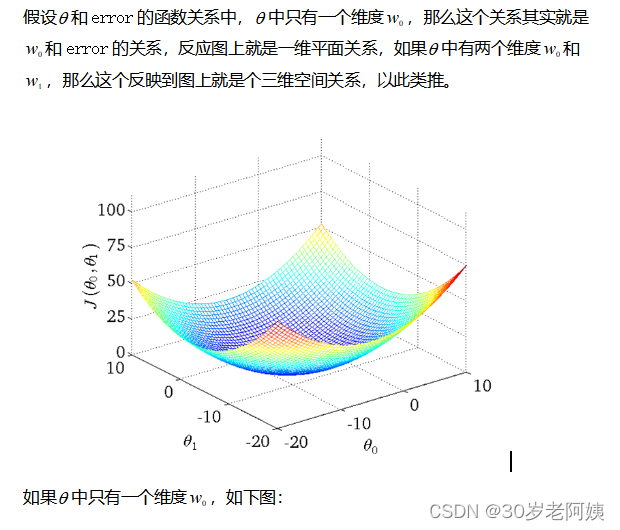
1、梯度下降法调节参数
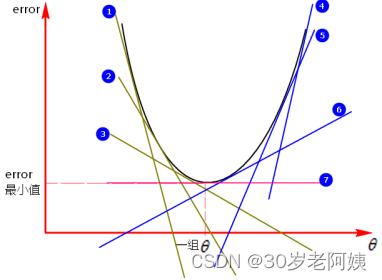

2、模拟过拟合
训练模型都会将数据集分为两部分,一般会将0.8比例的数据集作为训练集,将0.2比例的数据集作为测试集,来训练模型。模型过拟合就是训练出来的模型在训练集上表现很好,但是在测试集上表现较差的一种现象,也就是模型对已有的训练集数据拟合的非常好(误差值等于0),对于测试集数据拟合的非常差,模型的泛化能力比较差。
如何判断模型发生过拟合?
训练出模型后,可以在训练集中测试下模型的正确率,在测试集中测试下模型的正确率,如果两者差别很大(测试集正确率小,训练集正确率大),那么模型就有可能发生了过拟合。
3、Spark Mllib线性回归案例
object LinearRegression {def main(args: Array[String]) {// 构建Spark对象val conf = new SparkConf().setAppName("LinearRegressionWithSGD").setMaster("local")val sc = new SparkContext(conf)Logger.getRootLogger.setLevel(Level.WARN)
// sc.setLogLevel("WARN")//读取样本数据val data_path1 = "lpsa.data"val data = sc.textFile(data_path1)val examples = data.map { line =>val parts = line.split(',')val y = parts(0)val xs = parts(1)LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))}.cache()val train2TestData = examples.randomSplit(Array(0.8, 0.2), 1)/** 迭代次数* 训练一个多元线性回归模型收敛(停止迭代)条件:* 1、error值小于用户指定的error值* 2、达到一定的迭代次数*/val numIterations = 100//在每次迭代的过程中 梯度下降算法的下降步长大小 0.1 0.2 0.3 0.4val stepSize = 1val miniBatchFraction = 1val lrs = new LinearRegressionWithSGD()//让训练出来的模型有w0参数,就是由截距lrs.setIntercept(true)//设置步长lrs.optimizer.setStepSize(stepSize)//设置迭代次数lrs.optimizer.setNumIterations(numIterations)//每一次下山后,是否计算所有样本的误差值,1代表所有样本,默认就是1.0lrs.optimizer.setMiniBatchFraction(miniBatchFraction)val model = lrs.run(train2TestData(0))println(model.weights)println(model.intercept)// 对样本进行测试val prediction = model.predict(train2TestData(1).map(_.features))val predictionAndLabel = prediction.zip(train2TestData(1).map(_.label))val print_predict = predictionAndLabel.take(20)println("prediction" + "\t" + "label")for (i <- 0 to print_predict.length - 1) {println(print_predict(i)._1 + "\t" + print_predict(i)._2)}// 计算测试集平均误差val loss = predictionAndLabel.map {case (p, v) =>val err = p - vMath.abs(err)}.reduce(_ + _)val error = loss / train2TestData(1).countprintln(s"Test RMSE = " + error)// 模型保存val ModelPath = "model"model.save(sc, ModelPath)
// val sameModel = LinearRegressionModel.load(sc, ModelPath)sc.stop()}}




![配置应用程序监听器[org.springframework.web.context.ContextLoaderListener]错误](https://img-blog.csdnimg.cn/direct/062bd992ca8f438bb8addf1da4ff91b5.png)


