目录标题
- 前言
- 环境使用:
- 模块使用:
- 基本流程思路:
- 代码展示
- 获取数据
- 扩展知识
- 数据可视化
- 尾语
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

环境使用:
-
python 3.8 解释器
-
pycharm 编辑器
模块使用:
第三方模块 需要安装
- requests —> 发送 HTTP请求
内置模块 不需要安装
- csv —> 数据处理中经常会用到的一种文件格式
第三方模块安装:
win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安装速度比较慢, 你可以切换国内镜像源)
python资料、源码、教程\福利皆: 点击此处跳转文末名片获取
基本流程思路:
一. 数据来源分析
-
明确需求
-
明确采集网站以及数据
数据: 商品信息
-
-
抓包分析 --> 通过浏览器自带工具: 开发者工具
-
打开开发者工具: F12 / 右键点击检查选择network
-
刷新网页: 让网页数据重新加载一遍
-
搜索关键字: 搜索数据在哪里
找到数据包: 50条商品数据信息
整页数据内容: 120条 --> 分成三个数据包
-
前50条数据 --> 前50个商品ID
-
中50条数据 --> 中50个商品ID
-
后20条数据 --> 后20个商品ID
已知: 数据分为三组 --> 对比三组数据包请求参数变化规律
请求参数变化规律: 商品ID
分析找一下 是否存在一个数据包, 包含所有商品ID
-
如果想要获取商品信息 --> 先获取所有商品ID --> ID存在数据包
-
二. 代码实现步骤: 发送请求 -> 获取数据 -> 解析数据 -> 保存数据
第一次请求 --> 获取商品ID
-
发送请求, 模拟浏览器对于url地址发送请求
请求链接: 商品ID数据
-
获取数据, 获取服务器返回响应数据
开发者工具: response
-
解析数据, 提取我们想要的数据内容
商品ID
第二次请求 --> 获取商品信息
-
发送请求, 模拟浏览器对于url地址发送请求
请求链接: 商品信息数据包
-
获取数据, 获取服务器返回响应数据
开发者工具: response
-
解析数据, 提取我们想要的数据内容
商品信息
-
保存数据, 把信息保存本地文件 csv表格
-
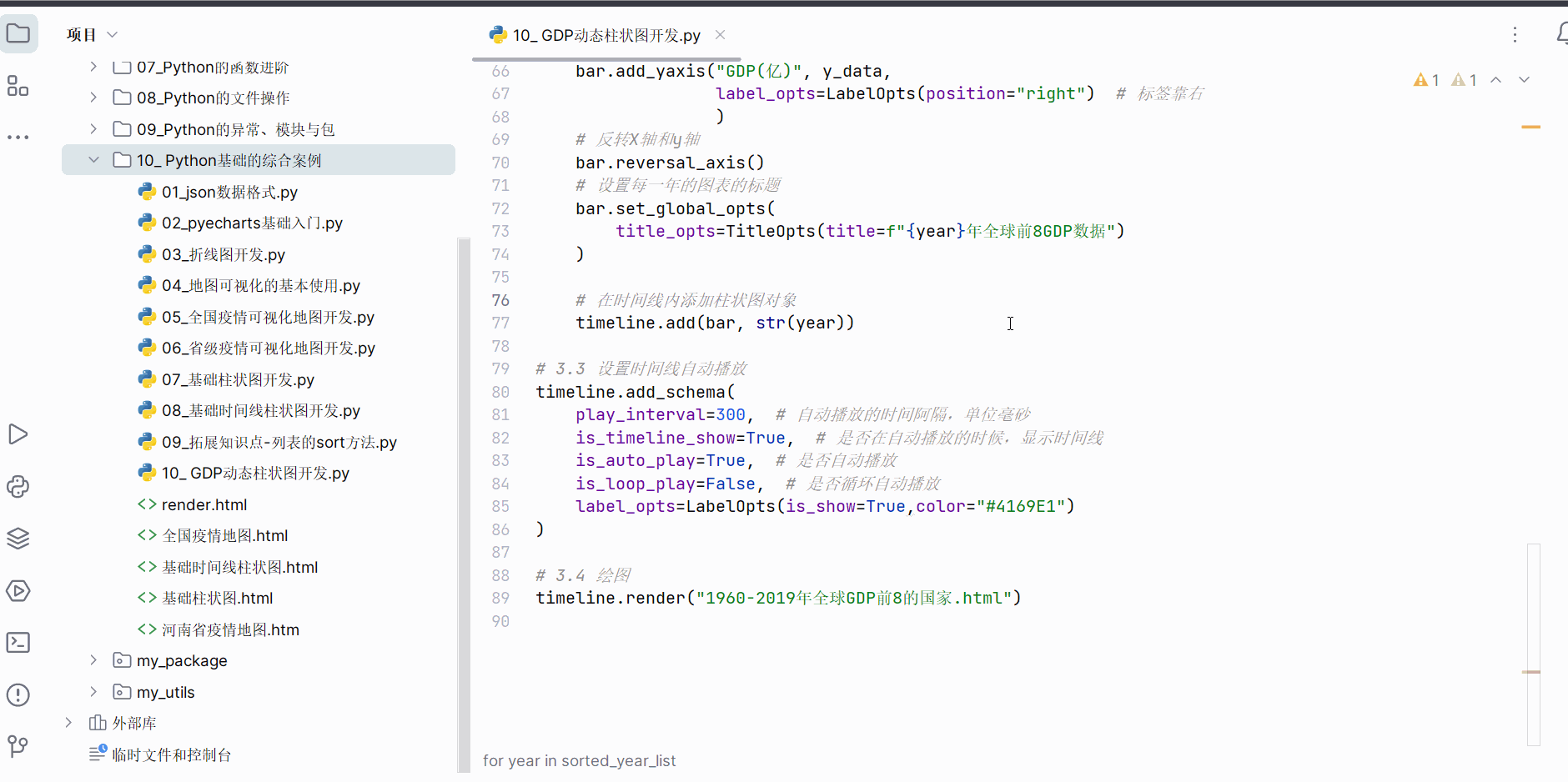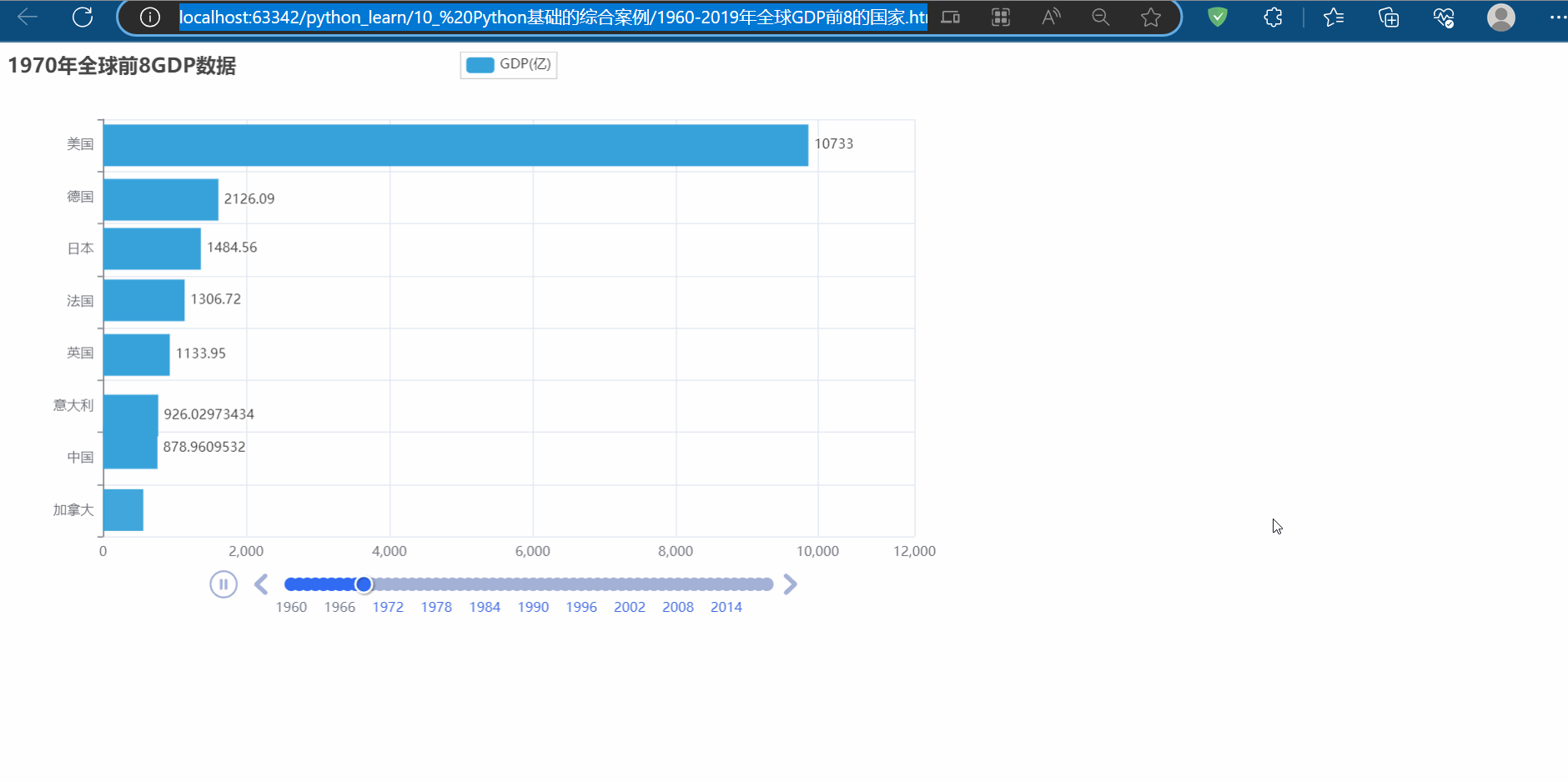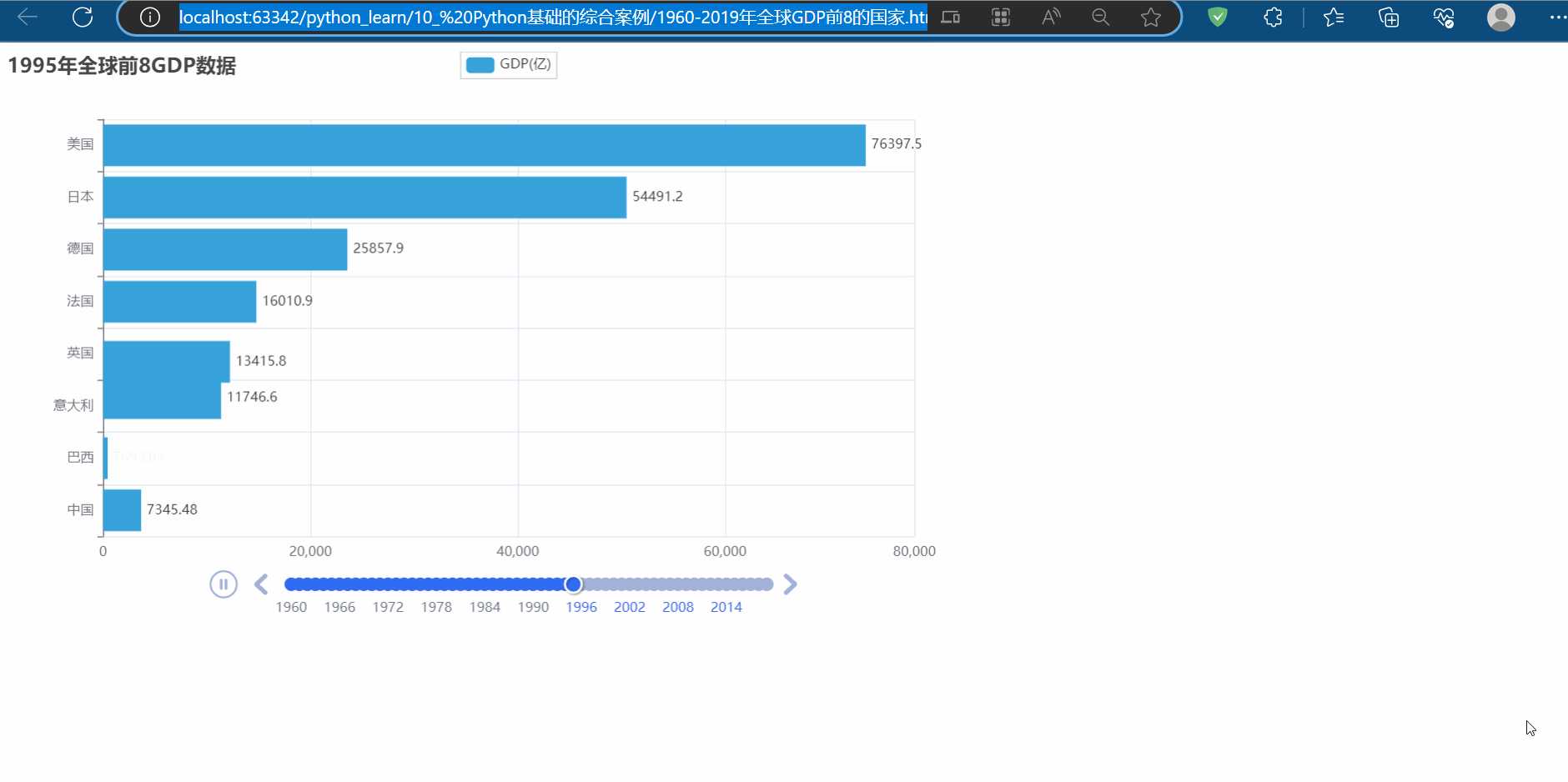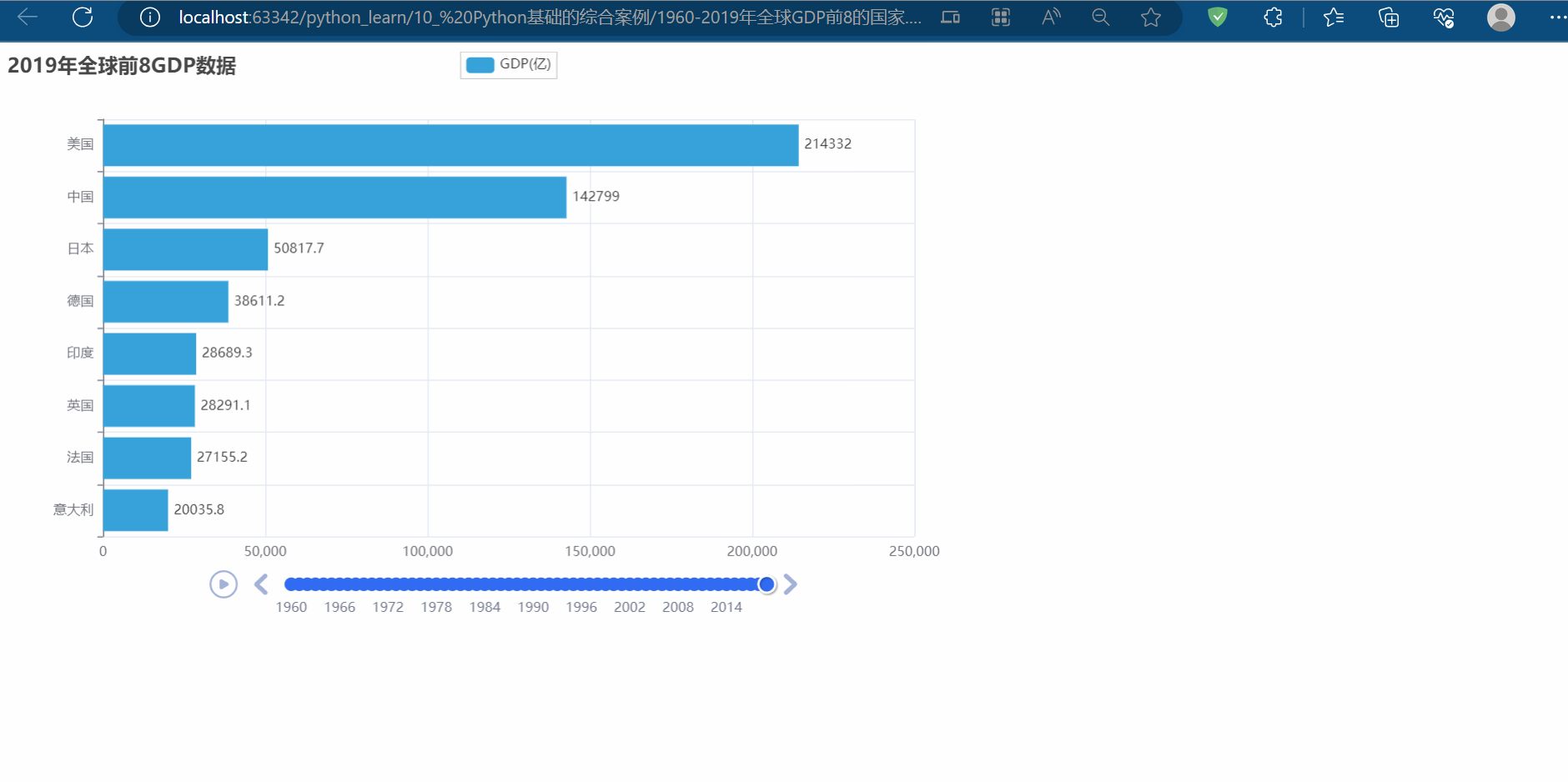
多页数据采集
代码展示
获取数据
# 导入数据请求模块
import requests
# 导入格式化输出模块
from pprint import pprint
# 导入csv
import csv# 模拟浏览器 -> 请求头 headers <字典>
headers = {# 防盗链 告诉服务器请求链接地址从哪里跳转过来'Referer': '*****/',# 用户代理, 表示浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
}
# 请求链接
# 源码、解答、教程、安装包等资料加V:qian97378免费领
url = 'https://m*****/vips-mobile/rest/shopping/pc/search/product/rank'
# 请求参数 <字典>
data = {# 回调函数# 'callback': 'getMerchandiseIds','app_name': 'shop_pc','app_version': '4.0','warehouse': 'VIP_HZ','fdc_area_id': '104103101','client': 'pc','mobile_platform': '1','province_id': '104103','api_key': '70f71280d5d547b2a7bb370a529aeea1','user_id': '','mars_cid': '1689245318776_e2b4a7b51f99b3dd6a4e6d356e364148','wap_consumer': 'a','standby_id': 'nature','keyword': '泳衣','lv3CatIds': '','lv2CatIds': '','lv1CatIds': '','brandStoreSns': '','props': '','priceMin': '','priceMax': '','vipService': '','sort': '0','pageOffset': '0','channelId': '1','gPlatform': 'PC','batchSize': '120','_': '1689250387620',
}
# 发送请求 --> <Response [200]> 响应对象
response = requests.get(url=url, params=data, headers=headers)
# 商品ID -> 120个
products = [i['pid'] for i in response.json()['data']['products']]
# 把120个商品ID 分组 --> 切片 起始:0 结束:50 步长:1
# 列表合并成字符串
product_id_1 = ','.join(products[:50]) # 提取前50个商品ID 0-49
product_id_2 = ','.join(products[50:100]) # 提取中50个商品ID 50-99
product_id_3 = ','.join(products[100:]) # 提取后20个商品ID 100到最后
product_id_list = [product_id_1, product_id_2, product_id_3]for product_id in product_id_list:# 请求链接源码、解答、教程、安装包等资料加V:qian97378免费领link = 'https://*****/vips-mobile/rest/shopping/pc/product/module/list/v2'# 请求参数params = {# 'callback': 'getMerchandiseDroplets2','app_name': 'shop_pc','app_version': '4.0','warehouse': 'VIP_HZ','fdc_area_id': '104103101','client': 'pc','mobile_platform': '1','province_id': '104103','api_key': '70f71280d5d547b2a7bb370a529aeea1','user_id': '','mars_cid': '1689245318776_e2b4a7b51f99b3dd6a4e6d356e364148','wap_consumer': 'a','productIds': product_id,'scene': 'search','standby_id': 'nature','extParams': '{"stdSizeVids":"","preheatTipsVer":"3","couponVer":"v2","exclusivePrice":"1","iconSpec":"2x","ic2label":1,"superHot":1,"bigBrand":"1"}','context': '','_': '1689250387628',}# 发送请求json_data = requests.get(url=link, params=params, headers=headers).json()for index in json_data['data']['products']:# 商品信息attr = ','.join([j['value'] for j in index['attrs']])# 创建字典dit = {'标题': index['title'],'品牌': index['brandShowName'],'原价': index['price']['marketPrice'],'售价': index['price']['salePrice'],'折扣': index['price']['mixPriceLabel'],'商品信息': attr,'详情页': f'*****/detail-{index["brandId"]}-{index["productId"]}.html',}
扩展知识
-
模拟浏览器: 为了防止被反爬
可以在开发者工具中复制粘贴
-
请求链接: 请求参数
长链接分段写:
-
问号前面 -> 请求链接
-
问号后面 -> 请求参数/查询参数
-
-
批量替换:
-
选择替换的内容 ctrl + R
-
使用正则进行匹配
(.?): (.)
‘$1’: ‘$2’,
-
-
字典取值 -> 根据键值对取值
根据冒号左边的内容, 提取冒号右边内容
-
空列表
products = []
列表<数据容器>, 装东西的盒子 {‘pid’: ‘6919798151514518861’} 盒子里苹果
for i in response.json()[‘data’][‘products’]:
i 塑料袋 把苹果装起来 --> 列表里面元素赋值给i
print(i[‘pid’])
products.append(i[‘pid’]) # 往 products 列表里面添加 i[‘pid’] 元素
-
只要获取 response.json() 时候报错:
-
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
原因: 获取 response.json() 必须是完整json数据格式
-
数据可视化
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
import pandas as pd
df = pd.read_csv('data.csv')
df.head()
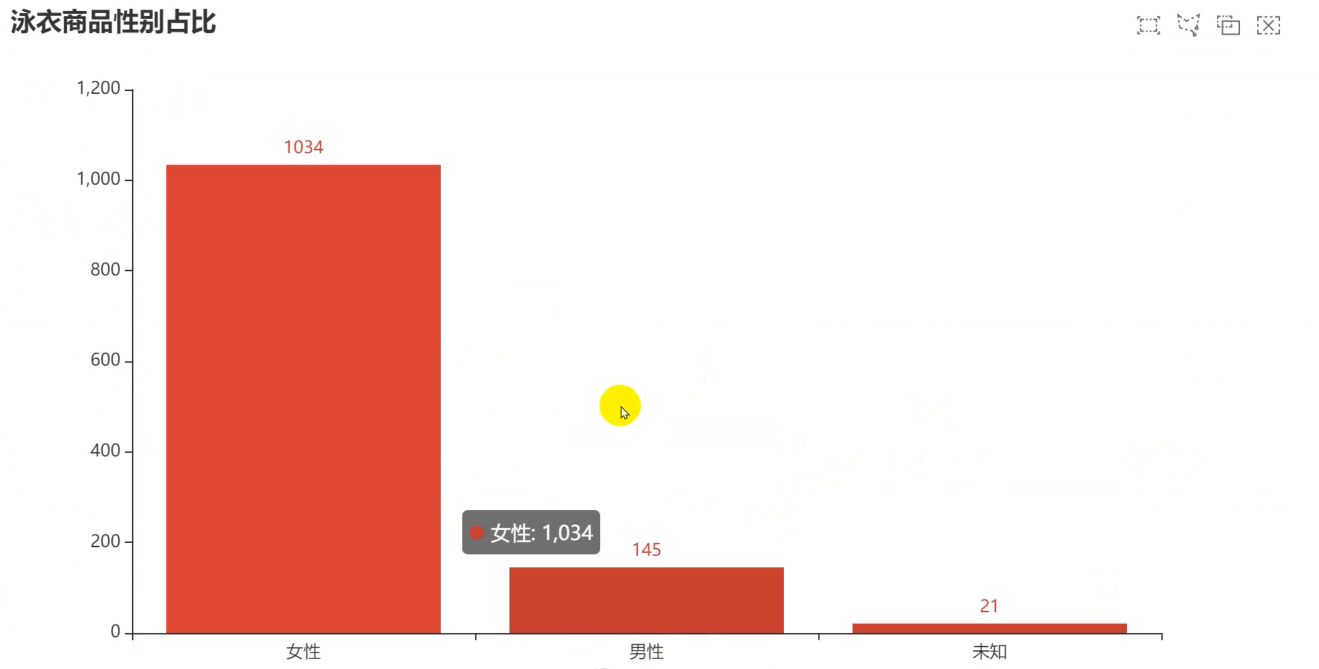
def gender_category(gender):if '男' in gender:return '男性'elif '女' in gender:return '女性'else:return '未知'
df['性别'] = df['标题'].apply(gender_category)
sex_num = df['性别'].value_counts().to_list()
sex_type = df['性别'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Fakerc = (Bar().add_xaxis(sex_type).add_yaxis("", sex_num).set_global_opts(完整源码、解答、教程、安装包等资料加V:qian97378免费领title_opts=opts.TitleOpts(title="泳衣商品性别占比", subtitle=""),brush_opts=opts.BrushOpts(),)
)
c.load_javascript()
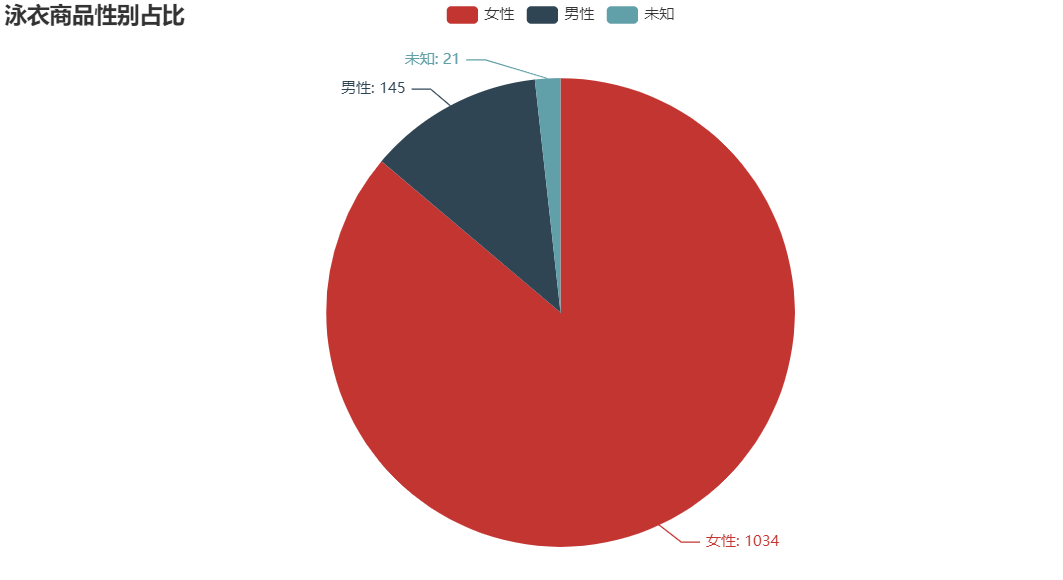
from pyecharts import options as opts
from pyecharts.charts import Piec = (Pie().add("", [list(z) for z in zip(sex_type, sex_num)]).set_global_opts(title_opts=opts.TitleOpts(title="泳衣商品性别占比")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
shop_num = df['品牌'].value_counts().to_list()
shop_type = df['品牌'].value_counts().index.to_list()
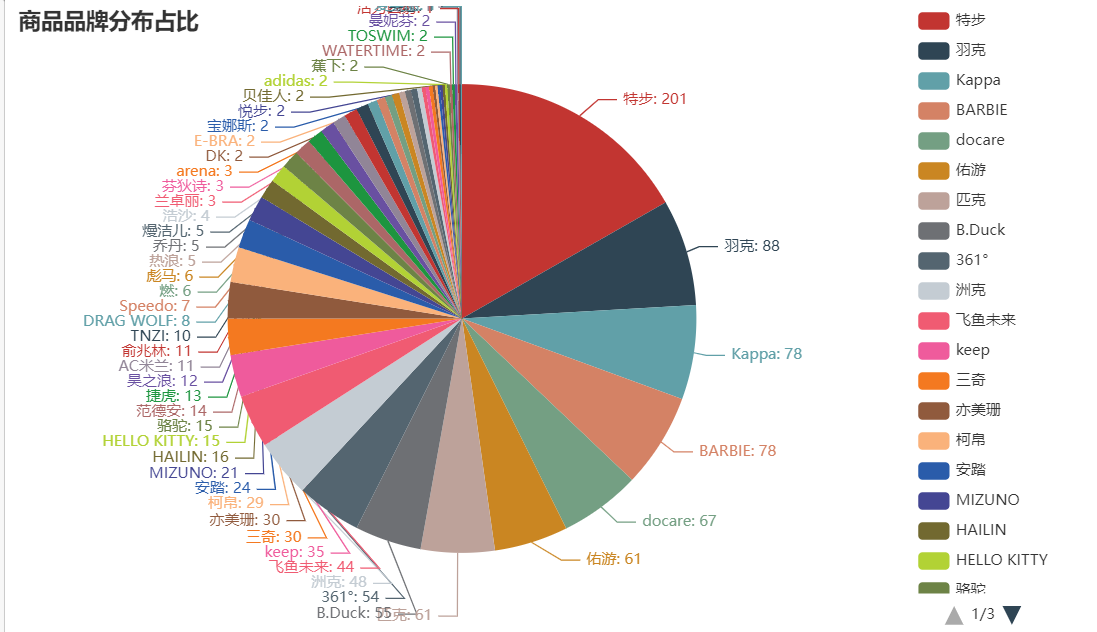
c = (Pie().add("",[list(z)for z in zip(shop_type, shop_num)],center=["40%", "50%"],).set_global_opts(title_opts=opts.TitleOpts(title="商品品牌分布占比"),legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
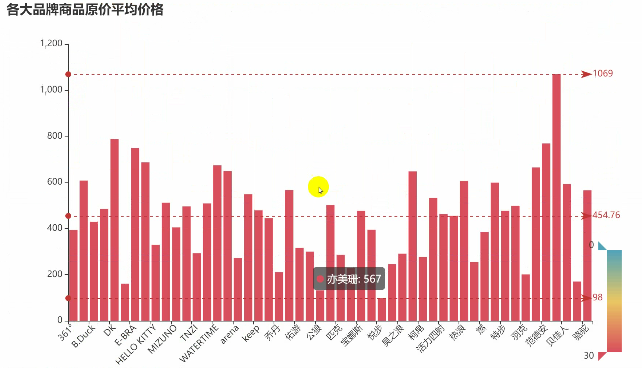
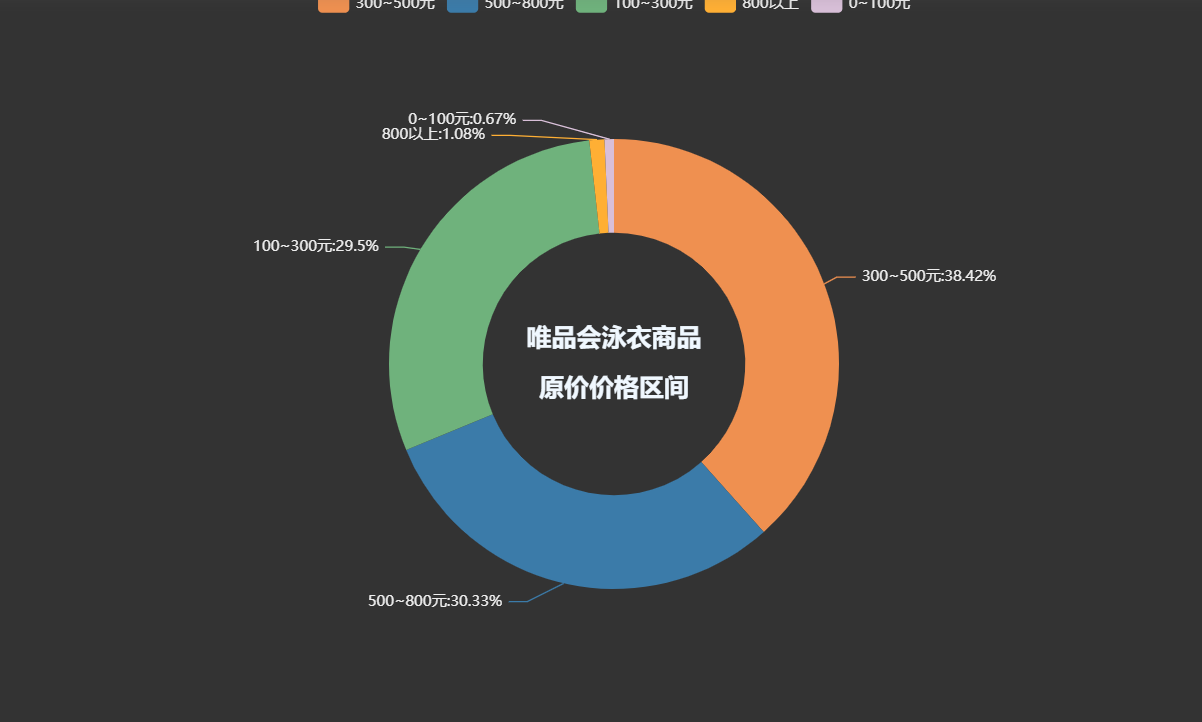
# 按城市分组并计算平均薪资
avg_salary = df.groupby('品牌')['售价'].mean()
ShopType = avg_salary.index.tolist()
ShopNum = [int(a) for a in avg_salary.values.tolist()]
# 创建柱状图实例
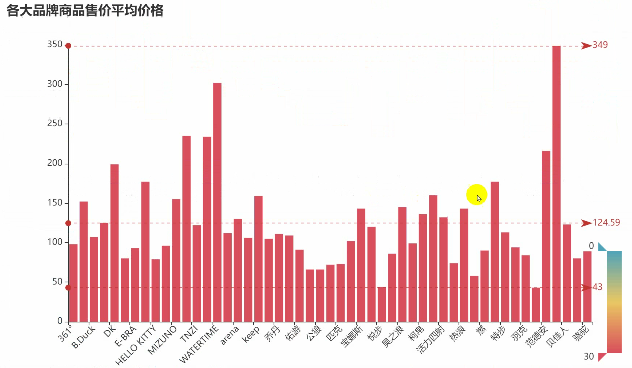
c = (Bar().add_xaxis(ShopType).add_yaxis("", ShopNum).set_global_opts(title_opts=opts.TitleOpts(title="各大品牌商品售价平均价格"),visualmap_opts=opts.VisualMapOpts(dimension=1,pos_right="5%",max_=30,is_inverse=True,),# 完整源码、解答、教程、安装包等资料加V:qian97378免费领xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度).set_series_opts(label_opts=opts.LabelOpts(is_show=False),markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="min", name="最小值"),opts.MarkLineItem(type_="max", name="最大值"),opts.MarkLineItem(type_="average", name="平均值"),]),)
)c.render_notebook()
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。