判别器之间的交叉一致性训练。消融实验证明了用不同上采样的解码器可以提升精度,用锐化之后再计算一致性损失也能提高精度。