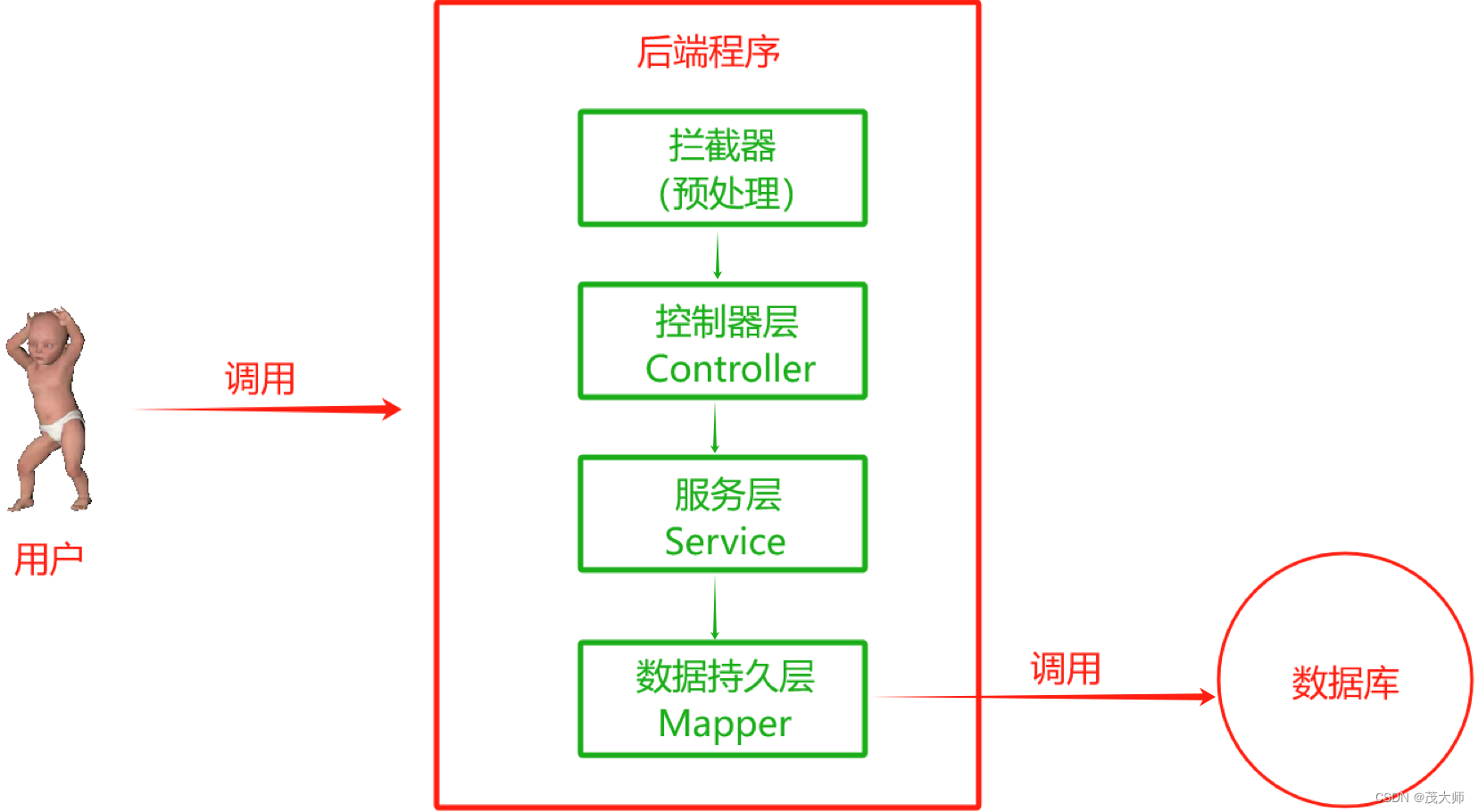
Python 网络爬虫入门:Spider man的第二课
- 写在最前面
- 观察目标网站
- 代码编写
- 第二课总结
写在最前面
有位粉丝希望学习网络爬虫的实战技巧,想尝试搭建自己的爬虫环境,从网上抓取数据。
前面有写一篇博客分享,但是内容感觉太浅显了
【一个超简单的爬虫demo】探索新浪网:使用 Python 爬虫获取动态网页数据
本期邀请了擅长爬虫的朋友@PoloWitty,来撰写这篇博客。通过他的专业视角和实战经验,一步步引导我们入门,成为一名数据探索的“Spider Man”。
【Python网络爬虫入门教程1】成为“Spider Man”的第一课:HTML、Request库、Beautiful Soup库
【Python网络爬虫入门教程2】成为“Spider Man”的第二课:观察目标网站、代码编写
随着互联网数据的指数级增长,了解如何有效地提取这些信息变得越来越重要。无论是文本模型如ChatGPT,还是视觉模型如Stable Diffusion,它们的训练数据大多来源于互联网的海量数据。在这个日新月异的大数据时代,爬虫也算是其中不得不点的一项基础技能树了。
本系列文章将深入浅出地介绍Python网络爬虫的基础知识和技术,从 Requests 库到 Scrapy 框架的 入门级 使用,为你开启python网络爬虫的大门,成为spider man的一员,并最终以ScrapeMe网站作为目标示例,爬取下网站上的可爱又有趣的宝可梦照片。
在开始之前,还要啰嗦几句叠个甲,网络爬虫虽然强大,但在使用时必须遵守法律法规和网站的爬虫协议。不违法爬取数据,遵守相关法律法规哦~

这是本系列的第二篇文章,将会以ScrapeMe网站作为示例,展示如何使用第一课中学到的基础知识来对网站上的宝可梦图片进行爬取。
观察目标网站
首先,我们需要先对我们需要爬取的目标网站及目标内容进行一番观察。
直接点进目标网站,我们可以看到如下内容:
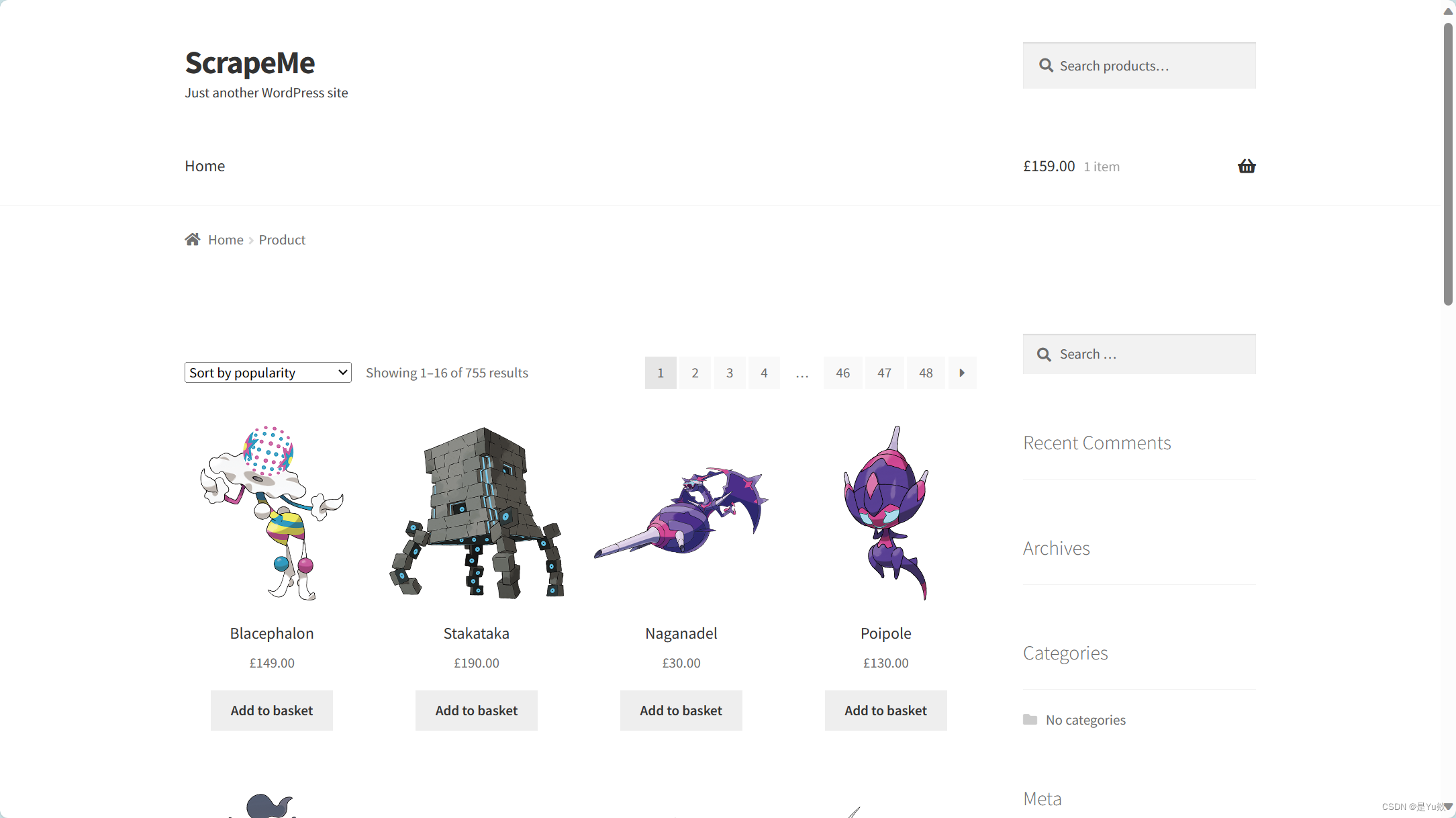
我们想要爬取的目标图像就处于中间位置。
再观察一下如何获取到不同page上的所有图片,点击不同page并观察对应的链接地址可以发现,通过在请求的地址链接中加入page参数,便可以访问不同的链接了。比如https://scrapeme.live/shop/page/2/?orderby=popularity,就是第二个page对应的链接地址,通过不断更换page后面的参数,便可以访问到不同的page了。
代码编写
通过上面的观察分析,我们的爬虫代码思路便很清晰了:
- 通过改变
url=f'https://scrapeme.live/shop/page/{pageNum}/?orderby=popularity'中的pageNum参数,获取到不同的page- 获取当前page下所有图片的链接
- 利用requests去请求相应的链接并保存至本地文件夹中
通过上面的伪代码,我们便可以写出相应的爬虫程序了:
import requests
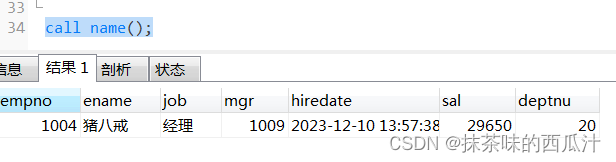
from bs4 import BeautifulSoupdef download_from_url(url:str):'''利用requests库,从相应的图片链接中下载对应的图片结果会保存到results文件夹中'''filename = url.split('/')[-1]with open(f'./results/{filename}','wb') as fp:fig_response = requests.get(url)fp.write(fig_response.content)if __name__=='__main__':for pageNum in range(1,49):url=f'https://scrapeme.live/shop/page/{pageNum}/?orderby=popularity'response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')# 找到所有的图片元素links = soup.find_all('img')for link in links:# 找到图片对应的链接fig_link = link.get('src')# 根据链接下载相应的图片download_from_url(fig_link)然后我们可以看看我们爬取下来的宝可梦图片:

怎么样,是不是又优雅又简单hhh,轻轻松松拿捏住了🤏
第二课总结
通过本节课程,你应该已经对如何使用requests库和Beautiful Soup库编写爬虫程序有了更加深入的认识。恭喜你,你已经能够应付大多数的爬虫场景了,已经基本入门了python 网络爬虫的世界φ(゜▽゜*)♪
接下来,本系列课程的第三课,将讲述本系列课程的提高内容:利用scrapy库以应对更多更复杂的爬虫场景。