文章目录
- 一、强化学习问题
- 1、交互的对象
- 1. 智能体(Agent)
- 2. 环境(Environment)
- 2、强化学习的基本要素
- 1. 状态 𝑠
- 2. 动作 𝑎
- 3. 策略 𝜋(𝑎|𝑠)
- 4. 状态转移概率 𝑝(𝑠′|𝑠, 𝑎)
- 5. 即时奖励 𝑟(𝑠, 𝑎, 𝑠′)
- 3、策略(Policy)
- 1. 确定性策略(Deterministic Policy)
- 2. 随机性策略(Stochastic Policy)
- 3. 选择随机性策略的优点
一、强化学习问题
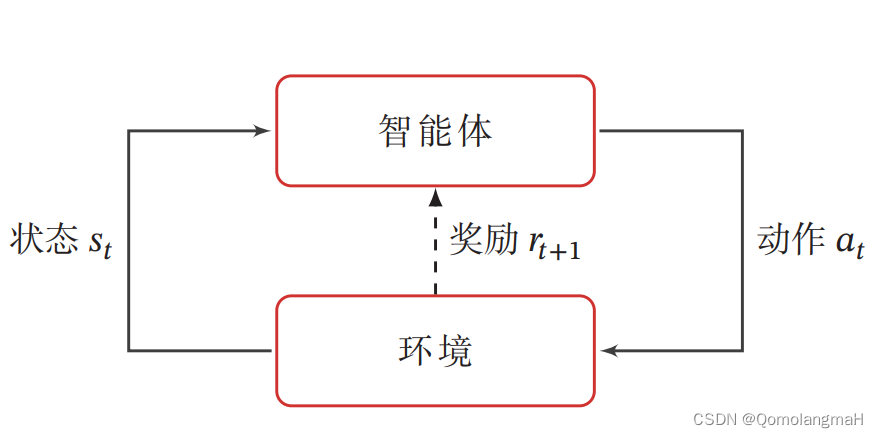
强化学习的基本任务是通过智能体与环境的交互学习一个策略,使得智能体能够在不同的状态下做出最优的动作,以最大化累积奖励。这种学习过程涉及到智能体根据当前状态选择动作,环境根据智能体的动作转移状态,并提供即时奖励的循环过程。
1、交互的对象
在强化学习中,有两个可以进行交互的对象:智能体和环境:
1. 智能体(Agent)
智能体是具有感知、学习和决策能力的实体。它能感知来自环境的状态(State),并根据学到的策略(Policy做出不同的动作,其目标是通过与环境的交互获得最大的累积奖励(Reward)。
-
感知外界环境的状态和奖励:
- 智能体能够感知环境的状态,也就是获取关于环境当前情况的信息。
- 智能体还可以接收来自环境的即时奖励,即环境对智能体当前行为的反馈。
-
学习功能:
- 智能体能够根据环境的反馈(奖励信号)来调整自己的策略。
- 学习的目标通常是最大化累积奖励,使智能体能够在与环境的交互中表现得更加智能。
-
决策功能:
- 智能体通过决策来做出动作(即智能体对环境做出的响应),其目标是产生对环境有利的结果,即最大化奖励。
2. 环境(Environment)
环境包括智能体外部的一切事物,是智能体所处的背景。环境的状态可能随着智能体的动作而改变,并且会提供奖励或惩罚,用于反馈智能体的行为。
-
外部事物:
- 环境是智能体外部的一切事物,包括所有与智能体进行交互的元素。
- 可以是虚拟环境(例如计算机模拟的游戏场景)或真实环境(例如机器人在现实世界中的移动)。
-
状态的改变:
- 智能体的动作会影响环境的状态,导致环境发生变化。
- 这种状态的变化反过来会影响智能体在未来做出的决策。
-
奖励的反馈:
- 智能体的动作不仅会改变环境的状态,还会导致环境给予智能体一个奖励信号。
- 奖励信号是智能体学习过程中的关键反馈,用于调整智能体的行为。
通过智能体与环境之间的这种相互作用,智能体通过学习和不断调整其决策策略,逐渐学会在给定环境中获得最大化奖励的有效行为,这就是强化学习的基本框架。
2、强化学习的基本要素
强化学习涉及到智能体与环境的交互,其基本要素包括状态、动作、策略、状态转移概率和即时奖励。
1. 状态 𝑠
-
定义: 状态是对环境的描述,可以是离散的或连续的,用来表示智能体所处的环境情境。
-
状态空间: 状态的集合构成状态空间,通常表示为 𝒮。
- 状态空间描述了所有可能的环境状态。
2. 动作 𝑎
-
定义: 动作是对智能体行为的描述,可以是离散的或连续的。
- 智能体通过选择动作来影响环境。
-
动作空间: 动作的集合构成动作空间,通常表示为 𝒜。
- 动作空间描述了所有可能的智能体行为。
3. 策略 𝜋(𝑎|𝑠)
- 定义: 策略是一个函数,用来描述智能体在给定状态下选择不同动作的概率。
- 即𝜋(𝑎|𝑠) 表示在状态 𝑠 下选择动作 𝑎 的概率。
4. 状态转移概率 𝑝(𝑠′|𝑠, 𝑎)
- 定义: 状态转移概率描述了在智能体在状态 𝑠 下执行动作 𝑎 后,环境转移到下一个状态 𝑠′ 的概率。
5. 即时奖励 𝑟(𝑠, 𝑎, 𝑠′)
- 定义: 即时奖励是一个标量函数,表示在智能体在状态 𝑠 执行动作 𝑎 后,环境反馈给智能体的奖励。
- 这个奖励通常与下一个状态 𝑠′ 有关。
3、策略(Policy)
策略(Policy)就是智能体如何根据环境状态 𝑠 来决定下一步的动作 𝑎(智能体在特定状态下选择动作的规则或分布)。
策略是智能体学习和决策的核心,它决定了智能体在不同状态下应该采取什么样的行为,它可以是确定性的,也可以是随机性的。确定性策略(Deterministic Policy)直接指定智能体应该采取的具体动作,而随机性策略(Stochastic Policy)则考虑了动作的概率分布,增加了对不同动作的探索。
1. 确定性策略(Deterministic Policy)
- 定义: 确定性策略是指从状态空间到动作空间的映射函数,即给定某个状态,智能体会选择一个确定的动作。
- 映射函数: 用符号 𝜋: 𝒮 → 𝒜 表示,表示策略将状态映射到唯一的动作。
- 数学表示:
确定性策略: π ( a ∣ s ) ≡ μ ( s ) \text{确定性策略:} \quad \pi(a|s) \equiv \mu(s) 确定性策略:π(a∣s)≡μ(s)
其中, μ ( s ) \mu(s) μ(s) 是一个确定性映射,将状态 s s s 映射到相应的动作 a a a。
2. 随机性策略(Stochastic Policy)
- 定义: 随机性策略表示在给定环境状态时,智能体选择某个动作的概率分布。
- 随机性策略引入了随机性,即相同状态下可能选择不同的动作。
- 数学表示: 用符号 𝜋(𝑎|𝑠) 表示,在状态 𝑠 下选择动作 𝑎 的概率
随机性策略: π ( a ∣ s ) ≡ p ( a ∣ s ) \text{随机性策略:} \quad \pi(a|s) \equiv p(a|s) 随机性策略:π(a∣s)≡p(a∣s)
其中, p ( a ∣ s ) p(a|s) p(a∣s) 是在状态 s s s 下选择动作 a a a 的概率分布,且满足概率分布的性质:
∑ a ∈ A π ( a ∣ s ) = 1 \sum_{a \in \mathcal{A}} \pi(a|s) = 1 a∈A∑π(a∣s)=1 - 随机性策略允许智能体在相同的状态下以不同的概率选择不同的动作,使得智能体在探索和利用之间能够找到平衡。
3. 选择随机性策略的优点
- 更好的探索性:
- 引入一定的随机性有助于智能体更好地探索环境。
- 在学习阶段,智能体可能通过尝试不同的动作来发现潜在的高奖励路径。
- 多样性的动作:
- 随机性策略使得智能体在相同的状态下选择多样的动作。
- 这对于博弈等多智能体场景中非常重要,因为确定性策略可能会导致对手能够准确预测智能体的行为。
- 避免易被预测:
- 采用确定性策略的智能体对相同的状态会做出相同的动作,这使得其策略相对容易被对手预测。
- 随机性策略的引入增加了对手对智能体行为的不确定性。
![[HITCON 2017]SSRFme perl语言的 GET open file 造成rce](https://img-blog.csdnimg.cn/direct/4b858c98342545e1894101da34d33673.png)