导读
在智源社区举办的「青源Workshop第27期:AI Agents 闭门研讨会」上,来自英伟达的高级应用科学家王智琳、CAMEL一作李国豪、AutoAgents一作陈光耀,以及相关技术专家们共同参与交流讨论,分享了最新的研究成果,共同探索了AI智能体的未来发展方向和应用前景。
所谓AI智能体(AI Agents),是一种能够感知环境、进行决策和执行动作的智能实体。它们拥有自主性和自适应性,可以依靠AI赋予的能力完成特定任务,并在此过程中不断对自我进行完善和改进。今年以来,AI Agents概念持续高涨,其研究本质究竟是什么?为什么大模型之后,还需要有AI智能体?AI智能体未来可以辅助人类实现哪些任务?以下是本期Workshop精华观点集锦。
AutoAgents——自动化智能体生成框架

/ 陈光耀 /
北京大学博士
2023年于北京大学取得博士学位,主要研究方向为开放世界学习、多智能合作学习与模型压缩,已在TPAMI、NeurIPS、ICCV等国际顶级期刊会议共发表论文十余篇,作为主要技术骨干参与编制多项人工智能模型表示与压缩技术的国际国家标准。曾获北京大学优秀博士学位论文奖、IEEE标准突出贡献奖和石青云院士优秀论文奖等。他长期担任TPAMI/IJCV/NeurlPS/ICLR/CVPR/ICCV/AAAI 等多个学术会议或期刊的 PCMember/Reviewer。

大语言模型带来的挑战
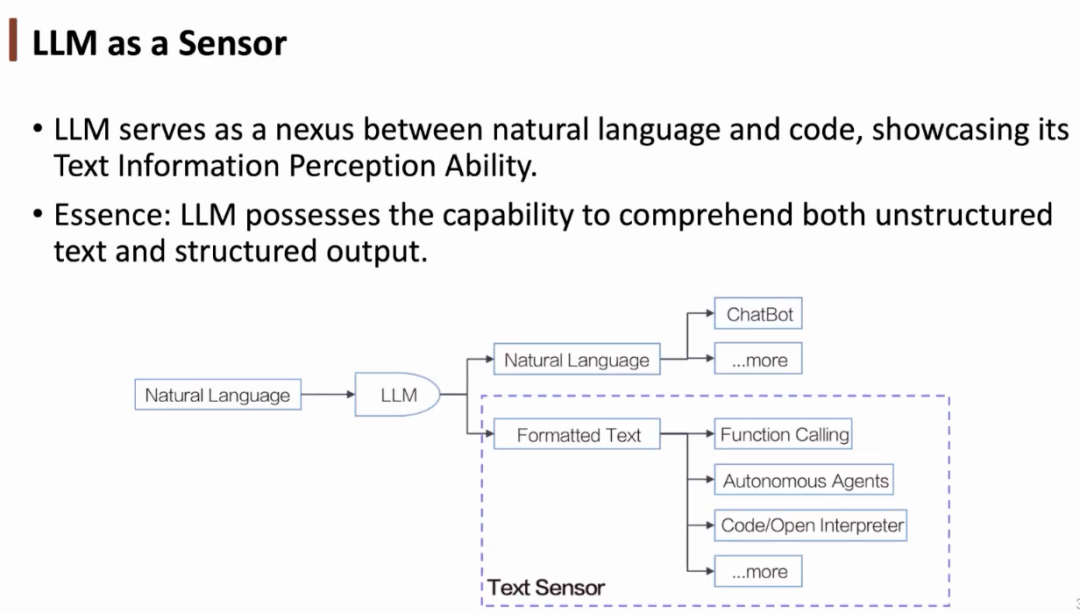
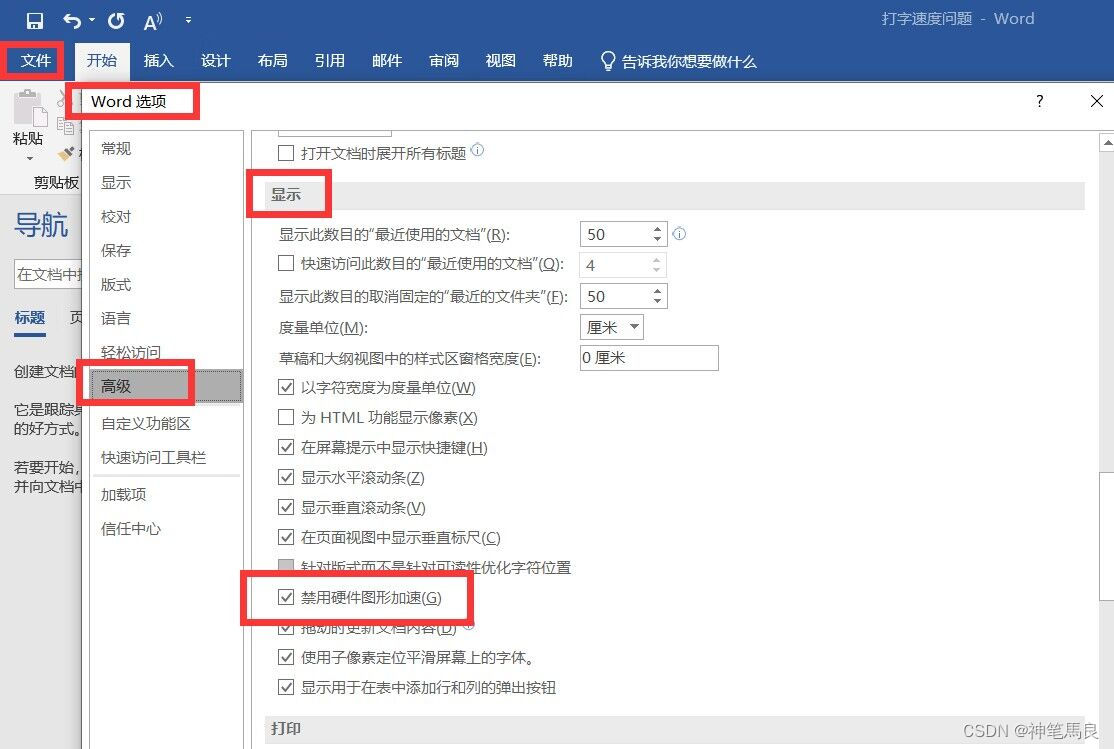
我们可以将大语言模型(LLM)视为一种感知器,它是自然语言和代码之间的纽带,具有对文本信息的感知能力,可以感知到代码、函数的功能。从本质上说,LLM 具有理解非结构化文本并给出结构化输出的能力。
我们还可以将 LLM 视做一种编程框架。在 ChatGPT 诞生初期,许多人调用其 API 开发一些插件。后来,一些从业者基于 LLM 开发自动化的智能体。如今,人们将 LLM 用作代码解释器,提升了与环境的交互效率。
函数调用
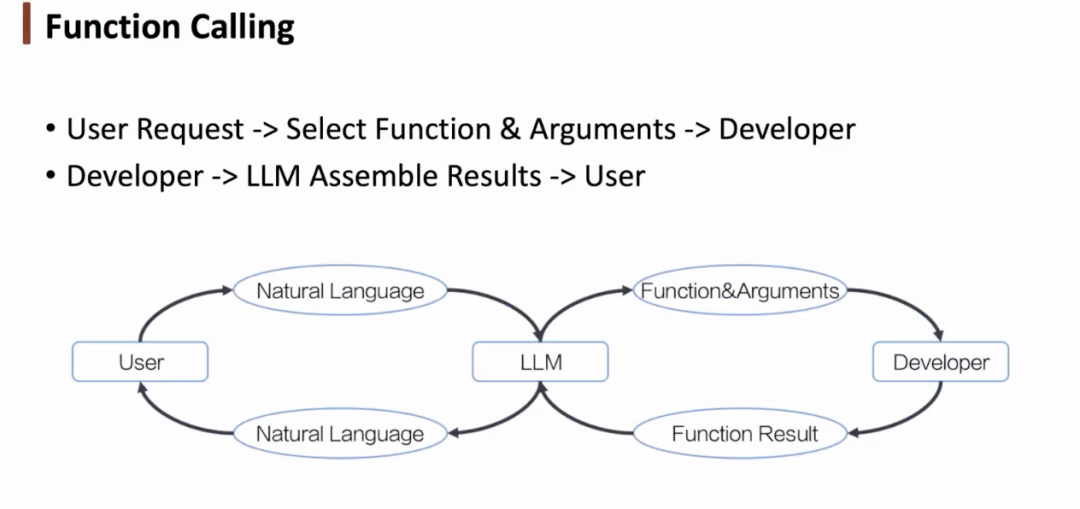
就函数调用而言,针对用户需求,我们可以通过大语言模型选择函数及其参数,将其提供给开发者执行。得到反馈后,我们可以通过大语言模型将函数结果转化为自然语言,从而与用户进行交互。大语言模型相当于与环境交互的桥梁。
自动化智能体
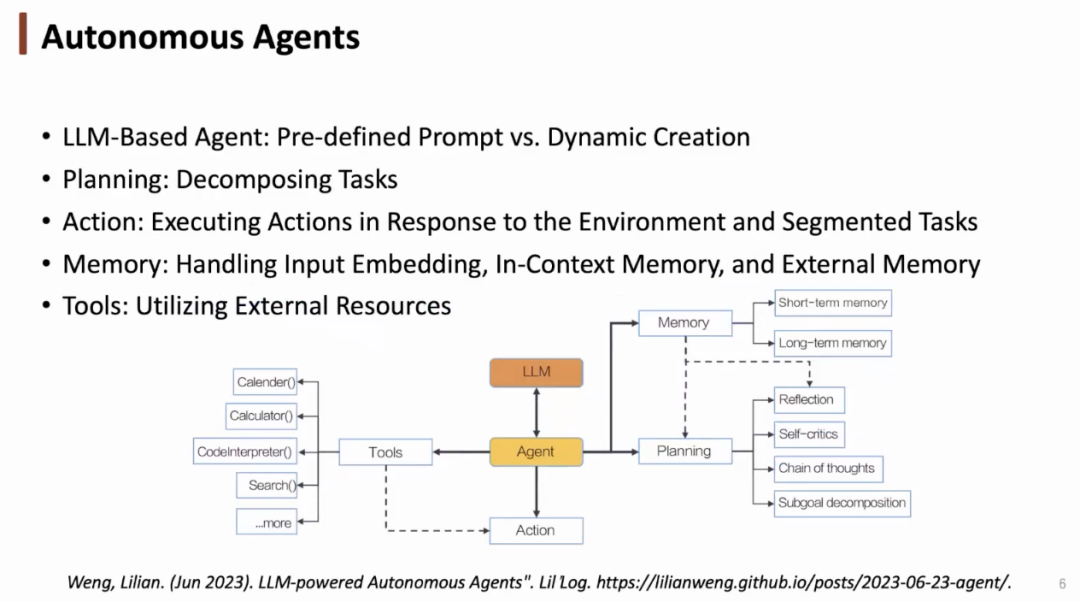
在应用 LLM 之前,智能体也具备规划、行动、记忆、应用工具等功能。在应用 LLM 之后,我们可以通过预定义的提示帮助智能体更好地工作,我们与智能体之间交互的方式产生了改变(从强化学习到大语言模型)。
代码解释器
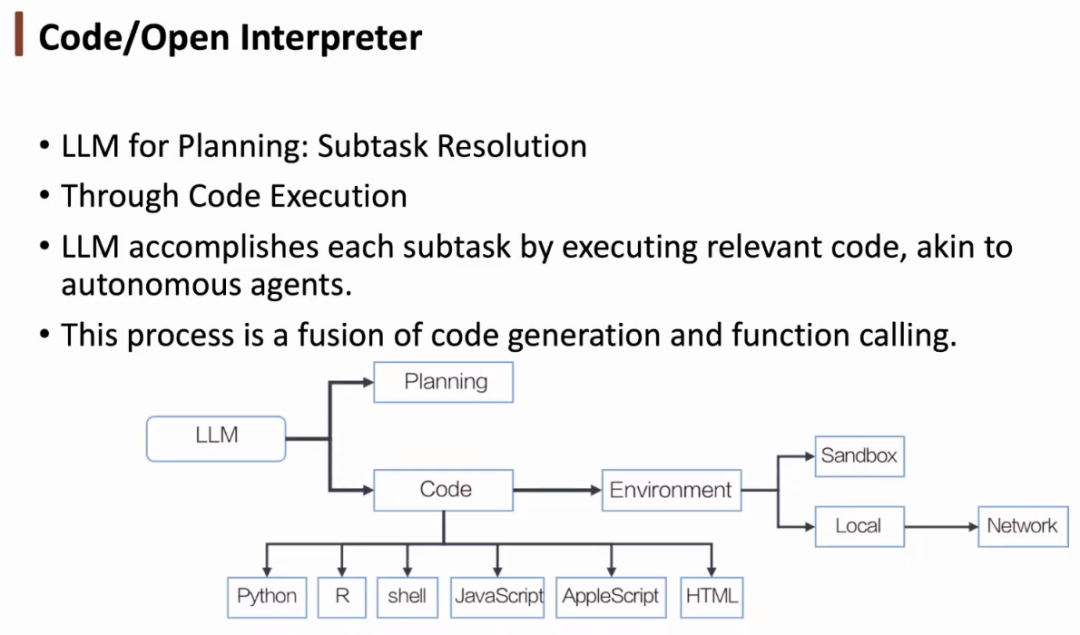
代码解释器也可以被视为一种智能体,与其交互的语言是代码。相较于自然语言,代码的语义更加清晰,执行效率更高,更加精确。但同时,代码的权限更高,可能会带来一些安全性问题。
智能体的发展历史

早在 2002 年,人们就在科技教材中对智能体进行了简单的定义:智能——能够自动完成一些任务;智能体——能代替用户独立行动的计算机系统(完成规划、行动等动作)。多智能体系统涉及到多个智能体间的交互、协作、协商。互联网智能体能够像人类一样,自动从网上获取信息,并整合、提炼出关键信息。

2009 年,研究者对智能体的定义进行了进一步细化。单个智能体需要与环境进行交互,针对环境中的输入给出反馈,并通过不断的交流独立自主完成交互。智能体还需要具有预判能力,并以此引导其行为,做出响应。多智能体系统下的智能体具有社交能力,它们通过某种智能体通信「语言」交流。
早年间,基于规则的智能体效率较低;接着,基于强化学习的模型犹如一个「黑盒」,AlphaGo 等系统在围棋、游戏领域击败了人类顶尖选手,得到了较大的发展;现有的基于大语言模型的智能体依赖于自然语言,可以提升交流效率。相较于强化学习的智能体,我们无需定义细致的奖励函数,智能体可以直接通过自然语言与环境交互,它具备规划、记忆、函数调用、代码生成、结果集成、反思等能力。
基于 LLM 的智能体可以大致被分为 3 类:单智能体(例如,AutoGPT、BabyAGI),通过不断调用工具与环境交互,得到输出后进行反馈;多智能体(例如,CAMEL、AgentGen、MetaGPT),通过 prompt 为智能体提供角色提示,使其能各司其职,更好与环境交流。然而,人类需要手动定义每个智能体,具有很强的不确定性;智能体生成(例如,AgentVerse,SPP,AutoAgents),不再需要预定义智能体,系统可以自动生成智能体。
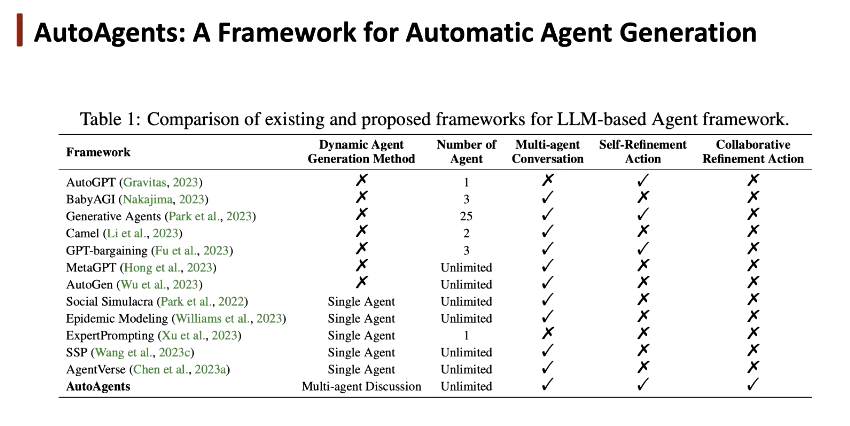
AutoAgents:自动化智能体生成框架
在 AutoAgents 系统中,为提高生成智能体的质量,我们定义了多种智能体之间的讨论,为每个任务确定需要的智能体。此外,在多智能体系统中,我们更加细致地考虑了智能体执行单个任务的能力,定义了自我细化、合作细化的过程。
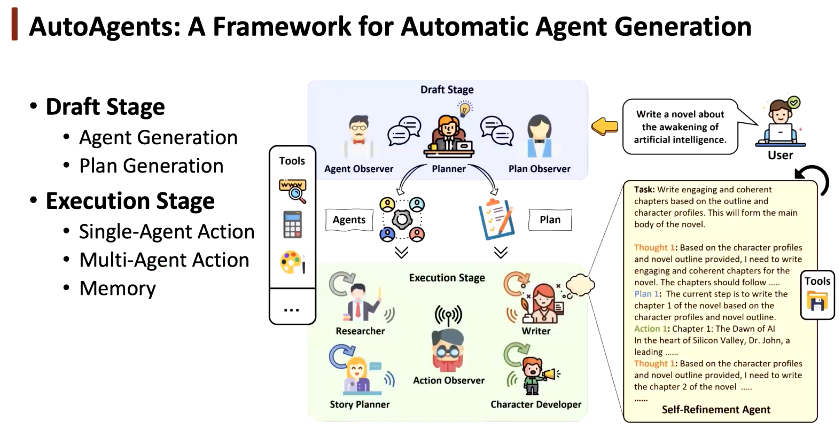
AutoAgents 包含两个部分:(1)起草阶段:智能体生成、计划生成(2)执行阶段:单智能体执行、多智能体合作执行、通过记忆实现智能体之间的信息共享。
起草阶段:智能体生成
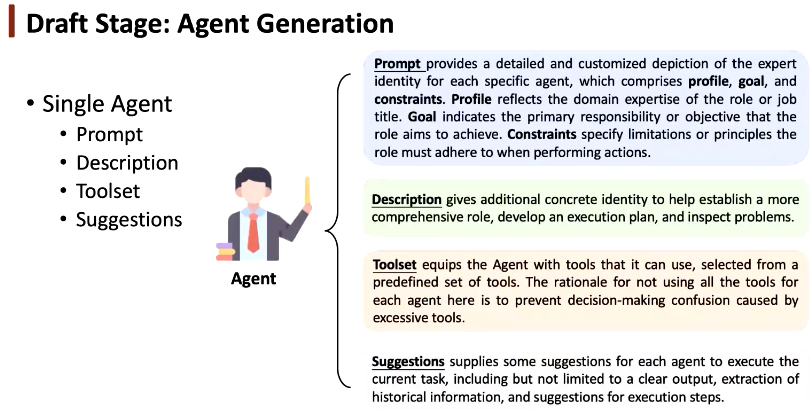
我们首先定义单智能体具有的 4 种属性:(1)提示。定义每个智能体扮演的角色,明确其执行目标,添加角色必须遵守的限制和原则(2)描述。方便系统在运行时快速了解单智能体的功能(3)工具集。使智能体挑选出最适合当前任务的工具。(4)建议。规范化,使智能体更关注某些方面,提升效率。
起草阶段:执行计划生成
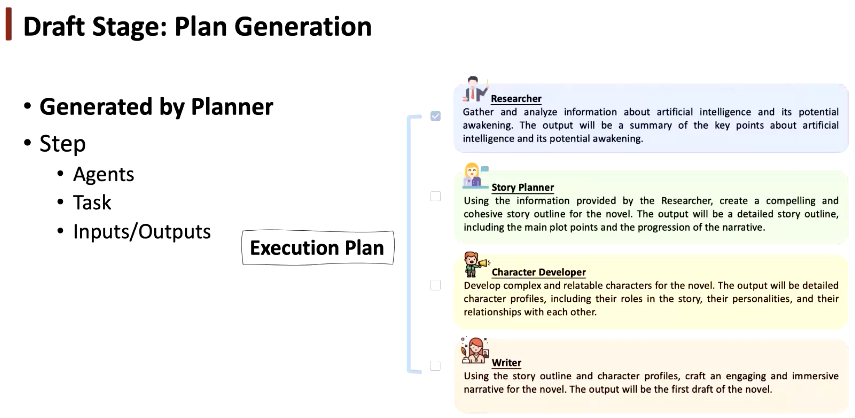
执行计划生成指的是将任务分解成多步,让智能体通过讨论动态确定计划,单个智能体或多个合作完成任务。我们需要明确每个智能体的输入和输出。
在多智能体讨论阶段,我们人工预定义了三种智能体:(1)规划者。起草智能体列表和计划(2)智能体观察者。评估每个智能体的质量和适配性(3)计划观察者。根据智能体列表和任务内容验证执行计划。
执行阶段:多智能体通信
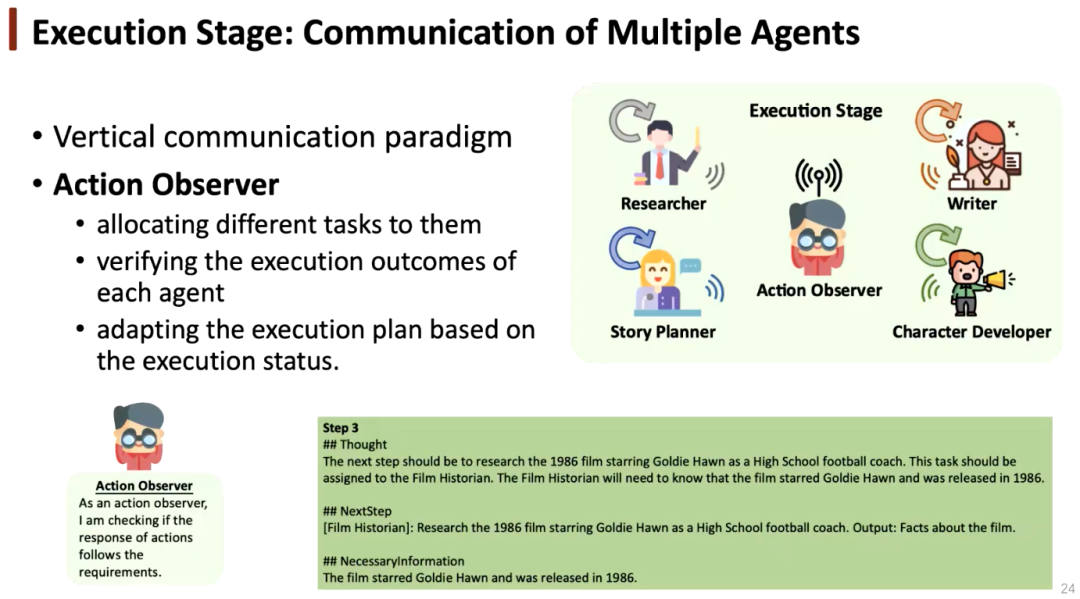
多智能体系统相当于一个包含不同专家的团队,执行阶段的垂直通信需要一个经理管理该团队。为此,我们设置了行动观察者,它可以为不同智能体分配不同的任务;检查每个智能体执行的输出;根据执行状态适配执行计划,根据执行结果为智能体提供更好的建议。
执行阶段:自我细化&合作细化
针对单智能体场景,采用自我细化方法使智能体逐步执行任务。针对多智能体场景,首先确定了智能体之间的合作关系,通过不同智能体之间的交流,整合它们的知识和能力,更好地完成交叉领域的任务。在智能体执行任务时,需要生成提示,并不断自我细化。为此,我们设计了「Meta Agent」机制,确定了单个智能体提示中动态变化的过程,提取了共性的部分。
在执行阶段,我们采用了三种记忆机制:(1)长时记忆。记录每个智能体执行的结果(2)短时记忆。记录单个智能体自我细化的中间结果。(3)动态记忆。包含对单个智能体重要的信息,无需从长时记忆中获取。
对未来智能体的展望
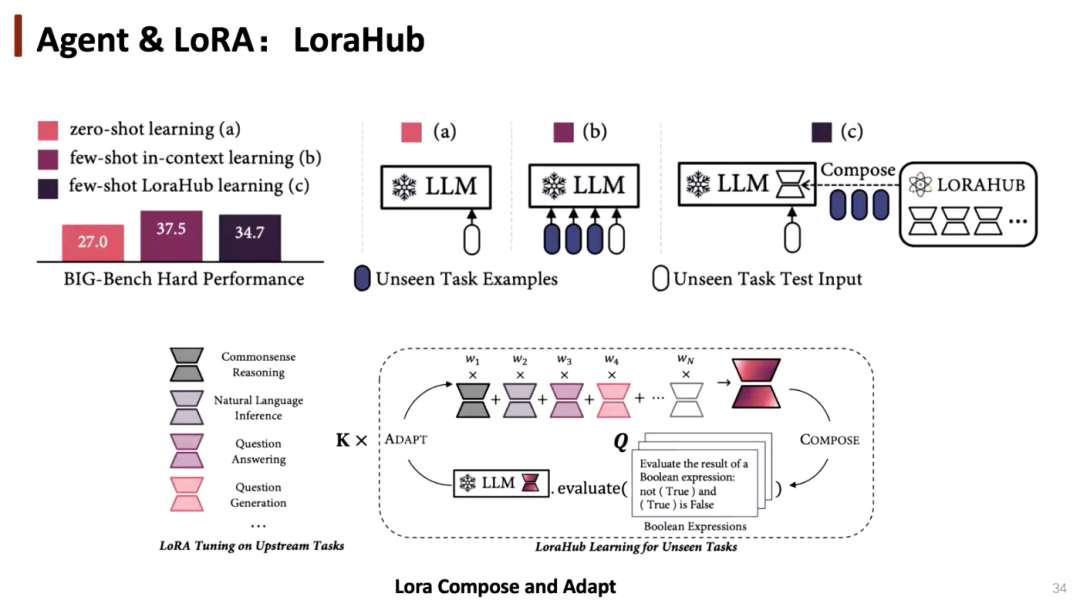
目前的多智能体系统研究更多尝试对提示进行改变,对模型本身的调整较少。未来,我们能可以探究如何对模型进行微调,例如通过LoraHub 的方式,为每个模型添加一组小参数,提升模型在某些任务上的能力。
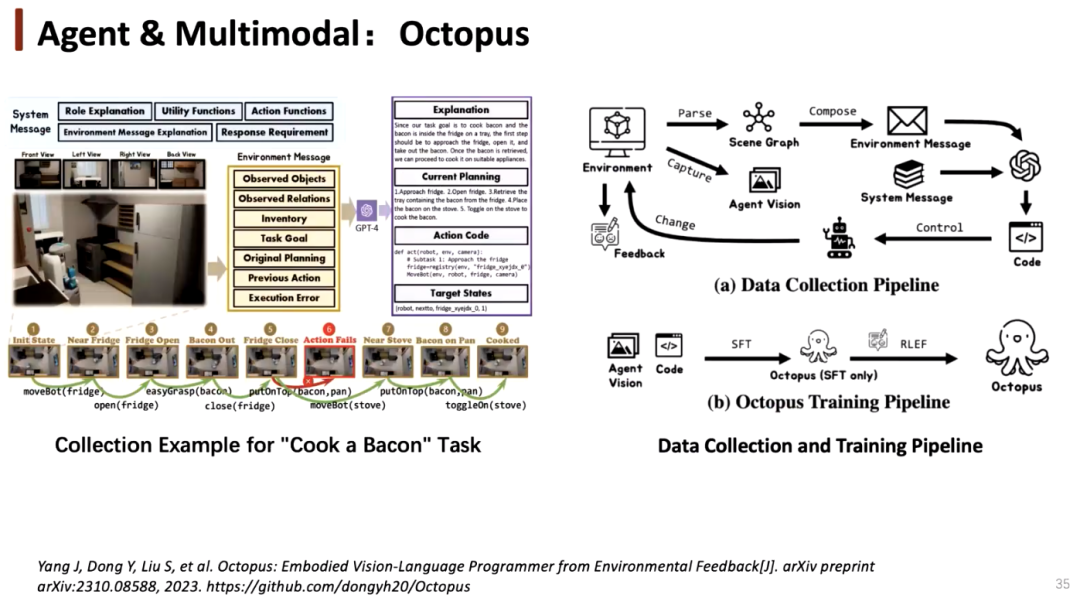
在数据收集方面,我们可以先从环境中收集任务相关的数据,利用它们对模型进行微调,并将其作为智能体执行,进而在环境中进行交互和反馈。我们可以通过强化学习等方式不断提升模型,让模型自我成长。
Humanoid Agents——模拟类人生成式智能体的平台

/ 王智琳 /
英伟达科学家、Humanoid agents作者
NVIDIA NeMo NLP团队的高级应用科学家。他致力于通过使LLM可控、安全和可访问,使其对每个人都有用。他曾就读于华盛顿大学研究生院,研究自然语言处理,研究对话系统和计算社会科学。他关注技术的最新发展,尤其是语言技术的交叉点,以及语言技术如何为改善人类生活做出贡献。

研究动机
 本工作旨在构建能够逼真模拟人类的智能体,其动机主要有两点:(1)理解——人类的各种行为如何形成,影响人类的各种因素如何相互作用,基于对人类的理解预测人类行为(2)应用——将智能体作为研究人类行为的工具,进行各种心理学和社会学实验,进行更加逼真的仿真模拟。
本工作旨在构建能够逼真模拟人类的智能体,其动机主要有两点:(1)理解——人类的各种行为如何形成,影响人类的各种因素如何相互作用,基于对人类的理解预测人类行为(2)应用——将智能体作为研究人类行为的工具,进行各种心理学和社会学实验,进行更加逼真的仿真模拟。
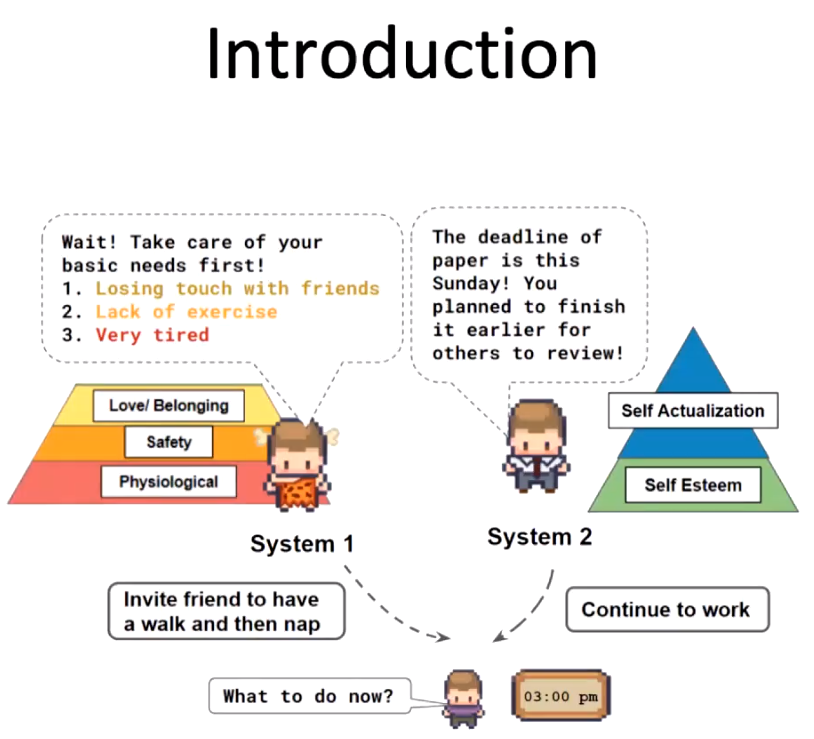
我们从两个理论出发探索影响人类行为的各种因素:(1)丹尼尔·卡尔曼在《思考,快与慢》中提出的 system 1&system 2 的思维模式。人类情感、快速感知对应于 system 1,而深度思考则对应于 system 2,两个系统存在竞争关系(2)马斯洛需求层次理论。人类的需求分为五个层次:生理需求(Physiological needs)、安全需求(Safety needs)、爱和归属感(Love and belonging)、尊重(Esteem)和自我实现(Self-actualization)。人只有满足了较为底层的需求,才能追求更高级的需求。我们构建的智能体不仅是能够完成某些功能的「工具人」,更是对人类心理层面上更具体的模拟。
系统设计
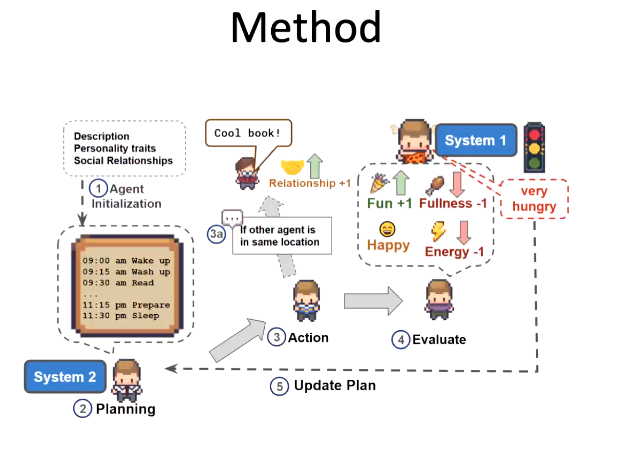
我们首先建立了一个智能体。该智能体包含描述、个人特质、社会关系。初始化后,我们会为智能体制定一天的计划。到了每个时间点,智能体做出行动,根据当时的心理状态,决定是否改变计划。每项行为也会反过来影响智能体的状态,实现动态平衡。
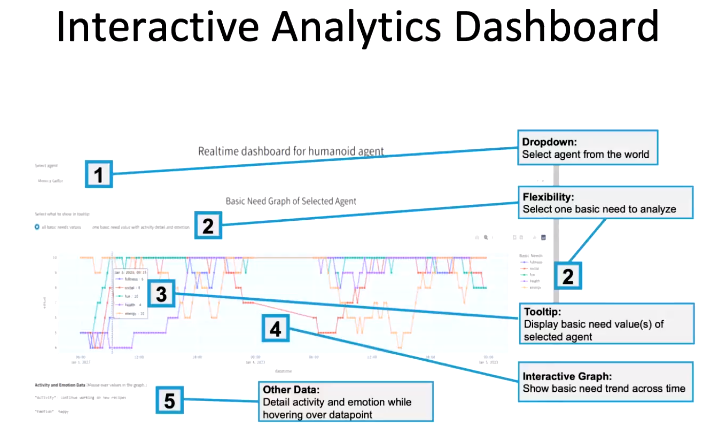
我们推出了一个交互式的可视化分析界面。用户可以看到智能体包含的成分、执行行为后状态的变化。
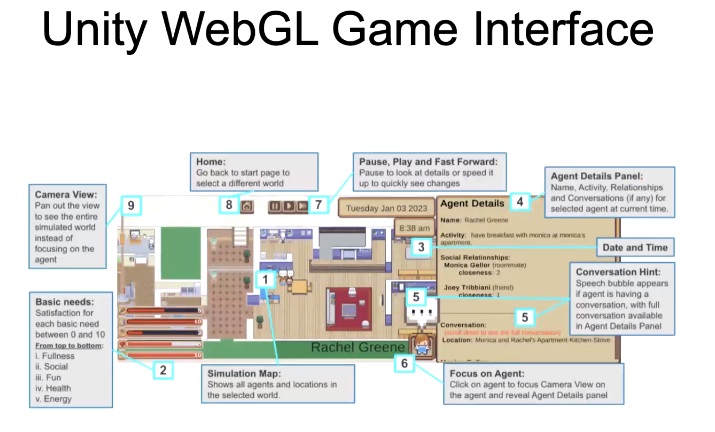
我们基于 Unity WebGL 游戏引擎构建了一个游戏界面,用户可以直观看到智能体的需求、行为、状态变化。
实验结果
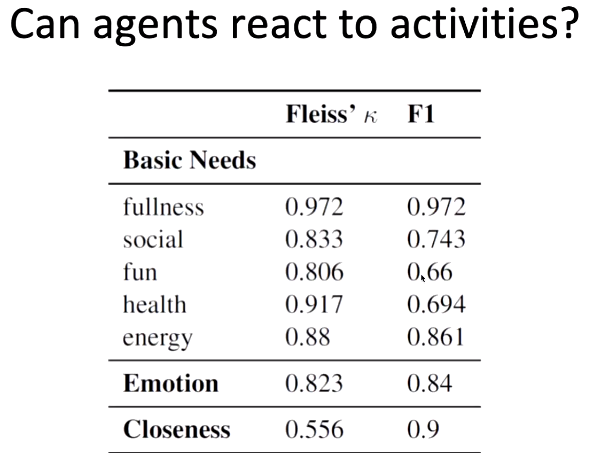
我们设置了一组实验,测试智能体是否会根据一些行为更新自己的基本状态。如上图中的 Fleiss Kappa 指数和 F1 得分所示,在吃饭、社交、休息等行为过后,可以很好地观测到状态的变化,而衡量一件事情是否有趣,做某事是否健康则很难,这是因为每个人对「有趣」、「健康」的定义差距较大。此外,该系统对人类情感的分析能力也较强。
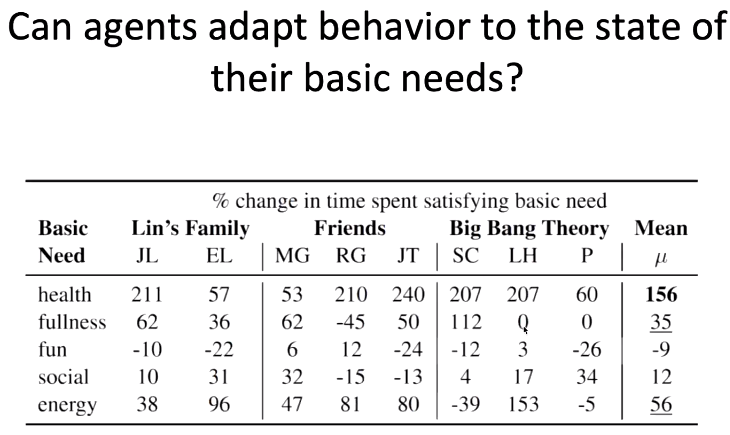
在第二个实验中,我们探究了智能体是否会根据其关于基本需求的状态调整自己的行为。实验结果表明,当智能体健康状态很差时,它会花费很多时间寻找医疗资源。同样,当智能体感到饥饿、困乏时,都会相应对行为做出很大的调整。但是,当智能体感到无聊、寂寞时,改变自己行为的概率较小。上述实验结果反过来印证了马斯洛的需求理论。
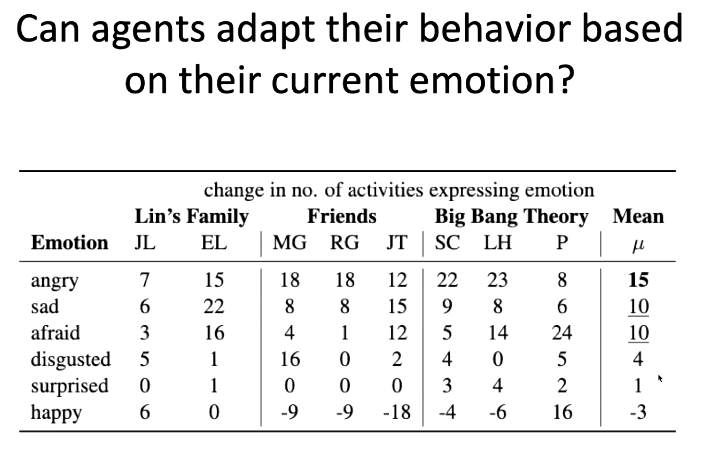
在第三个实验中,我们探究了智能体是否会根据当前的情绪状态调整其行为。我们发现,当智能体生气时,平均会做出 15 项行为调节自己的情绪;当智能体感到伤心或害怕时,平均会做出 10 项行为调节情绪。值得一提的是,当智能体已经处于快乐的情绪下,智能体不会偏向于尝试让自己马上感到快乐的事。此时,智能体也许更可能做一些能够获得长期收益的事。
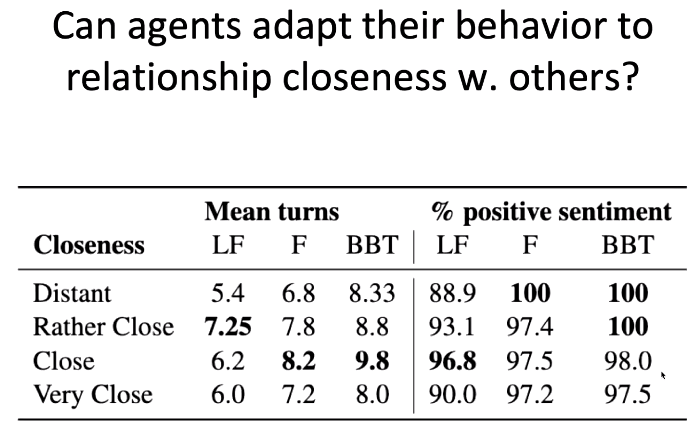
在第四个实验中,我们探究两个智能体之间亲近关系对其调整对话行为的影响。实验结果表明,当智能体关系较为接近,或接近时,他们的对话最多。而当他们非常熟络时,反而没有这么多对话。在现实生活中,我们也可能不需要用过多的对话维系与亲朋好友之间的关系。当智能体之间关系疏远时,他们的对话基本都是正面积极的,希望给对方留下积极地印象。
在上述实验中,我们从基本需求、情感、智能体关系这三个方面开展了研究。接下来,我们考虑探究智能体的类人思考,考虑人与人之间的同理心、不同的价值体系、文化背景。目前,该系统只支持 ChatGPT 3.5,我们会逐渐支持更多的大模型,并训练自己的模型。目前的 LLM 大多旨在为人类提供帮助。此外,我们希望基于生成式人工智能在游戏界面中提供更加个性化的选项。
未来的研究方向
对于整个智能体研究领域来说,这是一个很宝贵的了解人类自身的机会。我们可以从第三视角,更好地模拟人类,也许可以做出相较于传统心理学方法更好的工作,得到一些更好的发现结果。这种方式可以与传统心理学方法互补,考虑更多的因素。我们还可以利用对类人智能体系统的理解,改善人与人之间的关系,实现人类社会的幸福。最后,我们还可以像「西部世界」中一样,实现高度逼真的仿真模拟。
利用智能体构建 AI 社会

/ 李国豪 /
阿卜杜拉国王科技大学(KAUST)计算机科学博士
人工智能研究员、开源贡献者,致力于构建能够感知、学习、交流、推理和行动的智能主体。他是开源项目CAMEL-AI.org和DeepGCNs.org的核心负责人,也是PyG.org的核心成员。他在阿卜杜拉国王科技大学获得计算机科学博士学位,导师为Bernard Ghanem教授。在攻读博士期间,他曾在英特尔ISL担任研究实习生。他作为访问研究员访问了ETHz CVL,并曾在Kumo AI工作。主要研究方向包括自主代理、图形机器学习、计算机视觉和嵌入式人工智能。他在ICCV、CVPR、ICML、NeurIPS、RSS、3DV和TPAMI等顶级会议和期刊上发表了相关论文。

1986:马文·明斯基的智能体

人工智能先驱马文·明斯基早在 38 年前就提出了智能体(Agent)一词,介绍了智能体的交互、通信、特性、具身智能等概念。他在《心智社会》一书中指出,每个智能体本身只能做一些简单的事情,但是如果智能体形成一个社会,就会产生真正的智能,这就是这本书的哲学思想。在本书中,明斯基有一句经典的名言「The trick is that there is no trick」,并没有单一、完美的准则,人类的智慧来自于人类社会的多样性。受此书的启发,我们有了做 CAMEL 项目的想法。
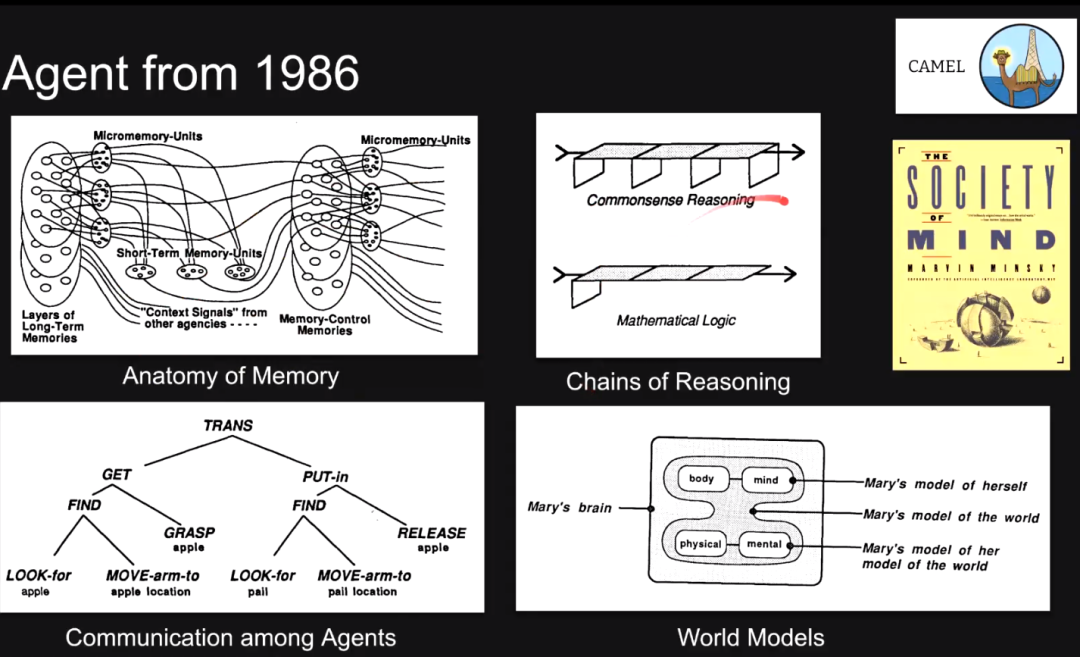
最初的智能体主要是符号智能体,此书还提到了记忆的构成、推理链、智能体之间的交互、世界模型等概念,也介绍了人工智能与心理学、认知科学等学科的联系。然而,马文·明斯基的著作《perception》导致神经网络研究遭遇第一次寒冬,诸多由他提出的概念并不被神经网络研究者推崇。
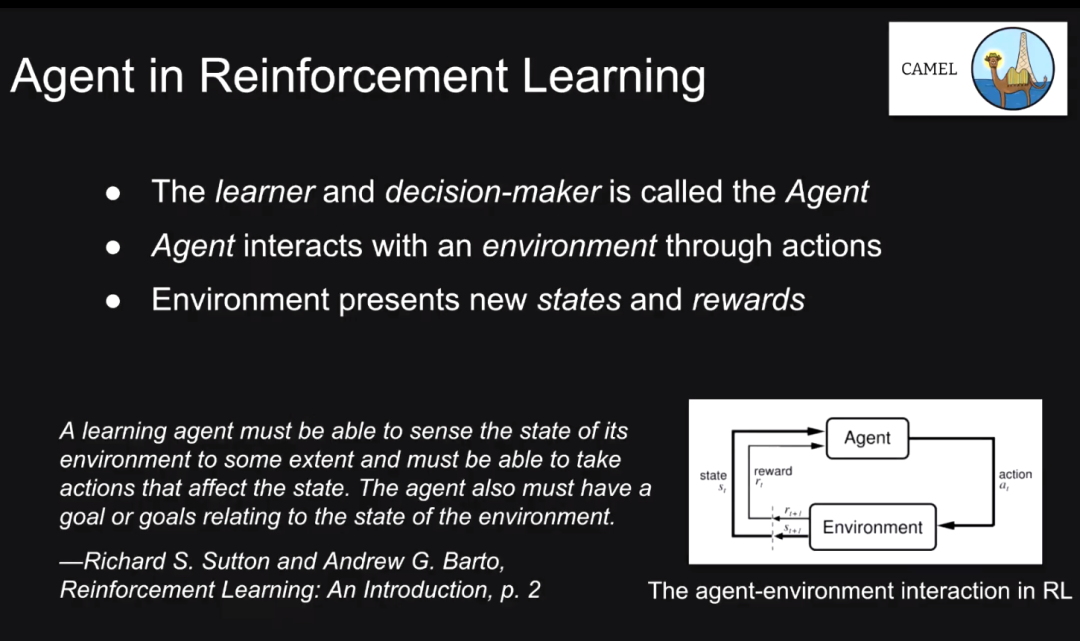
在强化学习背景下,我们将智能体定义为学习器和决策制定器,它们在环境中执行动作,并受到环境的奖励,改变其状态,我们可以不断更新智能体的策略。此类智能体在围棋、Atari 游戏等场景下被广泛应用。然而,它们的泛化能力往往较弱。

第一个将大语言模型作为智能体的工作是 WebGPT,作者试图在 LLM 上添加一个搜索引擎,从而提升搜索的效果。基于 LLM 的智能体有很强的泛化能力,它们具备一些关于世界的知识,能理解输入,并给出高维空间中的输出。ChatGPT 惊艳的效果让智能体研究者们眼前一亮。在李国豪看来,模型能力的放缩法则已经是过去式,智能体能力的涌现是未来。

实际上,CAMEL 是第一个基于 LLM 的对话式智能体。起初,作者团队希望构建一个智能体引导 ChatGPT 完成任务:一个智能体给定高级指令,另一个机器人与 ChatGPT 进行多轮对话。这种对话式的智能体可以扮演不同的角色,完成不同的任务。为此,我们提出了「Inception Prompting」方法来引导对话智能体完成任务,智能体之间通过「指令跟随」(Instrucion-following)的方式合作。这种合作方式可控性很强,也可以产生新的数据集。
CAMEL 框架
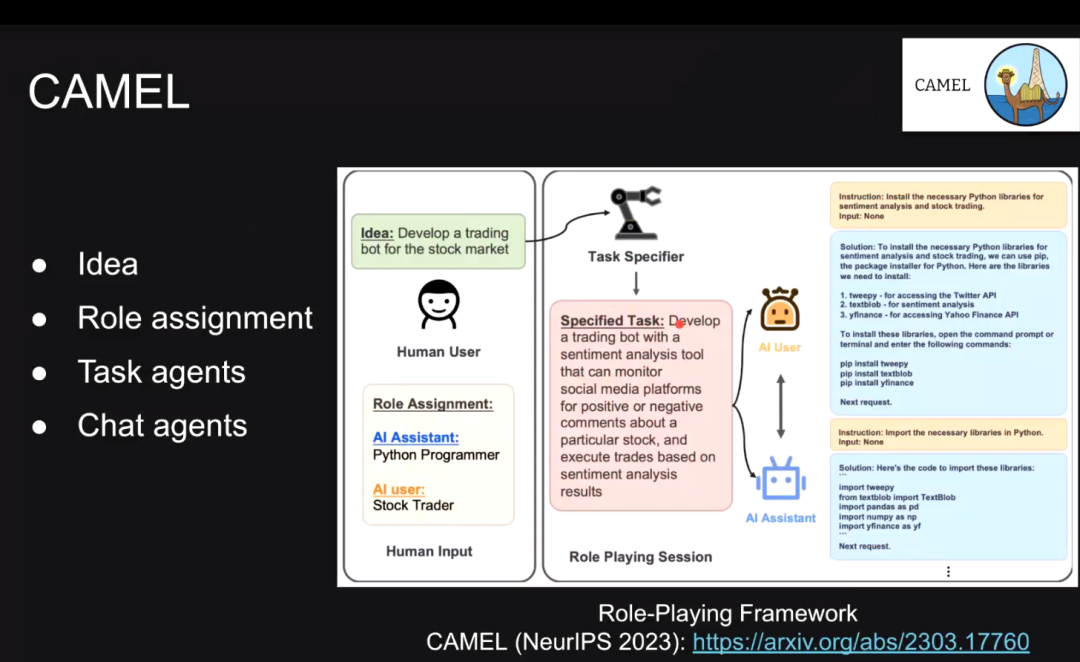
在 CAMEL 框架下,用户给出自己的意图,有一个智能体会将这个意图具体化为可执行的方案。然后我们选择两个智能体完成机制的设计。例如,在股票交易场景下,一个智能体为 Python 编程者,另一个为股票交易员。任务制定者将交易任务指定为监控社交平台上关于某只股票的舆情,并以此为依据执行交易操作。此时,AI 用户代替人类进行规划,AI 助手则帮助 AI 用户执行动作。
类似地,我们模拟了 50 多种 AI 助手的角色、10 种任务,尝试使用 20种编程语言完成 50 个领域的 50 种任务。

我们发现,在 70% 的情况下,人类评估和 GPT-4 评估的结果指明,使用 2 个智能体的效果比使用单个智能体效果更好,这与 CoT 的形式类似。
通过「Instruction following」方式,我们可以产生大量用于指令微调的数据。我们针对 LLaMa 等模型进行了微调。例如,加入关于数学的指令数据后,LLaMa 模型在数学问题上的性能有巨大提升。
在 CAMEL 项目中,我们提出了在完全自动化的系统中进行「Actor-Critic」。我们引入了一个批评智能体,设定一些标准,让他选择是否修改当前选择,由此形成了一个类似树的搜索方式。同时 CAMEL 项目也设计具身/工具智能体,这种智能体可以写代码、生成图片。
Q&A
Q1:如何在为通用领域的语言模型赋予角色时,使其成为专业领域的专家?在赋予智能体角色时,其能力都来自同一个预训练大模型。为其赋予不同角色,使其成为特殊领域的专家,与使用一个通才模型有何区别?
李国豪:显式告知自然语言模型扮演某种角色会影响其输出。我们可以加入一些知识、记忆,也可以为智能体赋予不同的工具,成为不同领域的专家。实际上,我们往往很难直接训练出一个通才智能体。我们可以采用「分而治之」的思想,将问题分解为多个子问题,在降低问题复杂度的同时,让任务并行完成,这比训练一个通才模型更加容易。
我们通过不同的提示可以得到不同的结果。通过模型形成不同的专家,会比通才模型在某些领域得到的回答更好。实际应用场景和实验场景下使用的模型也可以是完全不同的。
陈光耀:我们可以将大语言模型视为一个通才,但是我们在多智能体系统中通过 Prompt 的方式更好地挖掘领域知识,提升回答的指令。使用不同的模型可能会降低模型的微调效率,还需要进一步探索。
Q2:目前大多数智能体框架都基于 ChatGPT 开发而来,如果我们更换后端模型,会不会影响框架的性能?Prompt 会不会失效?
王智琳 :由于每种模型的训练过程不太一样,更换后端模型确实会对 Prompt 的效果产生有一定影响。短期来讲,没有特别好的解决办法,我们可以针对特定任务进行单元测试,或者可以使用非常强的大语言模型(例如 GPT-4)测试更换模型后的效果。长远来看,我们可以通过基于 Lora、RLHF 等方式训练定制化的模型,对模型进行控制。
Q3:多智能体框架包含规划者和多个执行者,规划是否决定了基于 Prompt 的智能体的能力上限?如果规划能力较弱,是否可以通过人机协作使任务执行更加高效?
陈光耀:规划确实是很重要的一环,但是单个智能体的执行能力、工具的执行效率也都很重要。人机合作是一种很好的机制,但是大多数多智能体系统都是一种工具。我们可以通过智能体辅助人,也可以让人辅助智能体。
李国豪:规划很重要,其它能力也同等重要。我们要考虑如何扩展智能体个数、实用工具的数量、记忆的维度等因素的组合。目前,我们还做不到完全自动化的系统,任务中一些模糊不清的部分还需要人类与机器合作。这种人机合作的方式也包含人被动、人主动两种模型,会产生不同的系统设计。
Q4:大模型似乎不太会主动向人类提问,如何让智能体主动向人类获取知识?
李国豪:可以通过 prompting 来解决该问题。我们可以在开始做任务之前,让智能体询问人类各种问题,直到他觉得答案已经明确为止。
Q5:除了设计模块、进行 Prompt 工程之外,该领域还有哪些有价值的研究方向?
李国豪:有很多可以做的地方。首先,可以研究 Agent 的哪些能力应该融合到模型里。有没有一种混合模型的设计?工具是不是可以作为神经网络的某一层?
Q6:目前似乎缺少一个评测智能体的 Benchmark,这方面的工作是否有意义?
李国豪:非常有意义。我们一开始在做 CAMEL 项目时,根本不知道怎么去评价它。现在,模型能力已经远远超过我们能够评估这些模型的方法。智能体的评测将会是未来非常重要的研究方向。
更多内容 尽在智源社区



![[全志Tina/Linux]全志在线生成bootlogo工具](https://img-blog.csdnimg.cn/direct/ad98b56c5c3b4dba9764017bcc5055f8.jpeg)