数据库操作语言包括DDL、DML、DQL和DCL,分别用于定义、操作、查询和控制数据库。
DDL(Data Definition Language)数据定义语言:
DDL用于定义数据库、表、列、索引、视图、存储过程、触发器等对象,包括CREATE、ALTER、DROP等命令。
常用的DDL命令有:
- CREATE:创建数据库或表
- ALTER:修改数据库或表结构
- DROP:删除数据库或表
DML(Data Manipulation Language)数据操作语言:
DML用于添加、删除、更新和查询数据,包括INSERT、DELETE、UPDATE和SELECT等命令。
常用的DML命令有:
- INSERT:插入数据
- DELETE:删除数据
- UPDATE:更新数据
- SELECT:查询数据
DQL(Data Query Language)数据查询语言:
DQL用于查询数据,包括SELECT命令。SELECT可以查询指定的列、表、条件和排序方式等。
DCL(Data Control Language)数据控制语言:
DCL用于控制数据库对象的访问、权限、安全性等,包括GRANT和REVOKE命令。GRANT授权将访问权限授予用户和角色,REVOKE撤销访问权限。
SQL关键字的执行顺序通常是:
- FROM:从哪个表中获取数据
- JOIN:连接其他表
- WHERE:筛选满足条件的数据
- GROUP BY:按照指定的列进行分组
- HAVING:对分组后的数据进行筛选
- SELECT:选择要返回的列
- DISTINCT:去除重复的数据
- ORDER BY:按照指定的列进行排序
- LIMIT:限制返回的数据条数
MySQL是一种开源的关系型数据库管理系统。以下是MySQL的基本语句:
#基本语句
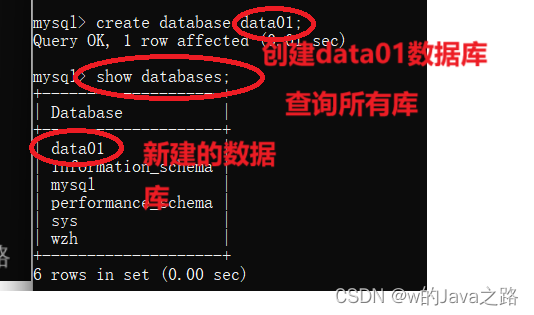
查询所有数据库:
show databases;
创建数据库:
CREATE DATABASE database_name;
选择数据库:
USE database_name;
![]()
创建表格:
CREATE TABLE table_name (column1 datatype constraint,column2 datatype constraint,...
);
插入数据:
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
更新数据:
UPDATE table_name SET column_name = new_value WHERE condition;
删除数据:
DELETE FROM table_name WHERE condition;
注意:要注意字段和值之间的对应情况,逗号隔开,若update和delete没有指定where语句的话或直接默认全部;
insert into user(id, name, age) value (1,'zhangsan',23);
insert into user(id, name, age) value (2,'lisi',24);insert into user values (3,'wangwu',25);update user set name = 'zhaoliu' where id =1;update user set name='小美',age=18 where id=3;update user set age=18;delete from user where id=1;
delete from user ;select * from user;
查询数据:
SELECT column1, column2, ... FROM table_name WHERE condition;
对数据进行排序:
SELECT column1, column2, ... FROM table_name ORDER BY column_name ASC/DESC;
对数据进行分组:
SELECT column1, COUNT(column2) FROM table_name GROUP BY column1;
连接表格:
SELECT column1, column2, ... FROM table1 JOIN table2 ON table1.column_name = table2.column_name;
下面是练习代码:
先创建表内数据
insert into emp(id, workno, name, gender, age, idcard, workaddress, date)
values (1,'1','柳岩','女',20,'123456789012345678','北京','2000-01-01 '),(2,'2','张无忌','男',18,'123456789012345670','北京','2005-09-01 '),(3,'3','韦一笑','男',38,'123456789712345670','上海','2005-08-01 '),(4,'4','赵敏','女',18,'123456757123845670','北京','2009-12-01'),(5,'5','小昭','女',16,'123456769012345678','上海','2007-07-01'),(6,'6','杨道','男',28,'12345678931234567X','北京','2006-01-01'),(7,'7','范瑶','男',40,'123456789212345670','北京','2005-05-01 '),(8,'8','黛绮丝','女',38,'123456157123645670','天津','2015-05-01'),(9,'9','范凉凉','女',45,'123156789012345678','北京','2010-04-01 '),(10,'10','陈友谅','男',53,'123456789012345670','上海','2011-01-01 '),(11, '11 ','张士诚','男',55,'123567897123465670','江苏','2015-05-01 ') ,(12,'12','常遇春','男',32,'123446757152345670','北京','2004-02-01 '),(13,'13','张三丰','男',88,'123656789012345678','江苏','2020-11-01 '),(14,'14','灭绝','女',65,'123456719012345670','西安',' 2019-05-01'),(15,'15','胡青牛','男',70,'12345674971234567X','西安','2018-04-01'),(16,'16','周芷若','女',18, null,'北京','2012-06-01');
select name,workno,age from emp;-- as关键字,distinct去重
select distinct workaddress as '工作地址' from emp;-- where查询
select * from emp where age=88;select * from emp where emp.idcard is null;
select * from emp where emp.idcard is not null;select * from emp where age>=15 and age<=30;
select * from emp where age between 15 and 20;select * from emp where age=18 or age=20 or age=40;
select * from emp where age in(18 ,20 , 40);-- 查询符合字符的数据
select * from emp where name like '__';-- 身份证号最后一位是X
select * from emp where emp.idcard like '%X';-- 聚合函数
-- 有多少个字段
-- null不参与聚合函数计算
select count(*) from emp;
select count(idcard) from emp;-- 平均年龄-- 最小年龄
select min(age) from emp;
-- 最大年龄
select max(age) from emp;-- 西安地区年龄之和
select sum(age) from emp where workaddress='西安';-- group by
-- 分组之前查询用where,之后用having
-- 分组男女
select gender , count(*) from emp group by gender;select gender , avg(age) from emp group by gender;-- 3.查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress, count(*) arr from emp where age<45 group by workaddress having arr>=3;-- 排序
-- 升
select * from emp order by age asc ;
select * from emp order by age;-- 降
select * from emp order by age desc ;-- 根据入职时间降序排序
select * from emp order by date desc ;-- 3.根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序
select * from emp order by age , date desc ;-- 分页查询
select * from emp limit 10,10;select gender,count(*) from emp where age<60 group by gender;-- 查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序。
select name,age from emp where age<35 order by age ,date desc ;-- 5.查询性别为男,且年龄在20-40 岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序。
select * from emp where gender='男' and age>20 and age<=40 order by age ,date limit 5;