目录
一、数组越界死循环
二、strcpy函数
三、memcpy函数
四、memmove函数
五、memcmp函数
六、memset函数
一、数组越界死循环
数组越界死循环问题(详细,通俗,易懂)_数组加i死循环-CSDN博客![]() https://blog.csdn.net/weixin_55420366/article/details/120394302
https://blog.csdn.net/weixin_55420366/article/details/120394302
//数组随着下标的增长,地址由低到高增长
//栈区的内存,先使用高地址,再开辟低地址
#include<stdio.h>
int main()
{int i = 0;/*数组中的下标从0开始,那么在上面代码中只能访问:a[1]、a[2]、a[3]、a[4]、a[5]、a[6]、a[7]、a[8]、a[9];当i自加到10时,a[10]属于数组下标越界。*/int arr[10] = { 1,2,3,4,5,6,7,8,9 };for (i = 0; i <= 12; i++){arr[i] = 0;printf("hehe\n");}printf("%d\n", i);//12return 0;
}
/*声明一个数组a[5],该数组中只能存放5个元素,下标索引值取值范围0~4,超过这个范围就属于下标越界;*/这个程序放到编译器中运行的话会造成死循环,那这时我们可能会想,数组的总元素是10,而循环语句中的i要循环到12才结束,那么肯定会出现数组越界报错啊,但为什么会出现死循环而不是数组越界,并且这个语句为什么会形成死循环呢?下面我来给大家解释。
首先我们得先从栈开始讲起(不知道什么是栈的小伙伴可以自己去搜),我们平时创建的局部变量就放在栈中,而栈的使用规则从高地址向低地址使用的。并且单个数组元素在栈中的地址相对大小和下标大小相同,也就是说变量i和数组在栈中的位置关系如下图所示。
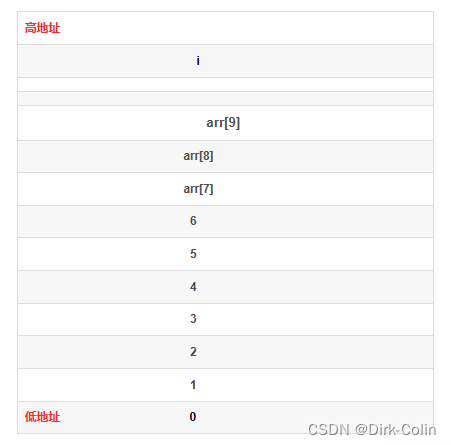
那么这就明了了,当数组越界后,i一直++,直到i=12时,此时arr[12]与i,他们俩的地址一样,所代表的的内存空间一样,可以说arr[12]就是i了,此时给arr[12]赋值为0,也就是重新给i赋值为0,那么这个循环会重新开始,也就造成了死循环。
数组名表示首元素的地址,但是有两个例外:
1.sizeof(数组名),这个数组名表示整个数组
2.&数组名,这个数组名也表示整个数组,取出的是整个数组的地址
int main()
{int arr1[] = { 1,2,3,4,5 };int arr2[] = { 2,3,4,5,6 };int arr3[] = { 3,4,5,6,7 };int* parr[3] = {arr1,arr2,arr3};int i = 0;for (i = 0; i < 3; i++){char j = 0;for (j = 0; j < sizeof(arr1) / sizeof(arr1[0]);j++){/*arr1存放的是其首元素1的地址parr[1]存放的是arr1的地址也就是arr1首元素的地址现在对parr进行解引用实际得到的是arr1首元素的地址arr1首元素的地址存放的是arr1的首元素,解引用得到1*/printf("%d ", *(*(parr + i) + j));if (j == 4){printf("\n");}}}return 0;
}
数组指针:

二、strcpy函数
int main()
{ char name[20] = "xxxxXXxxxx";char name1[20] = "xxxxXXxxxx";char arr[] = { 'a','b','c','i' };strcpy(name, "zhangsan");strcpy(name1, "zhang\0san");printf("%s\n", name);printf("%s\n", name1);strcpy(name, arr);printf("%s\n", name);strcpy(name, "zhangsansssssssssssssssssssssssss");//超出,崩溃return 0;
}
char* my_strcpy(char* parr2, const char* parr1)
{assert(parr1);assert(parr2);char* ret = *parr1;while (*parr2++ = *parr1++);/*parr1++;parr2++;*/*parr2 = '\0';return ret;
}
int main()
{char arr1[] = "abcdef";char arr2[20] = { 0 };my_strcpy(arr2, arr1);printf("%s\n", arr2);}三、memcpy函数

/*void*类型不能解引用*/
my_memcpy(void* parr2, void* parr1, unsigned int num)
{assert(parr1 && parr2);while (num--){*(char*)parr2 = *(char*)parr1;parr1 = (char*)parr1 + 1;parr2 = (char*)parr2 + 1;}
}
int main()
{int arr1[] = { 1,2,3,4,5,6 };int arr2[20] = { 0 };my_memcpy(arr2,arr1,20);int i = 0;for (i = 0; i < 20; i++){printf("%d ", arr2[i]);}return 0;
}四、memmove函数

void* my_memmove(void* dst,const void* src,unsigned int num)
{assert(dst && src);void* ret = dst;if (dst < src)//从前向后拷贝{while (num--){*(char*)dst = *(char*)src;dst = (char*)dst + 1;src = (char*)src + 1;}}else if (dst >= src)//从后向前拷贝{while (num--){*((char*)dst + num) = *((char*)src + num);}}return ret;
}
int main()
{int arr1[10] = { 1,2,3,4,5,6,7 };my_memmove(arr1, arr1+3, 20);int i = 0;for (i = 0; i < 10; i++){printf("%d ", arr1[i]);}return 0;
}五、memcmp函数


arr1<arr2,所以返回<0//一个字节一个字节的比较,只要出现小于就会返回

int my_memcmp(const void* parr1, const void* parr2, unsigned int num)
{int ret = 0;while (num--){if (*(char*)parr1 > *(char*)parr2){ret = 1;break;}else if (*(char*)parr1 < *(char*)parr2){ret = -1;break;}else{parr1 = (char*)parr1 + 1;parr2 = (char*)parr2 + 1;}ret = 0;}return ret;
}
int main()
{int arr1[10] = { 1,2,3,4,5,6,7 };int arr2[10] = { 1,2,3,5,6,7,8 };int arr3[10] = { 1,2,3,4,5,6,7 };int arr4[10] = { 1,2,3,2,5,6,7 };int ret1 = my_memcmp((void*)arr1, (void*)arr2, 20);int ret2 = my_memcmp(arr1, arr3, sizeof(arr1) / sizeof(arr1[0]));int ret3 = my_memcmp(arr1, arr4, 20);printf("%d\n%d\n%d\n", ret1,ret2,ret3);return 0;
}
六、memset函数
int main()
{char arr[] = "hello,bit";memset(arr, 'x', 5);printf("%s\n", arr);memset(arr, 0, strlen(arr));int i = 0;for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){printf("%d ",*(arr+i) );}
}