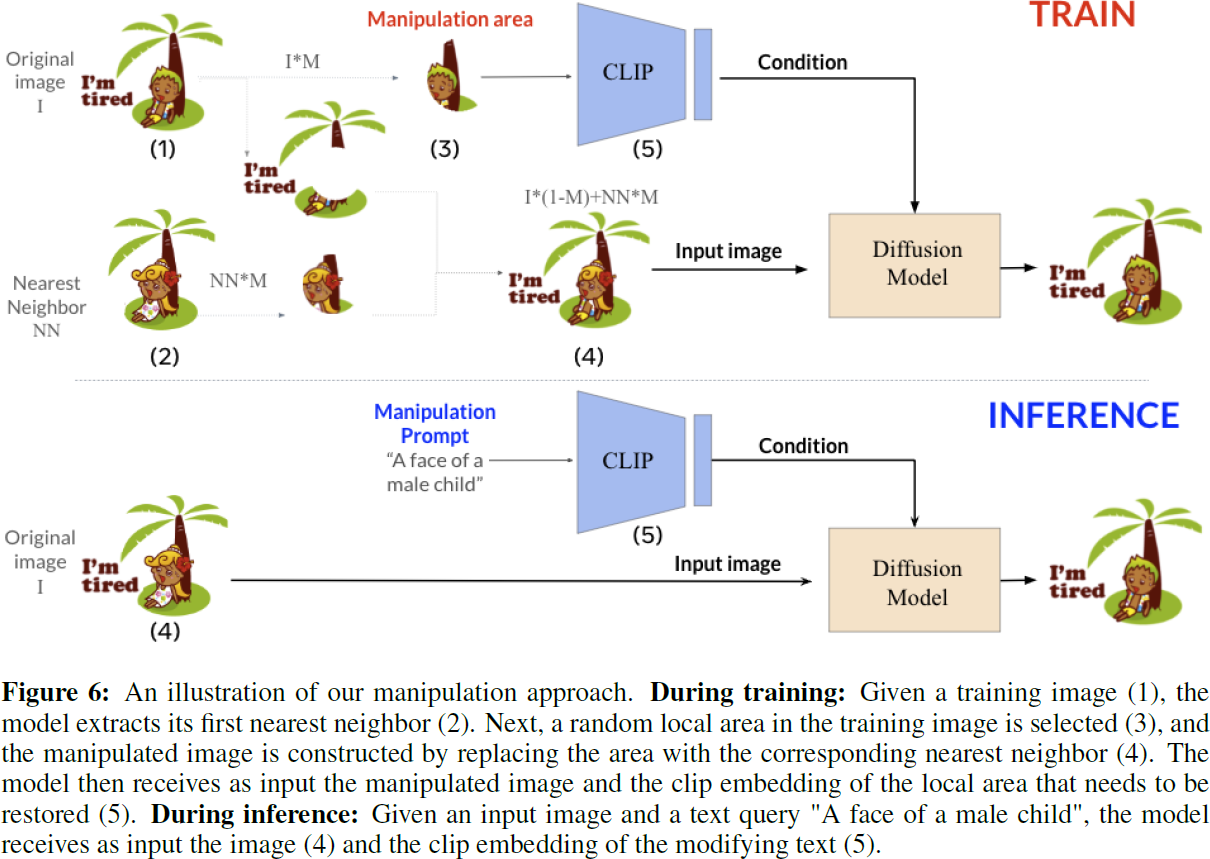
- 字符集
- 计算机的存储规则(英文字符)

- 常见字符集介绍
a.GB2312字符集:1980年发布,1981年5月1日实施的简体中文汉字编码国家标准。收录7445个图形字符,其中包括6763个简体汉字
b.BIG5字符集:台湾地区繁体中文标准字符集,共收录13053个中文字,1984年实施。
c.GBK字符集:2000年3月17日发布,收录21003个汉字。
包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。windows系统默认使用的就是GBK,系统显示:ANSI。
d.Unicode字符集:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
- 计算机的存储规则(GBK中文字符)

规则1:汉字两个字节存储
规则2:高位字节二进制一定以1开头,转成十进制之后是一个负数。
- 字符集小结
1.在计算机中,任意数据都是以二进制的形式来存储的
2.计算机中最小的存储单元是一个字节
3.ASCI字符集中,一个英文占一个字节
4.简体中文版Windows,默认使用GBK字符集
5.GBK字符集完全兼容ASCI字符集
一个英文占一个字节,二进制第一位是0
一个中文占两个字节,二进制高位字节的第一位是1
- Unicode字符集
Unicode:万国码
研发方:统一码联盟 (也叫Unicode组织)
总部位置:美国加州
研发时间:1990年
发布时间:1994年发布1.0版本,期间不断添加新的文字,最新的版本是2022年9月13日发布的15.0版本。
联盟组成:世界各地主要的电脑制造商、软件开发商、数据库开发商、政府部门、研究机构、国际机构、及个人组成
- UTF-16编码规则:用2~4个字节保存
Unicode Transfer Format
- UTF-32编码规则:固定使用四个字节保存
- UTF-8编码规则:用1~4个字节保存

在UTF-8编码下,英文使用1个字节保存,中文使用3个字节保存。
注意UTF-8并不是字符集,而是Unicode的一种编码方式。
Unicode字符集的UTF-8编码格式
一个英文占一个字节,二进制第一位是0,转成十进制是正数
一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数。
- Java中编码的方法
| String类中的方法 | 说明 |
| public byte[] getBytes() | 使用默认方式进行编码 |
| public byte[] getBytes(String charsetName) | 使用指定方式进行编码 |
- Java中解码的方法
| String类中的方法 | 说明 |
| String(byte[] bytes) | 使用默认方式进行解码 |
| String(byte[] bytes, String charsetName) | 使用指定方式进行解码 |
代码如下:
import java.io.UnsupportedEncodingException;
import java.util.Arrays;public class CharsetDemo1 {public static void main(String[] args) throws UnsupportedEncodingException {// 1.编码String str = "你好啊~";// 使用默认字符集编码byte[] bytesDefault = str.getBytes();System.out.println(Arrays.toString(bytesDefault));// [-28, -67, -96, -27, -91, -67, -27, -107, -118, 126]// 使用GBK字符集编码byte[] bytesGBK = str.getBytes("GBK");System.out.println(Arrays.toString(bytesGBK));// [-60, -29, -70, -61, -80, -95, 126]// 2.解码String str2 = new String(bytesDefault); // 使用默认编码方式解码System.out.println(str2); // 你好啊~String str3 = new String(bytesDefault, "GBK");System.out.println(str3); // 浣犲ソ鍟妦}
}