预训练–微调
一个很简单的道理,如果我们的模型是再ImageNet下训练的,那么这个模型一定是会比较复杂的,意思就是这个模型可以识别到很多种类别的即泛化能力很强,但是如果要它精确的识别是否某种类别,它的表现可能就不佳了,因此,我们需要在原来的基础上再对特定的我们需要识别的类别进行重新训练,微调原来网络结构中的参数,此时模型还是可以抽取较通用的图像特征。
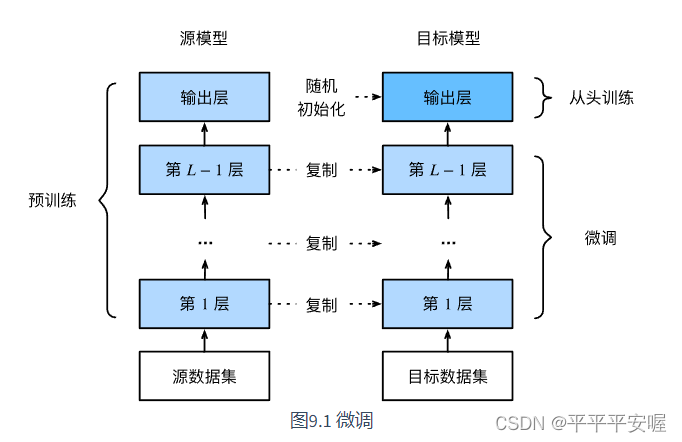
参考自https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter09_computer-vision/9.2_fine-tuning
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
热狗识别
源数据集是ImageNet,超过1000万个图像和1000类物体,热狗数据集包含1400个正类图像和其他多种负类图像
最开始还是导入所需要的库以及设置cuda
import torch
from torch import nn,optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision import models
import os
import d2lzh_pytorch as d2l
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
下载数据集https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/hotdog.zip
我直接放在了我的默认路径下,读数据如下
train_imgs = ImageFolder("hotdog/train")
test_imgs = ImageFolder("hotdog/test")
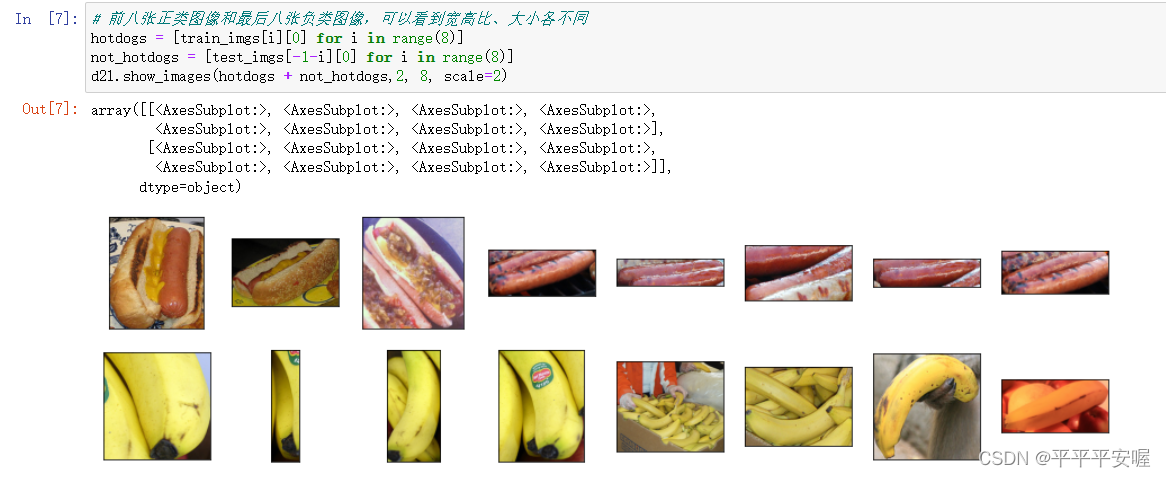
然后我们观察一下数据集,可以看到大小,宽高比各不同
# 前八张正类图像和最后八张负类图像,可以看到宽高比、大小各不同
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [test_imgs[-1-i][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs,2, 8, scale=2)
接下来就是训练时,我们先从图像中随机裁剪一块区域,然后将该区域缩放成224*224的图像进行输入,测试时,我们将图像的高和宽均缩放为256像素,然后从中裁剪出高、宽均为224的中心区域作为输入,此外对RGB三通道作标准化,每个数值减去通道的平均值,再除以标准差需要注意的是,在使用预训练模型时,一定要和预训练时作同样的预处理。 如果你使用的是torchvision的models,
那就要求: All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224. The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225].
如果你使用的是pretrained-models.pytorch仓库,请务必阅读其README,其中说明了如何预处理。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
train_augs = transforms.Compose([#transforms.Resize(size=256), # 是将最小边调整到256#transforms.CenterCrop(size=224),transforms.RandomResizedCrop(size=224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize
])test_augs = transforms.Compose([transforms.Resize(size=256),transforms.CenterCrop(size=224),transforms.ToTensor(),normalize
])
需要注意的是,首先我有最开始有两点疑惑
- 为什么不能需要从图像中随机裁剪一块区域,然后将该区域缩放成224*224的图像进行输入。然后我测试了一下,如果不这样做的话,那么泛化能力会比较差
- 如果非要这么做,那么可不可以直接transforms.Resize(size=224)?不可以的,transforms.Resize(size=224)是把最短的边变为224,宽高比没变,那么这样就会导致图像的尺寸不一样,后面自然会报错,所以需要先transforms.Resize(size=256),然后transforms.CenterCrop(size=224)
之后我们使用在ImageNet上预训练的ResNet18,pretrained=True,自动下载预训练参数
不管你是使用的torchvision的models还是pretrained-models.pytorch仓库,默认都会将预训练好的模型参数下载到你的home目录下.torch文件夹。
你可以通过修改环境变量$TORCH_MODEL_ZOO来更改下载目录
pretrained_net = models.resnet18(pretrained=True)
修改最后一层
pretrained_net.fc = nn.Linear(512, 2)
接下来设置训练的参数,由于除了最后一层,之前的参数都经过预训练,所以我们学习率调小一点,最后的fc层是初始化过的,于是我们学习率调大一点
output_params = list(map(id, pretrained_net.fc.parameters())) # fc层
feature_params = filter(lambda p: id(p) not in output_params, pretrained_net.parameters()) # 除了fc层
lr = 0.01 # 用来更新特征层
# fc层是lr * 10
optimizer = optim.SGD([{"params":feature_params},{"params":pretrained_net.fc.parameters(), "lr":lr*10}
] ,lr = lr, weight_decay=0.001)
在之后就是训练了
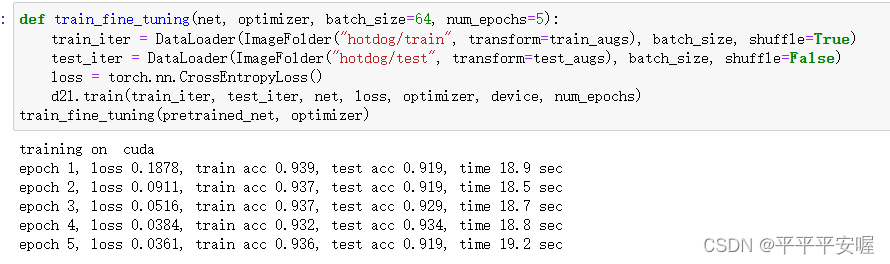
def train_fine_tuning(net, optimizer, batch_size=64, num_epochs=5):train_iter = DataLoader(ImageFolder("hotdog/train", transform=train_augs), batch_size, shuffle=True)test_iter = DataLoader(ImageFolder("hotdog/test", transform=test_augs), batch_size, shuffle=False)loss = torch.nn.CrossEntropyLoss()d2l.train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
train_fine_tuning(pretrained_net, optimizer)