深度学习自然语言处理 原创
作者: Xnhyacinth
在自然语言处理(NLP)领域,如何有效地进行无监督域自适应(Unsupervised Domain Adaptation, UDA) 一直是研究的热点和挑战。无监督域自适应的目标是在目标域无标签的情况下,将源域的知识迁移到目标域,以提高模型在新领域的泛化能力。近年来,随着大规模预训练语言模型的出现,情境学习(In-Context Learning) 作为一种新兴的学习方法,已经在各种NLP任务中取得了显著的成果。然而,在实际应用场景中,我们经常面临一个问题:源领域的演示数据并不总是一目了然。这就导致了需要进行跨领域的上下文学习的问题。此外,LLMs在未知和陌生领域中仍然面临着一些挑战,尤其是在长尾知识方面。同时在无监督域自适应任务中,如何充分利用情境学习的优势进行知识迁移仍然是一个开放性问题。
本文旨在探讨如何在无监督域自适应场景下,通过检索增强的情境学习(Retrieval-Augmented In-Context Learning) 实现知识迁移。具体来说,作者提出了一种名为Domain Adaptive In-Context Learning (DAICL) 的框架,该框架通过检索目标域的相似示例作为上下文,帮助模型学习目标域的分布和任务特征。全面研究了上下文学习对于领域转移问题的有效性,并展示了与基线模型相比取得的显著改进。
接下来就让我们一起看看作者是如何实现检索增强情境学习的知识迁移!

论文: Adapt in Contexts: Retrieval-Augmented Domain Adaptation via In-Context Learning
地址: https://arxiv.org/pdf/2311.11551.pdf
前言
在自然语言处理领域,大型语言模型(LLMs)通过其强大的能力在各种任务上取得了显著的成功。然而,当面临跨领域的情景时,LLMs仍面临着挑战,由于目标域标签不可用,在实际场景中通常缺乏域内演示。从其他领域获取带标签的示例可能会遭受巨大的句法和语义领域变化。此外,LLMs很容易产生不可预测的输出, 而且LLMs在未知和陌生领域的长尾知识上仍然存在局限性。因此亟需有效的适应策略,将语言模型的知识从标记的源域转移到未标记的目标域,称为无监督域适应(UDA)。UDA 旨在调整模型,从标记的源样本和未标记的目标样本中学习与领域无关的特征。
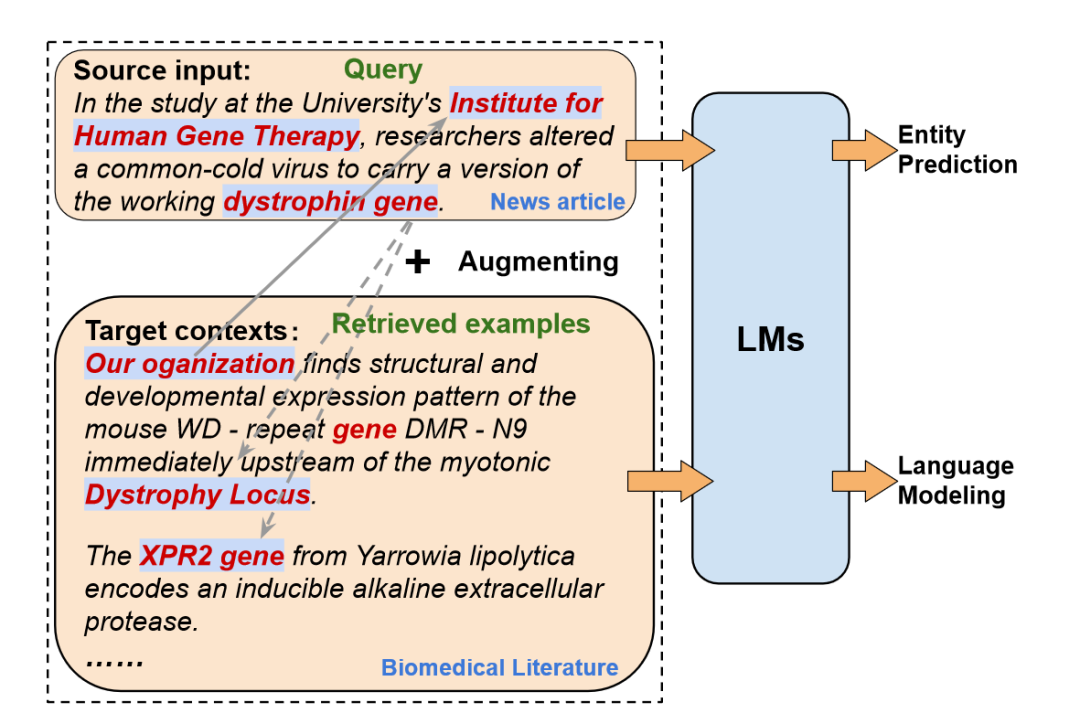
为了解决这些问题,本文提出了一种基于上下文学习的无监督领域适应(Unsupervised Domain Adaptation, UDA)方法,旨在将LLMs从源领域成功适应到目标领域,无需任何目标标签。从目标未标记语料库中检索类似的示例作为源查询的上下文,并通过连接源查询和目标上下文作为输入提示来执行自适应上下文学习。如上图所示,对于来自源域的每个输入,将其上下文与从目标未标记域检索到的语义相似的文本组合起来,以丰富语义并减少表面形式的域差异。然后,模型将学习源输入和目标上下文的任务区分。
方法
该研究提出了一种名为Domain Adaptive In-Context Learning (DAICL)的框架,通过检索目标域的相似示例作为上下文,帮助模型学习目标域的分布和任务特征,使LLMs同时学习目标领域分布和判别性任务信号。具体来说,对于给定的源域数据和目标域数据,首先使用检索模型(如SimCSE)在目标域中检索与源域数据相似的示例。然后,将检索到的示例作为上下文,与源域数据一起作为输入,进行情境学习。通过这种方式,模型可以在目标域的上下文中学习任务特征,同时适应目标域的数据分布。主要分为以下几个部分:
检索目标域相似示例:首先,在目标域中检索与源域数据相似的示例。这一步的目的是找到能够代表目标域特征的示例,以便模型能够在目标域的上下文中学习任务特征。检索方法可以采用现有的密集检索模型,如SimCSE。
构建上下文:将检索到的目标域相似示例与源域数据一起作为输入,形成上下文。这样,模型可以在目标域的上下文中学习任务特征,同时适应目标域的数据分布。
情境学习:在构建的上下文上进行情境学习。这里采用了两种任务损失函数:(1)上下文任务损失,用于学习任务特征,预测标签值y;(2)上下文语言建模损失,用于学习目标域的分布。通过优化这两个损失函数,模型可以在目标域中实现知识迁移。
模型训练:根据所使用的模型架构(如编码器,解码器模型),设计相应的prompting策略和训练策略。对于编码器模型,可以采用提示词(prompt)策略,将源域数据和检索到的目标域示例拼接在一起作为输入;对于解码器模型,可以直接将检索到的目标域示例作为输入,进行自回归学习。
模型评估:在目标域的测试数据上评估模型性能。通过比较不同方法在命名实体识别(NER)和情感分析(SA)等任务上的结果,验证DAICL框架的有效性。
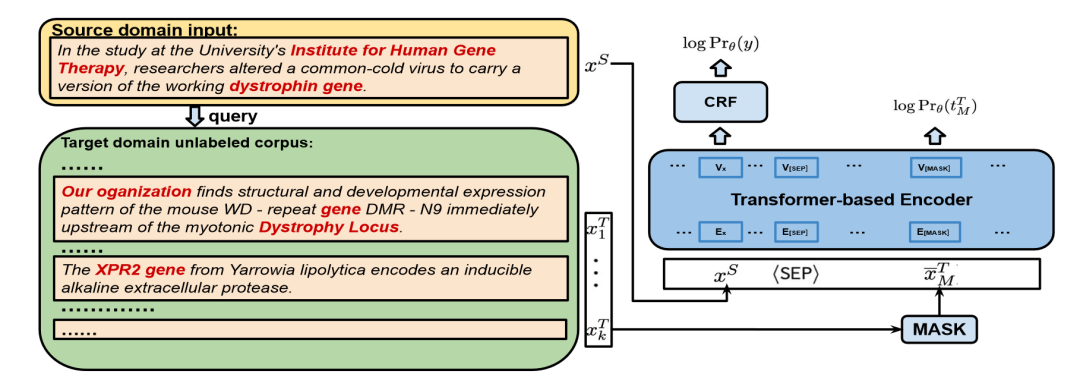
如上图所示, 显示了 NER 任务上仅编码器模型的训练过程概述,MLM 目标会鼓励编码器学习与源域无法区分的目标分布。对于任务学习目标,在源输入上使用平均汇聚(average pooling) 作为情感分析任务的预测机制,而在语言模型特征之上使用附加的条件随机场(CRF)层进行命名实体识别任务的标记级别分类。
对于仅解码器架构,包括仅推理和微调两种范式,下图图为带有推理提示的示例,在给定目标测试查询的情况下从源标记数据集中搜索输入标签对。虚线框包含从源检索的演示。

对于微调设置下,利用lora用更少的计算资源微调更大的 LM,微调数据示例形式为,如下所示:

实验设置
为了评估DAICL方法的有效性,该研究在命名实体识别(NER)和情感分析(SA)任务上进行了广泛的实验。实验采用了多种源域和目标域的组合,涵盖了新闻、社交媒体、金融和生物医学等领域。CoNLL-03(英语新闻)作为源域数据集,目标域数据集包括:金融(FIN)、社交媒体(WNUT-16、WNUT-17)、生物医学(BC2GM、BioNLP09、BC5CDR) 对于情感分析(SA)任务,使用了亚马逊评论数据集,涵盖了四个领域:书籍(BK)、电子产品(E)、美容(BT)和音乐(M)。
本文对比了多种基线方法,包括无监督域自适应的传统方法(如Pseudo-labeling和对抗训练)、基于检索的LM方法(如REALM和RAG)和情境学习方法(如In-context learning)。在实验中,将不同的LLMs架构与提出的In-Context Learning方法进行对比,并评估其在领域适应中的性能。对于评估指标,NER任务使用了F1分数,SA任务使用了准确率acc。
结果分析
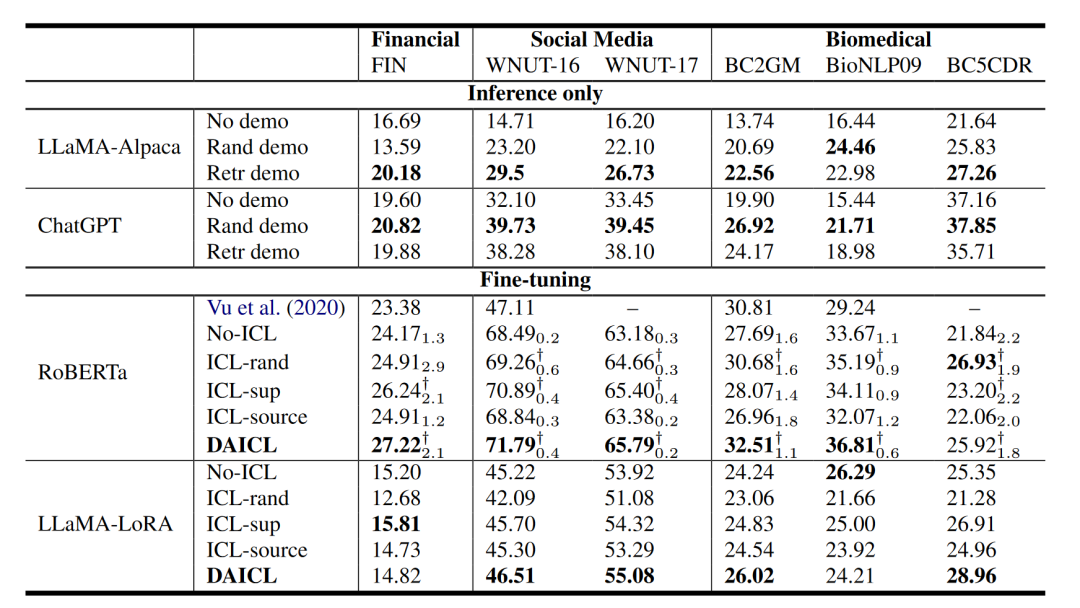
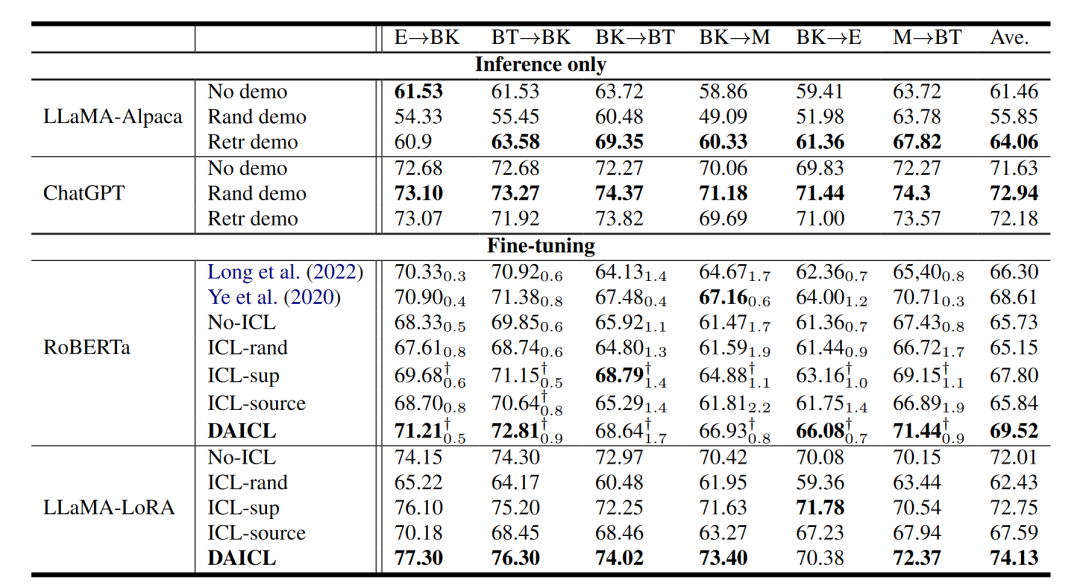
由以上两个任务的性能对比表可知,DAICL 同时学习两个目标,在大多数适应场景中都大大超过了基线。从 ICL-sup 的结果来看,我们发现仅使用任务目标进行训练对 UDA 略有帮助。正如前面所讨论的,好处源于利用目标上下文的任务判别能力。通过将 DAICL 与 ICL-sup 和 ICL-source 进行比较,可以发现所提出的上下文适应策略通过同时联合学习任务信号和语言建模来增强领域适应。
微调有益于UDA,在 NER 实验中,ChatGPT 的性能非常低,但微调更小的 RoBERTa 模型可以在大多数适应场景中实现最先进的分数。在 SA 实验中,使用更少的可训练参数 (1.7M) 微调 LLaMA 优于所有其他方法。因此,我们假设虽然法学硕士具有很强的泛化能力,但他们不能解决所有领域的问题。对于UDA来说,设计一个有效的适配策略还是有好处的。
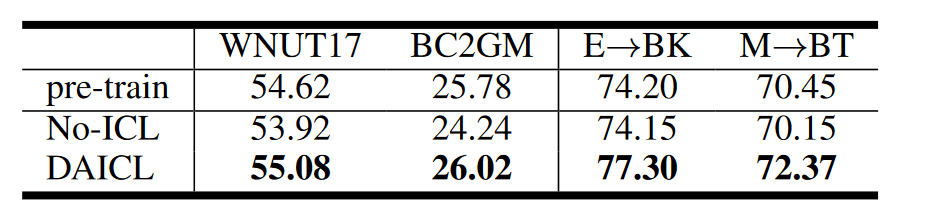
最后作者也对比了自适应ICL和自适应预训练,自适应 ICL 在执行任务预测时将源输入与目标上下文混合,而自适应预训练只需要源输入;自适应ICL同时学习两个损失。为了比较这两种方法,在 LLaMA-LoRA 上进行了实验以执行自适应预训练。在第一阶段,使用目标未标记文本预训练 LoRA 权重。第二阶段,从上一阶段获得的LoRA检查点开始,通过任务监督继续对其进行微调。使用相同的羊Alpaca模板,但不提供说明性上下文。结果见上表,可以观察到,与 NoICL 相比,预训练对 SA 任务带来的收益很小,可以推测 SA 数据集中的域差距比 NER 数据集中的域差距更小。从而得出结论所提出的自适应 ICL 策略优于自适应预训练,这可能归因于自适应 ICL 下的仅解码器模型可以学习具有示范上下文的两个目标。
总结
本文提出了一种名为Domain Adaptive In-Context Learning (DAICL)的框架,用于实现无监督域自适应(UDA)。该框架通过检索目标域的相似示例作为上下文,结合任务损失和领域适应损失进行情境学习,以实现知识迁移。实验采用了多个源域和目标域的数据集,包括命名实体识别(NER)和情感分析(SA)任务。与多种基线方法相比,DAICL在多种跨域场景下均取得了显著的性能提升,证明了其有效性。
尽管本文的方法在领域自适应上取得了令人满意的结果,但仍有一些可以进一步探索和改进的方向。首先,可以进一步研究不同的上下文学习策略,以进一步提高语言模型的领域适应能力。其次,可以考虑在不同任务和领域之间进行联合训练,以进一步提升模型的泛化性能。此外,还可以探索如何将上下文学习与其他领域自适应技术(如对抗训练)相结合,以进一步改进模型的适应性和抗干扰能力;可以考虑将多个任务同时进行无监督域自适应,以提高模型的泛化能力和适应性。通过在这些方向进行探索和改进,未来研究有望进一步提高无监督域自适应方法的性能,为实际应用提供更有效的解决方案。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦